Nastavení AutoML pro trénování modelů počítačového zpracování obrazu
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
V tomto článku se naučíte trénovat modely počítačového zpracování obrazu na datech obrázků pomocí automatizovaného strojového učení. Modely můžete trénovat pomocí rozšíření Azure Machine Learning CLI verze 2 nebo sady Azure Machine Learning Python SDK v2.
Automatizované strojové učení podporuje trénování modelů pro úlohy počítačového zpracování obrazu, jako jsou klasifikace obrázků, rozpoznávání objektů nebo segmentace instancí. Vytváření modelů automatizovaného strojového učení pro úlohy počítačového zpracování obrazu se v současné době podporuje prostřednictvím sady Python SDK služby Azure Machine Learning. Výsledné pokusy o experimentování, modely a výstupy jsou přístupné z uživatelského rozhraní studio Azure Machine Learning. Přečtěte si další informace o automatizovaném ml pro úlohy počítačového zpracování obrazu na datech obrázků.
Požadavky
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
- Pracovní prostor služby Azure Machine Learning. Pokud chcete vytvořit pracovní prostor, přečtěte si téma Vytvoření prostředků pracovního prostoru.
- Nainstalujte a nastavte rozhraní příkazového řádku (v2) a ujistěte se, že jste rozšíření nainstalovali
ml.
Vyberte typ úkolu.
Automatizované strojové učení pro image podporuje následující typy úloh:
| Typ úkolu | Syntaxe úlohy AutoML |
|---|---|
| klasifikace obrázků | CLI v2: image_classification SDK v2: image_classification() |
| klasifikace obrázků s více popisky | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| Rozpoznávání objektů obrázku | CLI v2: image_object_detection SDK v2: image_object_detection() |
| Segmentace instance image | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Tento typ úkolu je povinný parametr a lze ho task nastavit pomocí klíče.
Příklad:
task: image_object_detection
Trénovací a ověřovací data
Abyste mohli generovat modely počítačového MLTablezpracování obrazu, musíte jako vstup pro trénování modelu použít označení obrazová data ve formě . Můžete vytvořit MLTable z trénovacích dat ve formátu JSONL.
Pokud jsou trénovací data v jiném formátu (například pascal VOC nebo COCO), můžete použít pomocné skripty, které jsou součástí ukázkových poznámkových bloků, a převést data na JSONL. Přečtěte si další informace o tom , jak připravit data pro úlohy počítačového zpracování obrazu pomocí automatizovaného strojového učení.
Poznámka:
Aby bylo možné odeslat úlohu AutoML, musí trénovací data obsahovat alespoň 10 obrázků.
Upozorňující
Vytváření MLTable dat ve formátu JSONL se podporuje pouze pomocí sady SDK a rozhraní příkazového řádku pro tuto funkci.
MLTable Vytváření prostřednictvím uživatelského rozhraní se v tuto chvíli nepodporuje.
Ukázky schématu JSONL
Struktura TabularDataset závisí na úkolu, který je v ruce. U typů úloh počítačového zpracování obrazu se skládá z následujících polí:
| Pole | Popis |
|---|---|
image_url |
Obsahuje cestu k souboru jako objekt StreamInfo. |
image_details |
Informace o metadatech obrázků se skládají z výšky, šířky a formátu. Toto pole je volitelné, a proto může nebo nemusí existovat. |
label |
Reprezentace popisku obrázku ve formátu JSON na základě typu úlohy. |
Následující kód je ukázkový soubor JSONL pro klasifikaci obrázků:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Následující kód je ukázkový soubor JSONL pro detekci objektů:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Využívání dat
Jakmile jsou vaše data ve formátu JSONL, můžete vytvořit trénování a ověření MLTable , jak je znázorněno níže.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Automatizované strojové učení neukládá žádné omezení velikosti trénovacích nebo ověřovacích dat pro úlohy počítačového zpracování obrazu. Maximální velikost datové sady je omezená pouze vrstvou úložiště za datovou sadou (příklad: úložiště objektů blob). Neexistuje žádný minimální počet obrázků ani popisků. Doporučujeme ale začít s minimálně 10 až 15 vzorky na popisek, aby byl výstupní model dostatečně natrénovaný. Čím vyšší je celkový počet popisků/tříd, tím více vzorků na popisek potřebujete.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Trénovací data jsou povinný parametr a předávají se pomocí training_data klíče. Volitelně můžete zadat jinou tabulku MLtable jako ověřovací data s validation_data klíčem. Pokud nezadáte žádná ověřovací data, použije se pro ověření ve výchozím nastavení 20 % trénovacích dat, pokud nepředáte validation_data_size argument s jinou hodnotou.
Název cílového sloupce je povinný parametr, který se používá jako cíl pro úlohu ML pod dohledem. Předává se pomocí target_column_name klíče. Příklad:
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Výpočetní prostředí pro spuštění experimentu
Poskytnutí cílového výpočetního objektu pro automatizované strojové učení pro trénování modelu Modely automatizovaného strojového učení pro úlohy počítačového zpracování obrazu vyžadují skladové položky GPU a podporují rodiny nc a ND. Pro rychlejší trénování doporučujeme řady NCsv3 (s grafickými procesory v100). Cílový výpočetní objekt s skladovou jednotkou virtuálního počítače s více GPU používá k urychlení trénování několik GPU. Navíc při nastavování cílového výpočetního objektu s více uzly můžete provádět rychlejší trénování modelu prostřednictvím paralelismu při ladění hyperparametrů pro váš model.
Poznámka:
Pokud jako cílový výpočetní objekt používáte výpočetní instanci , ujistěte se, že není spuštěno více úloh AutoML najednou. Ujistěte se také, že max_concurrent_trials je v limitech vaší úlohy nastavená hodnota 1.
