Použití služby Azure Machine Learning s opensourcovým balíčkem Fairlearn k posouzení spravedlnosti modelů ML (Preview)
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto průvodci postupy se naučíte používat opensourcový balíček Pythonu Fairlearn se službou Azure Machine Learning k provádění následujících úloh:
- Vyhodnoťte nestrannost předpovědí modelu. Další informace o nestrannosti ve strojovém učení najdete v článku o nestrannosti strojového učení.
- Nahrajte, vypíšete a stáhnete přehledy posouzení nestrannosti do/z studio Azure Machine Learning.
- Podívejte se na řídicí panel posouzení nestrannosti v studio Azure Machine Learning pro interakci s přehledy o nestrannosti vašich modelů.
Poznámka:
Posouzení nestrannosti není čistě technické cvičení. Tento balíček vám může pomoct vyhodnotit nestrannost modelu strojového učení, ale jenom vy můžete nakonfigurovat a učinit rozhodnutí ohledně toho, jak model funguje. I když tento balíček pomáhá identifikovat kvantitativní metriky pro posouzení nestrannosti, vývojáři modelů strojového učení musí také provést kvalitativní analýzu, která vyhodnotí nestrannost vlastních modelů.
Důležité
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti.
Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Azure Machine Learning Fairness SDK
Sada Azure Machine Learning Fair Learning SDK azureml-contrib-fairnessintegruje opensourcový balíček Pythonu Fairlearn v rámci služby Azure Machine Learning. Další informace o integraci Fairlearnu ve službě Azure Machine Learning najdete v těchto ukázkových poznámkových blocích. Další informace o fairlearnu najdete v ukázkové příručce a ukázkových poznámkových blocích.
K instalaci azureml-contrib-fairness a fairlearn balíčků použijte následující příkazy:
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
Novější verze Fairlearn by také měly fungovat v následujícím ukázkovém kódu.
Nahrání přehledů o nestrannosti pro jeden model
Následující příklad ukazuje, jak používat balíček nestrannosti. Nahrajeme přehledy o nestrannosti modelu do služby Azure Machine Learning a na řídicím panelu posouzení nestrannosti uvidíme v studio Azure Machine Learning.
Vytrénujte ukázkový model v Jupyter Notebooku.
Pro datovou sadu používáme známou datovou sadu pro sčítání dospělých, kterou načítáme z OpenML. Předstírat, že máme problém s rozhodnutím o půjčce s popiskem, který označuje, jestli jednotlivá splátka předchozí půjčky. Model vytrénujeme, abychom předpověděli, jestli dříve nezídaní jednotlivci budou splácet půjčku. Takový model se může použít při rozhodování o půjčkách.
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})Přihlaste se ke službě Azure Machine Learning a zaregistrujte svůj model.
Řídicí panel spravedlnosti se může integrovat s registrovanými nebo neregistrovanými modely. Zaregistrujte svůj model ve službě Azure Machine Learning pomocí následujících kroků:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)Předkompute metriky nestrannosti.
Vytvořte slovník řídicího
metricspanelu pomocí balíčku Fairlearn. Metoda_create_group_metric_setmá podobné argumenty jako konstruktor řídicího panelu s tím rozdílem, že citlivé funkce se předávají jako slovník (aby se zajistilo, že jsou názvy k dispozici). Při volání této metody musíme také určit typ předpovědi (v tomto případě binární klasifikace).# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Nahrajte předem připravené metriky nestrannosti.
Teď importujte
azureml.contrib.fairnessbalíček, který má provést nahrání:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idVytvořte experiment, pak spusťte a nahrajte do něj řídicí panel:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Kontrola řídicího panelu nestrannosti z studio Azure Machine Learning
Pokud dokončíte předchozí kroky (nahrání vygenerovaných přehledů o nestrannosti do služby Azure Machine Learning), můžete řídicí panel nestrannosti zobrazit v studio Azure Machine Learning. Tento řídicí panel je stejný řídicí panel vizualizace, který je součástí Fairlearnu a umožňuje analyzovat rozdíly mezi podskupinami citlivých funkcí (např. muž vs. žena). Pokud chcete získat přístup k řídicímu panelu vizualizace v studio Azure Machine Learning, postupujte následovně:
- Podokno Úlohy (Preview)
- Výběrem možnosti Úlohy v levém podokně zobrazíte seznam experimentů, které jste spustili ve službě Azure Machine Learning.
