Správa vstupů a výstupů pro komponenty a kanály
Kanály Azure Machine Learning podporují vstupy a výstupy na úrovni komponent i kanálů. Tento článek popisuje vstupy kanálů a komponent a výstupy a jejich správu.
Na úrovni komponenty definují vstupy a výstupy rozhraní komponenty. Výstup z jedné komponenty můžete použít jako vstup pro jinou komponentu ve stejném nadřazeném kanálu, což umožňuje předávání dat nebo modelů mezi komponentami. Toto propojení představuje tok dat v rámci kanálu.
Na úrovni kanálu můžete použít vstupy a výstupy k odesílání úloh kanálu s různými datovými vstupy nebo parametry, například learning_rate. Vstupy a výstupy jsou zvláště užitečné při vyvolání kanálu prostřednictvím koncového bodu REST. Ke vstupu kanálu můžete přiřadit různé hodnoty nebo přistupovat k výstupu různých úloh kanálu. Další informace najdete v tématu Vytváření úloh a vstupních dat pro dávkové koncové body.
Vstupní a výstupní typy
Následující typy jsou podporovány jako vstupy i výstupy komponent nebo kanálů:
Datové typy. Další informace naleznete v tématu Datové typy.
uri_fileuri_foldermltable
Typy modelů.
mlflow_modelcustom_model
Pouze pro vstupy jsou podporovány následující primitivní typy:
- Primitivní typy
stringnumberintegerboolean
Výstup primitivního typu není podporovaný.
Příklady vstupů a výstupů
Tyto příklady pocházejí z kanálu regrese dat taxislužby NYC v úložišti Azure Machine Learning .
- Komponenta vlaku
numbermá vstup s názvem .test_split_ratio - Komponenta přípravy má
uri_foldervýstup typu. Zdrojový kód komponenty přečte soubory CSV ze vstupní složky, zpracuje soubory a zapíše zpracované soubory CSV do výstupní složky. - Komponenta vlaku
mlflow_modelmá výstup typu. Zdrojový kód komponenty uloží natrénovaný model pomocímlflow.sklearn.save_modelmetody.
Serializace výstupu
Pomocí výstupů dat nebo modelu serializuje výstupy a uloží je jako soubory v úložišti. Pozdější kroky mají přístup k souborům během provádění úlohy připojením tohoto umístění úložiště nebo stažením nebo nahráním souborů do výpočetního systému souborů.
Zdrojový kód komponenty musí serializovat výstupní objekt, který je obvykle uložen v paměti, do souborů. Datový rámec pandas můžete například serializovat do souboru CSV. Azure Machine Learning nedefinuje žádné standardizované metody pro serializaci objektů. Máte flexibilitu zvolit preferované metody serializace objektů do souborů. V podřízené komponentě můžete zvolit, jak tyto soubory deserializovat a číst.
Vstupní a výstupní cesty datového typu
Pro vstupy a výstupy datového assetu je nutné zadat parametr cesty, který odkazuje na umístění dat. Následující tabulka ukazuje podporovaná umístění dat pro vstupy a výstupy kanálu Azure Machine Learning s path příklady parametrů.
| Umístění | Vstup | Výstup | Příklad |
|---|---|---|---|
| Cesta na místním počítači | ✓ | ./home/<username>/data/my_data |
|
| Cesta na veřejném serveru HTTP/s | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Cesta ve službě Azure Storage | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>nebo abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Cesta k úložišti dat služby Azure Machine Learning | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| Cesta k datovému assetu | ✓ | ✓ | azureml:my_data:<version> |
* Použití služby Azure Storage přímo se nedoporučuje pro vstup, protože ke čtení dat může vyžadovat další konfiguraci identity. Je lepší používat cesty úložiště dat Azure Machine Learning, které jsou podporované napříč různými typy úloh kanálu.
