Posouzení systémů AI pomocí řídicího panelu Zodpovědné AI
Implementace zodpovědné umělé inteligence v praxi vyžaduje důkladné inženýrství. Ale důkladné inženýrství může být zdlouhavé, ruční a časově náročné bez správného nástroje a infrastruktury.
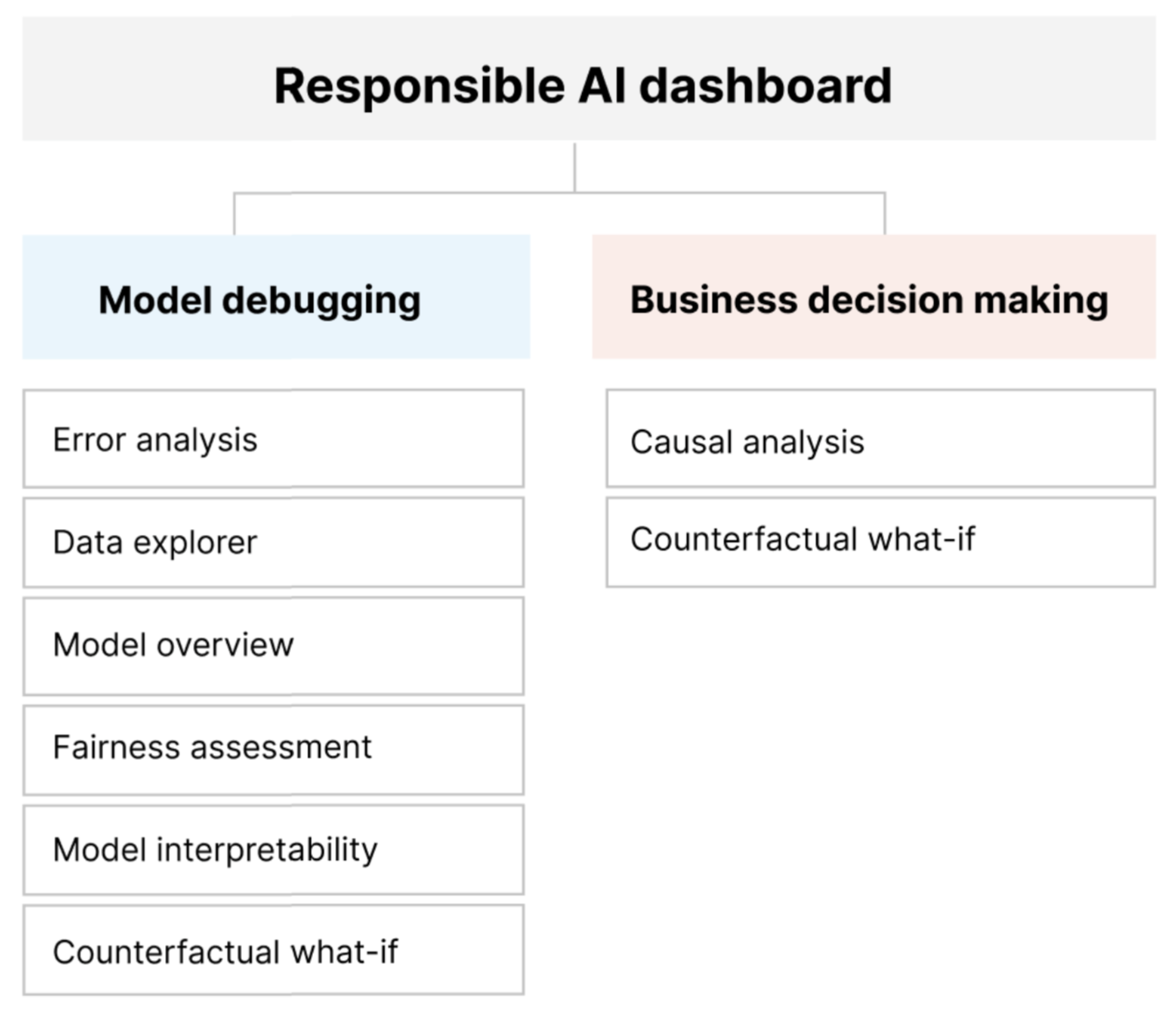
Řídicí panel Zodpovědné AI poskytuje jediné rozhraní, které vám pomůže efektivně a efektivně implementovat zodpovědné AI. Spojuje několik vyspělých nástrojů zodpovědné umělé inteligence v oblastech:
- Posouzení výkonu modelu a nestrannosti
- zkoumání dat
- Interpretovatelnost strojového učení
- Analýza chyb
- Kontrafaktuální analýza a perturbace
- Kauzální odvození
Řídicí panel nabízí ucelené posouzení a ladění modelů, abyste mohli provádět informovaná rozhodnutí založená na datech. Přístup ke všem těmto nástrojům v jednom rozhraní vám umožní:
Vyhodnoťte a ladíte modely strojového učení tím, že identifikujete chyby modelu a problémy s nestranností, diagnostikou, proč k těmto chybám dochází, a informujte své kroky pro zmírnění rizik.
