V tomto článku se dozvíte, jak pomocí Open Neural Network Exchange (ONNX) vytvářet předpovědi na modelech počítačového zpracování obrazu vygenerovaných z automatizovaného strojového učení (AutoML) ve službě Azure Machine Learning.
Pokud chcete pro predikce použít ONNX, musíte:
Stáhněte si soubory modelu ONNX z trénovacího spuštění AutoML.
Seznamte se se vstupy a výstupy modelu ONNX.
Předzpracuje data tak, aby byla v požadovaném formátu pro vstupní obrázky.
Proveďte odvozování s modulem runtime ONNX pro Python.
Vizualizujte předpovědi pro úlohy detekce objektů a segmentace instancí.
ONNX je otevřený standard pro modely strojového učení a hlubokého učení. Umožňuje importovat a exportovat model (interoperabilitu) mezi oblíbenými architekturami AI. Další podrobnosti najdete v projektu ONNX Na GitHubu.
ONNX Runtime je opensourcový projekt, který podporuje odvozování mezi platformami. MODUL RUNTIME ONNX poskytuje rozhraní API napříč programovacími jazyky (včetně Pythonu, C++, C#, C, Javy a JavaScriptu). Tato rozhraní API můžete použít k odvozování vstupních imagí. Po exportu modelu do formátu ONNX můžete tato rozhraní API použít v libovolném programovacím jazyce, který váš projekt potřebuje.
V této příručce se dozvíte, jak pomocí rozhraní Python API pro modul RUNTIME ONNX vytvářet předpovědi obrázků pro oblíbené úlohy zpracování obrazu. Tyto exportované modely ONNX můžete použít napříč jazyky.
Požadavky
Získejte model počítačového zpracování obrazu trénovaný autoML pro některou z podporovaných úloh obrázků: klasifikaci, detekci objektů nebo segmentaci instancí. Přečtěte si další informace o podpoře AutoML pro úlohy počítačového zpracování obrazu.
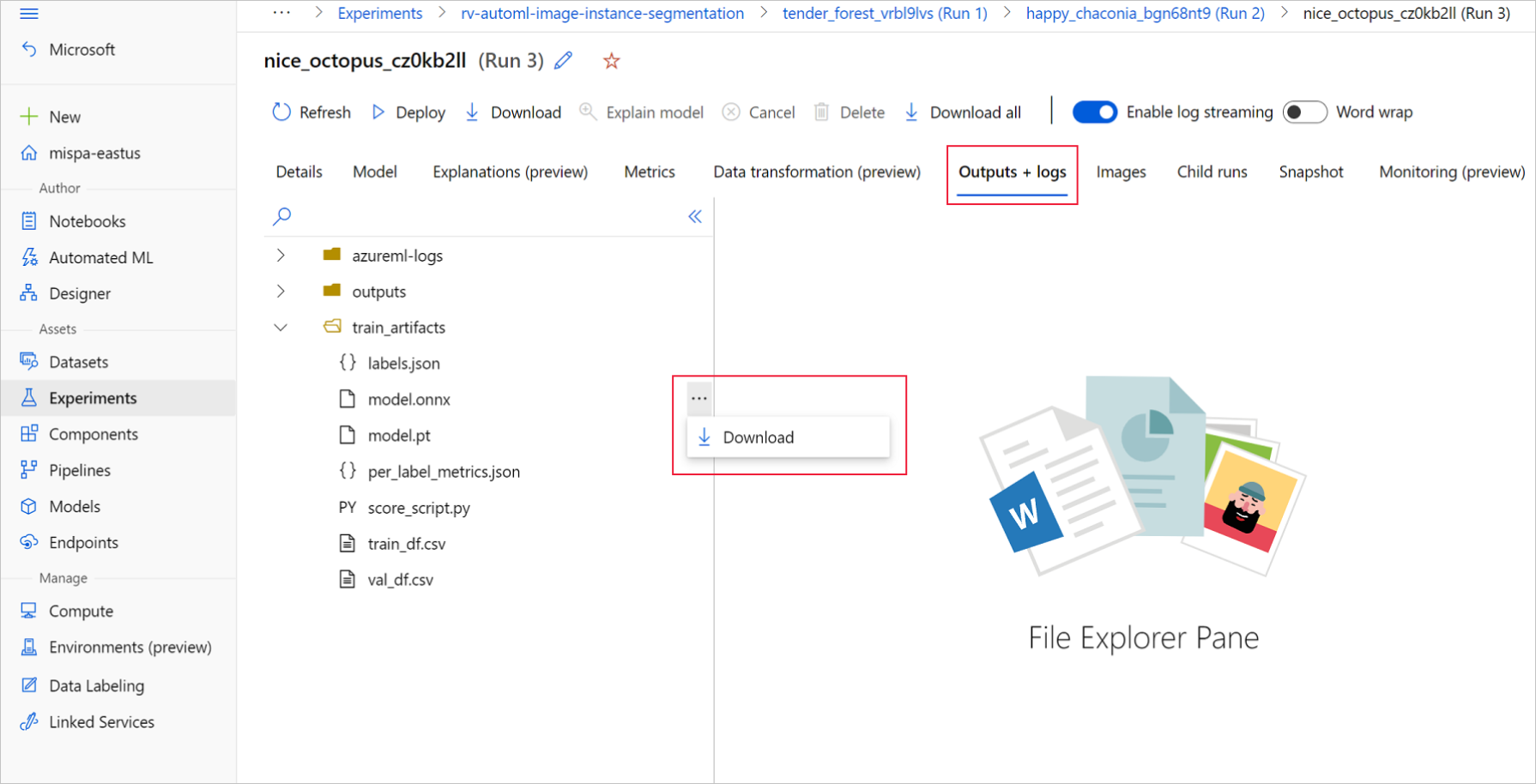
Soubory modelu ONNX můžete stáhnout z autoML spuštění pomocí uživatelského rozhraní studio Azure Machine Learning nebo sady Azure Machine Learning Python SDK. Doporučujeme stáhnout sadu SDK s názvem experimentu a ID nadřazeného spuštění.
Studio Azure Machine Learning
V studio Azure Machine Learning přejděte na experiment pomocí hypertextového odkazu na experiment vygenerovaný v poznámkovém bloku pro trénování nebo výběrem názvu experimentu na kartě Experimenty v části Prostředky. Pak vyberte nejlepší podřízené spuštění.
