Transformace dat v návrháři služby Azure Machine Learning
V tomto článku se dozvíte, jak transformovat a ukládat datové sady v návrháři služby Azure Machine Learning, abyste připravili vlastní data pro strojové učení.
Ukázkovou datovou sadu pro sčítání lidu pro dospělé použijete k přípravě dvou datových sad: jedné datové sady, která obsahuje informace o sčítání dospělých pouze z USA, a další datovou sadu, která obsahuje informace o sčítání lidu od dospělých mimo USA.
V tomto článku se naučíte:
- Transformujte datovou sadu a připravte ji na trénování.
- Exportujte výsledné datové sady do úložiště dat.
- Zkontrolujte výsledky.
Tento postup je předpokladem pro přetrénování článku o modelech návrháře . V tomto článku se dozvíte, jak pomocí transformovaných datových sad trénovat více modelů s parametry kanálu.
Důležité
Pokud v tomto dokumentu nevidíte grafické prvky, jako jsou tlačítka v sadě nebo návrháři, pravděpodobně nemáte správnou úroveň oprávnění k pracovnímu prostoru. Obraťte se na správce předplatného Azure a ověřte, že máte udělenou správnou úroveň přístupu. Další informace najdete v tématu Správa uživatelů a rolí.
Transformace datové sady
V této části se dozvíte, jak importovat ukázkovou datovou sadu a rozdělit je do datových sad USA a jiných než USA. Další informace o importu vlastních dat do návrháře najdete v tématu importu dat .
Importovat data
K importu ukázkové datové sady použijte tento postup:
Přihlaste se k studio Azure Machine Learning a vyberte pracovní prostor, který chcete použít.
Přejděte do návrháře. Výběrem možnosti Vytvořit nový kanál pomocí klasických předem připravených komponent vytvořte nový kanál.
Na levé straně plátna kanálu rozbalte na kartě Komponenta uzel Ukázková data .
