Vysvětlení modelů ML a predikcí (Preview) pomocí balíčku interpretovatelnosti Pythonu
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto návodu se naučíte používat balíček interpretovatelnosti sady Azure Machine Learning Python SDK k provádění následujících úloh:
Vysvětlete celé chování modelu nebo individuální předpovědi na vašem osobním počítači místně.
Povolte techniky interpretovatelnosti pro zkonstruované funkce.
Vysvětlete chování celého modelu a jednotlivých předpovědí v Azure.
Nahrajte vysvětlení do historie spuštění služby Azure Machine Learning.
Pomocí řídicího panelu vizualizace můžete pracovat s vysvětleními modelu, a to jak v poznámkovém bloku Jupyter, tak v studio Azure Machine Learning.
Nasaďte spolu s modelem vysvětlení skóre, abyste mohli sledovat vysvětlení během odvozování.
Důležité
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti.
Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Další informace o podporovaných technikách interpretace a modelech strojového učení najdete v tématu Interpretovatelnost modelů ve službě Azure Machine Learning a ukázkových poznámkových blocích.
Pokyny k povolení interpretability pro modely natrénované pomocí automatizovaného strojového učení najdete v tématu Interpretability: vysvětlení modelů pro automatizované modely strojového učení (Preview).
Generování hodnoty důležitosti funkcí na osobním počítači
Následující příklad ukazuje, jak používat balíček interpretovatelnosti na osobním počítači bez kontaktování služeb Azure.
Nainstalujte balíček
azureml-interpret.pip install azureml-interpretTrénování ukázkového modelu v místním poznámkovém bloku Jupyter
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Zavolejte místně vysvětlovač.
- Chcete-li inicializovat objekt vysvětlujícího objektu, předejte model a některá trénovací data konstruktoru vysvětlujícího.
- Pokud chcete, aby vysvětlení a vizualizace byly informativnější, můžete při klasifikaci předat názvy funkcí a názvy výstupních tříd.
Následující bloky kódu ukazují, jak vytvořit instanci vysvětlujících objektů s
TabularExplainer,MimicExplaineraPFIExplainermístně.TabularExplainervolá jeden ze tří vysvětlení SHAP pod (TreeExplainer,DeepExplainerneboKernelExplainer).TabularExplainerautomaticky vybere nejvhodnější pro váš případ použití, ale můžete volat každý z jejích tří podkladových vysvětlení přímo.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)nebo
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)nebo
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Vysvětlení celého chování modelu (globální vysvětlení)
Informace o získání hodnot důležitosti agregovaných (globálních) funkcí najdete v následujícím příkladu.
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Vysvětlení individuální předpovědi (místní vysvětlení)
Získejte hodnoty důležitosti jednotlivých funkcí různých datových bodů voláním vysvětlení pro jednotlivé instance nebo skupinu instancí.
Poznámka:
PFIExplainer nepodporuje místní vysvětlení.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Nezpracované transformace funkcí
Můžete se rozhodnout získat vysvětlení z hlediska nezpracovaných, netransformovaných funkcí, nikoli zpracovaných funkcí. Pro tuto možnost předáte kanál transformace funkce vysvětlujícímu prvku v train_explain.pysouboru . V opačném případě vysvětlující nástroj poskytuje vysvětlení z hlediska inženýrovaných funkcí.
Formát podporovaných transformací je stejný jako v sklearn-pandas. Obecně platí, že všechny transformace se podporují, pokud pracují s jedním sloupcem, aby byly jasné, že jsou 1:N.
Získejte vysvětlení nezpracovaných funkcí pomocí sklearn.compose.ColumnTransformer nebo se seznamem fitovaných řazených řazených kolekcí transformátorů. Následující příklad používá sklearn.compose.ColumnTransformer.
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
V případě, že chcete spustit příklad se seznamem fitovaných řazených kolekcí transformátorů, použijte následující kód:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Generování hodnot důležitosti funkcí prostřednictvím vzdálených spuštění
Následující příklad ukazuje, jak můžete pomocí ExplanationClient třídy povolit interpretovatelnost modelu pro vzdálená spuštění. Koncepčně se podobá místnímu procesu s výjimkou vás:
ExplanationClientPomocí vzdáleného spuštění nahrajte kontext interpretovatelnosti.- Stáhněte si kontext později v místním prostředí.