Cílový výpočetní objekt se předává pomocí parametru compute . Příklad:
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
compute: azureml:gpu-cluster
Konfigurace experimentů
U úloh počítačového zpracování obrazu můžete spustit jednotlivé zkušební verze, ruční úklidy nebo automatické úklidy. Pokud chcete získat první základní model, doporučujeme začít automatickým úklidem. Pak si můžete vyzkoušet jednotlivé zkušební verze s určitými modely a konfiguracemi hyperparametrů. Nakonec pomocí ručních úklidů můžete prozkoumat více hodnot hyperparametrů poblíž slibnějších modelů a konfigurací hyperparametrů. Tento třístupňový pracovní postup (automatické úklidy, individuální pokusy, ruční úklidy) zabraňuje prohledání celého prostoru hyperparametrů, který exponenciálně roste v počtu hyperparametrů.
Automatické úklidy můžou přinést konkurenční výsledky pro mnoho datových sad. Navíc nevyžadují pokročilé znalosti architektur modelů, berou v úvahu korelace hyperparametrů a bezproblémově fungují napříč různými hardwarovými nastaveními. Všechny tyto důvody z nich činí silnou volbou pro počáteční fázi procesu experimentování.
Primární metrika
Trénovací úloha AutoML používá primární metriku pro optimalizaci modelu a ladění hyperparametrů. Primární metrika závisí na typu úkolu, jak je znázorněno níže; jiné primární hodnoty metrik se v současné době nepodporují.
- Přesnost klasifikace obrázků
- Průnik nad sjednocením pro vícenásobnou klasifikaci obrázků
- Průměrná průměrná přesnost detekce objektů obrázku
- Průměrná průměrná přesnost segmentace instance obrázku
Limity úloh
Prostředky vynaložené na trénovací úlohu image AutoML můžete řídit zadáním timeout_minutesmax_trials parametru max_concurrent_trials a úlohy v nastavení limitu, jak je popsáno v následujícím příkladu.
| Parametr | Podrobnosti |
|---|---|
max_trials |
Parametr maximálního počtu pokusů, které se mají uklidit. Musí být celé číslo od 1 do 1000. Při zkoumání pouze výchozích hyperparametrů pro danou architekturu modelu nastavte tento parametr na hodnotu 1. Výchozí hodnota je 1. |
max_concurrent_trials |
Maximální počet zkušebních verzí, které se dají spustit souběžně. Pokud je zadáno, musí být celé číslo od 1 do 100. Výchozí hodnota je 1. POZNÁMKA: max_concurrent_trials je omezen interně max_trials . Pokud by například uživatelské sady max_concurrent_trials=4, max_trials=2hodnoty by se interně aktualizovaly jako max_concurrent_trials=2, max_trials=2. |
timeout_minutes |
Doba v minutách před ukončením experimentu. Pokud není zadaný žádný, výchozí experiment timeout_minutes je sedm dnů (maximálně 60 dnů). |
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Automatické úklidové hyperparametry modelu (AutoMode)
Důležité
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Je těžké předpovědět nejlepší architekturu modelu a hyperparametry pro datovou sadu. V některých případech může být také omezený čas člověka přidělený k ladění hyperparametrů. U úloh počítačového zpracování obrazu můžete zadat libovolný počet pokusů a systém automaticky určí oblast prostoru hyperparametrů, který se má uklidit. Nemusíte definovat prostor vyhledávání hyperparametrů, metodu vzorkování nebo zásady předčasného ukončení.
Aktivace automatického režimu
Automatické úklidy můžete spustit tak, že nastavíte max_trials hodnotu větší než 1 in limits a nezadáte vyhledávací prostor, metodu vzorkování a zásady ukončení. Tuto funkci nazýváme AutoMode; Projděte si následující příklad.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
limits:
max_trials: 10
max_concurrent_trials: 2
Řada pokusů mezi 10 a 20 pravděpodobně dobře funguje u mnoha datových sad. Časový rozpočet pro úlohu AutoML je stále možné nastavit, ale doporučujeme to udělat jenom v případě, že každá zkušební verze může trvat dlouhou dobu.
Upozorňující
Spuštění automatických úklidů prostřednictvím uživatelského rozhraní se v tuto chvíli nepodporuje.
Individuální zkušební verze
V jednotlivých zkušebních verzích přímo řídíte architekturu modelu a hyperparametry. Architektura modelu se předává prostřednictvím parametru model_name .
Podporované architektury modelů
Následující tabulka shrnuje podporované starší modely pro každou úlohu počítačového zpracování obrazu. Použití pouze těchto starších modelů se spustí pomocí starší verze modulu runtime (kde se jednotlivé spuštění nebo zkušební verze odesílají jako úloha příkazu). Podporu HuggingFace a MMDetection najdete níže.
| Úloha | architektury modelů | Syntaxe řetězcového literáludefault_model* označeno * |
|---|---|---|
| Klasifikace obrázku (více tříd a více popisků) |
MobileNet: Lehké modely pro mobilní aplikace ResNet: Zbytkové sítě ResNeSt: Rozdělení sítí pozornosti SE-ResNeXt50: Sítě stisknuté a vzrušující ViT: Sítě transformátoru obrazu |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (malý) vitb16r224* (základna) vitl16r224 (velký) |
| Detekce objektů |
YOLOv5: Model detekce objektů v jedné fázi Rychlejší analýza RCNN ResNet FPN: Modely detekce objektů ve dvou fázích Sítnice ResNet FPN: adresní nerovnováha třídy s kontaktní ztrátou Poznámka: Informace o model_size hyperparametrech pro velikosti modelů YOLOv5 |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentace instancí | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Podporované architektury modelů – HuggingFace a MMDetection
S novým back-endem, který běží v kanálech Azure Machine Learning, můžete navíc použít jakýkoli model klasifikace obrázků z centra HuggingFace, který je součástí knihovny transformátorů (například microsoft/beit-base-patch16-224), a také jakýkoli model detekce objektů nebo segmentace instancí z modelu MMDetection verze 3.1.0 Model Zoo (napříkladatss_r50_fpn_1x_coco).
Kromě podpory jakéhokoli modelu z HuggingFace Transfomers a MMDetection 3.1.0 nabízíme také seznam kurátorovaných modelů z těchto knihoven v registru azureml. Tyto kurátorované modely byly důkladně testovány a k zajištění efektivního trénování používají výchozí hyperparametry vybrané z rozsáhlých srovnávacích testů. Následující tabulka shrnuje tyto kurátorované modely.
| Úloha | architektury modelů | Syntaxe řetězcového literálu |
|---|---|---|
| Klasifikace obrázku (více tříd a více popisků) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Rozpoznávání objektů |
Řídký R-CNN DeTR s možností deformace Virtuální síť YOLOF |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Segmentace instancí | Maska R-CNN | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Seznam kurátorovaných modelů neustále aktualizujeme. Nejnovější seznam kurátorovaných modelů pro danou úlohu můžete získat pomocí sady Python SDK:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Výstup:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Při použití jakéhokoli modelu HuggingFace nebo MMDetection se spustí spuštění pomocí komponent kanálu. Pokud se použijí starší modely i modely HuggingFace/MMdetection, všechny spuštění a zkušební verze se aktivují pomocí komponent.
Kromě řízení architektury modelu můžete také ladit hyperparametry používané pro trénování modelu. Zatímco mnohé z vystavených hyperparametrů jsou nezávislé na modelu, existují instance, ve kterých jsou hyperparametry specifické pro úlohu nebo pro konkrétní model. Přečtěte si další informace o dostupných hyperparametrech pro tyto instance.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Pokud chcete pro danou architekturu použít výchozí hodnoty hyperparametrů (například yolov5), můžete ho zadat pomocí klíče model_name v části training_parameters. Příklad:
training_parameters:
model_name: yolov5
Ruční úklid hyperparametrů modelu
Při trénování modelů počítačového zpracování obrazu závisí výkon modelu silně na vybraných hodnotách hyperparametrů. Často můžete chtít hyperparametry ladit, abyste získali optimální výkon. U úloh počítačového zpracování obrazu můžete hyperparametry uklidit, abyste našli optimální nastavení pro váš model. Tato funkce používá možnosti ladění hyperparametrů ve službě Azure Machine Learning. Naučte se ladit hyperparametry.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Definování prostoru pro hledání parametrů
Můžete definovat architektury modelů a hyperparametry, které se mají v prostoru parametrů uklidit. Můžete zadat jednu architekturu modelu nebo více modelů.
- Seznam podporovaných architektur modelů pro jednotlivé typy úloh najdete v jednotlivých zkušebních verzích .
- Viz Hyperparametry pro úlohy počítačového zpracování obrazu hyperparametry pro každý typ úlohy počítačového zpracování obrazu.
- Podrobnosti o podporovaných distribucích najdete v samostatných a průběžných hyperparametrech.
Metody vzorkování pro úklid
Při úklidu hyperparametrů je potřeba zadat metodu vzorkování, která se má použít k úklidu nad definovaným prostorem parametrů. V současné době jsou s parametrem sampling_algorithm podporovány následující metody vzorkování:
| Typ vzorkování | Syntaxe úlohy AutoML |
|---|---|
| Náhodné vybrání vzorků | random |
| Vzorkování mřížky | grid |
| Bayesský vzorkování | bayesian |
Poznámka:
V současné době podporují podmíněné hyperparametry pouze náhodné vzorkování a vzorkování mřížky.
Zásady předčasného ukončení
U zásad předčasného ukončení můžete automaticky ukončit neúspěšné pokusy. Předčasné ukončení zlepšuje výpočetní efektivitu a šetří výpočetní prostředky, které by jinak byly vynaloženy na méně slibné pokusy. Automatizované strojové učení pro image podporuje následující zásady předčasného ukončení s využitím tohoto parametru early_termination . Pokud není zadána žádná zásada ukončení, všechny zkušební verze se spustí až po dokončení.
| Zásady předčasného ukončení | Syntaxe úlohy AutoML |
|---|---|
| Zásady bandit | CLI v2: bandit SDK v2: BanditPolicy() |
| Zásady zastavení mediánu | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Zásady výběru zkrácení | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
Přečtěte si další informace o tom, jak nakonfigurovat zásady předčasného ukončení pro úklid hyperparametrů.
Poznámka:
Kompletní ukázku konfigurace úklidu najdete v tomto kurzu.
Můžete nakonfigurovat všechny parametry související s úklidem, jak je znázorněno v následujícím příkladu.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Pevná nastavení
Můžete předat pevná nastavení nebo parametry, které se během úklidu prostoru parametrů nemění, jak je znázorněno v následujícím příkladu.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Rozšíření dat
Obecně platí, že výkon modelu hlubokého učení se může často zlepšit s více daty. Rozšíření dat je praktická technika, jak rozšířit velikost dat a variabilitu datové sady, což pomáhá zabránit přeurčení a zlepšit schopnost zobecnění modelu u nezobrazených dat. Automatizované strojové učení používá různé techniky rozšiřování dat na základě úlohy počítačového zpracování obrazu před podáváním vstupních obrázků do modelu. V současné době není k dispozici žádný zpřístupněný hyperparametr pro řízení rozšiřování dat.
| Úloha | Ovlivněná datová sada | Použité techniky rozšiřování dat |
|---|---|---|
| Klasifikace obrázků (více tříd a více popisků) | Školení Ověřování a testování |
Náhodná změna velikosti a oříznutí, vodorovné překlopení, změna barvy (jas, kontrast, sytost a odstín), normalizace pomocí střední hodnoty a směrodatné odchylky imagenetu Změna velikosti, středového oříznutí, normalizace |
| Rozpoznávání objektů, segmentace instancí | Školení Ověřování a testování |
Náhodné oříznutí kolem ohraničujících polí, rozbalení, vodorovné překlopení, normalizace, změna velikosti Normalizace, změna velikosti |
| Rozpoznávání objektů pomocí yolov5 | Školení Ověřování a testování |
Mozaika, náhodný affine (otočení, překlad, měřítko, stříšku), vodorovné překlopení Změna velikosti poštovní schránky |
V současné době se rozšíření definovaná výše použijí ve výchozím nastavení pro automatizované strojové učení pro úlohu image. Pokud chcete zajistit kontrolu nad rozšířeními, automatizované strojové učení pro obrázky zveřejňuje pod dvěma příznaky, aby se určité rozšíření vypnulo. V současné době jsou tyto příznaky podporovány pouze pro úlohy detekce objektů a segmentace instancí.
- apply_mosaic_for_yolo: Tento příznak je specifický pouze pro model Yolo. Nastavením hodnoty False vypnete rozšiřování dat o mozaikách, které se použije v době trénování.
-
apply_automl_train_augmentations: Nastavení tohoto příznaku na false vypne rozšíření použité během trénování pro modely detekce objektů a segmentace instancí. Informace o rozšířeních najdete v podrobnostech v tabulce výše.
- U modelů detekce objektů a modelů segmentace instancí, které nejsou yolo, tento příznak vypne pouze první tři rozšíření. Příklad: Náhodné oříznutí kolem ohraničujících polí, rozbalení, vodorovné překlopení. Normalizace a změna velikosti rozšíření se stále použijí bez ohledu na tento příznak.
- U modelu Yolo tento příznak vypne náhodnou affinu a horizontální překlopení.
Tyto dva příznaky jsou podporovány prostřednictvím advanced_settings pod training_parameters a lze je řídit následujícím způsobem.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Všimněte si, že tyto dva příznaky jsou nezávislé na sobě a lze je použít také v kombinaci pomocí následujících nastavení.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
V našich experimentech jsme zjistili, že tyto rozšíření pomáhají modelu lépe generalizovat. Proto když jsou tyto rozšíření vypnuté, doporučujeme uživatelům, aby je zkombinovali s dalšími offline rozšířeními, aby získali lepší výsledky.
Přírůstkové trénování (volitelné)
Po dokončení trénovací úlohy můžete model dále trénovat načtením kontrolního bodu natrénovaného modelu. Pro přírůstkové trénování můžete použít stejnou datovou sadu nebo jinou datovou sadu. Pokud jste s modelem spokojení, můžete zastavit trénování a použít aktuální model.
Předání kontrolního bodu prostřednictvím ID úlohy
Id úlohy, ze které chcete kontrolní bod načíst, můžete předat.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Odeslání úlohy AutoML
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Pokud chcete odeslat úlohu AutoML, spusťte následující příkaz CLI v2 s cestou k souboru .yml, názvu pracovního prostoru, skupině prostředků a ID předplatného.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Výstupy a metriky vyhodnocení
Automatizované trénovací úlohy ML generují výstupní soubory modelu, vyhodnocovací metriky, protokoly a artefakty nasazení, jako je soubor bodování a soubor prostředí. Tyto soubory a metriky se dají zobrazit na kartě výstupy a protokoly a metriky podřízených úloh.
Definice a příklady výkonnostních grafů a metrik poskytovaných pro každou úlohu najdete v tématu Vyhodnocení výsledků experimentů automatizovaného strojového učení.
Registrace a nasazení modelu
Po dokončení úlohy můžete zaregistrovat model vytvořený z nejlepší zkušební verze (konfigurace, která způsobila nejlepší primární metriku). Model můžete zaregistrovat po stažení nebo zadáním cesty azureml s odpovídajícím ID úlohy. Poznámka: Pokud chcete změnit nastavení odvozování, která jsou popsána níže, musíte stáhnout model a změnit settings.json a zaregistrovat pomocí aktualizované složky modelu.
Získání nejlepší zkušební verze
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
CLI example not available, please use Python SDK.
registrace modelu
Zaregistrujte model buď pomocí cesty azureml, nebo místně stažené cesty.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Jakmile zaregistrujete model, který chcete použít, můžete ho nasadit pomocí spravovaného online koncového bodu deploy-managed-online-endpoint.
Konfigurace online koncového bodu
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Vytvoření koncového bodu
Pomocí dříve vytvořeného MLClient koncového bodu vytvoříme v pracovním prostoru koncový bod. Tento příkaz spustí vytvoření koncového bodu a během vytváření koncového bodu vrátí potvrzovací odpověď.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Konfigurace online nasazení
Nasazení je sada prostředků vyžadovaných pro hostování modelu, který provádí skutečné odvozování. Pomocí třídy vytvoříme nasazení pro náš koncový bod ManagedOnlineDeployment . Pro cluster nasazení můžete použít skladové položky virtuálních počítačů s gpu nebo procesorem.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Vytvoření nasazení
Pomocí dříve vytvořeného MLClient prostředí teď vytvoříme nasazení v pracovním prostoru. Tento příkaz spustí vytvoření nasazení a během vytváření nasazení vrátí potvrzovací odpověď.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
aktualizace provozu:
Ve výchozím nastavení je aktuální nasazení nastavené na příjem 0% provozu. Můžete nastavit procento provozu, které by mělo aktuální nasazení přijímat. Součet procent provozu všech nasazení s jedním koncovým bodem by neměl překročit 100 %.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Případně můžete model nasadit z uživatelského rozhraní studio Azure Machine Learning. Přejděte na model, který chcete nasadit, na kartě Modely automatizované úlohy ML a vyberte možnost Nasadit a vyberte Nasadit do koncového bodu v reálném čase .