Přetáhněte datovou sadu pro sčítání lidu pro dospělé na plátno.
Pravým tlačítkem myši vyberte komponentu datové sady Pro dospělé ze sčítání lidu a vyberte Náhled dat.
K prozkoumání datové sady použijte okno náhledu dat. Poznamenejte si hodnoty sloupců "native-country" (nativní země).
Rozdělení dat
V této části použijete komponentu Rozdělit data k identifikaci a rozdělení řádků, které ve sloupci "native-country" obsahují "Spojené státy".
Na levé straně plátna na kartě komponent rozbalte část Transformace dat a najděte komponentu Rozdělit data .
Přetáhněte komponentu Split Data na plátno a přetáhněte ji pod komponentu datové sady.
Připojení komponenty datové sady k komponentě Split Data
Výběrem komponenty Rozdělit data otevřete podokno Rozdělit data.
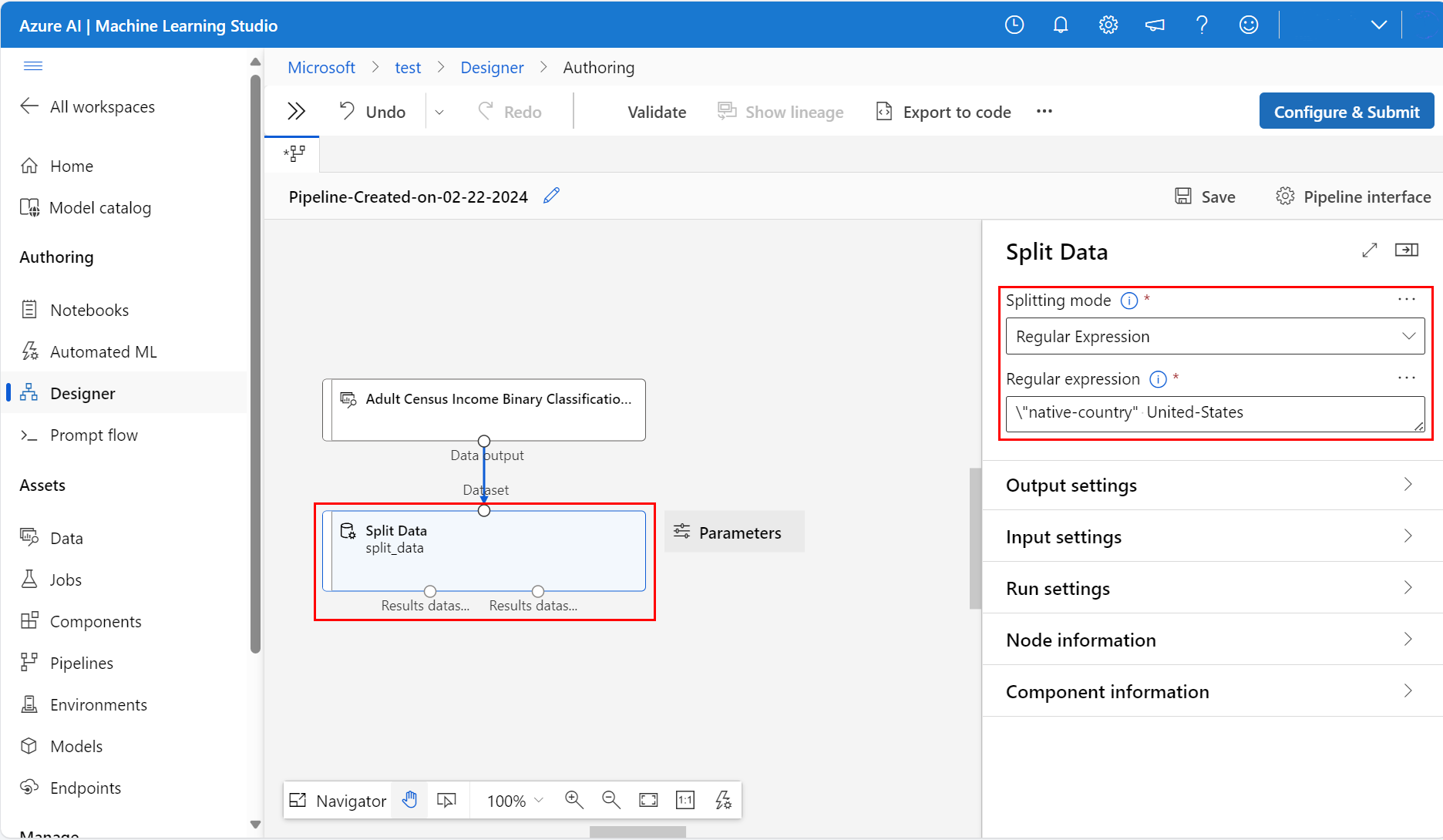
Napravo od plátna v ikoně Parametry nastavte režim rozdělení na regulární výraz.
Zadejte regulární výraz:
\"native-country" United-StatesRežim regulárního výrazu testuje jeden sloupec pro hodnotu. Další informace o komponentě Split Data najdete na referenční stránce komponenty souvisejícího algoritmu.
Váš kanál by měl vypadat podobně jako tento snímek obrazovky:
Uložení datových sad
Teď, když nastavíte kanál pro rozdělení dat, musíte určit, kam se mají datové sady zachovat. V tomto příkladu použijte komponentu Exportovat data k uložení datové sady do úložiště dat. Další informace o úložištích dat najdete v tématu Připojení ke službám Úložiště Azure.
Nalevo od plátna na paletě komponent rozbalte část Vstup a výstup dat a najděte komponentu Exportovat data .
Přetáhněte dvě součásti exportu dat pod komponentu Rozdělit data .
Připojte každý výstupní port komponenty Split Data k jiné komponentě Exportovat data .
