Řešení potíží s kanály strojového učení
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto článku se dozvíte, jak řešit potíže s chybami při spuštění kanálu strojového učení v sadě Azure Machine Learning SDK a návrháři služby Azure Machine Learning.
Rady pro řešení potíží
Následující tabulka obsahuje běžné problémy při vývoji kanálů a jejich možná řešení..
| Problém | Možné řešení |
|---|---|
Nejde předat data do adresáře PipelineData |
Ujistěte se, že jste ve skriptu vytvořili adresář, který odpovídá očekávanému umístění výstupních dat kroků kanálu. Ve většině případů vstupní argument definuje výstupní adresář a pak adresář explicitně vytvoříte. K vytvoření výstupního adresáře použijte os.makedirs(args.output_dir, exist_ok=True). Projděte si kurz, ve kterém najdete příklad skriptu bodování s ukázkou tohoto modelu návrhu. |
| Chyby závislostí | Pokud se ve vzdáleném kanálu zobrazí chyby závislostí, ke kterým nedošlo při místním testování, ověřte, že závislosti a verze vzdáleného prostředí odpovídají závislostem ve vašem testovacím prostředí. (Viz Vytváření, ukládání do mezipaměti a opětovné použití prostředí |
| Nejednoznačné chyby s cílovými výpočetními objekty | Zkuste odstranit a znovu vytvořit cílové výpočetní objekty. Opětovné vytvoření cílových výpočetních objektů je rychlé a může vyřešit některé přechodné problémy. |
| Kanál nepoužívá kroky opakovaně | Opakované použití kroků je standardně povoleno, ale ujistěte se, že jste ho nezakázali v kroku kanálu. Pokud je opětovné použití zakázané, allow_reuse parametr v kroku je nastaven na Falsehodnotu . |
| Kanál se zbytečně opětovně spouští | Chcete-li zajistit, aby se kroky znovu spouštěly jenom při změně podkladových dat nebo skriptů, oddělte adresáře zdrojového kódu pro jednotlivé kroky. Pokud používáte stejný zdrojový adresář pro více kroků, může docházet ke zbytečnému opakovanému spouštění. Pomocí parametru u objektu source_directory kroku kanálu přejděte do izolovaného adresáře pro tento krok a ujistěte se, že nepoužíváte stejnou source_directory cestu pro více kroků. |
| Krok se v průběhu trénovacích epoch zpomaluje nebo dochází k jinému chování ve smyčce | Zkuste přepnout všechny zápisy souborů, včetně protokolování, z as_mount() na as_upload(). Režim připojení používá vzdálený virtualizovaný systém souborů a při každém připojení nahrává celý soubor. |
| Spuštění cílového výpočetního objektu trvá dlouho | Obrazy Dockeru pro cílové výpočetní objekty se načítají ze služby Azure Container Registry (ACR). Azure Machine Learning ve výchozím nastavení vytvoří službu ACR, která používá úroveň služby Basic . Změna ACR pro váš pracovní prostor na úroveň Standard nebo Premium může zkrátit dobu potřebnou k vytváření a načítání imagí. Další informace najdete v článku Úrovně služby Azure Container Registry. |
Chyby ověřování
Pokud provádíte operaci správy s cílovým výpočetním objektem ze vzdálené úlohy, zobrazí se jedna z následujících chyb:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Pokud se například pokusíte vytvořit nebo připojit cílový výpočetní objekt z kanálu ML odeslaného ke vzdálenému spuštění, zobrazí se chyba.