Zvyšte své rozhodovací schopnosti řízené daty tím, že řešíte otázky, jako jsou:
"Jaká je minimální změna, kterou můžou uživatelé použít u svých funkcí, aby získali jiný výsledek než model?"
"Jaký je kauzální účinek snížení nebo zvýšení funkce (například spotřeba červeného masa) na skutečný výsledek (například průběh cukrovky)?"
Řídicí panel můžete přizpůsobit tak, aby zahrnoval pouze podmnožinu nástrojů, které jsou relevantní pro váš případ použití.
Řídicí panel Zodpovědné AI je doprovázen přehledem výkonnostních metrik PDF. Přehled výkonnostních metrik umožňuje exportovat metadata zodpovědné umělé inteligence a přehledy o datech a modelech. Pak je můžete sdílet offline se zúčastněnými stranami produktu a dodržování předpisů.
Zodpovědné komponenty řídicího panelu AI
Řídicí panel Zodpovědné umělé inteligence spojuje v komplexním zobrazení různé nové a předem existující nástroje. Řídicí panel tyto nástroje integruje s Azure Machine Learning CLI v2, sadou Azure Machine Learning Python SDK v2 a studio Azure Machine Learning. Mezi tyto nástroje patří:
- Analýza dat, abyste porozuměli a prozkoumali distribuce a statistiky datových sad.
- Přehled modelu a posouzení nestrannosti, vyhodnocení výkonu modelu a vyhodnocení problémů se skupinami modelu (vliv predikcí modelu na různorodé skupiny lidí)
- Analýza chyb pro zobrazení a pochopení způsobu distribuce chyb ve vaší datové sadě
- Interpretovatelnost modelu (hodnoty důležitosti pro agregované a jednotlivé funkce) pro pochopení předpovědí modelu a způsobu jejich celkové a individuální předpovědi.
- Kontrafaktuální citlivostní analýza, abyste mohli sledovat, jak by perturbace funkcí ovlivnily predikce modelu a současně poskytovaly nejbližší datové body protichůdným nebo jiným předpovědím modelu.
- Kauzální analýza, použití historických dat k zobrazení kauzálních účinků funkcí léčby na reálné výsledky.
Tyto nástroje vám společně pomůžou ladit modely strojového učení a zároveň informovat vaše obchodní rozhodnutí řízená daty a modelem. Následující diagram ukazuje, jak je můžete začlenit do životního cyklu umělé inteligence, abyste zlepšili modely a získali solidní přehledy dat.
Ladění modelů
Vyhodnocení a ladění modelů strojového učení je důležité pro spolehlivost modelu, interpretovatelnost, nestrannost a dodržování předpisů. Pomáhá určit, jak a proč se systémy AI chovají způsobem. Tyto znalosti pak můžete použít ke zlepšení výkonu modelu. Ladění modelu se koncepčně skládá ze tří fází:
Pokud chcete zjistit a rozpoznat chyby modelu nebo problémy s nestranností, vyřešte následující otázky:
"Jaké druhy chyb můj model má?"
"V jakých oblastech jsou chyby nejrozšířenější?"
Diagnostikujte a prozkoumejte příčiny zjištěných chyb jejich vyřešením:
"Jaké jsou příčiny těchto chyb?"
"Kde mám zaměřit prostředky na vylepšení modelu?"
Pokud chcete zmírnit potíže s identifikací a diagnostikou z předchozích fází, proveďte cílené kroky pro zmírnění rizik a vyřešte otázky, jako jsou:
"Jak můžu svůj model vylepšit?"
"Jaká sociální nebo technická řešení pro tyto problémy existují?"