Kanál by měl vypadat přibližně takto:
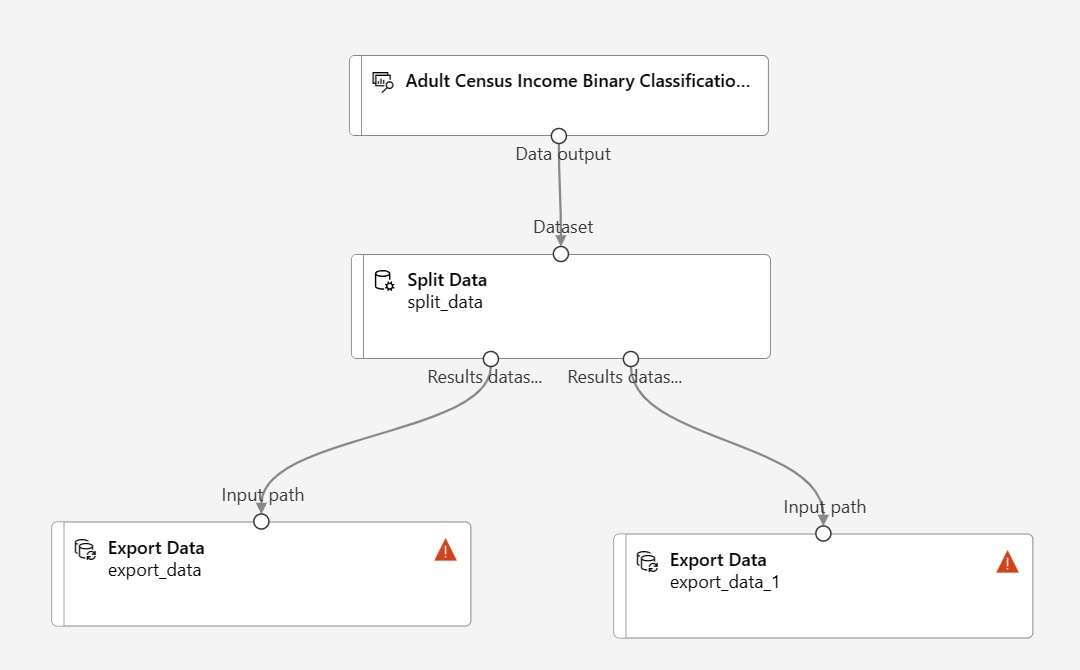
Výběrem komponenty Exportovat data připojenou k levému portu komponenty Rozdělit data otevřete podokno Konfigurace exportu dat.
U komponenty Split Data je důležité pořadí výstupních portů. První výstupní port obsahuje řádky, ve kterých je regulární výraz pravdivý. V tomto případě první port obsahuje řádky pro příjem založený na USA a druhý port obsahuje řádky pro příjem, který není založený na USA.
V podokně podrobností komponenty napravo od plátna nastavte následující možnosti:
Typ úložiště dat: Azure Blob Storage
Úložiště dat: Vyberte existující úložiště dat nebo vyberte Nový úložiště dat a vytvořte nový.
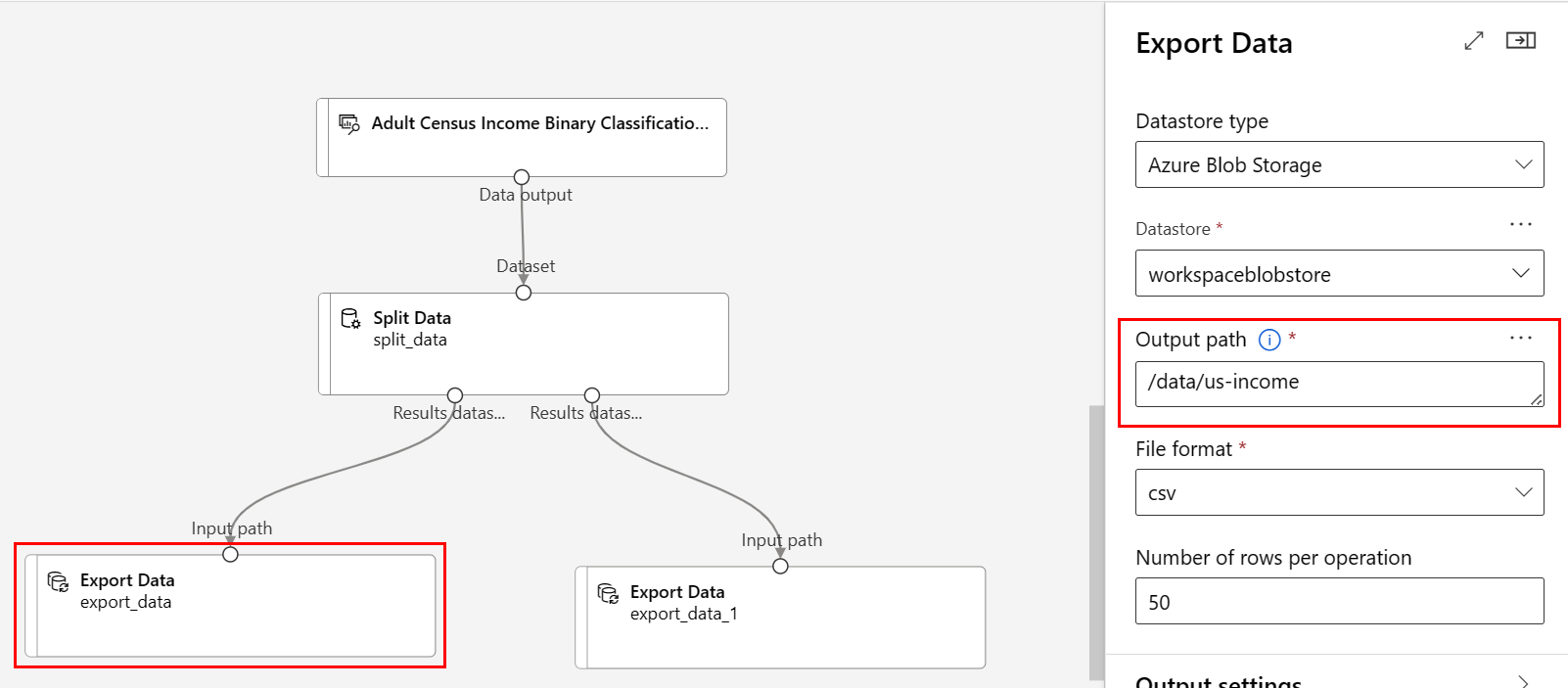
Cesta:
/data/us-incomeFormát souboru: csv
Poznámka:
Tento článek předpokládá, že máte přístup k úložišti dat zaregistrovaným v aktuálním pracovním prostoru Služby Azure Machine Learning. Pokyny k nastavení úložiště dat najdete v tématu Připojení ke službám úložiště dat.
Úložiště dat můžete vytvořit, pokud ho teď nemáte. Tento článek například ukládá datové sady do výchozího účtu úložiště objektů blob přidruženého k pracovnímu prostoru. Uloží datové sady do kontejneru
azuremldo nové složky s názvemdataVýběrem komponenty Exportovat data připojenou k pravému portu součásti Rozdělit data otevřete podokno Konfigurace exportu dat.
Napravo od plátna v podokně podrobností komponenty nastavte následující možnosti:
Typ úložiště dat: Azure Blob Storage