Řešení problémů ParallelRunStep
Skript musí ParallelRunStep obsahovat dvě funkce:
init(): Tuto funkci použijte pro jakoukoli nákladnou nebo běžnou přípravu na pozdější odvozování. Můžete ho například použít k načtení modelu do globálního objektu. Tato funkce se volá pouze jednou na začátku procesu.run(mini_batch): Funkce se spouští pro každoumini_batchinstanci.mini_batch:ParallelRunStepvyvolá metodu run a předá metodě seznam nebo knihovnu pandasDataFramejako argument. Každá položka v mini_batch je cesta k souboru, pokud je vstup neboFileDatasetpandasDataFrame, pokud je vstup .TabularDatasetresponse: metoda run() by měla vrátit knihovnu pandasDataFramenebo pole. Pro append_row output_action se tyto vrácené prvky připojí do společného výstupního souboru. Pro summary_only se obsah prvků ignoruje. U všech výstupních akcí každý vrácený výstupní prvek označuje jeden úspěšný spuštění vstupního prvku ve vstupní mini-batch. Ujistěte se, že je do výsledku spuštění zahrnutých dostatek dat pro mapování vstupu na výsledek spuštění výstupu. Výstup spuštění se zapisuje do výstupního souboru a není zaručeno, že je v pořádku, měli byste ho ve výstupu použít k namapovat na vstup.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Pokud máte jiný soubor nebo složku ve stejném adresáři jako skript pro odvozování, můžete na něj odkazovat vyhledáním aktuálního pracovního adresáře.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Parametry pro ParallelRunConfig
ParallelRunConfig je hlavní konfigurace pro ParallelRunStep instanci v rámci kanálu Azure Machine Learning. Použijete ho k zabalení skriptu a konfiguraci nezbytných parametrů, včetně všech následujících položek:
entry_script: Uživatelský skript jako místní cesta k souboru, která se spouští paralelně na více uzlech. Pokudsource_directoryje k dispozici, použijte relativní cestu. V opačném případě použijte jakoukoli cestu, která je na počítači přístupná.mini_batch_size: Velikost minidávkové dávky předané do jednohorun()volání. (volitelné; výchozí hodnota je10soubory proFileDataseta1MBproTabularDataset.)- Jedná
FileDatasetse o počet souborů s minimální hodnotou1. Do jedné minidávkové dávky můžete zkombinovat více souborů. - Pro
TabularDataset, je to velikost dat. Příklady hodnot jsou1024,1024KB,10MBa1GB. Doporučená hodnota je1MB. Minidávkové dávkyTabularDatasetnikdy nepřekračují hranice souborů. Pokud máte například .csv soubory s různými velikostmi, nejmenší soubor je 100 kB a největší je 10 MB. Pokud nastavítemini_batch_size = 1MB, soubory s velikostí menší než 1 MB se považují za jednu minidávku. Soubory s velikostí větší než 1 MB jsou rozdělené do několika mini dávek.
- Jedná
error_threshold: Počet selhání záznamů aTabularDatasetselhání souborů,FileDatasetkteré by se měly během zpracování ignorovat. Pokud počet chyb pro celý vstup překročí tuto hodnotu, úloha se přeruší. Prahová hodnota chyby je určená pro celý vstup, nikoli pro jednotlivé minidávkové dávky odeslané dorun()metody. Rozsah je[-1, int.max]. Tato-1část označuje ignorování všech selhání během zpracování.output_action: Jedna z následujících hodnot označuje, jak je výstup uspořádaný:summary_only: Uživatelský skript ukládá výstup.ParallelRunSteppoužívá výstup pouze pro výpočet prahové hodnoty chyby.append_row: Pro všechny vstupy se ve výstupní složce vytvoří pouze jeden soubor, který připojí všechny výstupy oddělené řádkem.
append_row_file_name: Chcete-li přizpůsobit název výstupního souboru pro append_row output_action (volitelné; výchozí hodnota jeparallel_run_step.txt).source_directory: Cesty ke složkám, které obsahují všechny soubory ke spuštění na cílovém výpočetním objektu (volitelné).compute_target: Podporuje se pouzeAmlCompute.node_count: Počet výpočetníchuzlůchchchprocess_count_per_node: Počet procesů na uzel. Osvědčeným postupem je nastavit počet GPU nebo procesoru, které má jeden uzel (volitelné, výchozí hodnota je1).environment: Definice prostředí Pythonu. Můžete ho nakonfigurovat tak, aby používal existující prostředí Pythonu nebo nastavil dočasné prostředí. Definice také zodpovídá za nastavení požadovaných závislostí aplikace (volitelné).logging_level: Log verbosity. Hodnoty při zvyšování podrobností jsou:WARNING,INFOaDEBUG. (volitelné; výchozí hodnota jeINFO)run_invocation_timeout: Časovýrun()limit vyvolání metody v sekundách. (volitelné; výchozí hodnota je60)run_max_try: Maximální počet vyzkoušenírun()pro minidávku. Chyba Arun()se nezdařila, pokud je vyvolán výjimka, nebo se porun_invocation_timeoutdosažení nevrací žádná hodnota (nepovinná, výchozí hodnota je3).
