Odvozování a hodnocení modelů prognózování
Tento článek představuje koncepty související s odvozováním modelu a vyhodnocením v úlohách prognózování. Pokyny a příklady pro trénování modelů prognóz v AutoML najdete v tématu Nastavení autoML pro trénování modelu prognózování časových řad pomocí sady SDK a rozhraní příkazového řádku.
Po použití AutoML k trénování a výběru nejlepšího modelu je dalším krokem generování prognóz. Pokud je to možné, vyhodnoťte jejich přesnost na testovací sadě uchovávané z trénovacích dat. Informace o nastavení a spuštění vyhodnocování modelů prognóz v automatizovaném strojovém učení najdete v tématu Orchestrace trénování, odvozování a hodnocení.
Scénáře odvození
Ve strojovém učení je odvozování proces generování předpovědí modelu pro nová data, která se při trénování nepoužívají. Existují různé způsoby generování předpovědí v důsledku závislosti na čase dat. Nejjednodušším scénářem je, když se období odvozování okamžitě řídí trénovacím obdobím a vygenerujete předpovědi do horizontu prognózy. Tento scénář znázorňuje následující diagram:
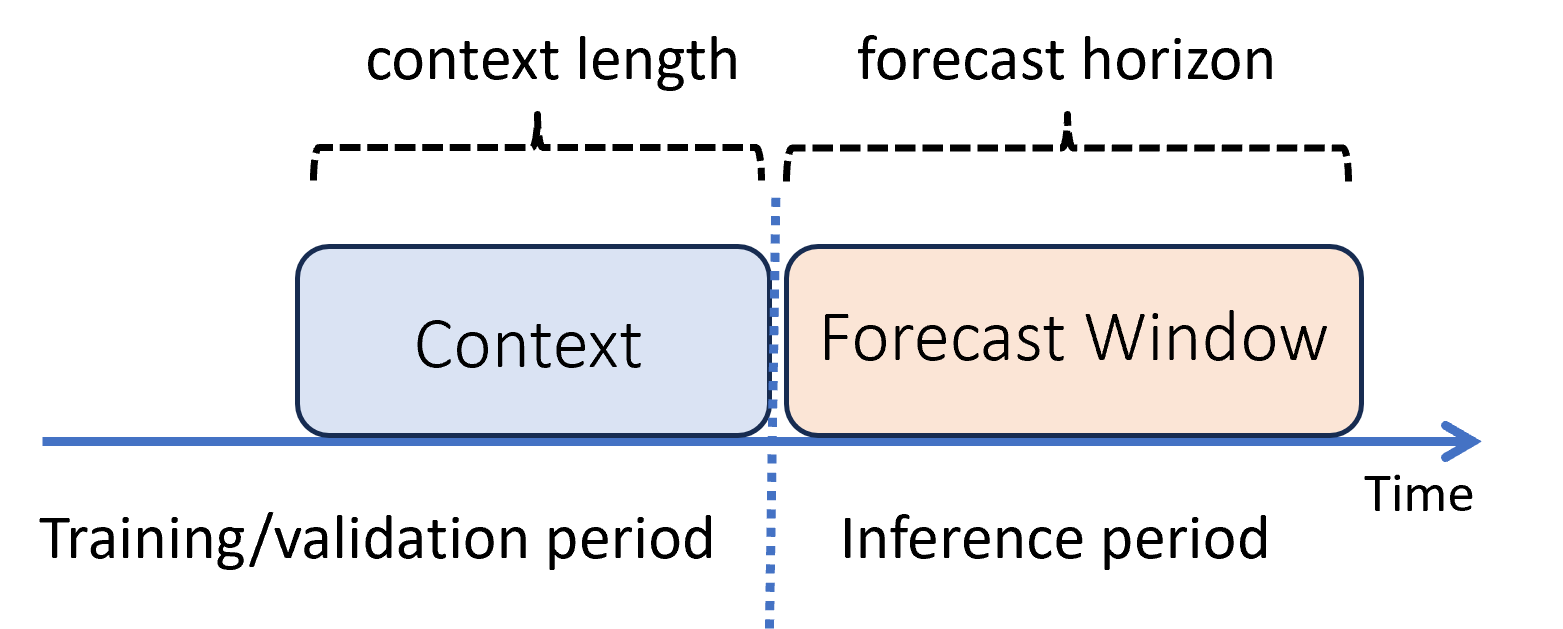
Diagram znázorňuje dva důležité parametry odvození:
- Délka kontextu je množství historie, kterou model vyžaduje k vytvoření prognózy.