Následující tabulka popisuje, kdy použít komponenty řídicího panelu Zodpovědné AI pro podporu ladění modelů:
| Fáze | Komponenta | Popis |
|---|---|---|
| Identifikovat | Analýza chyb | Komponenta analýzy chyb pomáhá lépe porozumět distribuci selhání modelu a rychle identifikovat chybné kohorty (podskupiny) dat. Možnosti této komponenty na řídicím panelu pocházejí z balíčku Analýza chyb. |
| Identifikovat | Analýza nestrannosti | Komponenta spravedlnosti definuje skupiny z hlediska citlivých atributů, jako je sex, rasa a věk. Pak posoudí, jak předpovědi modelu ovlivňují tyto skupiny a jak můžete zmírnit rozdíly. Vyhodnocuje výkon modelu prozkoumáním rozdělení hodnot predikce a hodnot metrik výkonu modelu napříč skupinami. Možnosti této komponenty na řídicím panelu pocházejí z balíčku Fairlearn . |
| Identifikovat | Přehled modelů | Komponenta přehledu modelu agreguje metriky hodnocení modelů v zobrazení distribuce predikce modelu na vysoké úrovni, aby se lépe prošetření jejího výkonu lépe prošetření. Tato komponenta také umožňuje posouzení nestrannosti skupin tím, že zvýrazní rozpis výkonu modelu napříč citlivými skupinami. |
| Diagnostikovat | Analýza dat | Analýza dat vizualizuje datové sady na základě předpovídaného a skutečného výsledku, skupin chyb a konkrétních funkcí. Pak můžete identifikovat problémy s překryvnou a podrepresí a zjistit, jak jsou data v datové sadě clusterovaná. |
| Diagnostika | Interpretovatelnost modelů | Komponenta interpretability generuje vysvětlení předpovědí modelu strojového učení pochopitelné člověkem. Poskytuje více zobrazení chování modelu: – Globální vysvětlení (například to, které funkce ovlivňují celkové chování modelu přidělování úvěrů) - Místní vysvětlení (například proč byla žádost o půjčku žadatele schválena nebo odmítnuta) Možnosti této komponenty na řídicím panelu pocházejí z balíčku InterpretML . |
| Diagnostika | Kontrafaktuální analýza a citlivostní analýza | Tato komponenta se skládá ze dvou funkcí pro lepší diagnostiku chyb: - Generování sady příkladů, ve kterých minimální změny konkrétního bodu mění predikci modelu. To znamená, že příklady ukazují nejbližší datové body s opačnými předpověďmi modelu. – Povolení interaktivních a vlastních perturbací jednotlivých datových bodů, aby bylo jasné, jak model reaguje na změny funkcí. Možnosti této komponenty na řídicím panelu pocházejí z balíčku DiCE . |
Kroky pro zmírnění rizik jsou k dispozici prostřednictvím samostatných nástrojů, jako je Fairlearn. Další informace najdete v algoritmech pro zmírnění nespravedlivosti.
Zodpovědné rozhodování
Rozhodování je jedním z největších příslibů strojového učení. Řídicí panel Zodpovědné umělé inteligence vám může pomoct provádět informovaná obchodní rozhodnutí prostřednictvím:
Přehledy řízené daty, abychom lépe porozuměli příčinným účinkům na léčbu výsledku pomocí historických dat. Příklad:
"Jak by lék ovlivnil krevní tlak pacienta?"
"Jak by poskytování propagačních hodnot určitým zákazníkům ovlivnilo výnosy?"
Tyto přehledy jsou poskytovány prostřednictvím kauzální odvozování komponenty řídicího panelu.
Modelem řízené přehledy pro odpovědi na otázky uživatelů (například "Co můžu udělat, když příště získám jiný výsledek než umělá inteligence?"), aby mohli provést akci. Tyto přehledy jsou poskytovány datovým vědcům prostřednictvím kontrafaktuální komponenty citlivostní analýzy.

Průzkumné analýzy dat, kauzální odvozování a možnosti kontrafaktuální analýzy vám můžou pomoct činit informovaná rozhodnutí řízená modelem a daty zodpovědně.
Tyto komponenty řídicího panelu Zodpovědné umělé inteligence podporují zodpovědné rozhodování:
Analýza dat: Tady můžete znovu použít komponentu analýzy dat, abyste porozuměli distribucím dat a identifikovali překryvnost a podrepresentaci. Zkoumání dat je důležitou součástí rozhodování, protože není možné provádět informovaná rozhodnutí o kohortě, která je v datech zastoupena.