Nainstalujte balíček
azureml-interpret.pip install azureml-interpretVytvořte trénovací skript v místním poznámkovém bloku Jupyter. Například
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Nastavte výpočetní prostředí Azure Machine Learning jako cílový výpočetní objekt a odešlete trénovací běh. Pokyny najdete v tématu Vytváření a správa výpočetních clusterů Azure Machine Learning. Příklady poznámkových bloků můžou být užitečné.
Stáhněte si vysvětlení v místním poznámkovém bloku Jupyter.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Vizualizace
Po stažení vysvětlení v místním poznámkovém bloku Jupyter můžete pomocí vizualizací na řídicím panelu vysvětlení porozumět a interpretovat model. Pokud chcete načíst widget řídicího panelu vysvětlení v poznámkovém bloku Jupyter, použijte následující kód:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
Vizualizace podporují vysvětlení pro zpracované i nezpracované funkce. Nezpracovaná vysvětlení jsou založená na funkcích z původní datové sady a zpracovaných vysvětlení jsou založená na funkcích z datové sady s použitým inženýrstvím funkcí.
Při pokusu o interpretaci modelu s ohledem na původní datovou sadu se doporučuje použít nezpracovaná vysvětlení, protože důležitost jednotlivých funkcí bude odpovídat sloupci z původní datové sady. Jedním ze scénářů, kdy může být užitečné zpracované vysvětlení, je při zkoumání dopadu jednotlivých kategorií z kategorické funkce. Pokud se u funkce kategorického použije kódování typu 1,pak výsledné vysvětlení budou obsahovat jinou hodnotu důležitosti na kategorii, jednu za jednu za hotovou funkci. Toto kódování může být užitečné při zúžení toho, která část datové sady je pro model nejinformativnější.
Poznámka:
Navržená a nezpracovaná vysvětlení se počítají postupně. Nejprve se vytvoří vytvořené vysvětlení založené na modelu a kanálu featurizace. Nezpracované vysvětlení se pak vytvoří na základě tohoto vytvořeného vysvětlení agregací důležitosti inženýrovaných funkcí, které pocházejí ze stejné nezpracované funkce.