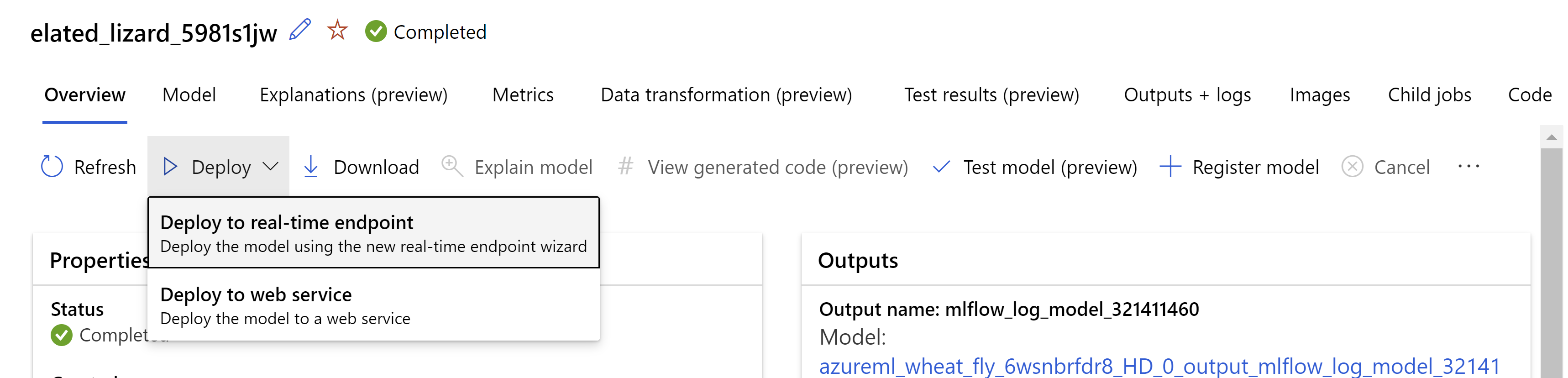 .
.
takto vypadá vaše stránka s recenzemi. Můžeme vybrat typ instance, počet instancí a nastavit procento provozu pro aktuální nasazení.
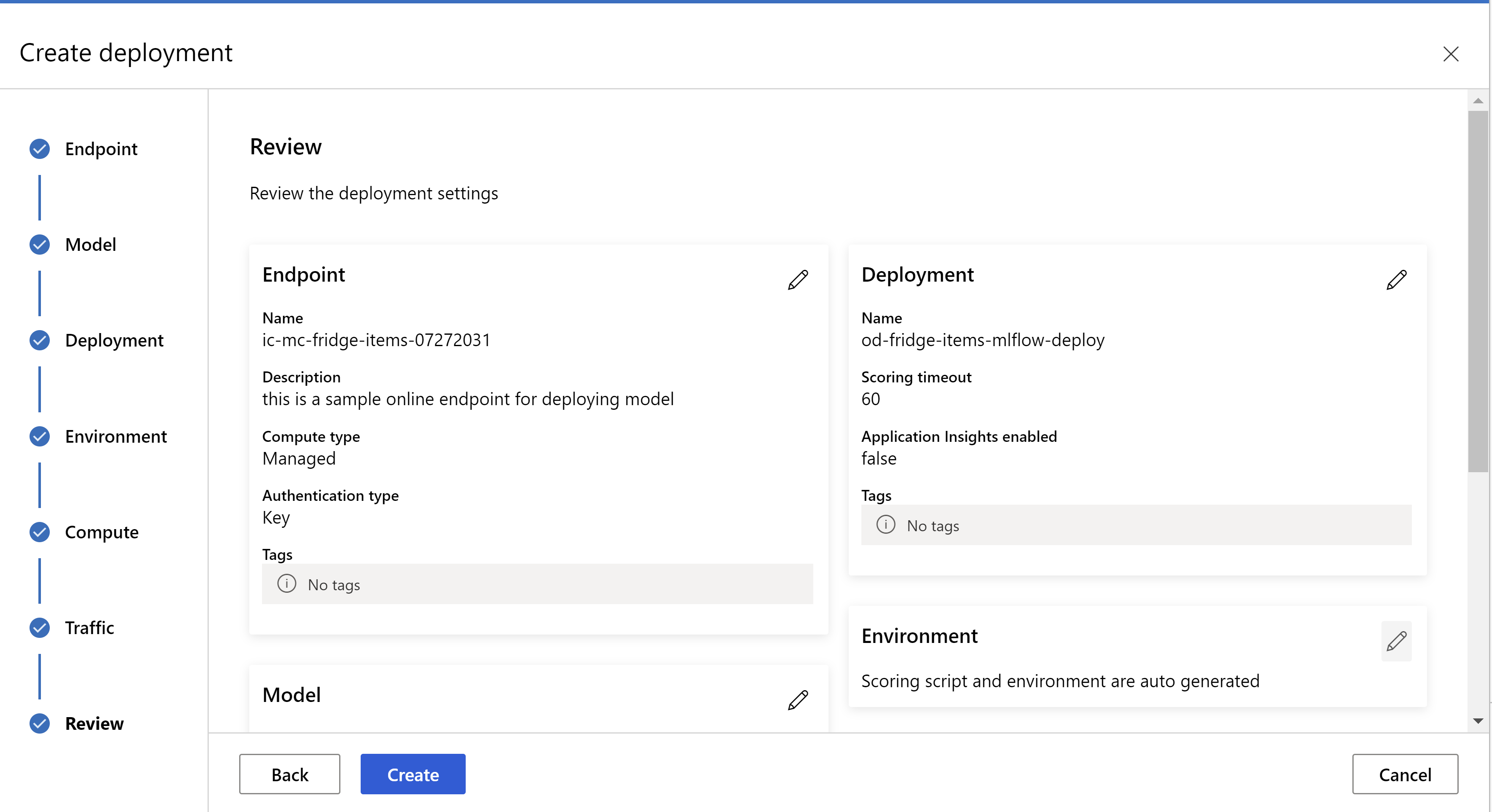 .