Vstupní a výstupní režimy datového typu
Pro vstupy a výstupy datového typu si můžete vybrat z několika režimů stahování, nahrávání a připojení, abyste definovali, jak cílový výpočetní objekt přistupuje k datům. Následující tabulka ukazuje podporované režimy pro různé typy vstupů a výstupů.
| Typ | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
uri_folder vstup |
✓ | ✓ | ✓ | ||||
uri_file vstup |
✓ | ✓ | ✓ | ||||
mltable vstup |
✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder výstup |
✓ | ✓ | |||||
uri_file výstup |
✓ | ✓ | |||||
mltable výstup |
✓ | ✓ | ✓ |
rw_mount Ve většině případů se doporučují režimyro_mount. Další informace naleznete v tématu Režimy.
Vstupy a výstupy v grafech kanálů
Na stránce úlohy kanálu v studio Azure Machine Learning se vstupy a výstupy komponent zobrazují jako malé kruhy označované jako vstupní a výstupní porty. Tyto porty představují tok dat v kanálu. Výstup na úrovni kanálu se zobrazí v fialových polích pro snadnou identifikaci.
Následující snímek obrazovky z grafu kanálu regrese dat taxislužby NYC ukazuje mnoho vstupů komponent a kanálů a výstupů.

Když najedete myší na vstupní/výstupní port, zobrazí se typ.
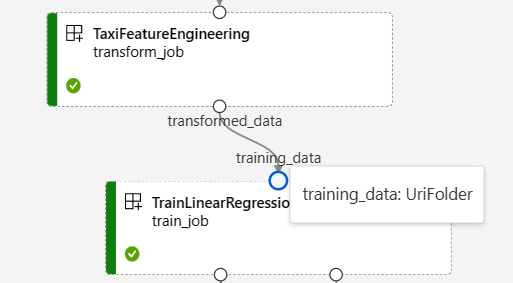
Graf kanálu nezobrazuje vstupy primitivního typu. Tyto vstupy se zobrazí na kartě Nastavení na panelu Přehled úlohy kanálu pro vstupy na úrovni kanálu nebo na panelu komponent pro vstupy na úrovni součástí. Pokud chcete otevřít panel komponent, poklikejte na komponentu v grafu.

Při úpravě kanálu v návrháři studia jsou vstupy a výstupy kanálu na panelu rozhraní kanálu a vstupy komponent a výstupy jsou na panelu komponent.
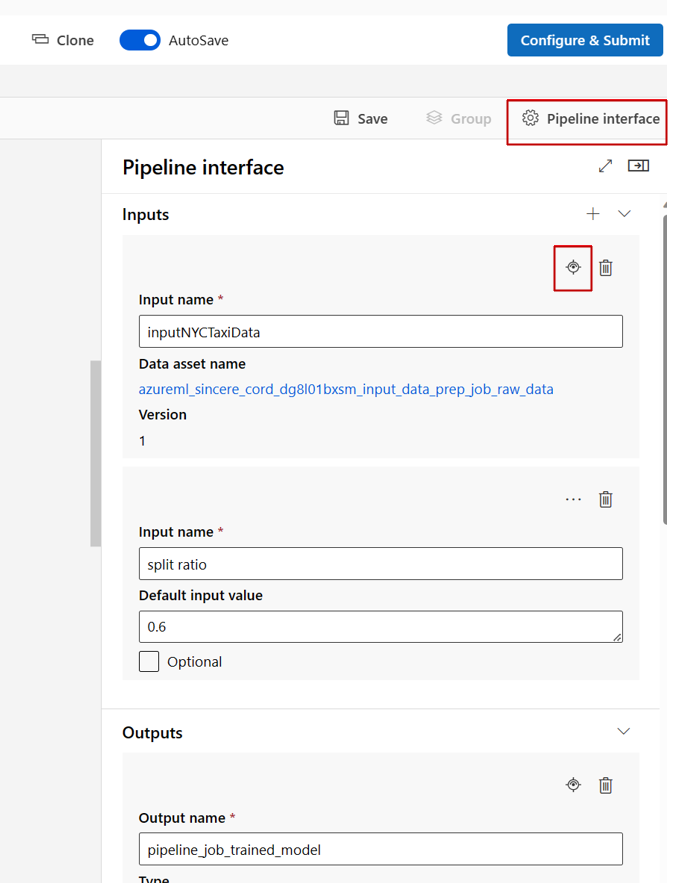
Zvýšení úrovně vstupů a výstupů komponent na úroveň kanálu
Zvýšením úrovně vstupu a výstupu komponenty na úroveň kanálu můžete při odesílání úlohy kanálu přepsat vstup a výstup komponenty. Tato schopnost je užitečná zejména pro aktivaci kanálů pomocí koncových bodů REST.