Vytváření, úpravy a zobrazení kohort datových sad
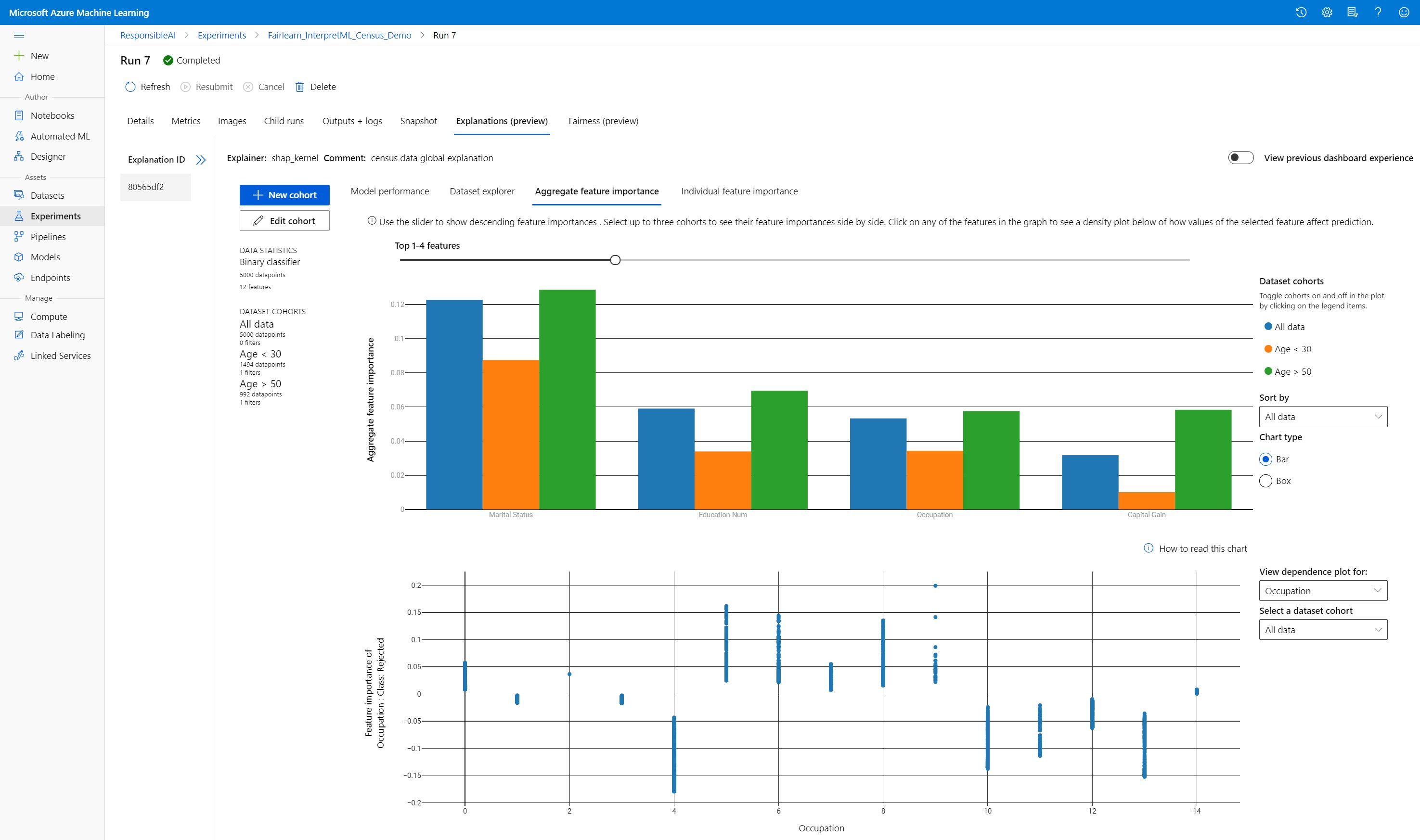
Na horním pásu karet se zobrazují celkové statistiky modelu a dat. Data můžete rozdělit na kohorty datových sad nebo podskupiny, abyste mohli prozkoumat nebo porovnat výkon a vysvětlení modelu napříč těmito definovanými podskupinami. Porovnáním statistik a vysvětlení datových sad napříč těmito podskupinami můžete získat představu o tom, proč se v jedné skupině a jiné dějí možné chyby.

Vysvětlení celého chování modelu (globální vysvětlení)
První tři karty řídicího panelu vysvětlení poskytují celkovou analýzu natrénovaného modelu spolu s jeho předpověďmi a vysvětleními.
Výkon modelu
Vyhodnoťte výkon modelu prozkoumáním rozdělení hodnot předpovědi a hodnot metrik výkonu modelu. Model můžete dále prozkoumat tak, že se podíváte na srovnávací analýzu jejího výkonu v různých kohortách nebo podskupinách datové sady. Vyberte filtry podle hodnoty y a hodnoty x, které se mají v různých dimenzích vyjmout. Zobrazení metrik, jako je přesnost, přesnost, úplnost, falešně pozitivní míra (FPR) a falešně negativní míra (FNR).

Průzkumník datových sad
Prozkoumejte statistiku datové sady výběrem různých filtrů na osách X, Y a barev, abyste mohli data rozdělit podle různých dimenzí. Vytvořte výše uvedené kohorty datové sady, abyste mohli analyzovat statistiky datové sady pomocí filtrů, jako jsou předpovězené výsledky, funkce datové sady a skupiny chyb. Pomocí ikony ozubeného kola v pravém horním rohu grafu můžete změnit typy grafů.

Agregace důležitosti funkcí
Prozkoumejte nejdůležitější funkce, které ovlivňují celkové předpovědi modelu (označované také jako globální vysvětlení). Pomocí posuvníku můžete zobrazit hodnoty důležitosti sestupně. Pokud chcete zobrazit hodnoty důležitosti jejich funkcí vedle sebe, vyberte až tři kohorty. Výběrem některého z pruhů funkcí v grafu zobrazíte, jak hodnoty vybraného modelu ovlivňují model v grafu závislostí níže.