Kauzální odvozování: Kauzální komponenta odvozování odhaduje, jak se skutečný výsledek mění v přítomnosti zásahu. Pomáhá také vytvářet slibné zásahy simulací reakcí na funkce na různé zásahy a vytvořením pravidel pro určení, které kohorty populace by mohly těžit z konkrétního zásahu. Tyto funkce společně umožňují uplatňovat nové zásady a uplatňovat skutečné změny.
Možnosti této komponenty pocházejí z balíčku EconML , který odhaduje heterogenní účinky léčby z pozorování dat prostřednictvím strojového učení.
Kontrafaktuální analýza: Zde můžete znovu použít komponentu kontrafaktuální analýzy, abyste vygenerovaly minimální změny použité u funkcí datového bodu, které vedou k opačným předpovědím modelu. Například: Taylor by získal schválení půjčky od umělé inteligence, pokud vydělal 10 000 USD v ročním příjmu a měl dva méně kreditních karet otevřené.
Poskytnutí těchto informací uživatelům informuje jejich perspektivu. Využívá je o tom, jak mohou v budoucnu provést akci, aby získali požadovaný výsledek z umělé inteligence.
Možnosti této komponenty pocházejí z balíčku DiCE .
Důvody použití řídicího panelu Zodpovědné umělé inteligence
I když došlo k pokroku v jednotlivých nástrojích pro konkrétní oblasti zodpovědné umělé inteligence, datoví vědci často potřebují k komplexnímu vyhodnocení svých modelů a dat různé nástroje. Může být například nutné použít společně interpretovatelnost modelu a posouzení nestrannosti.
Pokud datoví vědci zjistí problém s nestranností u jednoho nástroje, musí přejít na jiný nástroj, aby pochopili, jaké faktory dat nebo modelů leží v kořenovém bodě problému, než podniknou nějaké kroky ke zmírnění rizik. Tento náročný proces dále komplikují následující faktory:
- Neexistuje žádné centrální místo, kde by bylo možné objevovat a učit se o nástrojích, a prodloužit tak dobu potřebnou k výzkumu a učení se nových technik.
- Různé nástroje vzájemně nekomunikují. Datoví vědci musí uspořádat datové sady, modely a další metadata při jejich předávání mezi nástroji.
- Metriky a vizualizace nejsou snadno srovnatelné a výsledky se těžko sdílejí.
Tento stav quo řeší řídicí panel zodpovědné umělé inteligence. Je to komplexní, ale přizpůsobitelný nástroj, který spojuje fragmentované prostředí na jednom místě. Umožňuje bezproblémově připojit k jediné přizpůsobitelné rozhraní pro ladění modelů a rozhodování řízené daty.
Pomocí řídicího panelu Zodpovědné AI můžete vytvořit kohorty datových sad, předat tyto kohorty všem podporovaným komponentám a sledovat stav modelu pro identifikované kohorty. Přehledy ze všechpodporovaných funkcí můžete dále porovnávat z různých podporovaných komponent.
Až budete připravení tyto přehledy sdílet s dalšími účastníky, můžete je snadno extrahovat pomocí přehledu výkonnostních metrik Zodpovědné AI PDF. Připojte sestavu PDF k sestavám dodržování předpisů nebo ji sdílejte s kolegy, abyste získali důvěru a získali jejich schválení.
Způsoby přizpůsobení řídicího panelu Zodpovědné umělé inteligence
Síla řídicího panelu zodpovědné umělé inteligence spočívá v jeho přizpůsobitelnosti. Umožňuje uživatelům navrhovat přizpůsobené, ucelené ladění modelů a rozhodovací pracovní postupy, které řeší jejich konkrétní potřeby.