Můžete zadat mini_batch_size, , node_count, process_count_per_node, logging_levelrun_invocation_timeouta jako PipelineParameter, run_max_try tak, aby při opětovném odeslání spuštění kanálu můžete doladit hodnoty parametrů. V tomto příkladu použijete PipelineParameter a mini_batch_size Process_count_per_node tyto hodnoty změníte při opětovném odeslání spuštění později.
Parametry pro vytvoření ParallelRunStep
Vytvořte ParallelRunStep pomocí skriptu, konfigurace prostředí a parametrů. Zadejte cílový výpočetní objekt, který jste už připojili ke svému pracovnímu prostoru jako cíl provádění skriptu pro odvozování. Slouží ParallelRunStep k vytvoření kroku kanálu pro odvozování dávky, který přijímá všechny následující parametry:
name: Název kroku s následujícími omezeními pojmenování: jedinečný, 3–32 znaků a regulární výraz ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: ObjektParallelRunConfig, jak je definováno dříve.inputs: Jedna nebo více datových sad Azure Machine Learning s jedním typem, které se mají rozdělit pro paralelní zpracování.side_inputs: Nejméně jedna referenční data nebo datové sady používané jako vstupy na straně, aniž by bylo nutné dělit oddíly.output: ObjektOutputFileDatasetConfig, který odpovídá výstupnímu adresáři.arguments: Seznam argumentů předaných uživatelskému skriptu. Pomocí unknown_args je můžete načíst do vstupního skriptu (volitelné).allow_reuse: Určuje, jestli má krok při spuštění použít předchozí výsledky se stejnými nastaveními nebo vstupy. Pokud jeFalsetento parametr, vygeneruje se pro tento krok během provádění kanálu nové spuštění. (volitelné; výchozí hodnota jeTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Techniky ladění
Existují tři hlavní techniky ladění kanálů:
- Ladění jednotlivých kroků kanálu na místním počítači
- Použití protokolování a Application Insights k izolování a diagnostikování zdroj problému
- Připojení vzdáleného ladicího programu ke kanálu spuštěnému v Azure
Místní ladění skriptů
Jedním z nejběžnějších selhání v kanálu je to, že se skript domény nespustí podle očekávání nebo obsahuje chyby modulu runtime ve vzdáleném výpočetním kontextu, které se obtížně ladí.
Samotné kanály se nedají spustit místně. Spouštění skriptů v izolaci na místním počítači ale umožňuje rychlejší ladění, protože nemusíte čekat na proces sestavení výpočetních prostředků a prostředí. K tomu je potřeba provést některé vývojové práce:
- Pokud jsou vaše data v cloudovém úložišti dat, musíte si stáhnout data a zpřístupnit je vašemu skriptu. Použití malého vzorku dat je dobrý způsob, jak zkrátit modul runtime a rychle získat zpětnou vazbu k chování skriptu.
- Pokud se pokoušíte simulovat zprostředkující krok kanálu, možná budete muset ručně sestavit typy objektů, které konkrétní skript očekává od předchozího kroku.
- Potřebujete definovat vlastní prostředí a replikovat závislosti definované ve vzdáleném výpočetním prostředí.
Jakmile budete mít instalační program skriptu pro spuštění v místním prostředí, je jednodušší provádět úlohy ladění, jako je:
- Připojení vlastní konfigurace ladění
- Pozastavení provádění a kontrola stavu objektu
- Zachycení typů nebo logických chyb, které nebudou vystaveny, dokud nespustí modul runtime
Tip
Jakmile můžete ověřit, že je skript spuštěný podle očekávání, je dobrým dalším krokem spuštění skriptu v jednom kroku kanálu před pokusem o jeho spuštění v kanálu s několika kroky.
Konfigurace, zápis a kontrola protokolů kanálu
Testovací skripty místně představují skvělý způsob, jak ladit hlavní fragmenty kódu a složitou logiku před zahájením vytváření kanálu. V určitém okamžiku potřebujete ladit skripty během samotného spuštění samotného kanálu, zejména při diagnostice chování, ke kterému dochází během interakce mezi kroky kanálu. Doporučujeme v krokových print() skriptech používat příkazy, abyste během vzdáleného spuštění viděli stav objektu a očekávané hodnoty, podobně jako byste laděli javascriptový kód.
Možnosti a chování protokolování
Následující tabulka obsahuje informace o různých možnostech ladění kanálů. Nejedná se o vyčerpávající seznam, protože kromě azure Machine Learning a Pythonu zde existují i další možnosti.
| Knihovna | Typ | Příklad | Cíl | Zdroje informací |
|---|---|---|---|---|
| Azure Machine Learning SDK | Metrika | run.log(name, val) |
Uživatelské rozhraní portálu služby Azure Machine Learning | Jak sledovat experimenty Třída azureml.core.Run |
| Tisk/protokolování v Pythonu | Protokol | print(val)logging.info(message) |
Protokoly ovladačů, designer služby Azure Machine Learning | Jak sledovat experimenty Protokolování v Pythonu |
Příklad možností protokolování
import logging
from azureml.core.run import Run
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
Návrhář služby Azure Machine Learning
U kanálů vytvořených v návrháři najdete soubor 70_driver_log na stránce pro vytváření obsahu nebo na stránce podrobností o spuštění kanálu.
Povolení protokolování pro koncové body v reálném čase
Abyste mohli řešit potíže a ladit koncové body v reálném čase v návrháři, musíte povolit protokolování Application Insight pomocí sady SDK. Protokolování umožňuje řešit a ladit problémy s nasazením a využitím modelu. Další informace najdete v tématu Protokolování nasazených modelů.
Získání protokolů ze stránky pro tvorbu
Když odešlete spuštění kanálu a zůstanete na stránce vytváření, najdete soubory protokolu vygenerované pro každou komponentu, jakmile se jednotlivé komponenty dokončí.
Vyberte komponentu, která byla dokončena na plátně pro vytváření obsahu.
V pravém podokně komponenty přejděte na kartu Výstupy a protokoly .
Rozbalte pravé podokno a výběrem 70_driver_log.txt zobrazte soubor v prohlížeči. Protokoly si můžete stáhnout také místně.
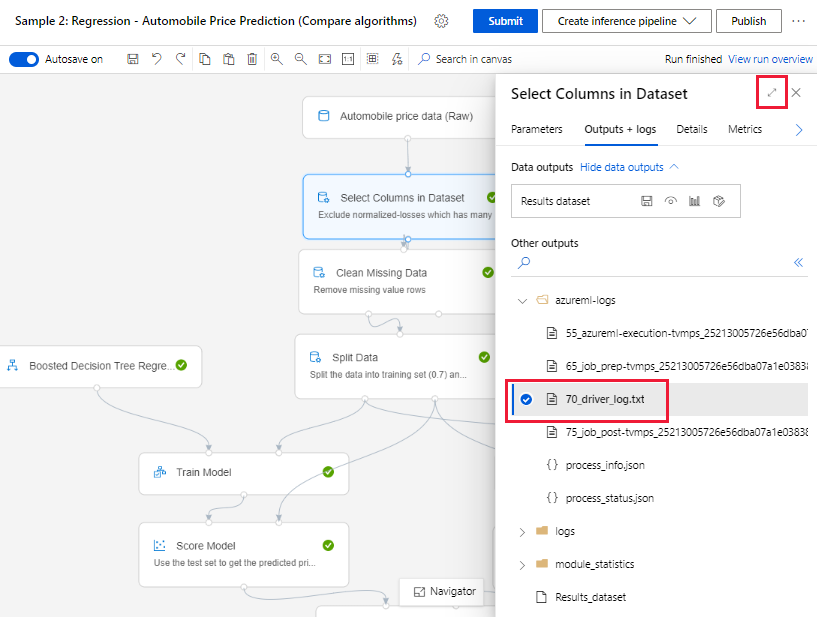
Získání protokolů z spuštění kanálu
Soubory protokolů pro konkrétní spuštění najdete také na stránce podrobností o spuštění kanálu, které najdete v části Kanály nebo Experimenty v sadě Studio.
Vyberte spuštění kanálu vytvořené v návrháři.
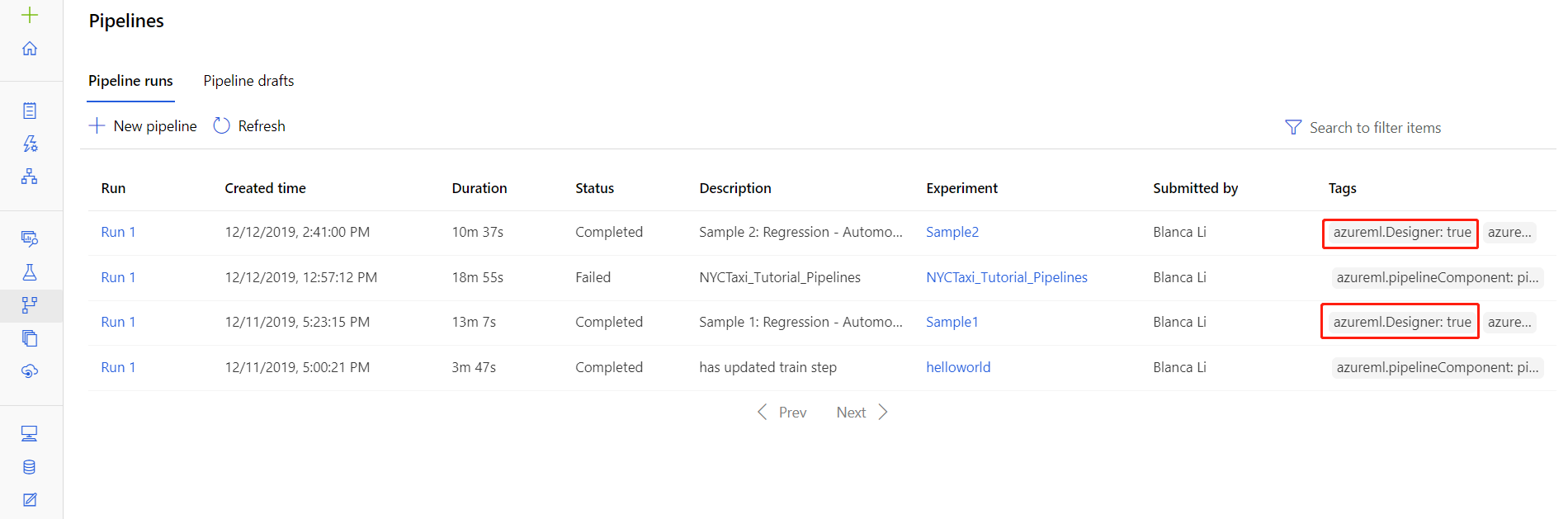
V podokně náhledu vyberte komponentu.
V pravém podokně komponenty přejděte na kartu Výstupy a protokoly .
Rozbalením pravého podokna zobrazíte soubor std_log.txt v prohlížeči nebo ho vyberte, pokud chcete protokoly stáhnout místně.
Důležité
Pokud chcete aktualizovat kanál ze stránky podrobností o spuštění kanálu, musíte naklonovat spuštění kanálu do nového konceptu kanálu. Spuštění kanálu je snímek kanálu. Podobá se souboru protokolu a nelze ho změnit.
Interaktivní ladění s využitím Visual Studio Code
V některých případech možná budete muset interaktivně ladit kód Pythonu použitý v kanálu ML. Pomocí nástrojů Visual Studio Code (VS Code) a debugpy se můžete připojit ke kódu, když běží v trénovacím prostředí. Další informace najdete v průvodci interaktivním laděním v editoru VS Code.
Selhání funkce HyperdriveStep a AutoMLStep s izolací sítě
Když použijete HyperdriveStep a AutoMLStep, při pokusu o registraci modelu se může zobrazit chyba.
Používáte sadu Azure Machine Learning SDK v1.
Váš pracovní prostor Azure Machine Learning je nakonfigurovaný pro izolaci sítě (VNet).
Váš kanál se pokusí zaregistrovat model vygenerovaný předchozím krokem. Například v následujícím příkladu
inputsje parametr saved_model z HyperdrivuStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Alternativní řešení
Důležité
K tomuto chování nedojde při použití sady Azure Machine Learning SDK v2.
Pokud chcete tuto chybu obejít, použijte třídu Run k získání modelu vytvořeného z hyperdrivuStep nebo AutoMLStep. Následuje ukázkový skript, který získá výstupní model z hyperdrivuStep:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Soubor pak můžete použít z PythonScriptStepu:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Další kroky
Kompletní kurz s využitím
ParallelRunSteptématu Kurz: Vytvoření kanálu Služby Azure Machine Learning pro dávkové vyhodnocováníÚplný příklad znázorňující automatizované strojové učení v kanálech ML najdete v tématu Použití automatizovaného strojového učení v kanálu Azure Machine Learning v Pythonu.
Nápovědu k balíčku azureml-pipelines-core a balíčku azureml-pipelines-steps najdete v referenčních informacích k sadě SDK.
Podívejte se na seznam výjimek návrháře a kódů chyb.