- Horizont prognózy je, jak daleko dopředu se prognóza vytrénuje, aby předpověděla.
Modely prognózování obvykle používají některé historické informace, kontext, aby předpovědi byly předem v předstihu až do horizontu prognózy. Když je kontext součástí trénovacích dat, AutoML uloží, co potřebuje k vytváření prognóz. Není nutné ji explicitně zadávat.
Existují dva další scénáře odvození, které jsou složitější:
- Generování předpovědí dále do budoucnosti než horizont prognózy
- Získání předpovědí v případech, kdy mezi obdobími trénování a odvozování dochází k mezerám
Následující pododdíly tyto případy prověřují.
Předpovědět za horizont prognózy: rekurzivní prognózování
Pokud potřebujete prognózy za horizontem, AutoML použije model rekurzivně v období odvozování. Předpovědi z modelu se vrací jako vstup pro generování předpovědí pro následná okna prognózy. Následující diagram ukazuje jednoduchý příklad:
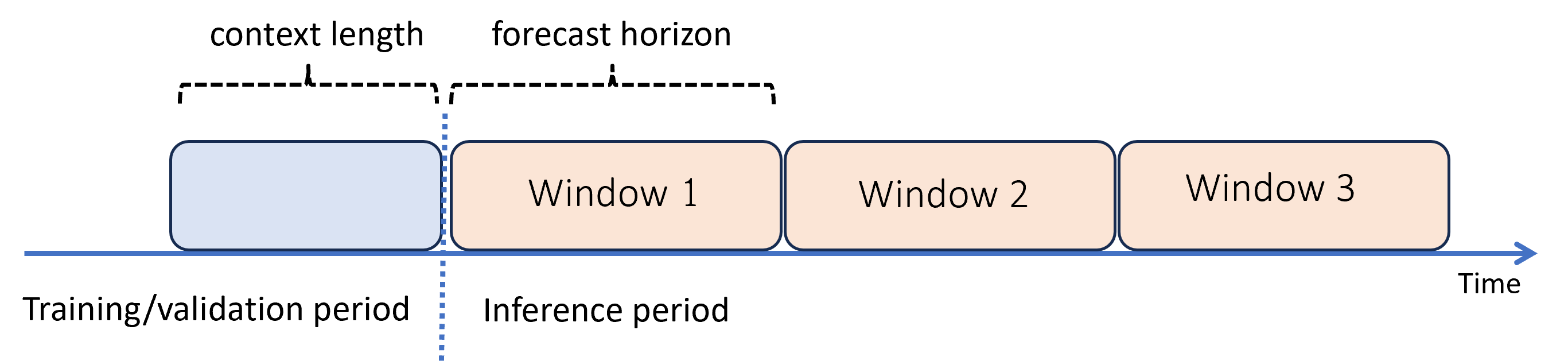
Strojové učení vygeneruje prognózy v období třikrát déle než horizont. Jako kontext pro další okno používá předpovědi z jednoho okna.
Upozorňující
Rekurzivní prognózování složených chyb modelování Předpovědi jsou méně přesné, čím dál jsou od původního horizontu prognózy. Přesnější model můžete najít opětovným trénováním s delším horizontem.