Úložiště dat: Vyberte dřívější úložiště dat.
Cesta:
/data/non-us-incomeFormát souboru: csv
Ověřte, že komponenta Exportovat data připojená k levému portu rozdělení dat má cestu.
/data/us-incomeOvěřte, že komponenta Exportovat data připojená k pravému portu má cestu.
/data/non-us-incomeKanál a nastavení by měly vypadat takto:
Odeslání úlohy
Teď, když nastavíte kanál pro rozdělení a export dat, odešlete úlohu kanálu.
V horní části plátna vyberte Konfigurovat a odeslat .
Vyberte možnost Vytvořit novou v podokně Základy úlohy Nastavit kanál a vytvořte experiment.
Experimenty logicky seskupují související úlohy kanálu dohromady. Pokud tento kanál spustíte v budoucnu, měli byste použít stejný experiment pro účely protokolování a sledování.
Zadejte popisný název experimentu , například split-census-data.
Vyberte Zkontrolovat a odeslat a pak vyberte Odeslat.
Zobrazení výsledků
Po dokončení spuštění kanálu můžete přejít do úložiště objektů blob na webu Azure Portal a zobrazit výsledky. Můžete také zobrazit zprostředkující výsledky součásti Rozdělit data a ověřit, že se data správně rozdělí.
Výběr komponenty Rozdělit data
V podokně podrobností komponenty napravo od plátna vyberte kartu Výstupy a protokoly .
Výběr rozevíracího seznamu Zobrazit výstupy dat
Výběr ikony
 vizualizovat vedle datové sady Výsledků1
vizualizovat vedle datové sady Výsledků1Ověřte, že sloupec "native-country" (nativní země) obsahuje pouze hodnotu "United-States" (Spojené státy).