V rámci nejlepšího podřízeného spuštění přejděte na výstupy a protokoly>train_artifacts.Pomocí tlačítka Stáhnout ručně stáhněte následující soubory:
labels.json: Soubor, který obsahuje všechny třídy nebo popisky v trénovací datové sadě.
model.onnx: Model ve formátu ONNX.
Uložte stažené soubory modelu do adresáře. Příklad v tomto článku používá adresář ./automl_models .
Sada Azure Machine Learning Python SDK
Pomocí sady SDK můžete vybrat nejlepší podřízený běh (podle primární metriky) s názvem experimentu a ID nadřazeného spuštění. Pak si můžete stáhnout soubory labels.json a model.onnx .
Následující kód vrátí nejlepší podřízené spuštění na základě relevantní primární metriky.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
mlflow_client = MlflowClient()
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
# Enter details of your Azure Machine Learning workspace
subscription_id = ''
resource_group = ''
workspace_name = ''
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
import mlflow
from mlflow.tracking.client import MlflowClient
# Obtain the tracking URL from MLClient
MLFLOW_TRACKING_URI = ml_client.workspaces.get(
name=ml_client.workspace_name
).mlflow_tracking_uri
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Specify the job name
job_name = ''
# Get the parent run
mlflow_parent_run = mlflow_client.get_run(job_name)
best_child_run_id = mlflow_parent_run.data.tags['automl_best_child_run_id']
# get the best child run
best_run = mlflow_client.get_run(best_child_run_id)
Stáhněte si soubor labels.json, který obsahuje všechny třídy a popisky v trénovací datové sadě.
local_dir = './automl_models'
if not os.path.exists(local_dir):
os.mkdir(local_dir)
labels_file = mlflow_client.download_artifacts(
best_run.info.run_id, 'train_artifacts/labels.json', local_dir
)
AutoML pro obrázky ve výchozím nastavení podporuje dávkové bodování pro klasifikaci. Modely ONNX pro detekci objektů a segmentaci instancí ale nepodporují dávkové odvozování. V případě odvozování dávek pro detekci objektů a segmentaci instancí použijte následující postup k vygenerování modelu ONNX pro požadovanou velikost dávky. Modely vygenerované pro konkrétní velikost dávky nefungují u jiných velikostí dávek.
Stáhněte soubor prostředí Conda a vytvořte objekt prostředí, který se má použít s úlohou příkazu.