Následující příklady ukazují, jak zvýšit úroveň vstupů a výstupů na úrovni kanálu vstupy a výstupy.
Následující kanál podporuje tři vstupy a tři výstupy na úrovni kanálu. Je to například vstup na úrovni kanálu, pipeline_job_training_max_epocs protože je deklarován v inputs části na kořenové úrovni.
V train_job části jobs se na vstup pojmenovaný max_epocs odkaz odkazuje, ${{parent.inputs.pipeline_job_training_max_epocs}}což znamená, že train_jobmax_epocs vstup "odkazuje na vstup na úrovni pipeline_job_training_max_epocs kanálu. Výstup kanálu se zvýší pomocí stejného schématu.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Úplný příklad najdete v kanálu train-score-eval s registrovanými komponentami v úložišti příkladů služby Azure Machine Learning.
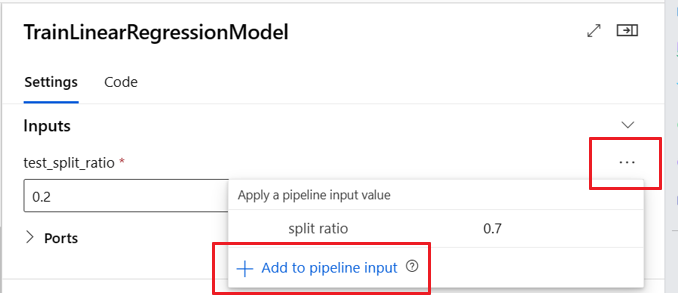
Definování volitelných vstupů
Ve výchozím nastavení jsou všechny vstupy povinné a musí mít buď výchozí hodnotu, nebo musí mít přiřazenou hodnotu při každém odeslání úlohy kanálu. Můžete ale definovat volitelný vstup.
Poznámka:
Volitelné výstupy nejsou podporované.
Nastavení volitelných vstupů může být užitečné ve dvou scénářích:
Pokud definujete volitelný vstup typu dat nebo modelu a při odesílání úlohy kanálu nepřiřazujete hodnotu, komponenta kanálu tuto závislost dat neobsahuje. Pokud vstupní port komponenty není propojený s žádnou komponentou nebo komponentou nebo uzlem modelu, kanál vyvolá komponentu přímo místo čekání na předchozí závislost.
Pokud nastavíte
continue_on_step_failure = Truekanál, alenode2použijete požadovaný vstup znode1,node2neproběhne, pokudnode1selže. Pokudnode1je vstup volitelný,node2spustí se i v případěnode1selhání. Následující graf ukazuje tento scénář.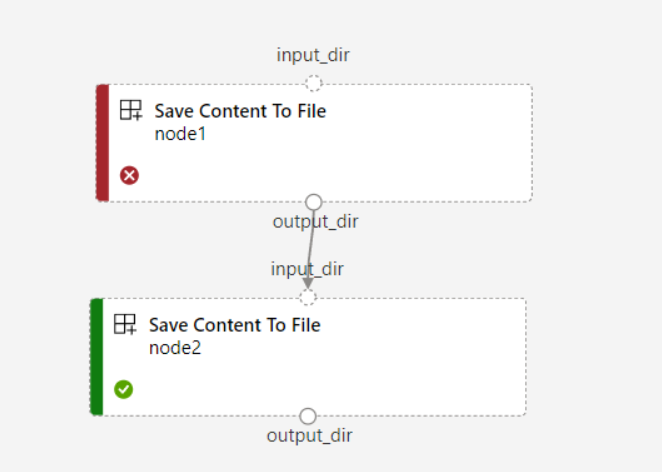
Následující příklad kódu ukazuje, jak definovat volitelný vstup. Pokud je vstup nastavený jako optional = true, musíte použít $[[]] k přijetí vstupů příkazového řádku, jako ve zvýrazněných řádcích příkladu.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Přizpůsobení výstupních cest
Ve výchozím nastavení je výstup komponenty uložen v {default_datastore} nastaveném kanálu azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}}. Pokud není nastavené, výchozí je úložiště objektů blob pracovního prostoru.