Predikce s mezerou mezi obdobími trénování a odvozování
Předpokládejme, že po vytrénování modelu ho chcete použít k předpovědím z nových pozorování, která ještě během trénování nebyla k dispozici. V tomto případě je mezi obdobími trénování a odvozování časová mezera:
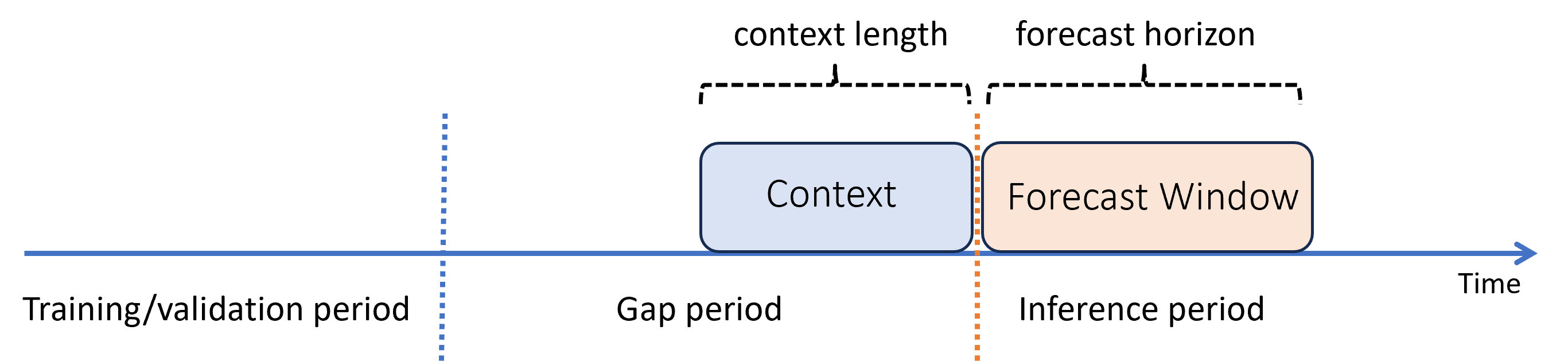
AutoML podporuje tento scénář odvozování, ale potřebujete zadat kontextová data v období mezery, jak je znázorněno v diagramu. Data předpovědi předaná komponentě odvozování potřebují hodnoty pro funkce a pozorované cílové hodnoty v mezerě a chybějící hodnoty nebo NaN hodnoty cíle v období odvozování. Následující tabulka ukazuje příklad tohoto vzoru:
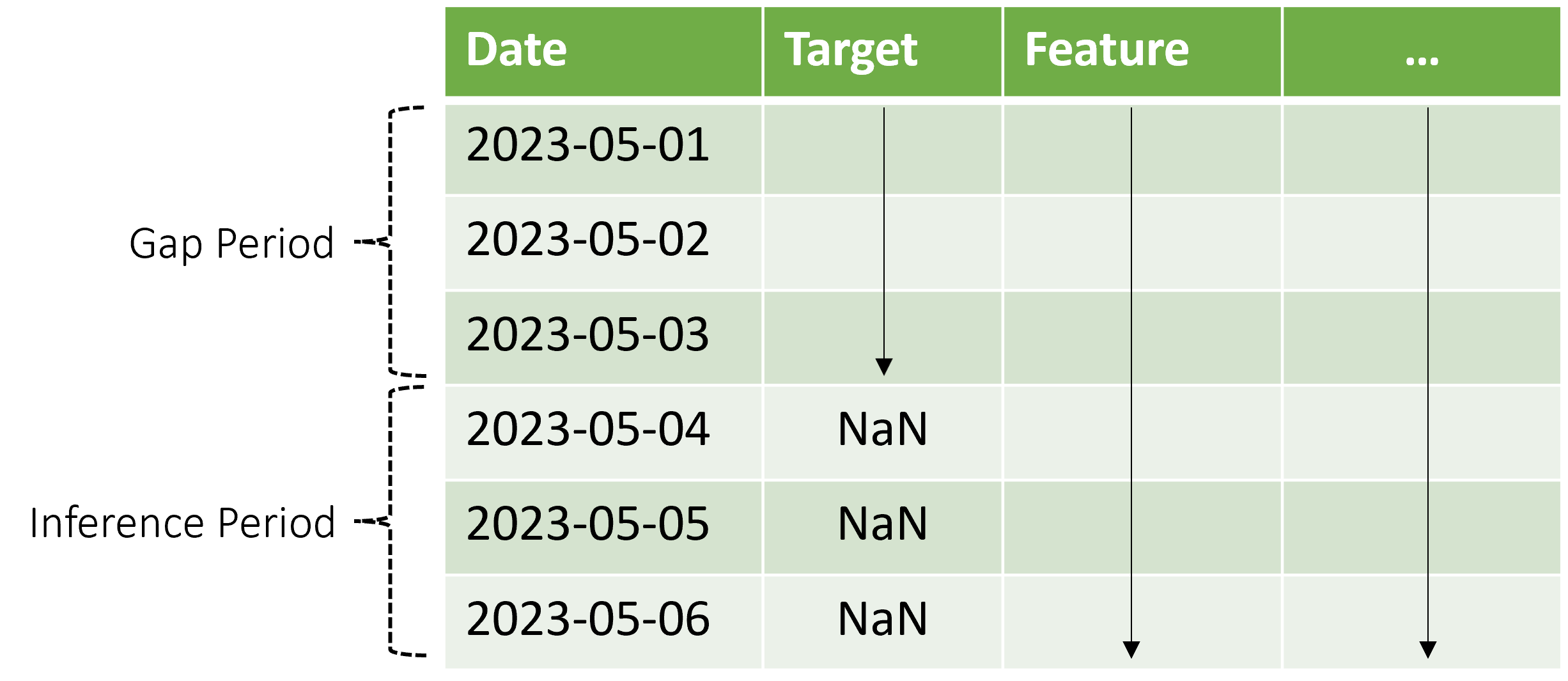
Známé hodnoty cíle a funkcí jsou poskytovány 2023-05-01 prostřednictvím 2023-05-03. Chybějící cílové hodnoty začínající na 2023-05-04 značce, že období odvozování začíná v daném datu.
AutoML používá nová kontextová data k aktualizaci prodlevy a dalších funkcí zpětného vyhledávání a také k aktualizaci modelů, jako je ARIMA, které udržují interní stav. Tato operace neaktualizuje ani nerefituje parametry modelu.