# Download conda file and define the environment
conda_file = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs/conda_env_v_1_0_0.yml", local_dir
)
from azure.ai.ml.entities import Environment
env = Environment(
name="automl-images-env-onnx",
description="environment for automl images ONNX batch model generation",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04",
conda_file=conda_file,
)
Pokud chcete získat hodnoty argumentů potřebné k vytvoření modelu dávkového bodování, projděte si skripty bodování vygenerované ve složce výstupů trénovacích běhů AutoML. Pro nejlepší podřízené spuštění použijte hodnoty hyperparametrů dostupné v proměnné nastavení modelu v souboru bodování.
Pro klasifikaci obrázků s více třídami podporuje vygenerovaný model ONNX pro nejlepší podřízené spuštění ve výchozím nastavení dávkové vyhodnocování. Proto nejsou pro tento typ úlohy potřeba žádné argumenty specifické pro model a můžete přeskočit na část Načíst popisky a soubory modelu ONNX.
Pro klasifikaci obrázků s více popisky podporuje vygenerovaný model ONNX pro nejlepší podřízené spuštění ve výchozím nastavení dávkové vyhodnocování. Proto nejsou pro tento typ úlohy potřeba žádné argumenty specifické pro model a můžete přeskočit na část Načíst popisky a soubory modelu ONNX.
inputs = {'model_name': 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
inputs = {'model_name': 'yolov5', # enter the yolo model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 640, # enter the height of input to ONNX model
'width_onnx': 640, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'img_size': 640, # image size for inference
'model_size': 'small', # size of the yolo model
'box_score_thresh': 0.1, # threshold to return proposals with a classification score > box_score_thresh
'box_iou_thresh': 0.5
}
inputs = {'model_name': 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-instance-segmentation',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
Stáhněte a zachovejte ONNX_batch_model_generator_automl_for_images.py soubor v aktuálním adresáři a odešlete skript. Pomocí následující úlohy příkazu odešlete skript ONNX_batch_model_generator_automl_for_images.py dostupný v úložišti GitHubu s příklady azureml a vygenerujte model ONNX konkrétní velikosti dávky. V následujícím kódu se vytrénované prostředí modelu používá k odeslání tohoto skriptu pro vygenerování a uložení modelu ONNX do výstupního adresáře.
Pro klasifikaci obrázků s více třídami podporuje vygenerovaný model ONNX pro nejlepší podřízené spuštění ve výchozím nastavení dávkové vyhodnocování. Proto nejsou pro tento typ úlohy potřeba žádné argumenty specifické pro model a můžete přeskočit na část Načíst popisky a soubory modelu ONNX.
Pro klasifikaci obrázků s více popisky podporuje vygenerovaný model ONNX pro nejlepší podřízené spuštění ve výchozím nastavení dávkové vyhodnocování. Proto nejsou pro tento typ úlohy potřeba žádné argumenty specifické pro model a můžete přeskočit na část Načíst popisky a soubory modelu ONNX.
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-rcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --img_size ${{inputs.img_size}} --model_size ${{inputs.model_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_iou_thresh ${{inputs.box_iou_thresh}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-maskrcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
Po vygenerování dávkového modelu si ho buď stáhněte z výstupů a protokolů>ručně prostřednictvím uživatelského rozhraní, nebo použijte následující metodu:
batch_size = 8 # use the batch size used to generate the model
returned_job_run = mlflow_client.get_run(returned_job.name)
# Download run's artifacts/outputs
onnx_model_path = mlflow_client.download_artifacts(
returned_job_run.info.run_id, 'outputs/model_'+str(batch_size)+'.onnx', local_dir
)
Po stažení modelu použijete balíček PYTHON modulu runtime ONNX k odvozování pomocí souboru model.onnx . Pro demonstrační účely tento článek používá datové sady z návodu k přípravě datových sad obrázků pro jednotlivé úlohy zpracování obrazu.
Vytrénovali jsme modely pro všechny úlohy zpracování obrazu pomocí příslušných datových sad, abychom ukázali odvození modelu ONNX.
Načtení popisků a souborů modelů ONNX
Následující fragment kódu načte labels.json, kde jsou názvy tříd seřazeny. To znamená, že pokud model ONNX predikuje ID popisku jako 2, pak odpovídá názvu popisku zadanému při třetím indexu v souboru labels.json .