Potřebujete nějakou inspiraci? Tady je několik příkladů, jak lze komponenty řídicího panelu sestavit a analyzovat scénáře různými způsoby:
| Zodpovědný tok řídicího panelu AI | Případ použití |
|---|---|
| Analýza dat analýzy > chyb přehledu > modelů | Identifikace chyb modelu a jejich diagnostika pochopením základní distribuce dat |
| > Přehled modelu analýzy dat posouzení > nestrannosti | Identifikace problémů s nestranností modelu a jejich diagnostika pochopením základní distribuce dat |
| Analýza kontrafaktuals analýzy chyb přehledu > modelů a citlivostní analýza > | Diagnostika chyb v jednotlivých instancích pomocí kontrafaktuální analýzy (minimální změna vedoucí k jiné predikci modelu) |
| Analýza dat přehledu > modelu | Vysvětlení původní příčiny chyb a problémů spravedlnosti zavedených prostřednictvím nerovnováhy dat nebo nedostatečné reprezentace konkrétní kohorty dat |
| > Přehled interpretovatelnosti modelu | Diagnostika chyb modelu prostřednictvím porozumění způsobu, jakým model provedl své předpovědi |
| Kauzální odvozování analýzy > dat | Rozlišovat mezi korelacemi a kauzalitami v datech nebo rozhodnout o nejlepších ošetřeních, které se mají použít k získání pozitivního výsledku |
| Interpretovatelnost > kauzální odvození | Informace o tom, zda faktory, které model používá k předpovědím, mají na skutečný výsledek příčinný vliv. |
| > Analýza čítačů analýzy dat a citlivostní analýza | Řešení otázek zákazníků ohledně toho, co může příště udělat, aby získali jiný výsledek než systém AI |
Lidé, kteří by měli používat řídicí panel Zodpovědné umělé inteligence
Následující uživatelé můžou k vytvoření vztahu důvěryhodnosti se systémy AI používat řídicí panel Zodpovědné AI a odpovídající přehled výkonnostních metrik Zodpovědné AI:
- Odborníci na strojové učení a datoví vědci, kteří mají zájem o ladění a vylepšení modelů strojového učení před nasazením
- Odborníci na strojové učení a datoví vědci, kteří mají zájem o sdílení záznamů o stavu modelu s produktovými manažery a obchodními účastníky za účelem vytvoření důvěryhodnosti a získání oprávnění k nasazení
- Produktoví manažeři a obchodní účastníci, kteří před nasazením kontrolují modely strojového učení
- Pracovníci pro rizika, kteří kontrolují modely strojového učení, aby porozuměli problémům se nestranností a spolehlivostí
- Poskytovatelé řešení umělé inteligence, kteří chtějí uživatelům vysvětlit rozhodnutí o modelu nebo jim pomoct zlepšit výsledek
- Odborníci v silně regulovaných prostorech, kteří potřebují kontrolovat modely strojového učení s regulačními orgány a auditory
Podporované scénáře a omezení
- Řídicí panel zodpovědné umělé inteligence v současné době podporuje regresní a klasifikační modely (binární a více tříd) natrénované na tabulkových strukturovaných datech.
- Řídicí panel Zodpovědné AI v současné době podporuje modely MLflow zaregistrované ve službě Azure Machine Learning pouze s příchutí sklearn (scikit-learn). Modely scikit-learn by měly implementovat
predict()/predict_proba()metody nebo by se měl zabalit do třídy, která implementujepredict()/predict_proba()metody. Modely musí být načístelné v prostředí komponent a musí být naváděné. - Řídicí panel zodpovědné umělé inteligence v současné době vizualizuje až 5 tisíc datových bodů v uživatelském rozhraní řídicího panelu. Před předáním datové sady na řídicí panel byste měli převzorkovat na 5 tisíc nebo méně.
- Vstupy datové sady na řídicí panel Zodpovědné umělé inteligence musí být datové rámce pandas ve formátu Parquet. NumPy a SciPy řídká data se v současné době nepodporují.
- Řídicí panel zodpovědné umělé inteligence v současné době podporuje číselné nebo kategorické funkce. U kategorických funkcí musí uživatel explicitně zadat názvy funkcí.
- Řídicí panel zodpovědné umělé inteligence v současné době nepodporuje datové sady s více než 10 tisíci sloupci.
- Řídicí panel Zodpovědné AI v současné době nepodporuje model AutoML MLFlow.
- Řídicí panel Zodpovědné AI v současné době nepodporuje registrované modely AutoML z uživatelského rozhraní.
Další kroky
- Zjistěte, jak vygenerovat řídicí panel zodpovědné umělé inteligence prostřednictvím rozhraní příkazového řádku a sady SDK nebo studio Azure Machine Learning uživatelského rozhraní.
- Zjistěte, jak vygenerovat přehled výkonnostních metrik zodpovědné umělé inteligence na základě přehledů zjištěných na řídicím panelu Zodpovědné umělé inteligence.