Vyhodnocení modelu
Vyhodnocení je proces generování predikcí na testovací sadě uchovávané z trénovacích dat a výpočetních metrik z těchto předpovědí, které řídí rozhodování o nasazení modelu. Proto existuje režim odvozování vhodný pro vyhodnocení modelu: průběžnou prognózu.
Osvědčeným postupem pro vyhodnocení modelu prognózování je převést natrénovaný prognózovací nástroj dopředu v průběhu testovací sady a průměrovat metriky chyb v několika oknech predikce. Tento postup se někdy nazývá backtest. V ideálním případě je testovací sada pro vyhodnocení dlouhá vzhledem k horizontu prognózy modelu. Odhady prognózovací chyby by jinak mohly být statisticky hlučné, a proto méně spolehlivé.
Následující diagram znázorňuje jednoduchý příklad se třemi okny prognózy:
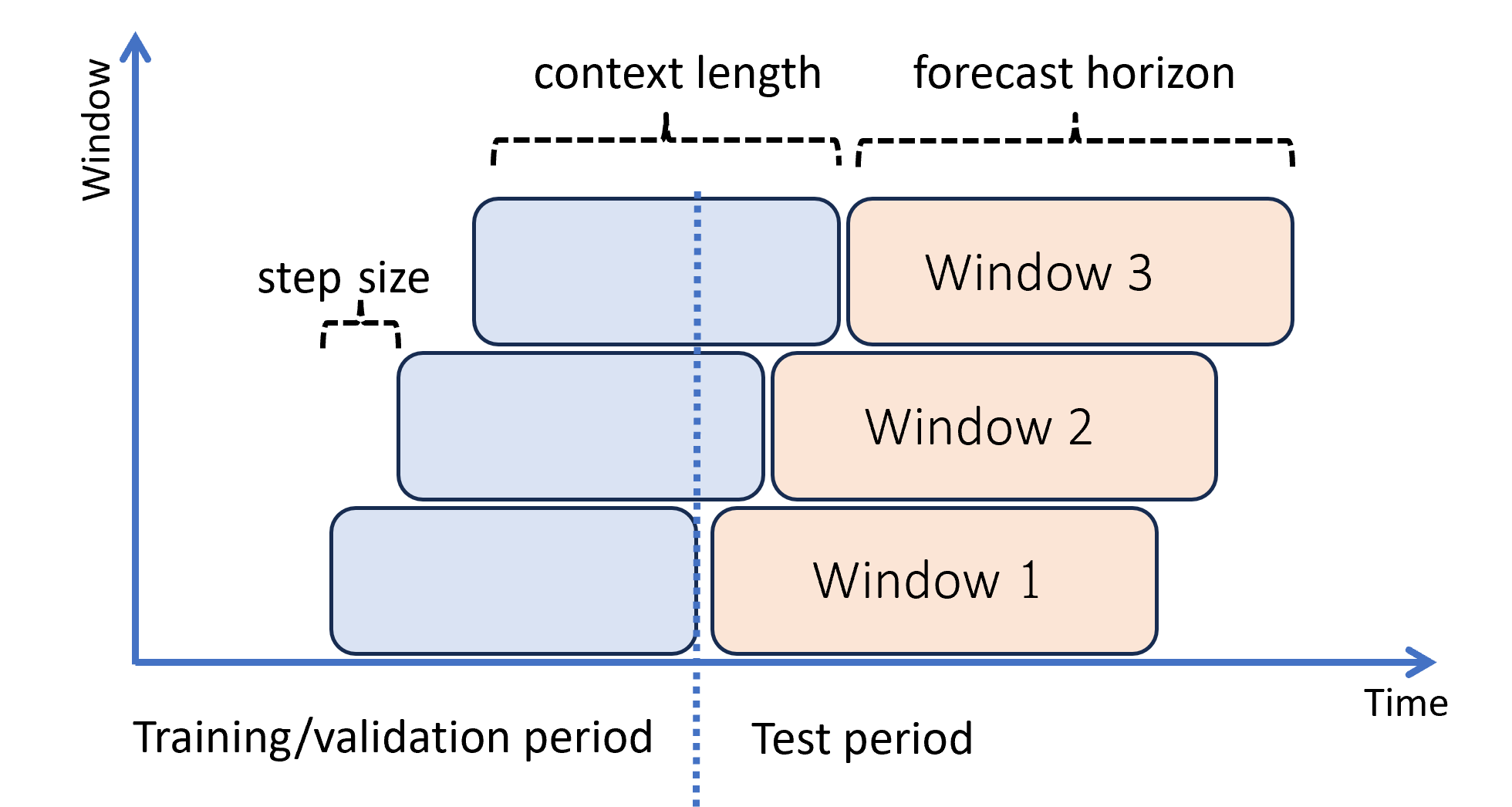
Diagram znázorňuje tři klouzavé parametry vyhodnocení:
- Délka kontextu je množství historie, kterou model vyžaduje k vytvoření prognózy.