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ", str(e))
Získání očekávaných vstupních a výstupních podrobností pro model ONNX
Pokud máte model, je důležité znát některé podrobnosti specifické pro konkrétní model a úlohu. Tyto podrobnosti zahrnují počet vstupů a počet výstupů, očekávaný vstupní obrazec nebo formát pro předběžné zpracování obrázku a výstupní obrazec, takže znáte výstupy specifické pro model nebo výstupy specifické pro úlohy.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Očekávané vstupní a výstupní formáty pro model ONNX
Každý model ONNX má předdefinovanou sadu vstupních a výstupních formátů.
Tento příklad použije model natrénovaný na datové sadě fridgeObjects s 134 obrázky a 4 třídami/popisky k vysvětlení odvozování modelu ONNX. Další informace o trénování úlohy klasifikace obrázků najdete v poznámkovém bloku klasifikace obrázků s více třídami.
Vstupní formát
Vstup je předzpracovaná image.
Název vstupu
Vstupní obrazec
Input type
Popis
input1
(batch_size, num_channels, height, width)
ndarray(float)
Vstup je předzpracovaný obrázek s obrazcem (1, 3, 224, 224) pro velikost dávky 1 a výškou a šířkou 224. Tato čísla odpovídají hodnotám použitým crop_size v příkladu trénování.
Výstupní formát
Výstup je pole logit pro všechny třídy/popisky.
Název výstupu
Výstupní obrazec
Typ výstupu
Popis
výstup 1
(batch_size, num_classes)
ndarray(float)
Model vrátí logits (bez softmax). Například pro dávkové třídy 1 a 4 vrátí (1, 4)hodnotu .
Tento příklad používá model natrénovaný na datové sadě multi-label fridgeObjects s 128 obrázky a 4 třídami/popisky k vysvětlení odvozování modelu ONNX. Další informace o trénování modelu pro klasifikaci obrázků s více popisky najdete v poznámkovém bloku klasifikace obrázků s více popisky.
Vstupní formát
Vstup je předzpracovaná image.
Název vstupu
Vstupní obrazec
Input type
Popis
input1
(batch_size, num_channels, height, width)
ndarray(float)
Vstup je předzpracovaný obrázek s obrazcem (1, 3, 224, 224) pro velikost dávky 1 a výškou a šířkou 224. Tato čísla odpovídají hodnotám použitým crop_size v příkladu trénování.
Výstupní formát
Výstup je pole logit pro všechny třídy/popisky.
Název výstupu
Výstupní obrazec
Typ výstupu
Popis
výstup 1
(batch_size, num_classes)
ndarray(float)
Model vrátí logits (bez sigmoid). Například pro dávkové třídy 1 a 4 vrátí (1, 4)hodnotu .
Tento příklad detekce objektů používá model natrénovaný na datové sadě detekce ledniceObjects 128 obrázků a 4 tříd/popisků k vysvětlení odvozování modelu ONNX. Tento příklad trénuje modely Rychlejší R-CNN, které demonstrují kroky odvozování. Další informace o trénovacích modelech rozpoznávání objektů najdete v poznámkovém bloku pro detekci objektů.
Vstupní formát
Vstup je předzpracovaná image.
Název vstupu
Vstupní obrazec
Input type
Popis
Vstup
(batch_size, num_channels, height, width)
ndarray(float)
Vstup je předzpracovaný obrázek s obrazcem (1, 3, 600, 800) pro velikost dávky 1 a výškou 600 a šířkou 800.
Výstupní formát
Výstupem je řazená kolekce output_names členů a predikce. output_names Tady jsou predictions seznamy s délkou 3*batch_size každé. Pro rychlejší pořadí výstupů R-CNN jsou rámečky, popisky a skóre, zatímco výstupy sítnice jsou rámečky, skóre, popisky.
Název výstupu
Výstupní obrazec
Typ výstupu
Popis
output_names
(3*batch_size)
Seznam klíčů
Pro velikost dávky 2 je output_names['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Seznam ndarray(float)
Pro velikost dávky 2 má predictions tvar [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. Zde hodnoty v každém indexu odpovídají stejnému indexu v output_names.
Následující tabulka popisuje pole, popisky a skóre vrácené pro každou ukázku v dávce obrázků.
Název
Tvar
Typ
Popis
Krabice
(n_boxes, 4), kde má každá skříňka x_min, y_min, x_max, y_max
ndarray(float)
Model vrátí n políček s jejich souřadnicemi vlevo nahoře a vpravo dole.