.
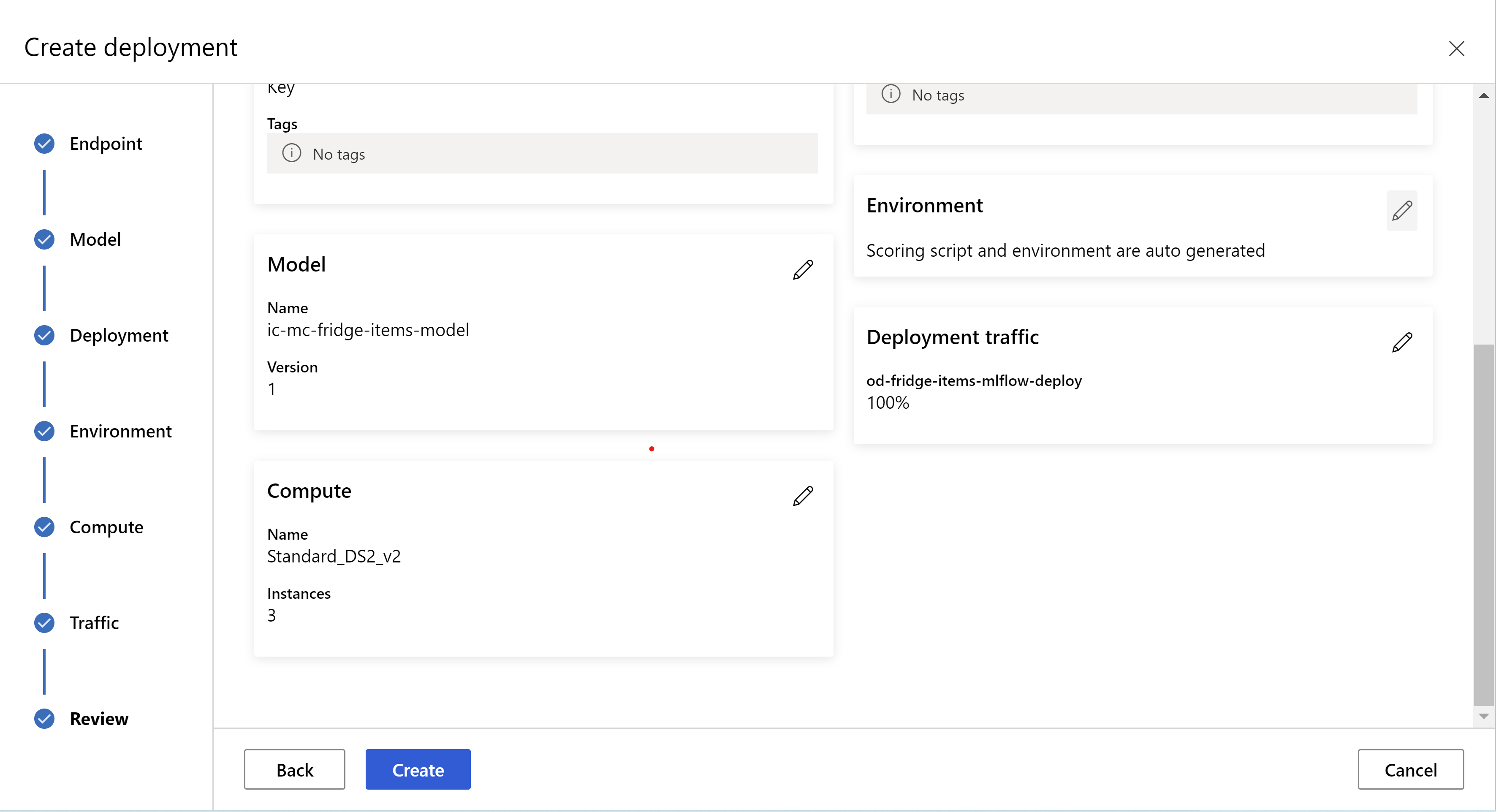 .
.
Aktualizace nastavení odvození
V předchozím kroku jsme stáhli soubor mlflow-model/artifacts/settings.json z nejlepšího modelu. které lze použít k aktualizaci nastavení odvozování před registrací modelu. I když se doporučuje použít stejné parametry jako trénování pro zajištění nejlepšího výkonu.