- Horizont prognózy je, jak daleko dopředu se prognóza vytrénuje, aby předpověděla.
- Velikost kroku je to, jak daleko dopředu se posuvné okno posune na každou iteraci v testovací sadě.
Kontext se posune spolu s oknem prognózy. Skutečné hodnoty z testovací sady slouží k vytváření prognóz, když spadají do aktuálního kontextového okna. Nejnovější datum skutečných hodnot použitých pro dané okno prognózy se nazývá čas původu okna. Následující tabulka ukazuje příklad výstupu ze tříohlábové prognózy s horizontem tří dnů a velikostí kroku jednoho dne:
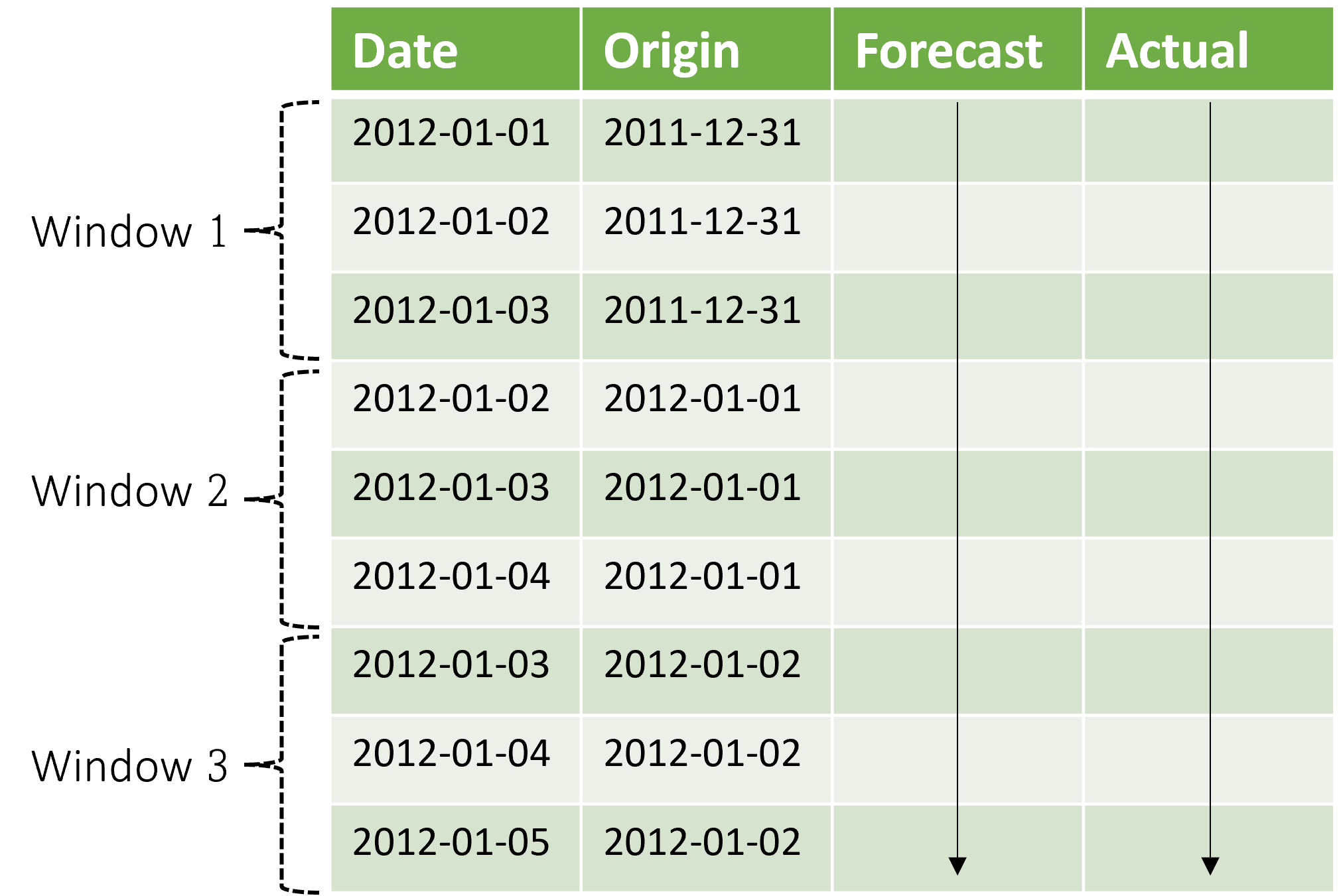
S tabulkou, jako je tato, můžete vizualizovat prognózy a skutečné hodnoty a vypočítat požadované metriky vyhodnocení. Kanály AutoML můžou generovat kumulativní prognózy v testovací sadě s komponentou odvozování.
Poznámka:
Pokud je testovací období stejné délky jako horizont prognózy, poskytuje průběžná prognóza jediné okno prognóz až do horizontu.
Metriky vyhodnocení
Konkrétní obchodní scénář obvykle řídí výběr souhrnu nebo metriky vyhodnocení. Mezi běžné volby patří následující příklady:
- Grafy pozorovaných cílových hodnot a předpovídajících hodnot za účelem kontroly, že určitá dynamika dat, která model zachycuje
- Střední absolutní procentuální chyba (MAPE) mezi skutečnými a předpovídanými hodnotami
- Odmocněná střední kvadratická chyba (RMSE), pravděpodobně s normalizací mezi skutečnými a předpovídanými hodnotami
- Střední absolutní chyba (MAE), pravděpodobně s normalizací mezi skutečnými a předpovídanými hodnotami
Existuje mnoho dalších možností v závislosti na obchodním scénáři. Možná budete muset vytvořit vlastní nástroje pro následné zpracování pro výpočetní metriky vyhodnocení z výsledků odvozování nebo průběžných prognóz. Další informace o metrikách najdete v tématu Regrese nebo prognózování metrik.
Související obsah
- Přečtěte si další informace o tom, jak nastavit AutoML pro trénování modelu prognózování časových řad.
- Přečtěte si, jak AutoML používá strojové učení k vytváření modelů prognózování.
- Přečtěte si odpovědi na nejčastější dotazy týkající se prognózování v AutoML.