Popisky
(n_boxes)
ndarray(float)
Popisek nebo ID třídy objektu v každém poli
Skóre
(n_boxes)
ndarray(float)
Skóre spolehlivosti objektu v každém poli
Tento příklad detekce objektů používá model natrénovaný na datové sadě detekce ledniceObjects 128 obrázků a 4 tříd/popisků k vysvětlení odvozování modelu ONNX. Tento příklad trénuje modely YOLO, aby demonstrovaly kroky odvozování. Další informace o trénovacích modelech rozpoznávání objektů najdete v poznámkovém bloku pro detekci objektů.
Vstupní formát
Vstup je předzpracovaný obrázek s obrazcem (1, 3, 640, 640) pro velikost dávky 1 a výškou a šířkou 640. Tato čísla odpovídají hodnotám použitým v příkladu trénování.
Název vstupu
Vstupní obrazec
Input type
Popis
Vstup
(batch_size, num_channels, height, width)
ndarray(float)
Vstup je předzpracovaný obrázek s obrazcem (1, 3, 640, 640) pro velikost dávky 1 a výškou 640 a šířkou 640.
Výstupní formát
Predikce modelu ONNX obsahují více výstupů. První výstup je potřeba k provedení potlačení nonmax pro detekci. Pro snadné použití automatizované strojové učení zobrazí výstupní formát po kroku následného zpracování NMS. Výstup po NMS je seznam polí, popisků a skóre pro každou ukázku v dávce.
Název výstupu
Výstupní obrazec
Typ výstupu
Popis
Výstup
(batch_size)
Seznam ndarray(float)
Model vrací detekce krabic pro každou ukázku v dávce.
Každá buňka v seznamu označuje detekci vzorku s obrazcem (n_boxes, 6), kde má každý rámeček x_min, y_min, x_max, y_max, confidence_score, class_id.
V tomto příkladu segmentace instance použijete model Mask R-CNN, který byl natrénován na datové sadě fridgeObjects s 128 obrázky a 4 třídami/popisky k vysvětlení odvozování modelu ONNX. Další informace o trénování modelu segmentace instance najdete v poznámkovém bloku segmentace instance.
Důležité
Pro úlohy segmentace instance se podporuje pouze maska R-CNN. Vstupní a výstupní formáty jsou založené pouze na maskování sítě R-CNN.
Vstupní formát
Vstup je předzpracovaná image. Model ONNX pro Mask R-CNN byl exportován pro práci s obrázky různých obrazců. Pokud chcete dosáhnout lepšího výkonu, doporučujeme změnit jejich velikost na pevnou velikost, která je konzistentní s trénovacími velikostmi obrázků.
Název vstupu
Vstupní obrazec
Input type
Popis
Vstup
(batch_size, num_channels, height, width)
ndarray(float)
Vstup je předzpracovaný obrázek s obrazcem (1, 3, input_image_height, input_image_width) pro velikost dávky 1 a výškou a šířkou podobnou vstupnímu obrázku.
Výstupní formát
Výstupem je řazená kolekce output_names členů a predikce. output_names Tady jsou predictions seznamy s délkou 4*batch_size každé.
Název výstupu
Výstupní obrazec
Typ výstupu
Popis
output_names
(4*batch_size)
Seznam klíčů
Pro velikost dávky 2 je output_names['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Seznam ndarray(float)
Pro velikost dávky 2 má predictions tvar [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. Zde hodnoty v každém indexu odpovídají stejnému indexu v output_names.
Název
Tvar
Typ
Popis
Krabice
(n_boxes, 4), kde má každá skříňka x_min, y_min, x_max, y_max
ndarray(float)
Model vrátí n políček s jejich souřadnicemi vlevo nahoře a vpravo dole.
Popisky
(n_boxes)
ndarray(float)
Popisek nebo ID třídy objektu v každém poli
Skóre
(n_boxes)
ndarray(float)
Skóre spolehlivosti objektu v každém poli
Masky
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Masky (mnohoúhelníky) zjištěných objektů s výškou obrazce a šířkou vstupního obrázku
Proveďte následující kroky předběžného zpracování pro odvozování modelu ONNX:
Převeďte obrázek na RGB.
Změňte velikost obrázku na valid_resize_size hodnoty, valid_resize_size které odpovídají hodnotám použitým při transformaci ověřovací datové sady během trénování. Výchozí hodnota je valid_resize_size 256.
Na střed oříznout obrázek na height_onnx_crop_size a width_onnx_crop_size. valid_crop_size Odpovídá výchozí hodnotě 224.
Změňte HxWxC na CxHxW.
Převeďte na typ float.
Normalizuje se pomocí imagí mean = [0.485, 0.456, 0.406] a .std = [0.229, 0.224, 0.225]
Pokud jste pro hyperparametryvalid_resize_size a valid_crop_size během trénování zvolili jiné hodnoty, měly by se tyto hodnoty použít.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
S PyTorchem
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Proveďte následující kroky předběžného zpracování pro odvozování modelu ONNX. Tento postup je stejný pro klasifikaci obrázků ve více třídách.
Převeďte obrázek na RGB.
Změňte velikost obrázku na valid_resize_size hodnoty, valid_resize_size které odpovídají hodnotám použitým při transformaci ověřovací datové sady během trénování. Výchozí hodnota je valid_resize_size 256.
Na střed oříznout obrázek na height_onnx_crop_size a width_onnx_crop_size. To odpovídá valid_crop_size výchozí hodnotě 224.
Změňte HxWxC na CxHxW.
Převeďte na typ float.
Normalizuje se pomocí imagí mean = [0.485, 0.456, 0.406] a .std = [0.229, 0.224, 0.225]
Pokud jste pro hyperparametryvalid_resize_size a valid_crop_size během trénování zvolili jiné hodnoty, měly by se tyto hodnoty použít.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
S PyTorchem
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Pro detekci objektů s architekturou Rychlejší R-CNN postupujte podle stejných kroků předzpracování jako klasifikace obrázků s výjimkou oříznutí obrázku. Můžete změnit velikost obrázku s výškou 600 a šířkou 800. Očekávanou výšku a šířku vstupu můžete získat následujícím kódem.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Pro detekci objektů s architekturou YOLO postupujte podle stejných kroků předzpracování jako klasifikace obrázků s výjimkou oříznutí obrázku. Můžete změnit velikost obrázku s výškou 600 a šířkou 800a získat očekávanou výšku a šířku vstupu pomocí následujícího kódu.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Důležité
Pro úlohy segmentace instance se podporuje pouze maska R-CNN. Kroky předběžného zpracování jsou založeny pouze na masce R-CNN.
Proveďte následující kroky předběžného zpracování pro odvozování modelu ONNX:
Převeďte obrázek na RGB.
Změňte velikost obrázku.
Změňte HxWxC na CxHxW.
Převeďte na typ float.
Normalizuje se pomocí imagí mean = [0.485, 0.456, 0.406] a .std = [0.229, 0.224, 0.225]
Pro resize_height a resize_width, můžete také použít hodnoty, které jste použili během trénování, ohraničené min_size a max_sizehyperparametry pro Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Odvozovat s modulem runtime ONNX
Odvozování s modulem RUNTIME ONNX se pro každou úlohu počítačového zpracování obrazu liší.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
Model segmentace instance předpovídá pole, popisky, skóre a masky. ONNX vypíše predikovanou masku na instanci spolu s odpovídajícími ohraničujícími rámečky a skóre spolehlivosti třídy. V případě potřeby možná budete muset převést z binární masky na mnohoúhelník.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Pokud chcete získat skóre spolehlivosti klasifikace (pravděpodobnosti) pro každou třídu, použijte softmax() předpovězené hodnoty. Pak bude predikce třídou s nejvyšší pravděpodobností.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Tento krok se liší od klasifikace s více třídami. Pokud chcete získat skóre spolehlivosti pro klasifikaci obrázků s více popisky, musíte použít sigmoid logits (výstup ONNX).
Bez PyTorchu
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
S PyTorchem
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
U klasifikace s více třídami a více popisky můžete postupovat podle stejných kroků uvedených dříve pro všechny podporované architektury modelů v AutoML.
Pro detekci objektů jsou předpovědi automaticky v měřítku height_onnx, . width_onnx Chcete-li transformovat souřadnice predikovaného rámečku na původní dimenze, můžete implementovat následující výpočty.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Další možností je použít následující kód ke škálování rozměrů krabic, které mají být v rozsahu [0, 1]. Tímto způsobem lze souřadnice rámečku vynásobit s původní výškou a šířkou obrázků s odpovídajícími souřadnicemi (jak je popsáno v části vizualizovat předpovědi) a získat pole v původních rozměrech obrázku.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
Následující kód vytvoří pole, popisky a skóre. Pomocí těchto podrobností ohraničujícího rámečku proveďte stejné kroky následného zpracování jako u modelu Rychlejší R-CNN.
Můžete použít buď kroky uvedené pro Rychlejší R-CNN (v případě masky R-CNN, každý vzorek má čtyři prvky pole, popisky, skóre, masky) nebo vizualizovat část predikce pro segmentaci instancí.
 Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)