Vyberte ikonu
vizualizace vedle datové sady Výsledků2.Ověřte, že sloupec "native-country" neobsahuje hodnotu United-States.
Vyčištění prostředků
Pokud chcete pokračovat ve dvou částech tohoto modelu opětovného natrénování s postupy návrháře služby Azure Machine Learning, přeskočte tuto část.
Důležité
Prostředky, které jste vytvořili, můžete použít jako předpoklady pro další kurzy a články s postupy služby Azure Machine Learning.
Odstranit vše
Pokud nemáte v úmyslu používat nic, co jste vytvořili, odstraňte celou skupinu prostředků, takže vám nebudou účtovány žádné poplatky.
Na webu Azure Portal vyberte skupiny prostředků na levé straně okna.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
Odstraněním skupiny prostředků se odstraní také všechny prostředky, které jste vytvořili v návrháři.
Odstranění jednotlivých prostředků
V návrháři, ve kterém jste experiment vytvořili, odstraňte jednotlivé prostředky tak, že je vyberete a pak vyberete tlačítko Odstranit .
Cílový výpočetní objekt, který jste zde vytvořili, automaticky škáluje na nula uzlů, když se nepoužívá. Tato akce se provede, aby se minimalizovaly poplatky. Pokud chcete odstranit cílový výpočetní objekt, postupujte takto:
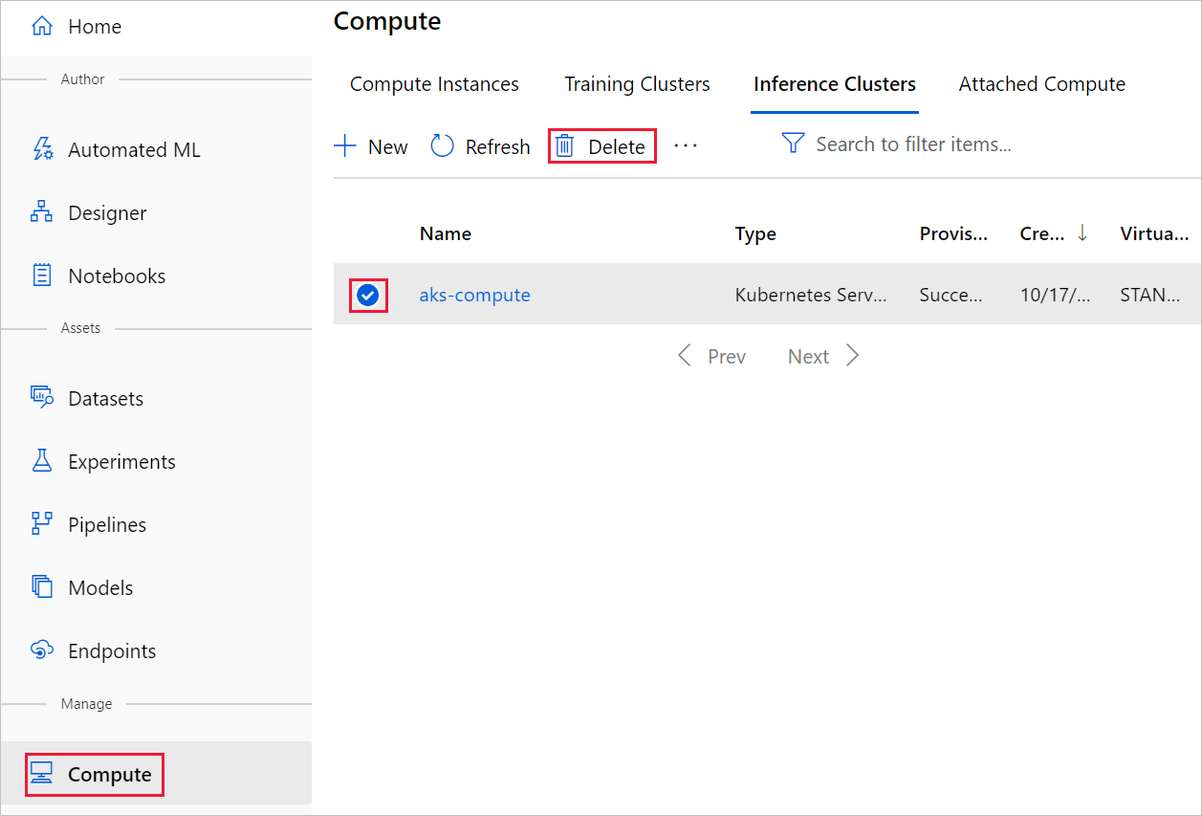
Datové sady z pracovního prostoru můžete zrušit tak, že vyberete každou datovou sadu a vyberete Zrušit registraci.