Vysvětlení jednotlivých předpovědí (místní vysvětlení)
Čtvrtá karta karty vysvětlení umožňuje přejít k podrobnostem jednotlivých datových bodů a jejich důležitosti jednotlivých funkcí. Jednotlivý graf důležitosti funkcí pro libovolný datový bod můžete načíst kliknutím na libovolný z jednotlivých datových bodů v hlavním bodovém grafu nebo výběrem konkrétního datového bodu v průvodci panelem vpravo.
| Vykreslit | Popis |
|---|---|
| Důležitost jednotlivých funkcí | Zobrazuje nejdůležitější funkce pro individuální predikci. Pomáhá znázornit místní chování základního modelu v určitém datovém bodě. |
| Citlivostní analýza | Umožňuje změny hodnot funkcí vybraného skutečného datového bodu a sledovat výsledné změny hodnoty předpovědi tak, že vygeneruje hypotetický datový bod s novými hodnotami funkcí. |
| Individuální podmíněné očekávání (ICE) | Umožňuje, aby se hodnoty funkcí změnily z minimální hodnoty na maximální hodnotu. Pomáhá ilustrovat, jak se mění predikce datového bodu při změně funkce. |

Poznámka:
Toto jsou vysvětlení založená na mnoha aproximacích a nejsou "příčinou" předpovědí. Bez přísné matematické robustnosti kauzální odvozování nedoporučujeme uživatelům provádět rozhodnutí v reálném životě na základě perturbace funkcí nástroje Citlivostní analýza. Tento nástroj je primárně určený pro pochopení modelu a ladění.
Vizualizace v studio Azure Machine Learning
Pokud dokončíte kroky vzdálené interpretace (nahrání vygenerovaných vysvětlení do historie spuštění služby Azure Machine Learning), můžete vizualizace zobrazit na řídicím panelu vysvětlení v studio Azure Machine Learning. Tento řídicí panel je jednodušší verze widgetu řídicího panelu vygenerovaného v poznámkovém bloku Jupyter. Grafy datových bodů citlivostní analýzy a grafy ICE jsou zakázané, protože v studio Azure Machine Learning nejsou aktivní výpočetní prostředky, které by mohly provádět výpočty v reálném čase.
Pokud jsou k dispozici datová sada, globální a místní vysvětlení, naplní data všechny karty. Pokud je ale k dispozici pouze globální vysvětlení, karta Důležitost jednotlivých funkcí bude zakázaná.
Pokud chcete získat přístup k řídicímu panelu vysvětlení v studio Azure Machine Learning, postupujte následovně:
Podokno Experimenty (Preview)
- Výběrem možnosti Experimenty v levém podokně zobrazíte seznam experimentů, které jste spustili ve službě Azure Machine Learning.
- Výběrem konkrétního experimentu zobrazíte všechna spuštění v daném experimentu.
- Vyberte spuštění a potom kartu Vysvětlení na řídicím panelu vizualizace vysvětlení.
Podokno Modely
- Pokud jste svůj původní model zaregistrovali podle kroků v části Nasazení modelů pomocí služby Azure Machine Learning, můžete ho zobrazit výběrem možnosti Modely v levém podokně.
- Vyberte model a potom na kartě Vysvětlení zobrazte řídicí panel vysvětlení.

Interpretovatelnost v době odvození
Vysvětlující rutinu můžete nasadit spolu s původním modelem a použít ho při odvozování, abyste poskytli hodnoty důležitosti jednotlivých funkcí (místní vysvětlení) pro jakýkoli nový datový bod. Nabízíme také popisovače s nižší hmotností, které zlepšují výkon interpretovatelnosti při odvozování, což se v současné době podporuje jenom v sadě Azure Machine Learning SDK. Proces nasazení popisovače s nižší hmotností se podobá nasazení modelu a zahrnuje následující kroky:
Vytvořte objekt vysvětlení. Můžete například použít
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Vytvořte popisovač bodování s objektem vysvětlení.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Nakonfigurujte a zaregistrujte image, která používá model vysvětlení bodování.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Jako volitelný krok můžete načíst vysvětlení bodování z cloudu a otestovat vysvětlení.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Nasaďte image do cílového výpočetního objektu pomocí následujícího postupu:
V případě potřeby zaregistrujte původní prediktivní model podle kroků v tématu Nasazení modelů ve službě Azure Machine Learning.