Každý z úkolů (a některé modely) má sadu parametrů. Ve výchozím nastavení používáme stejné hodnoty pro parametry, které byly použity během trénování a ověřování. V závislosti na chování, které potřebujeme při použití modelu pro odvozování, můžeme tyto parametry změnit. Níže najdete seznam parametrů pro každý typ úlohy a model.
| Úloha | Název parametru | Výchozí |
|---|---|---|
| Klasifikace obrázků (více tříd a více popisků) | valid_resize_sizevalid_crop_size |
256 224 |
| Detekce objektů | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
Rozpoznávání objektů pomocí yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 střední 0,1 0.5 |
| Segmentace instancí | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 False JPG |
Podrobný popis hyperparametrů specifických pro úlohu najdete v hyperparametrech pro úlohy počítačového zpracování obrazu v automatizovaném strojovém učení.
Pokud chcete použít provázání a chcete řídit chování provazování, jsou k dispozici následující parametry: tile_grid_sizetile_overlap_ratio a tile_predictions_nms_thresh. Další podrobnosti o těchtoparametrch
Otestování nasazení
Zkontrolujte tuto část Testování nasazení a otestujte nasazení a vizualizovat detekce z modelu.
Generování vysvětlení pro předpovědi
Důležité
Tato nastavení jsou aktuálně ve verzi Public Preview. Poskytují se bez smlouvy o úrovni služeb. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Upozorňující
Vysvětlení modelů je podporováno pouze pro klasifikaci více tříd a klasifikaci více popisků.
Některé z výhod použití explainable AI (XAI) s AutoML pro obrázky:
- Zlepšuje transparentnost předpovědí modelu komplexního zpracování obrazu.
- Pomáhá uživatelům pochopit důležité funkce a pixely na vstupním obrázku, které přispívají k předpovědím modelu.
- Pomáhá při řešení potíží s modely.
- Pomáhá při zjišťování předsudků.
Vysvětlení
Vysvětlení jsou přisuzování nebo váhy jednotlivých pixelů na vstupním obrázku na základě jeho příspěvku k predikci modelu. Každá váha může být záporná (negativní korelace s predikcí) nebo kladná (pozitivní korelace s predikcí). Tyto přisuzování se počítají s předpovězenou třídou. U klasifikace s více třídami se pro každou ukázku vygeneruje přesně jedna atribuční matice velikosti [3, valid_crop_size, valid_crop_size] , zatímco pro klasifikaci více popisků se pro každý predikovaný popisek a třídu pro každý vzorek vygeneruje matice přiřazení velikosti [3, valid_crop_size, valid_crop_size] .
Pomocí vysvětlitelné umělé inteligence v AutoML pro obrázky na nasazeném koncovém bodu můžou uživatelé získat vizualizace vysvětlení (připisování překryvné na vstupním obrázku) a/nebo přiřazení (multidimenzionální pole velikosti [3, valid_crop_size, valid_crop_size]) pro každou image. Kromě vizualizací můžou uživatelé získat také matici přisuzování, aby získali větší kontrolu nad vysvětleními (například generování vlastních vizualizací pomocí přisuzování nebo kontrolou segmentů přisuzování). Všechny algoritmy vysvětlení používají oříznuté čtvercové obrázky s velikostí valid_crop_size pro generování přisuzování.
Vysvětlení je možné vygenerovat buď z online koncového bodu , nebo z dávkového koncového bodu. Po dokončení nasazení je možné tento koncový bod využít k vygenerování vysvětlení předpovědí. V online nasazeních nezapomeňte předat request_settings = OnlineRequestSettings(request_timeout_ms=90000) parametr a nastavit request_timeout_ms jeho maximální hodnotu, abyste se vyhnuli problémům s vypršením časového limitu při generování vysvětlení (viz část registrace ManagedOnlineDeployment a nasazení modelu). Některé metody vysvětlitelnosti (XAI) jako xrai spotřebovávají více času (speciálně pro klasifikaci s více popisky, protože potřebujeme generovat popisky a/nebo vizualizace pro každý predikovaný popisek). Proto doporučujeme pro rychlejší vysvětlení libovolnou instanci GPU. Další informace o vstupním a výstupním schématu pro generování vysvětlení najdete v dokumentaci ke schématu.
Podporujeme následující nejmodernější algoritmy vysvětlení v AutoML pro obrázky:
- XRAI (xrai)
- Integrované přechody (integrated_gradients)
- GradCAM s asistencí (guided_gradcam)
- BackPropagation s asistencí (guided_backprop)
Následující tabulka popisuje parametry ladění specifické pro algoritmus vysvětlitelnosti pro XRAI a integrované přechody. Průvodce backpropagací a průvodce gradcam nevyžadují žádné parametry ladění.
| Algoritmus XAI | Parametry specifické pro algoritmus | Výchozí hodnoty |
|---|---|---|
xrai |
1. n_steps: Počet kroků používaných metodou aproximace. Větší počet kroků vede k lepším aproximacím přisuzování (vysvětlení). Rozsah n_steps je [2, inf), ale výkon přisuzování začíná konvergovat po 50 krocích. Optional, Int 2. xrai_fast: Zda použít rychlejší verzi XRAI. pokud Trueje výpočet času pro vysvětlení rychlejší, ale vede k méně přesným vysvětlením (přisuzování). Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: Počet kroků používaných metodou aproximace. Větší počet kroků vede k lepšímu přiřazení (vysvětlení). Rozsah n_steps je [2, inf), ale výkon přisuzování začíná konvergovat po 50 krocích.Optional, Int 2. approximation_method: Metoda pro aproximování integrálu. Dostupné metody aproximace jsou riemann_middle a gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Interně algoritmus XRAI používá integrované přechody. Parametr je tedy vyžadován jak integrovanými přechody, n_steps tak algoritmy XRAI. Větší počet kroků spotřebovává více času pro přibližné vysvětlení a může vést k problémům s vypršením časového limitu online koncového bodu.
