Přístup k datům z cloudového úložiště Azure během interaktivního vývoje
PLATÍ PRO:  Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)
Projekt strojového učení obvykle začíná průzkumnou analýzou dat (EDA), předzpracováním dat (čištění, příprava funkcí) a zahrnuje vytváření prototypů modelu ML pro ověření hypotéz. Tato fáze projektu vytváření prototypů je v podstatě vysoce interaktivní a hodí se k vývoji v poznámkovém bloku Jupyter nebo v integrovaném vývojovém prostředí s interaktivní konzolou Pythonu. V tomto článku se dozvíte, jak:
- Přístup k datům z identifikátoru URI úložiště dat služby Azure Machine Learning, jako by šlo o systém souborů.
- Materializace dat do Pandas pomocí knihovny Pythonu
mltable - Materializace datových prostředků služby Azure Machine Learning do Pandas pomocí knihovny Pythonu
mltable - Materializace dat prostřednictvím explicitního stažení pomocí
azcopynástroje.
Požadavky
- Pracovní prostor služby Azure Machine Learning. Další informace najdete v tématu Správa pracovních prostorů Služby Azure Machine Learning na portálu nebo pomocí sady Python SDK (v2).
- Úložiště dat služby Azure Machine Learning Další informace najdete v tématu Vytváření úložišť dat.
Tip
Pokyny v tomto článku popisují přístup k datům během interaktivního vývoje. Platí pro každého hostitele, který může spustit relaci Pythonu. To může zahrnovat váš místní počítač, cloudový virtuální počítač, GitHub Codespace atd. Doporučujeme použít výpočetní instanci Azure Machine Learning – plně spravovanou a předem nakonfigurovanou cloudovou pracovní stanici. Další informace najdete v tématu Vytvoření výpočetní instance služby Azure Machine Learning.
Důležité
Ujistěte se, že máte v prostředí Python nainstalované nejnovější azure-fsspecknihovny a mltableazure-ai-ml knihovny Pythonu:
pip install -U azureml-fsspec==1.3.1 mltable azure-ai-ml
Nejnovější azure-fsspec verze balíčku se může v průběhu času měnit. Další informace o balíčku najdete v azure-fsspec tomto prostředku.
Přístup k datům z identifikátoru URI úložiště dat, jako je systém souborů
Úložiště dat Azure Machine Learning je odkazem na existující účet úložiště Azure. Mezi výhody vytváření a používání úložiště dat patří:
- Běžné snadno použitelné rozhraní API pro interakci s různými typy úložiště (Blob/Files/ADLS).
- Snadné zjišťování užitečných úložišť dat v týmových operacích
- Podpora přístupu k datům na základě přihlašovacích údajů (například tokenu SAS) i přístupu na základě identity (použití Microsoft Entra ID nebo Manged identity).
- V případě přístupu na základě přihlašovacích údajů jsou informace o připojení zabezpečené pro ohrožení klíče void ve skriptech.
- Procházejte data a zkopírujte identifikátory URI úložiště dat v uživatelském rozhraní studia.
Identifikátor URI úložiště dat je identifikátor uniform resource identifier, což je odkaz na umístění úložiště (cestu) ve vašem účtu úložiště Azure. Identifikátor URI úložiště dat má tento formát:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Tyto identifikátory URI úložiště dat představují známou implementaci specifikace systému souborů (fsspec): jednotné pythonické rozhraní pro místní, vzdálené a vložené systémy souborů a úložiště bajtů. Nejprve pomocí nástroje pip nainstalujte azureml-fsspec balíček a jeho balíček závislostí azureml-dataprep . Pak můžete použít implementaci úložiště fsspec dat služby Azure Machine Learning.
Implementace úložiště fsspec dat Azure Machine Learning automaticky zpracovává předávání přihlašovacích údajů nebo identity, které používá úložiště dat Azure Machine Learning. V výpočetní instanci se můžete vyhnout ohrožení klíče účtu ve vašich skriptech a dalších přihlašovacích procedurách.
Můžete například přímo použít identifikátory URI úložiště dat v knihovně Pandas. Tento příklad ukazuje, jak číst soubor CSV:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Tip
Abyste se vyhnuli zapamatování formátu identifikátoru URI úložiště dat, můžete zkopírovat a vložit identifikátor URI úložiště dat z uživatelského rozhraní studia pomocí následujícího postupu:
- V nabídce vlevo vyberte Data a pak vyberte kartu Úložiště dat.
- Vyberte název úložiště dat a pak vyberte Procházet.
- Najděte soubor nebo složku, kterou chcete číst do pandas, a vyberte tři tečky (...) vedle něj. V nabídce vyberte Kopírovat identifikátor URI . Můžete vybrat identifikátor URI úložiště dat, který chcete zkopírovat do poznámkového bloku nebo skriptu.
Můžete také vytvořit instanci systému souborů Azure Machine Learning pro zpracování příkazů podobných systému souborů , například ls, glob, existsopen.