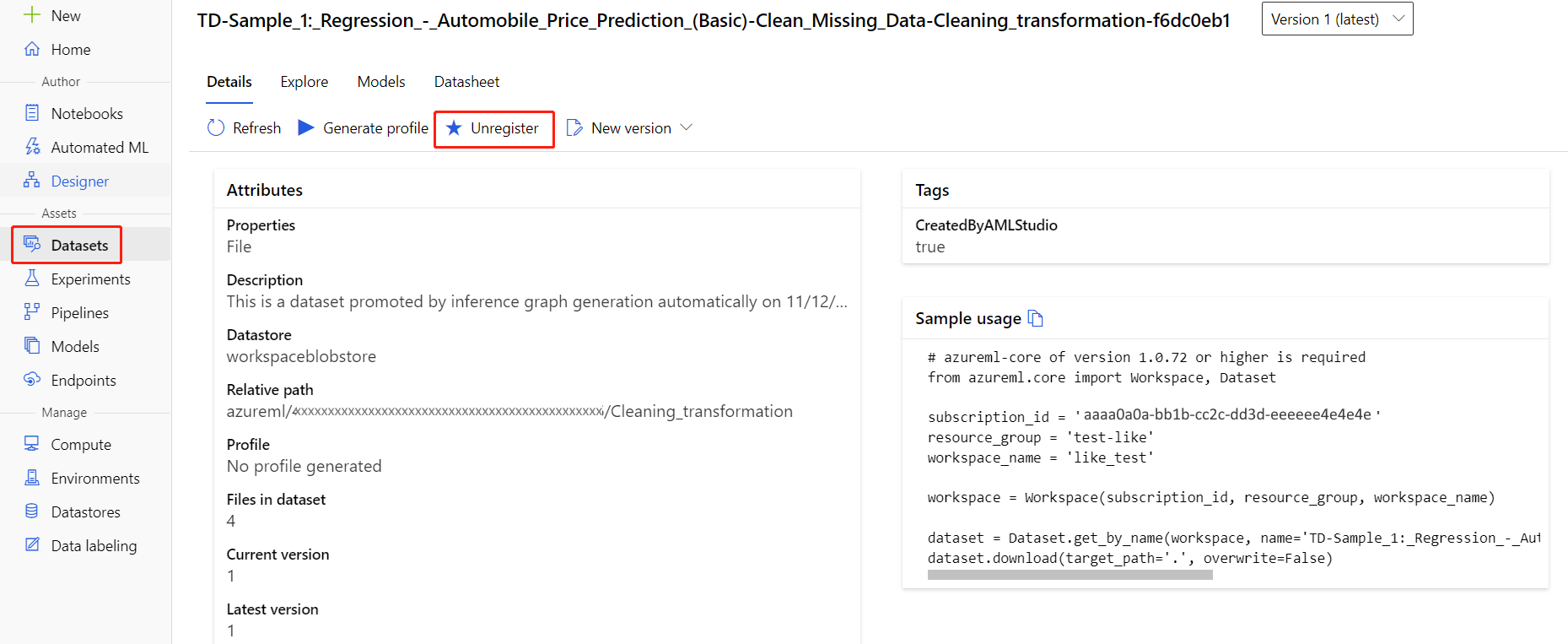
Pokud chcete datovou sadu odstranit, přejděte na účet úložiště pomocí webu Azure Portal nebo Průzkumník služby Azure Storage a odstraňte tyto prostředky ručně.
Další kroky
V tomto článku jste zjistili, jak transformovat datovou sadu a uložit ji do registrovaného úložiště dat.
Pokračujte k další části této série postupů s modelem Opětovné trénování pomocí návrháře služby Azure Machine Learning a využijte transformované datové sady a parametry kanálu k trénování modelů strojového učení.