Vytvořte soubor bodování.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Definujte konfiguraci nasazení.
Tato konfigurace závisí na požadavcích modelu. Následující příklad definuje konfiguraci, která používá jedno jádro procesoru a jednu GB paměti.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Vytvořte soubor se závislostmi prostředí.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Vytvořte vlastní soubor Dockerfile s nainstalovaným g++.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Nasaďte vytvořenou image.
Tento proces trvá přibližně pět minut.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Otestujte nasazení.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Odklidit.
Pokud chcete odstranit nasazenou webovou službu, použijte
service.delete().
Řešení problému
Řídká data se nepodporují: Řídicí panel vysvětlení modelu se přeruší nebo podstatně zpomalí s velkým počtem funkcí, proto v současné době nepodporujeme řídký datový formát. Kromě toho se u velkých datových sad a velkého počtu funkcí objeví obecné problémy s pamětí.
Matice podporovaných funkcí vysvětlení
| Karta Podporované vysvětlení | Nezpracované vlastnosti (hustá) | Nezpracované funkce (řídké) | Inženýrizované funkce (hustá) | Inženýrované funkce (řídké) |
|---|---|---|---|---|
| Výkon modelu | Podporováno (ne prognózování) | Podporováno (ne prognózování) | Podporováno | Podporováno |
| Průzkumník datových sad | Podporováno (ne prognózování) | Nepodporováno Vzhledem k tomu, že se nenahrají řídká data a uživatelské rozhraní má problémy s vykreslováním řídkých dat. | Podporováno | Nepodporuje se. Vzhledem k tomu, že se nenahrají řídká data a uživatelské rozhraní má problémy s vykreslováním řídkých dat. |
| Agregace důležitosti funkcí | Podporováno | Podporováno | Podporováno | Podporováno |
| Důležitost jednotlivých funkcí | Podporováno (ne prognózování) | Nepodporováno Vzhledem k tomu, že se nenahrají řídká data a uživatelské rozhraní má problémy s vykreslováním řídkých dat. | Podporováno | Nepodporuje se. Vzhledem k tomu, že se nenahrají řídká data a uživatelské rozhraní má problémy s vykreslováním řídkých dat. |
Modely prognózování, které nejsou podporovány s vysvětlením modelů: Interpretovatelnost, nejlepší vysvětlení modelu, není k dispozici pro experimenty s prognózováním AutoML, které doporučují následující algoritmy jako nejlepší model: TCNForecaster, AutoArima, Prorok, ExponentialSmoothing, Average, Naive, Seasonal Average a Seasonal Naive. Vysvětlení podporují modely regrese prognóz AutoML. Na řídicím panelu vysvětlení se ale pro prognózování nepodporuje karta Důležitost jednotlivých funkcí kvůli složitosti datových kanálů.
Místní vysvětlení indexu dat: Řídicí panel vysvětlení nepodporuje korelaci hodnot místní důležitosti s identifikátorem řádku z původní ověřovací datové sady, pokud je tato datová sada větší než 5 000 datových bodů, protože řídicí panel náhodně převzorkuje data. Řídicí panel ale zobrazuje nezpracované hodnoty funkcí datové sady pro každý datový bod předaný do řídicího panelu na kartě Důležitost jednotlivých funkcí. Uživatelé můžou mapovat místní důležitost zpět na původní datovou sadu pomocí odpovídajících hodnot vlastností nezpracované datové sady. Pokud je velikost ověřovací datové sady menší než 5 000 ukázek,
indexfunkce v studio Azure Machine Learning bude odpovídat indexu v ověřovací datové sadě.Grafy citlivosti a ICE, které nejsou v sadě Studio podporované: Grafy citlivostní a individuální podmíněné očekávání (ICE) nejsou podporované v studio Azure Machine Learning na kartě Vysvětlení, protože nahrané vysvětlení potřebuje aktivní výpočetní výkon k přepočtu předpovědí a pravděpodobností perturbedních funkcí. V poznámkových blocích Jupyter se v současné době podporuje při spuštění jako widget pomocí sady SDK.
Další kroky
Techniky interpretace modelů ve službě Azure Machine Learning
Podívejte se na ukázkové poznámkové bloky interpretovatelnosti ve službě Azure Machine Learning