Zobrazení trénovacího kódu pro model automatizovaného strojového učení
V tomto článku se dozvíte, jak zobrazit vygenerovaný trénovací kód z jakéhokoli vytrénovaného modelu automatizovaného strojového učení.
Generování kódu pro automatizované vytrénované modely ML umožňuje zobrazit následující podrobnosti, které automatizované strojové učení používá k trénování a sestavení modelu pro konkrétní spuštění.
- Předběžné zpracování dat
- Výběr algoritmu
- Extrakce příznaků
- Hyperparametry
Můžete vybrat libovolný automatizovaný vytrénovaný model ML, doporučený nebo podřízený běh a zobrazit vygenerovaný trénovací kód Pythonu, který tento konkrétní model vytvořil.
S trénovacím kódem vygenerovaného modelu můžete
- Zjistěte , jaký proces featurizace a hyperparametry algoritmus modelu používá.
- Sledujte, verze nebo audit natrénovaných modelů. Uložte kód s verzí, abyste mohli sledovat, jaký konkrétní trénovací kód se používá s modelem, který se má nasadit do produkčního prostředí.
- Přizpůsobte trénovací kód změnou hyperparametrů nebo použitím dovedností a zkušeností strojového učení a algoritmů a přetrénováním nového modelu pomocí přizpůsobeného kódu.
Následující diagram znázorňuje, že můžete vygenerovat kód pro automatizované experimenty ML se všemi typy úloh. Nejprve vyberte model. Vybraný model se zvýrazní, pak Azure Machine Learning zkopíruje soubory kódu použité k vytvoření modelu a zobrazí je do sdílené složky poznámkových bloků. Odtud můžete kód podle potřeby zobrazit a přizpůsobit.
Požadavky
Pracovní prostor služby Azure Machine Learning. Pokud chcete vytvořit pracovní prostor, přečtěte si téma Vytvoření prostředků pracovního prostoru.
Tento článek předpokládá určitou znalost nastavení experimentu automatizovaného strojového učení. Postupujte podle kurzu nebo návodu a podívejte se na hlavní vzory návrhu experimentů automatizovaného strojového učení.
Automatizované generování kódu ML je k dispozici pouze pro experimenty spouštěné na vzdálených cílových výpočetních objektech služby Azure Machine Learning. Generování kódu není podporováno pro místní spuštění.
Všechny automatizované strojové učení aktivované prostřednictvím studio Azure Machine Learning, SDKv2 nebo CLIv2 budou mít povolené generování kódu.
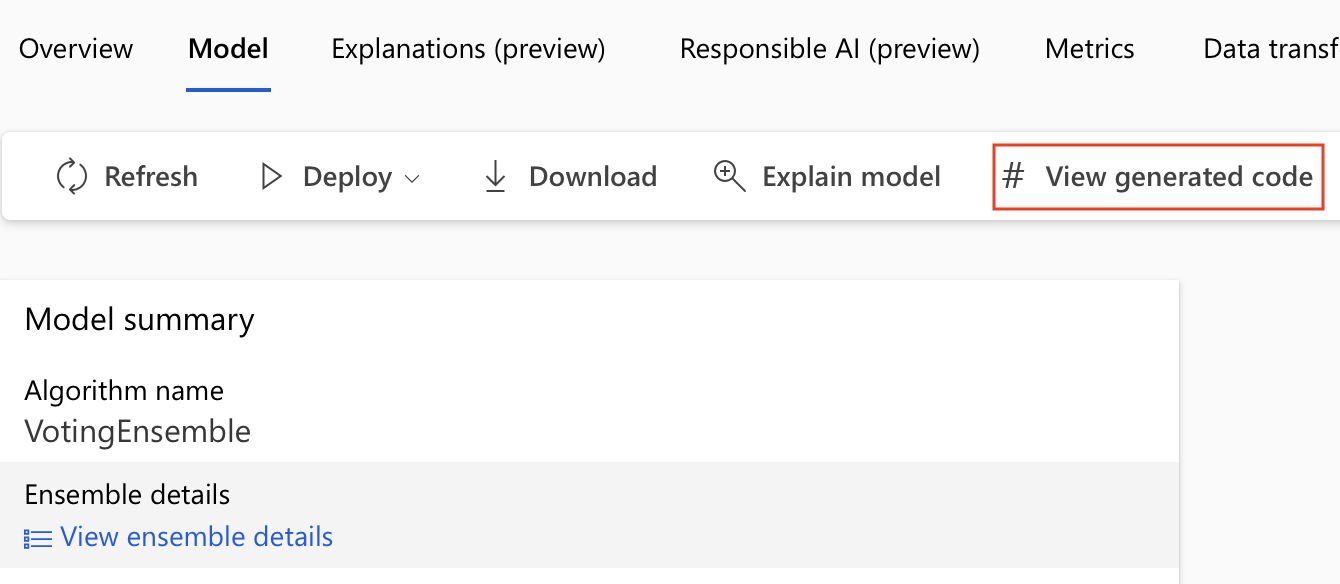
Získání vygenerovaného kódu a artefaktů modelu
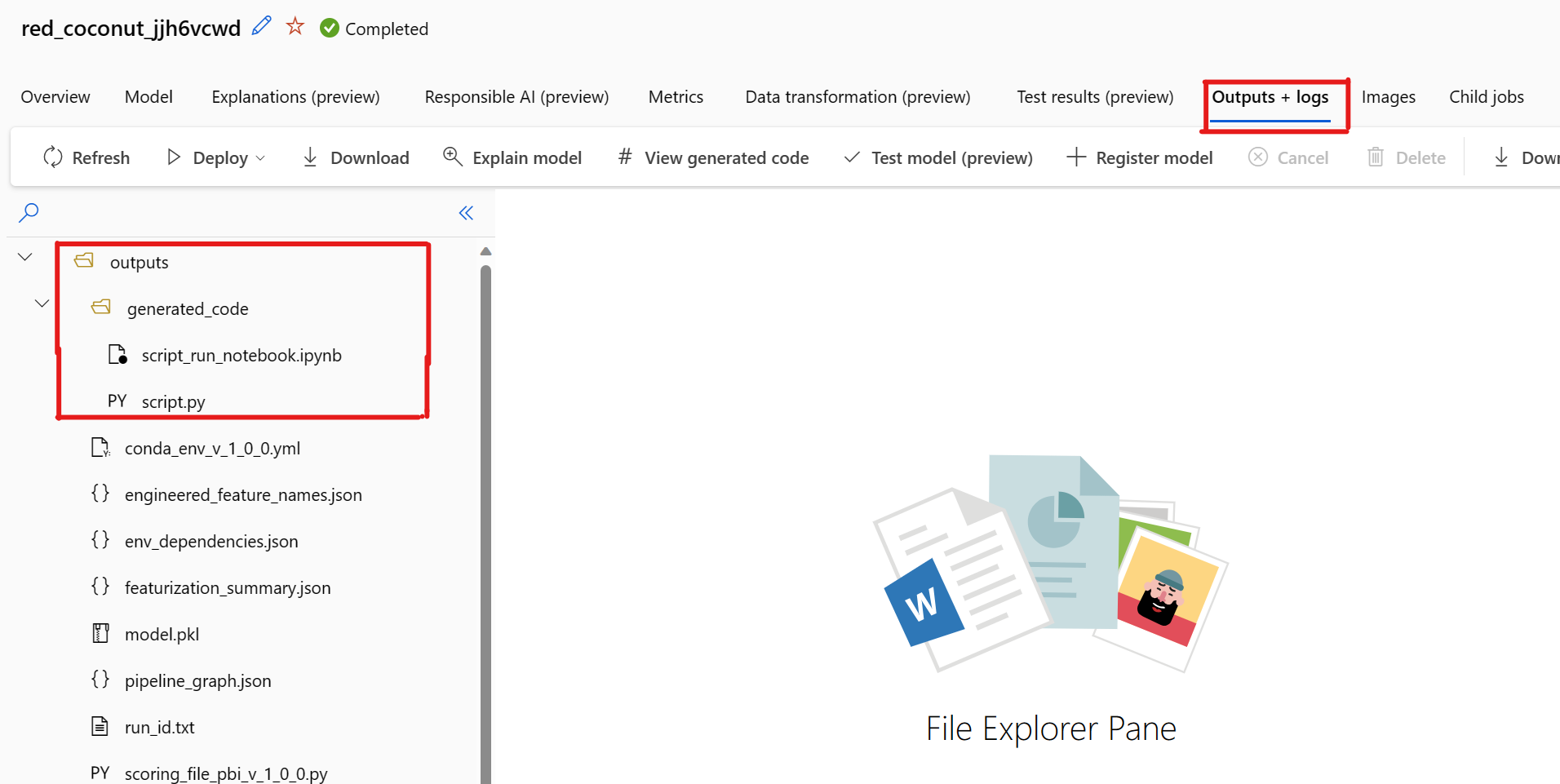
Ve výchozím nastavení každý automatizovaný model strojového učení vygeneruje po dokončení trénování svůj trénovací kód. Automatizované strojové učení uloží tento kód do experimentu outputs/generated_code pro tento konkrétní model. Můžete je zobrazit v uživatelském rozhraní studio Azure Machine Learning na kartě Výstupy a protokoly vybraného modelu.
script.py Toto je trénovací kód modelu, který pravděpodobně chcete analyzovat pomocí kroků featurizace, konkrétního použitého algoritmu a hyperparametrů.
poznámkový blok script_run_notebook.ipynb s kódem kotle pro spuštění trénovacího kódu modelu (script.py) ve službě Azure Machine Learning prostřednictvím služby Azure Machine Learning SDKv2.
Po dokončení automatizovaného trénování STROJOVÉho učení máte přístup k script.py souborům a script_run_notebook.ipynb souborům prostřednictvím uživatelského rozhraní studio Azure Machine Learning.