Úloha {name} se přeloží v době provádění úlohy a {output_name} je název, který jste definovali v yaml komponenty. Umístění pro uložení výstupu můžete přizpůsobit definováním výstupní cesty.
Soubor pipeline.yml v kanálu train-score-eval s registrovanými komponentami příklad definuje kanál, který má tři výstupy na úrovni kanálu. K nastavení vlastních výstupních cest pro pipeline_job_trained_model výstup můžete použít následující příkaz.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

Stažení výstupů
Výstupy si můžete stáhnout na úrovni kanálu nebo komponenty.
Stažení výstupů na úrovni kanálu
Můžete stáhnout všechny výstupy úlohy nebo stáhnout konkrétní výstup.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

Stažení výstupů komponent
Pokud chcete stáhnout výstupy podřízené komponenty, nejprve vypíšete všechny podřízené úlohy úlohy kanálu a pak pomocí podobného kódu stáhnete výstupy.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
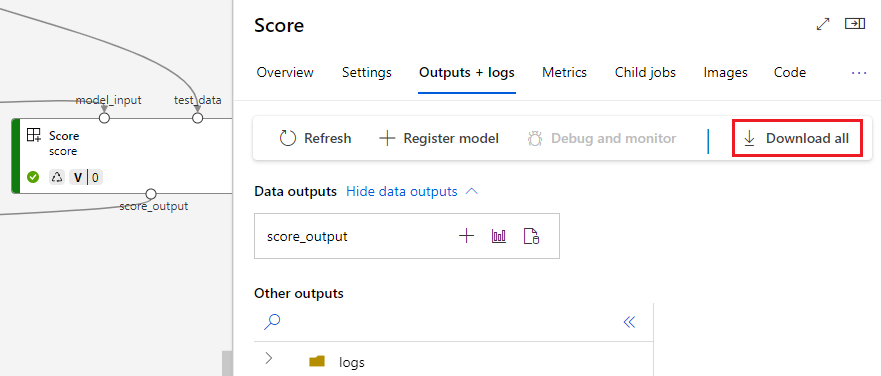
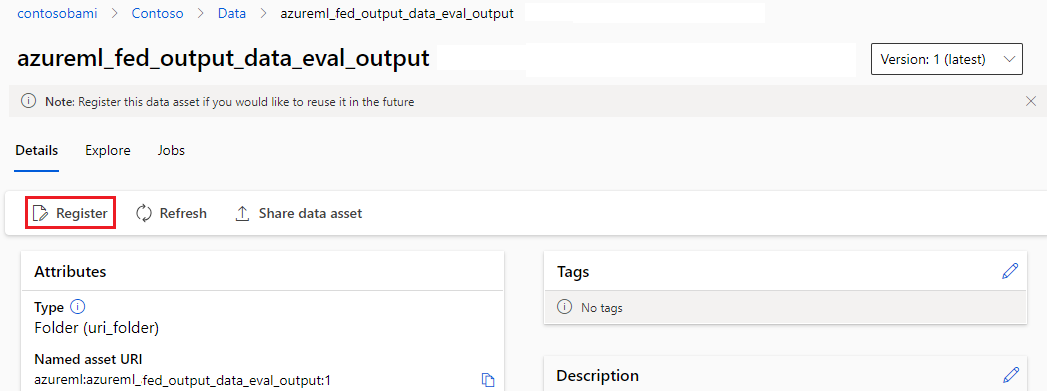
Registrace výstupu jako pojmenovaného prostředku
Výstup komponenty nebo kanálu můžete zaregistrovat jako pojmenovaný prostředek přiřazením name a version výstupem. Zaregistrovaný prostředek můžete v pracovním prostoru uvést prostřednictvím uživatelského rozhraní studia, rozhraní příkazového řádku nebo sady SDK a odkazovat na ho v budoucích úlohách pracovního prostoru.
Registrace výstupu na úrovni kanálu
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
Registrace výstupu komponenty
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster