Vytváření hodnoticích skriptů pro dávkové nasazení
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Koncové body služby Batch umožňují nasadit modely, které provádějí dlouhotrvající odvozování ve velkém měřítku. Při nasazování modelů musíte vytvořit a zadat bodovací skript (označovaný také jako skript dávkového ovladače), který indikuje, jak ho použít pro vstupní data k vytváření předpovědí. V tomto článku se dozvíte, jak používat hodnoticí skripty v nasazení modelu pro různé scénáře. Dozvíte se také o osvědčených postupech pro dávkové koncové body.
Tip
Modely MLflow nevyžadují bodovací skript. Je automaticky vygenerován. Další informace o tom, jak dávkové koncové body pracují s modely MLflow, najdete ve vyhrazeném kurzu Používání modelů MLflow v dávkových nasazeních .
Upozorňující
Pokud chcete nasadit model automatizovaného strojového učení do dávkového koncového bodu, mějte na paměti, že automatizované strojové učení poskytuje bodovací skript, který funguje jenom pro online koncové body. Tento bodovací skript není určený pro dávkové spuštění. Další informace o tom, jak vytvořit bodovací skript přizpůsobený pro to, co váš model dělá, najdete v těchto pokynech.
Principy hodnoticího skriptu
Bodovací skript je soubor Pythonu (.py), který určuje, jak spustit model, a číst vstupní data odesílaná exekutorem dávkového nasazení. Každé nasazení modelu poskytuje bodovací skript (spolu se všemi ostatními požadovanými závislostmi) při vytváření. Bodovací skript obvykle vypadá takto:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
Bodovací skript musí obsahovat dvě metody:
Metoda init
Použijte metodu init() pro jakoukoli nákladnou nebo běžnou přípravu. Můžete ho například použít k načtení modelu do paměti. Spuštění celé dávkové úlohy volá tuto funkci jednou. Soubory modelu jsou k dispozici v cestě určené proměnnou AZUREML_MODEL_DIRprostředí . V závislosti na tom, jak byl model zaregistrovaný, můžou být jeho soubory obsaženy ve složce. V dalším příkladu má model několik souborů ve složce s názvem model. Další informace najdete v tom, jak určit složku, kterou model používá.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
V tomto příkladu umístíme model do globální proměnné model. Pokud chcete zpřístupnit prostředky potřebné k odvozování funkce bodování, použijte globální proměnné.
Metoda run
run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] Metoda slouží ke zpracování vyhodnocování každé minisádky, kterou vygeneruje dávkové nasazení. Tato metoda se volá jednou pro každou mini_batch vygenerovanou pro vstupní data. Nasazení služby Batch čte data v dávkách podle toho, jak konfigurace nasazení probíhá.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
Metoda obdrží seznam cest k souborům jako parametr (mini_batch). Tento seznam můžete použít k iteraci a individuálnímu zpracování jednotlivých souborů nebo ke čtení celé dávky a zpracování všech souborů najednou. Nejlepší možnost závisí na výpočetní paměti a propustnosti, kterou potřebujete dosáhnout. Příklad, který popisuje, jak číst celé dávky dat najednou, navštivte nasazení s vysokou propustností.
Poznámka:
Jak se distribuuje práce?
Dávkové nasazení distribuují práci na úrovni souboru, což znamená, že složka, která obsahuje 100 souborů s mini dávkami 10 souborů, vygeneruje 10 dávek 10 souborů. Všimněte si, že velikosti příslušných souborů nemají žádnou relevanci. Pro soubory příliš velké na zpracování ve velkých minidávkách doporučujeme, abyste soubory rozdělili na menší soubory, abyste dosáhli vyšší úrovně paralelismu, nebo snížili počet souborů na minidávku. V tuto chvíli nemůže dávkové nasazení počítat s nerovnoměrnou distribucí velikosti souboru.
Metoda run() by měla vrátit pandas DataFrame nebo pole nebo seznam. Každý vrácený výstupní prvek označuje jeden úspěšný spuštění vstupního prvku ve vstupu mini_batch. U datových prostředků souborů nebo složek představuje každý vrácený řádek nebo prvek jeden zpracovaný soubor. U tabulkového datového assetu představuje každý vrácený řádek nebo prvek řádek ve zpracovaném souboru.
Důležité
Jak psát předpovědi?
Vše, co run() funkce vrátí, se připojí do výstupního souboru predikcí, který vygeneruje dávková úloha. Je důležité vrátit správný datový typ z této funkce. Pokud potřebujete vytvořit výstup jedné předpovědi, vrátí pole . Pokud potřebujete vrátit více informací, vraťte datové rámce pandas. Například u tabulkových dat můžete chtít přidat předpovědi k původnímu záznamu. K tomu použijte datový rámec pandas. I když datový rámec pandas může obsahovat názvy sloupců, výstupní soubor tyto názvy neobsahuje.
k zápisu předpovědí jiným způsobem můžete přizpůsobit výstupy v dávkových nasazeních.
Upozorňující
run Ve funkci nevypisujte složité datové typy (ani seznamy složitých datových typů) místo pandas.DataFrame. Tyto výstupy se transformují na řetězce a budou těžko čitelné.
Výsledný datový rámec nebo pole se připojí k označenému výstupnímu souboru. Kardinalita výsledků není nutná. Jeden soubor může ve výstupu vygenerovat 1 nebo více řádků nebo prvků. Všechny prvky ve výsledném datovém rámci nebo poli se zapisují do výstupního souboru tak, jak jsou (vzhledem k tomu, že to output_action není summary_only).
Balíčky Pythonu pro bodování
Musíte označit jakoukoli knihovnu, kterou skript bodování vyžaduje ke spuštění v prostředí, ve kterém se spouští dávkové nasazení. Pro bodovací skripty jsou prostředí označená pro každé nasazení. Obvykle označíte své požadavky pomocí conda.yml souboru závislostí, který může vypadat takto:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Další informace o tom, jak označit prostředí pro váš model, najdete v tématu Vytvoření dávkového nasazení .
Psaní předpovědí jiným způsobem
Ve výchozím nastavení dávkové nasazení zapisuje předpovědi modelu do jednoho souboru, jak je uvedeno v nasazení. V některých případech ale musíte předpovědi zapsat do více souborů. Například pro dělená vstupní data byste pravděpodobně chtěli vygenerovat také dělený výstup. V těchto případech můžete přizpůsobit výstupy v dávkových nasazeních a označit:
- Formát souboru (CSV, parquet, json atd.) použitý k zápisu předpovědí
- Způsob dělení dat ve výstupu
Další informace o tom, jak toho dosáhnout, najdete v tématu Přizpůsobení výstupů v dávkových nasazeních .
Správa zdrojového kódu hodnoticích skriptů
Důrazně doporučujeme umístit bodovací skripty pod správu zdrojového kódu.
Osvědčené postupy pro psaní hodnoticích skriptů
Při psaní hodnoticích skriptů, které zpracovávají velké objemy dat, musíte vzít v úvahu několik faktorů, včetně
- Velikost každého souboru
- Množství dat v jednotlivých souborech
- Množství paměti potřebné ke čtení každého souboru
- Množství paměti potřebné ke čtení celé dávky souborů
- Nároky na paměť modelu
- Využití paměti modelu při spuštění přes vstupní data
- Dostupná paměť ve výpočetních prostředcích
Nasazení služby Batch distribuují práci na úrovni souboru. To znamená, že složka, která obsahuje 100 souborů v mini dávkách 10 souborů, generuje 10 dávek z 10 souborů každý (bez ohledu na velikost zahrnutých souborů). Pro soubory příliš velké na zpracování ve velkých minidávkách doporučujeme rozdělit soubory na menší soubory, dosáhnout vyšší úrovně paralelismu nebo snížit počet souborů na minidávku. V tuto chvíli nemůže dávkové nasazení počítat s nerovnoměrnou distribucí velikosti souboru.
Vztah mezi stupněm paralelismu a bodovacím skriptem
Konfigurace nasazení řídí velikost každé minidávkové dávky i počet pracovních procesů na každém uzlu. To je důležité, když se rozhodnete, jestli chcete číst celou minidávku, aby bylo možné provést odvozování, spustit soubor odvozování podle souboru nebo spustit řádek odvozování po řádku (pro tabulkový). Další informace najdete v části Spuštění odvozování na minidávkovém souboru nebo na úrovni řádku.
Při spouštění více pracovních procesů ve stejné instanci byste měli počítat se skutečností, že se paměť sdílí mezi všemi pracovními procesy. Zvýšení počtu pracovních procesů na uzel by obecně mělo doprovázet snížení velikosti minidávkové dávky nebo změnou strategie vyhodnocování, pokud velikost dat a výpočetní skladová položka zůstávají stejné.
Spuštění odvozování na mini dávce, souboru nebo na úrovni řádku
Dávkové koncové body volají run() funkci v bodovacím skriptu jednou za minidávku. Můžete se ale rozhodnout, jestli chcete pro tabulková data spustit odvozování po celé dávce, po jednom souboru najednou nebo po jednom řádku.
Úroveň minidávkové dávky
Obvykle budete chtít spustit odvozování v dávce najednou, abyste dosáhli vysoké propustnosti v procesu dávkového hodnocení. K tomu dochází v případě, že spustíte odvozování přes GPU, kde chcete dosáhnout sytosti zařízení pro odvozování. Můžete se také spolehnout na zavaděč dat, který dokáže zpracovat samotné dávkování, pokud se data nevejdou do paměti, například TensorFlow na PyTorch zavaděče dat. V těchto případech můžete chtít spustit odvození v celé dávce.
Upozorňující
Spuštění odvozování na úrovni dávky může vyžadovat úzkou kontrolu nad velikostí vstupních dat, aby se správně zohlednily požadavky na paměť a aby nedocházelo k výjimkám mimo paměť. Jestli můžete načíst celou minidávku v paměti, závisí na velikosti minidávkové dávky, velikosti instancí v clusteru, počtu pracovních procesů na každém uzlu a velikosti minidávkové dávky.
Informace o tom, jak toho dosáhnout, najdete v nasazeních s vysokou propustností. Tento příklad zpracovává celou dávku souborů najednou.
Úroveň souboru
Jedním z nejjednodušších způsobů, jak provést odvozování, je iterace všech souborů v mini dávce a pak model spustit. V některých případech může být vhodné například zpracování obrázků. U tabulkových dat možná budete muset provést dobrý odhad počtu řádků v každém souboru. Tento odhad může ukázat, jestli váš model dokáže zpracovat požadavky na paměť pro načtení celých dat do paměti a provedení odvozování. Některé modely (zejména tyto modely založené na opakujících se neurálních sítích) se rozbalí a představují paměťovou stopu s potenciálně nelineárním počtem řádků. U modelu s vysokými náklady na paměť zvažte spuštění odvozování na úrovni řádku.
Tip
Zvažte rozdělení příliš velkých souborů najednou na čtení do několika menších souborů, abyste mohli lépe paralelizovat.
Informace o tom, jak to udělat, najdete v tématu Zpracování obrázků pomocí dávkových nasazení . Tento příklad zpracovává soubor najednou.
Úroveň řádků (tabulková)
U modelů, které představují problémy s velikostmi vstupu, můžete chtít spustit odvozování na úrovni řádku. Vaše dávkové nasazení stále poskytuje váš bodovací skript s minisáží souborů. Budete ale číst jeden soubor po jednom řádku. Může to vypadat jako neefektivní, ale u některých modelů hlubokého učení to může být jediný způsob, jak provádět odvozování bez vertikálního navýšení kapacity hardwarových prostředků.
Informace o tom, jak to udělat, najdete v tématu Zpracování textu pomocí dávkových nasazení . Tento příklad zpracovává řádek najednou.
Použití modelů, které jsou složkami
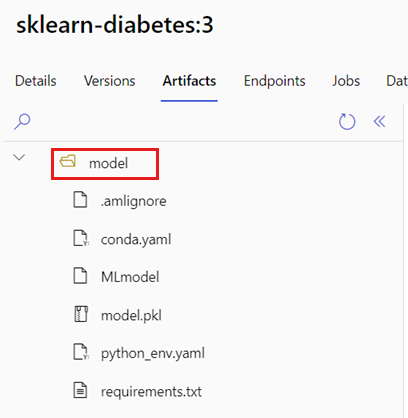
AZUREML_MODEL_DIR Proměnná prostředí obsahuje cestu k vybranému umístění modelu a init() funkce ji obvykle používá k načtení modelu do paměti. Některé modely ale můžou obsahovat soubory ve složce a při jejich načítání je budete muset zohlednit. Strukturu složek modelu můžete identifikovat, jak je znázorněno tady:
Přejděte na portál Azure Machine Learning.
Přejděte do části Modely.
Vyberte model, který chcete nasadit, a vyberte kartu Artefakty .
Všimněte si zobrazené složky. Tato složka byla označena při registraci modelu.

K načtení modelu použijte tuto cestu:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)