Uděláte to tak, že přejdete na kartu Modely na stránce nadřazeného spuštění experimentu automatizovaného strojového učení. Po výběru některého z natrénovaných modelů můžete vybrat tlačítko Zobrazit vygenerovaný kód . Toto tlačítko vás přesměruje na rozšíření portálu Poznámkové bloky , kde můžete zobrazit, upravit a spustit vygenerovaný kód pro daný vybraný model.
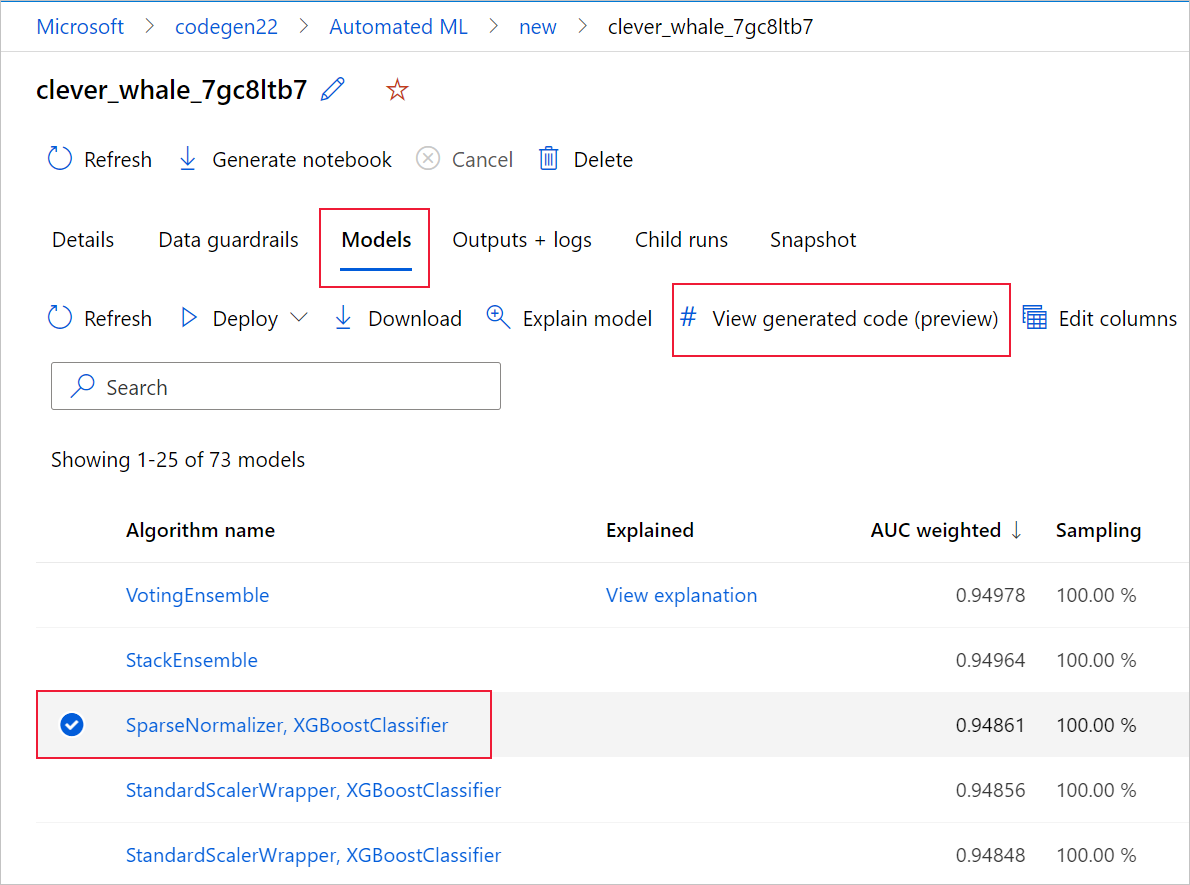
Po přechodu na stránku konkrétního podřízeného modelu můžete také získat přístup k vygenerovanému kódu modelu z horní části stránky podřízeného spuštění.
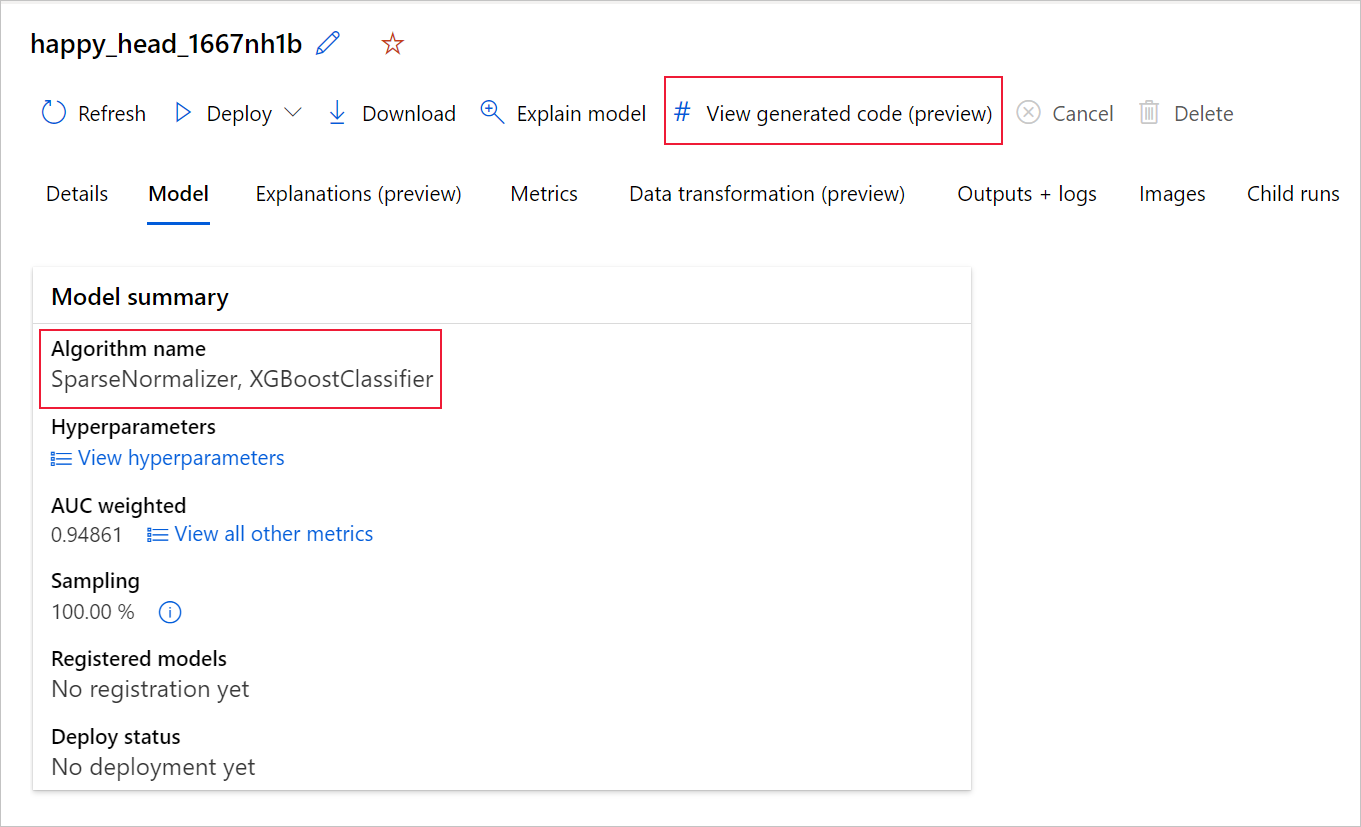
Pokud používáte Python SDKv2, můžete si také stáhnout "script.py" a "script_run_notebook.ipynb" načtením nejlepšího spuštění přes MLFlow a stažením výsledných artefaktů.
Omezení
Při výběru možnosti Zobrazit vygenerovaný kód je známý problém. Tato akce se nepodaří přesměrovat na portál Poznámkové bloky, pokud je úložiště za virtuální sítí. Jako alternativní řešení může uživatel ručně stáhnout script.py a soubory script_run_notebook.ipynb tak, že přejde na kartu Výstupy a protokoly ve složce výstupy>generated_code. Tyto soubory je možné nahrát ručně do složky poznámkových bloků a spustit je nebo upravit. Další informace o virtuálních sítích ve službě Azure Machine Learning najdete na tomto odkazu.
script.py
Soubor script.py obsahuje základní logiku potřebnou k trénování modelu pomocí dříve použitých hyperparametrů. I když se má spustit v kontextu spuštění skriptu Azure Machine Learning, s některými úpravami je možné trénovací kód modelu spustit i samostatně ve vlastním místním prostředí.
Skript lze zhruba rozdělit do několika následujících částí: načítání dat, příprava dat, featurizace dat, specifikace preprocesoru/algoritmu a trénování.
Načítání dat
Funkce get_training_dataset() načte dříve použitou datovou sadu. Předpokládá se, že se skript spustí ve skriptu Azure Machine Learning, který běží ve stejném pracovním prostoru jako původní experiment.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Při spuštění skriptu Run.get_context().experiment.workspace načte správný pracovní prostor. Pokud se však tento skript spouští uvnitř jiného pracovního prostoru nebo místně, musíte skript upravit tak, aby explicitně určil příslušný pracovní prostor.
Po načtení pracovního prostoru se původní datová sada načte podle ID. Jinou datovou sadu s přesně stejnou strukturou je možné zadat také pomocí ID nebo názvu s get_by_id() hodnotou nebo get_by_name(), v uvedeném pořadí. ID najdete později ve skriptu v podobné části jako následující kód.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Můžete se také rozhodnout nahradit tuto celou funkci vlastním mechanismem načítání dat; Jediným omezením je, že návratová hodnota musí být datový rámec Pandas a že data musí mít stejný tvar jako v původním experimentu.
Kód pro přípravu dat
Funkce prepare_data() vyčistí data, rozdělí funkci a ukázkové sloupce váhy a připraví data pro použití při trénování.
Tato funkce se může lišit v závislosti na typu datové sady a typu úlohy experimentu: klasifikace, regrese, prognózování časových řad, obrázky nebo úkoly NLP.
Následující příklad ukazuje, že obecně se datový rámec z kroku načítání dat předává. Sloupec popisku a váhy vzorku, pokud jsou původně zadány, se extrahují a řádky obsahující NaN se ze vstupních dat vyřadí.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Pokud chcete udělat další přípravu dat, můžete to udělat v tomto kroku přidáním vlastního kódu pro přípravu dat.
Kód featurizace dat
Funkce generate_data_transformation_config() určuje krok featurizace v konečném kanálu scikit-learn. Featurizátory z původního experimentu jsou zde reprodukovány spolu s jejich parametry.
Například možné transformace dat, ke které může dojít v této funkci, může být založena na imputerech, jako jsou, SimpleImputer() a CatImputer(), nebo transformátory, jako StringCastTransformer() a LabelEncoderTransformer().
Následuje transformátor typu StringCastTransformer() , který lze použít k transformaci sady sloupců. V tomto případě sada označena column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Pokud máte mnoho sloupců, které potřebují použít stejnou funkci nebo transformaci (například 50 sloupců v několika skupinách sloupců), tyto sloupce se zpracovávají seskupením podle typu.
V následujícím příkladu si všimněte, že každá skupina má přiřazený jedinečný mapovač. Tento mapovač se pak použije u každého sloupce této skupiny.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Tento přístup umožňuje mít efektivnější kód, protože nemá blok kódu transformátoru pro každý sloupec, který může být obzvláště těžkopádný, i když máte v datové sadě desítky nebo stovky sloupců.
U úlohFeatureUnion klasifikace a regrese se [] používá pro featurizátory.
U modelů prognózování časových řad se do kanálu scikit-learn shromažďuje několik featurizátorů pracujících s časovými řadami a pak je zabaleno do TimeSeriesTransformer.
Všechny uživatelem poskytnuté featurizace pro modely prognózování časových řad probíhají před modely, které poskytuje automatizované strojové učení.
Kód specifikace preprocesoru
generate_preprocessor_config()Funkce , pokud je k dispozici, určuje krok předběžného zpracování, který se má provést po featurizaci v konečném kanálu scikit-learn.
Za normálních okolností se tento krok předběžného zpracování skládá pouze z standardizace a normalizace dat, které se provádí pomocí sklearn.preprocessing.
Automatizované strojové učení určuje pouze krok předběžného zpracování pro neproměněné klasifikační a regresní modely.
Tady je příklad vygenerovaného kódu preprocesoru:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Kód specifikace algoritmů a hyperparametrů
Kód specifikace algoritmu a hyperparametrů je pravděpodobně tím, o co se nejvíce zajímá mnoho odborníků v ML.
Funkce generate_algorithm_config() určuje skutečný algoritmus a hyperparametry pro trénování modelu jako poslední fázi konečného kanálu scikit-learn.