- Metoda
ls()uvádí soubory v určitém adresáři. K výpisu souborů můžete použít ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>). Podporujeme jak '.', tak i '..', v relativních cestách. - Metoda
glob()podporuje globbing '*' a '**'. - Metoda
exists()vrátí logickou hodnotu, která označuje, zda zadaný soubor existuje v aktuálním kořenovém adresáři. - Metoda
open()vrátí objekt podobný souboru, který lze předat jakékoli jiné knihovně, která očekává, že bude pracovat se soubory Pythonu. Váš kód může tento objekt také použít, jako by se jednalo o normální objekt souboru pythonu. Tyto objekty podobné souboru respektují použitíwithkontextů, jak je znázorněno v tomto příkladu:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Nahrání souborů přes AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath je místní cesta a rpath je to vzdálená cesta.
Pokud zadané složky rpath ještě neexistují, vytvoříme pro vás složky.
Podporujeme tři režimy přepisování:
- APPEND: Pokud v cílové cestě existuje soubor se stejným názvem, funkce APPEND zachová původní soubor.
- FAIL_ON_FILE_CONFLICT: Pokud v cílové cestě existuje soubor se stejným názvem, FAIL_ON_FILE_CONFLICT vyvolá chybu.
- MERGE_WITH_OVERWRITE: Pokud v cílové cestě existuje soubor se stejným názvem, MERGE_WITH_OVERWRITE přepíše stávající soubor novým souborem.
Stažení souborů přes AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Příklady
Tyto příklady ukazují použití specifikace systému souborů v běžných scénářích.
Čtení jednoho souboru CSV do Pandas
Do Pandas můžete přečíst jeden soubor CSV, jak je znázorněno na obrázku:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Čtení složky souborů CSV do Pandas
Metoda Pandas read_csv() nepodporuje čtení složky souborů CSV. Abyste to zvládli, zřetěďte cesty csv a zřetězením je do datového rámce pomocí metody Pandas concat() . Následující ukázka kódu ukazuje, jak tuto zřetězení dosáhnout pomocí systému souborů Azure Machine Learning:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Čtení souborů CSV do Dask
Tento příklad ukazuje, jak číst soubor CSV do datového rámce Dask:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Čtení složky souborů parquet do Pandas
V rámci procesu ETL se soubory Parquet obvykle zapisují do složky, která pak může generovat soubory relevantní pro ETL, jako je průběh, potvrzení atd. Tento příklad ukazuje soubory vytvořené z procesu ETL (soubory začínající _) a potom vytvoří soubor parquet dat.
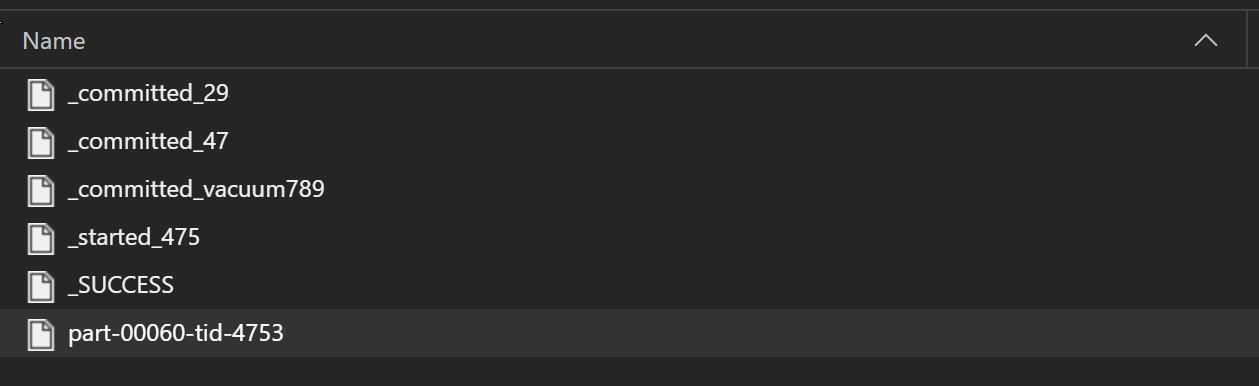
V těchto scénářích budete číst pouze soubory parquet ve složce a ignorovat soubory procesu ETL. Tento vzorový kód ukazuje, jak můžou vzory globů číst jen soubory parquet ve složce:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Přístup k datům ze systému souborů Azure Databricks (dbfs)
Specifikace systému souborů (fsspec) má řadu známých implementací, včetně systému souborů Databricks (dbfs).
Pokud chcete získat přístup k datům dbfs z prostředku, potřebujete:
- Název instance ve formě .
adb-<some-number>.<two digits>.azuredatabricks.netTuto hodnotu najdete v adrese URL pracovního prostoru Azure Databricks. - Token PAT (Personal Access Token) – další informace o vytváření PAT najdete v tématu Ověřování pomocí tokenů pat pro osobní přístup k Azure Databricks.