- Výběrem konkrétního experimentu zobrazíte všechna spuštění v daném experimentu.
- Vyberte spuštění a pak na kartě Nestrannost přejděte na řídicí panel vizualizace vysvětlení.
- Po přistání na kartě Nestrannost klikněte na ID nestrannosti z nabídky vpravo.
- Nakonfigurujte řídicí panel výběrem citlivého atributu, metriky výkonu a metriky spravedlnosti, které vás zajímají, abyste se mohli dostat na stránku posouzení nestrannosti.
- Přepněte typ grafu z jednoho na druhý, abyste mohli sledovat poškození přidělení i kvalitu škod služeb .
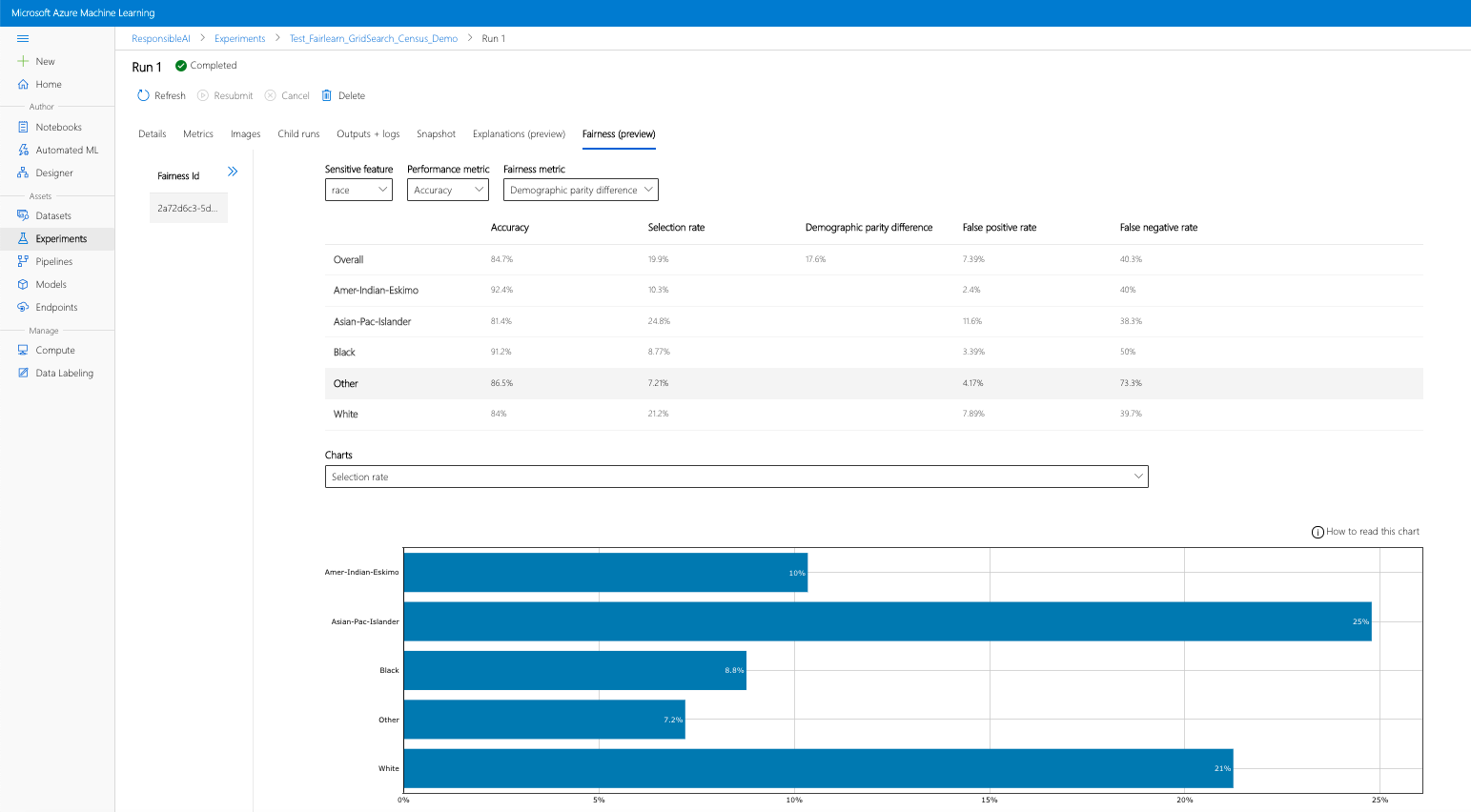
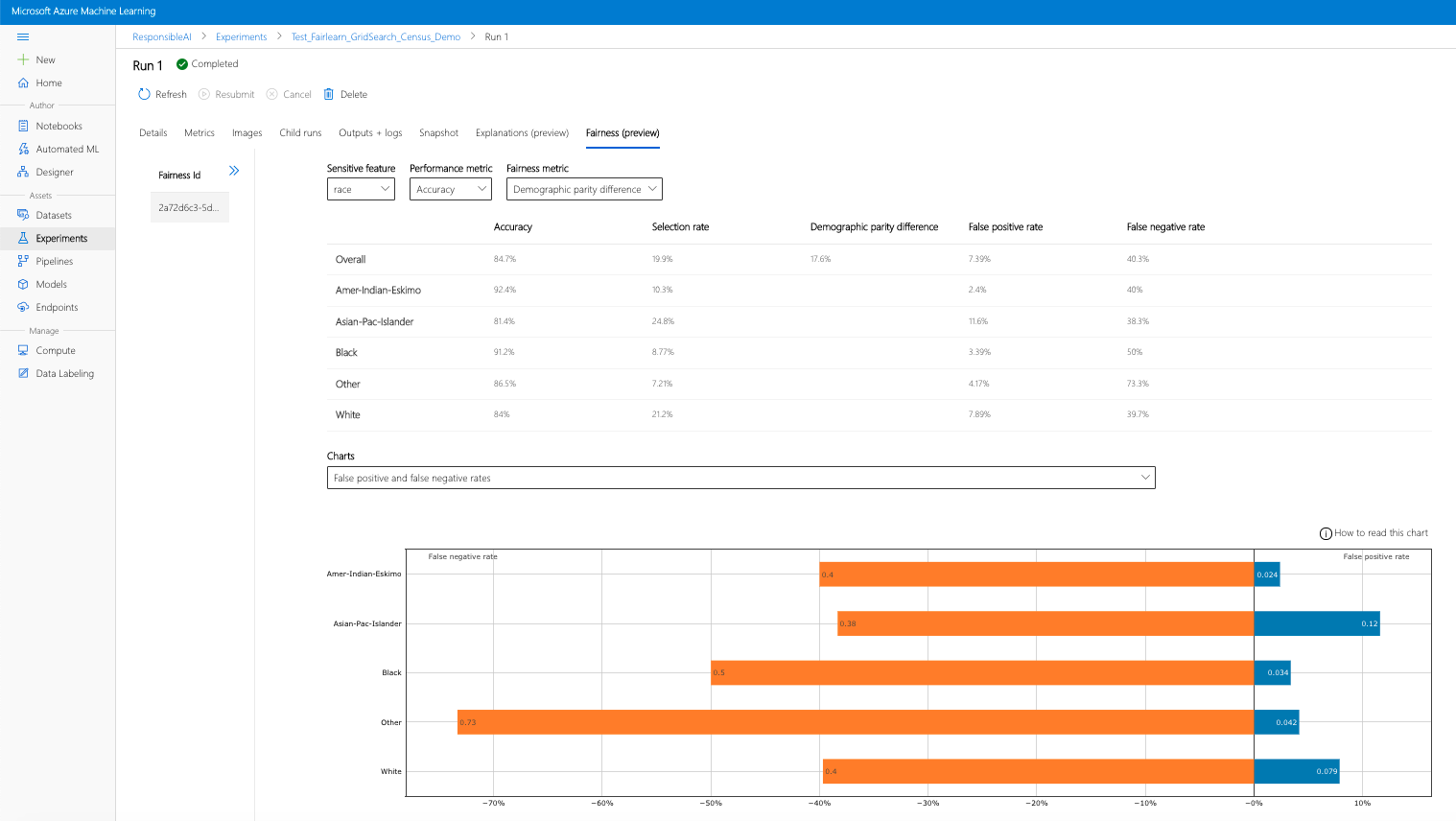
- Podokno Modely
- Pokud jste původní model zaregistrovali podle předchozích kroků, můžete ho zobrazit výběrem možnosti Modely v levém podokně.
- Vyberte model a pak kartu Nestrannost zobrazte řídicí panel vizualizace vysvětlení.
Další informace o řídicím panelu vizualizace a jeho obsahu najdete v uživatelské příručce fairlearnu.


Nahrání přehledů o nestrannosti pro více modelů
Pokud chcete porovnat více modelů a zjistit, jak se jejich posouzení nestrannosti liší, můžete předat řídicímu panelu vizualizace více než jeden model a porovnat jejich kompromisy mezi výkonem a nestranností.
Trénování modelů:
Teď vytvoříme druhý klasifikátor založený na estimátoru Support Vector Machine a nahrajeme slovník řídicího panelu nestrannosti pomocí balíčku Fairlearn
metrics. Předpokládáme, že dříve natrénovaný model je stále dostupný.# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)Registrace modelů
V dalším kroku zaregistrujte oba modely ve službě Azure Machine Learning. Pro usnadnění práci uložte výsledky do slovníku, který mapuje
idregistrovaný model (řetězec vename:versionformátu) na samotný prediktor:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictorMístní načtení řídicího panelu nestrannosti
Než nahrajete přehledy o nestrannosti ve službě Azure Machine Learning, můžete tyto předpovědi prozkoumat na řídicím panelu Spravedlnosti vyvolaný místně.
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)Předkompute metriky nestrannosti.
Vytvořte slovník řídicího
metricspanelu pomocí balíčku Fairlearn.sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Nahrajte předem připravené metriky nestrannosti.
Teď importujte
azureml.contrib.fairnessbalíček, který má provést nahrání:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idVytvořte experiment, pak spusťte a nahrajte do něj řídicí panel:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Podobně jako v předchozí části můžete postupovat podle jedné z výše popsaných cest (prostřednictvím experimentů nebo modelů) v studio Azure Machine Learning pro přístup k řídicímu panelu vizualizace a porovnat tyto dva modely z hlediska nestrannosti a výkonu.
Nahrání nezmírněných a zmírnit přehledy o nestrannosti
Můžete použít algoritmy pro zmírnění rizik fairlearnu, porovnat jejich vygenerované zmírněné modely s původním nemitigovaným modelem a procházet kompromisy mezi výkonem a nestranností mezi porovnávanými modely.
Podívejte se na příklad, který ukazuje použití algoritmu pro zmírnění potíží s vyhledáváním v mřížce (který vytvoří kolekci zmírněných modelů s různými kompromisy za nestrannost a výkon), podívejte se na tento ukázkový poznámkový blok.
Nahrání přehledů o nestrannosti více modelů v jednom spuštění umožňuje porovnání modelů s ohledem na nestrannost a výkon. Kliknutím na libovolný z modelů zobrazených v grafu porovnání modelů zobrazíte podrobné přehledy o nestrannosti konkrétního modelu.

Další kroky
Další informace o nestrannosti modelu
Podívejte se na ukázkové poznámkové bloky spravedlnosti ve službě Azure Machine Learning