Pro lepší vysvětlení doporučujeme používat integrované přechody XRAI > Řízené přechody > GradCAM > s asistencí, zatímco pro rychlejší vysvětlení v zadaném pořadí se doporučuje integrované přechody > GradCAM > s asistencí BackPropagation>.
Ukázkový požadavek na online koncový bod vypadá následovně. Tento požadavek generuje vysvětlení, pokud model_explainability je nastavena na True. Následující požadavek generuje vizualizace a přisuzování pomocí rychlejší verze algoritmu XRAI s 50 kroky.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Další informace o generování vysvětlení najdete v úložišti poznámkových bloků GitHubu pro ukázky automatizovaného strojového učení.
Interpretace vizualizací
Nasazený koncový bod vrátí řetězec obrázku s kódováním base64, pokud je nastaven na Truehodnotu obamodel_explainability.visualizations Dekódujte řetězec base64, jak je popsáno v poznámkových blocích , nebo pomocí následujícího kódu dekódujte a vizualizujete řetězce obrázků base64 v predikci.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
Následující obrázek popisuje vizualizaci vysvětlení ukázkového vstupního obrázku.

Dekódovaný obrázek base64 má čtyři části obrázků v mřížce 2 x 2.
- Obrázek v levém horním rohu (0, 0) je oříznutý vstupní obrázek.
- Obrázek v pravém horním rohu (0, 1) je heat mapa přisuzování na barevné škále bgyw (modrá žlutá bílá), kde příspěvek bílých pixelů v predikované třídě je nejvyšší a modré pixely je nejnižší.
- Obrázek v levém dolním rohu (1, 0) je vymíchaná heat mapa přiřazujících na oříznutém vstupním obrázku.
- Obrázek v pravém dolním rohu (1, 1) je oříznutý vstupní obrázek s nejvyšším 30 procentem pixelů na základě skóre přisuzování.
Interpretace přisuzování
Nasazený koncový bod vrátí atribuce, pokud jsou obě model_explainability a attributions jsou nastaveny na True. Další podrobnosti najdete v poznámkových blocích klasifikace s více třídami a více popisků.
Tyto přisuzování poskytují uživatelům větší kontrolu nad generováním vlastních vizualizací nebo kontrolou skóre přisuzování na úrovni pixelů. Následující fragment kódu popisuje způsob generování vlastních vizualizací pomocí matice přisuzování. Další informace o schématu přisuzování pro klasifikaci s více třídami a klasifikaci s více popisky najdete v dokumentaci ke schématu.
Pomocí přesných valid_resize_size hodnot a valid_crop_size hodnot vybraného modelu vygenerujte vysvětlení (výchozí hodnoty jsou 256 a 224). Následující kód používá funkce vizualizace Captum k vygenerování vlastních vizualizací. Uživatelé můžou ke generování vizualizací využít jakoukoli jinou knihovnu. Další podrobnosti najdete v nástrojích pro vizualizaci captum.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Velké datové sady
Pokud k trénování velkých datových sad používáte AutoML, můžou být užitečná některá experimentální nastavení.
Důležité
Tato nastavení jsou aktuálně ve verzi Public Preview. Poskytují se bez smlouvy o úrovni služeb. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Trénování s více GPU a více uzly
Ve výchozím nastavení se každý model trénuje na jednom virtuálním počítači. Pokud trénování modelu trvá příliš dlouho, může pomoct použití virtuálních počítačů, které obsahují více GPU. Doba trénování modelu u velkých datových sad by se měla snížit v zhruba lineárním poměru k počtu použitých grafických procesorů. (Například model by měl na virtuálním počítači s dvěma GPU trénovat zhruba dvakrát tak rychle jako na virtuálním počítači s jedním GPU.) Pokud je čas na trénování modelu na virtuálním počítači s více grafickými procesory stále vysoký, můžete zvýšit počet virtuálních počítačů použitých k trénování jednotlivých modelů. Podobně jako u trénování s více GPU by se doba trénování modelu u velkých datových sad měla také snížit v zhruba lineárním poměru k počtu použitých virtuálních počítačů. Při trénování modelu napříč několika virtuálními počítači nezapomeňte použít výpočetní skladovou položku, která podporuje InfiniBand , aby se zajistily nejlepší výsledky. Počet virtuálních počítačů použitých k trénování jednoho modelu můžete nakonfigurovat nastavením node_count_per_trial vlastnosti úlohy AutoML.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
properties:
node_count_per_trial: "2"
Streamování souborů obrázků z úložiště
Ve výchozím nastavení se všechny soubory obrázků stáhnou na disk před trénováním modelu. Pokud je velikost souborů obrázků větší než dostupné místo na disku, úloha selže. Místo stahování všech imagí na disk můžete vybrat, že chcete streamovat soubory obrázků z úložiště Azure, jak jsou potřeba během trénování. Soubory obrázků se streamují z úložiště Azure přímo do systémové paměti a obcházejí disk. Současně je na disku co nejvíce souborů uložených v mezipaměti, aby se minimalizoval počet požadavků na úložiště.
Poznámka:
Pokud je povolené streamování, ujistěte se, že se účet úložiště Azure nachází ve stejné oblasti jako výpočetní prostředky, aby se minimalizovaly náklady a latence.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Příklady poznámkových bloků
Podrobné příklady kódu a případy použití najdete v ukázkách automatizovaného strojového učení v úložišti poznámkových bloků na GitHubu. Ve složkách s předponou automl-image zkontrolujte ukázky specifické pro vytváření modelů počítačového zpracování obrazu.
Příklady kódu
Projděte si podrobné příklady kódu a případy použití v úložišti azureml-examples pro ukázky automatizovaného strojového učení.