Následující příklad používá algoritmus XGBoostClassifier s konkrétními hyperparametry.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
Vygenerovaný kód ve většině případů používá balíčky a třídy open source softwaru (OSS). Existují instance, kde jsou zprostředkující třídy obálky použity ke zjednodušení složitějšího kódu. Můžete například použít klasifikátor XGBoost a další běžně používané knihovny, jako jsou LightGBM nebo algoritmy Scikit-Learn.
Jako ml Professional můžete přizpůsobit konfigurační kód tohoto algoritmu tak, že podle potřeby upravíte jeho hyperparametry na základě vašich dovedností a zkušeností s tímto algoritmem a vaším konkrétním problémem ML.
Pro souborové modely generate_preprocessor_config_N() (v případě potřeby) a generate_algorithm_config_N() jsou definovány pro každého žáka v modelu souboru, kde N představuje umístění každého žáka v seznamu souborů. Pro modely souborů zásobníku je definován metauč.generate_algorithm_config_meta()
Kompletní trénovací kód
Generování kódu generuje build_model_pipeline() a train_model() definuje kanál scikit-learn a pro jeho volání fit() .
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
Kanál scikit-learn zahrnuje krok featurizace, preprocesor (pokud se používá) a algoritmus nebo model.
U modelů prognózování časových řad je kanál scikit-learn zabalený do ForecastingPipelineWrapper, který má určitou další logiku potřebnou k správnému zpracování dat časových řad v závislosti na použitém algoritmu.
Pro všechny typy úkolů používáme PipelineWithYTransformer v případech, kdy je potřeba zakódovat sloupec popisku.
Jakmile máte kanál scikit-Learn, vše, co zbývá volat, je fit() metoda pro trénování modelu:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
Návratová hodnota z train_model() je model fitovaný/natrénovaný na vstupních datech.
Hlavní kód, který spouští všechny předchozí funkce, je následující:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Jakmile máte natrénovaný model, můžete ho použít k vytváření předpovědí pomocí metody predict(). Pokud je váš experiment určený pro model časových řad, použijte pro předpovědi metodu forecast().
y_pred = model.predict(X)
Nakonec se model serializuje a uloží jako .pkl soubor s názvem "model.pkl":
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
Poznámkový script_run_notebook.ipynb blok slouží jako snadný způsob, jak provádět script.py výpočetní prostředky služby Azure Machine Learning.
Tento poznámkový blok je podobný existujícím ukázkovým poznámkovým blokům automatizovaného strojového učení, ale existuje několik klíčových rozdílů, jak je vysvětleno v následujících částech.
Prostředí
Obvykle je trénovací prostředí pro automatizované spuštění STROJOVÉho učení automaticky nastaveno sadou SDK. Když ale spustíte vlastní skript, jako je vygenerovaný kód, automatizované strojové učení už proces nezatěžuje, takže je nutné zadat prostředí, aby úloha příkazu byla úspěšná.
Generování kódu opakovaně používá prostředí, které bylo použito v původním experimentu automatizovaného strojového učení, pokud je to možné. Tím zaručujete, že spuštění trénovacího skriptu selže kvůli chybějícím závislostem a má vedlejší výhodu, že nepotřebujete opětovné sestavení image Dockeru, což šetří čas a výpočetní prostředky.
Pokud provedete změnyscript.py, které vyžadují další závislosti nebo chcete použít vlastní prostředí, musíte odpovídajícím způsobem aktualizovat prostředí.script_run_notebook.ipynb
Odeslání experimentu
Vzhledem k tomu, že vygenerovaný kód už není řízený automatizovaným strojovém učením, místo vytváření a odesílání úlohy AutoML je potřeba vytvořit Command Job a poskytnout mu vygenerovaný kód (script.py).
Následující příklad obsahuje parametry a běžné závislosti potřebné ke spuštění úlohy příkazu, jako jsou výpočty, prostředí atd.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning studio
Další kroky
- Přečtěte si další informace o tom, jak a kde nasadit model.
- Podívejte se, jak povolit funkce interpretovatelnosti speciálně v rámci experimentů automatizovaného strojového učení.