Pomocí těchto hodnot musíte vytvořit proměnnou prostředí pro token PAT ve výpočetní instanci:
export ADB_PAT=<pat_token>
Pak můžete přistupovat k datům v Knihovně Pandas, jak je znázorněno v tomto příkladu:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Čtení obrázků pomocí pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Příklad vlastní datové sady PyTorch
V tomto příkladu vytvoříte vlastní datovou sadu PyTorch pro zpracování obrázků. Předpokládáme, že existuje soubor poznámek (ve formátu CSV) s touto celkovou strukturou:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Podsložky ukládají tyto obrázky podle jejich popisků:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Vlastní třída datové sady PyTorch musí implementovat tři funkce: __init____len__, a __getitem__, jak je znázorněno zde:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
Potom můžete vytvořit instanci datové sady, jak je znázorněno tady:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Materializace dat do Pandas pomocí mltable knihovny
Knihovna mltable může také pomoct získat přístup k datům v cloudovém úložišti. Čtení dat do Pandas s tímto obecným formátem mltable :
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Podporované cesty
Knihovna mltable podporuje čtení tabulkových dat z různých typů cest:
| Umístění | Příklady |
|---|---|
| Cesta na místním počítači | ./home/username/data/my_data |
| Cesta na veřejném serveru HTTP | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Cesta ve službě Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Dlouhodobé úložiště dat služby Azure Machine Learning | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Poznámka:
mltable provede předávání přihlašovacích údajů uživatele pro cesty ve službě Azure Storage a úložištích dat Azure Machine Learning. Pokud nemáte oprávnění pro přístup k datům v podkladovém úložišti, nemůžete k nim získat přístup.
Soubory, složky a globy
mltable podporuje čtení z:
- soubor(y) – například:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - složky – například
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - vzory globů – například
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - kombinace souborů, složek a/nebo vzorů globbingu
mltable Flexibilita umožňuje materializaci dat do jednoho datového rámce z kombinace místních a cloudových prostředků úložiště a kombinací souborů, složek/globů. Příklad:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Podporované formáty souborů
mltable podporuje následující formáty souborů:
- Text s oddělovači (například soubory CSV):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - Formát řádků JSON:
mltable.from_json_lines_files(paths=[path])
Příklady
Čtení souboru CSV
Aktualizujte zástupné symboly (<>) v tomto fragmentu kódu pomocí konkrétních podrobností:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Čtení souborů parquet ve složce
Tento příklad ukazuje, jak mltable se dají použít vzory globu ( například zástupné cardy), aby se zajistilo, že se čtou jenom soubory parquet.
Aktualizujte zástupné symboly (<>) v tomto fragmentu kódu pomocí konkrétních podrobností:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Čtení datových prostředků
V této části se dozvíte, jak získat přístup k datovým prostředkům služby Azure Machine Learning v Pandas.
Asset tabulky
Pokud jste dříve vytvořili prostředek tabulky ve službě Azure Machine Learning (neboli mltableV1 TabularDataset), můžete tento prostředek tabulky načíst do Pandas pomocí tohoto kódu:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Asset souboru
Pokud jste registrovali prostředek souboru (například soubor CSV), můžete tento prostředek přečíst do datového rámce Pandas pomocí tohoto kódu:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Asset složky
Pokud jste zaregistrovali asset složky (uri_folder nebo V1 FileDataset), například složku obsahující soubor CSV, můžete tento prostředek přečíst do datového rámce Pandas pomocí tohoto kódu:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Poznámka ke čtení a zpracování velkých objemů dat pomocí Pandas
Tip
Pandas není navržený tak, aby zpracovával velké datové sady. Pandas může zpracovávat pouze data, která se můžou vejít do paměti výpočetní instance.
U velkých datových sad doporučujeme použít Spark spravovaný službou Azure Machine Learning. To poskytuje rozhraní API PySpark Pandas.
Před vertikálním navýšením kapacity na vzdálenou asynchronní úlohu můžete chtít rychle iterovat menší podmnožinu velké datové sady. mltable poskytuje integrované funkce pro získání ukázek velkých dat pomocí metody take_random_sample :
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
Pomocí těchto operací můžete také vzít podmnožinu velkých dat:
Stahování dat pomocí azcopy nástroje
azcopy Pomocí nástroje stáhněte data do místního disku SSD hostitele (místní počítač, cloudový virtuální počítač, výpočetní instance služby Azure Machine Learning atd.) do místního systému souborů. Nástroj azcopy , který je předinstalovaný ve výpočetní instanci služby Azure Machine Learning, zpracovává stahování dat. Pokud nepoužíváte výpočetní instanci služby Azure Machine Learning nebo virtuální počítač Datová Věda (DSVM), možná budete muset nainstalovat azcopy. Další informace najdete v azcopy.
Upozornění
Nedoporučujeme stahovat data do /home/azureuser/cloudfiles/code umístění výpočetní instance. Toto umístění je navržené tak, aby ukládaly artefakty poznámkového bloku a kódu, ne data. Čtení dat z tohoto umístění způsobí při trénování značné režijní náklady na výkon. Místo toho doporučujeme úložiště dat v úložišti home/azureuser, což je místní SSD výpočetního uzlu.
Otevřete terminál a vytvořte nový adresář, například:
mkdir /home/azureuser/data
Přihlášení k azcopy pomocí:
azcopy login
Dále můžete kopírovat data pomocí identifikátoru URI úložiště.
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST