Vyhodnocení komponenty modelu
Tento článek popisuje komponentu v návrháři služby Azure Machine Learning.
Tato komponenta slouží k měření přesnosti natrénovaného modelu. Zadáte datovou sadu obsahující skóre vygenerovaná z modelu a komponenta Vyhodnotit model vypočítá sadu standardních metrik vyhodnocení.
Metriky vrácené modelem vyhodnocení závisí na typu modelu, který vyhodnocujete:
- Klasifikační modely
- Regresní modely
- Modely clusteringu
Tip
Pokud s hodnocením modelů začínáte, doporučujeme série videí dr. Stephena Elstona jako součást kurzu strojového učení z EdX.
Jak používat vyhodnocovaný model
Připojte výstup vyhodnocené datové sady výstupu skóre modelu nebo výsledné datové sady přiřazení dat clusterům k levému vstupnímu portu vyhodnocení modelu.
Poznámka:
Pokud k výběru části vstupní datové sady použijete komponenty, jako je Výběr sloupců v datové sadě, ujistěte se, že sloupec Skutečné popisky (použitý při trénování), sloupec Scored Probabilities (Skóre pravděpodobností) a Sloupec Scored Labels (Skóre popisků) existují k výpočtu metrik, jako je AUC, Přesnost pro detekci binární klasifikace nebo anomálií. Skutečný sloupec popisku, sloupec Scored Labels existuje k výpočtu metrik pro klasifikaci nebo regresi s více třídami. Sloupec Přiřazení, sloupce DistancesToClusterCenter no.X (X je centroidový index v rozsahu od 0, ..., počet centroidů-1) existují k výpočtu metrik pro clustering.
Důležité
- Pokud chcete vyhodnotit výsledky, měla by výstupní datová sada obsahovat konkrétní názvy sloupců skóre, které splňují požadavky na komponentu Vyhodnotit model.
- Sloupec
Labelsbude považován za skutečné popisky. - Pro regresní úlohu musí datová sada, která se má vyhodnotit, musí mít jeden sloupec s názvem
Regression Scored Labels, který představuje popisky skóre. - U úlohy binární klasifikace musí mít datová sada, která se má vyhodnotit, dva sloupce s názvem
Binary Class Scored Labels,Binary Class Scored Probabilitieskteré představují popisky skóre a pravděpodobnosti. - U úlohy s více klasifikacemi musí datová sada, která se má vyhodnotit, musí mít jeden sloupec s názvem
Multi Class Scored Labels, který představuje popisky skóre. Pokud výstupy upstreamové komponenty tyto sloupce neobsahují, musíte je upravit podle výše uvedených požadavků.
[Volitelné] Připojte výstup vyhodnocené datové sady výstupu skóre modelu nebo výsledku datové sady přiřazení dat clusterům pro druhý model ke správnému vstupnímu portu vyhodnocení modelu. Výsledky ze dvou různých modelů můžete snadno porovnat se stejnými daty. Dva vstupní algoritmy by měly být stejného typu algoritmu. Nebo můžete porovnat skóre ze dvou různých běhů na stejných datech s různými parametry.
Poznámka:
Typ algoritmu odkazuje na "Klasifikace se dvěma třídami", "Klasifikace s více třídami", "Regrese", "Clustering" v části Algoritmy strojového učení.
Odešlete kanál, který vygeneruje hodnocení.
Výsledky
Po spuštění funkce Vyhodnotit model vyberte komponentu, aby se na pravé straně otevřel navigační panel Vyhodnotit model . Pak zvolte kartu Výstupy + Protokoly a na této kartě oddíl Výstupy dat má několik ikon. Ikona Vizualizujte má ikonu pruhového grafu a je první způsob, jak zobrazit výsledky.
U binární klasifikace můžete po kliknutí na ikonu Vizualizovat vizualizovat binární konfuzní matici. Pro více klasifikací najdete soubor s konfuzní maticí na kartě Výstupy a protokoly , například takto:
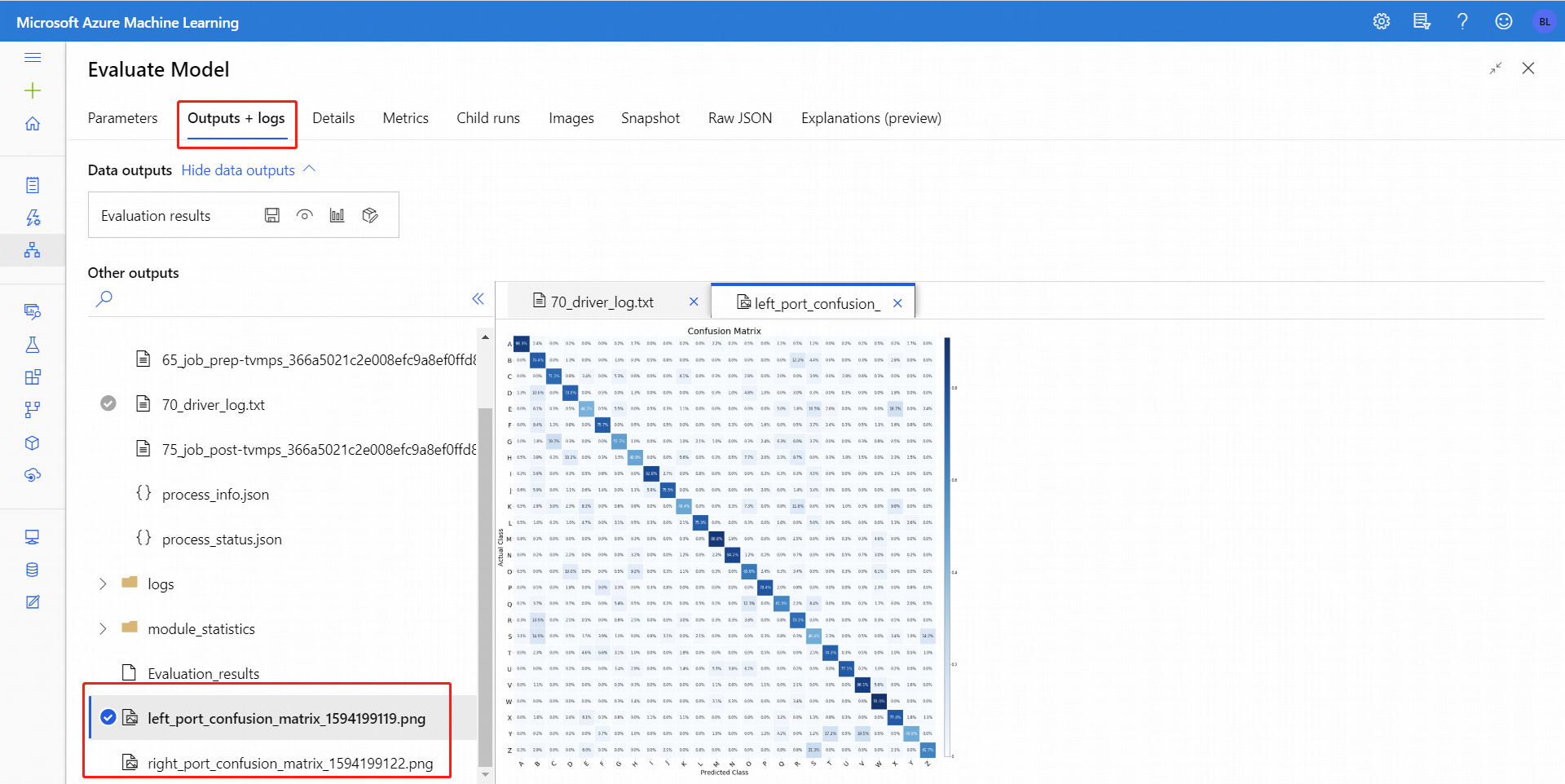
Pokud datové sady propojíte s oběma vstupy vyhodnocovaného modelu, výsledky budou obsahovat metriky pro obě sady dat nebo oba modely. Model nebo data připojená k levému portu se zobrazí jako první v sestavě a za ní metriky datové sady nebo modelu připojeného na pravém portu.
Následující obrázek například představuje porovnání výsledků ze dvou modelů clusteringu, které byly založeny na stejných datech, ale s různými parametry.
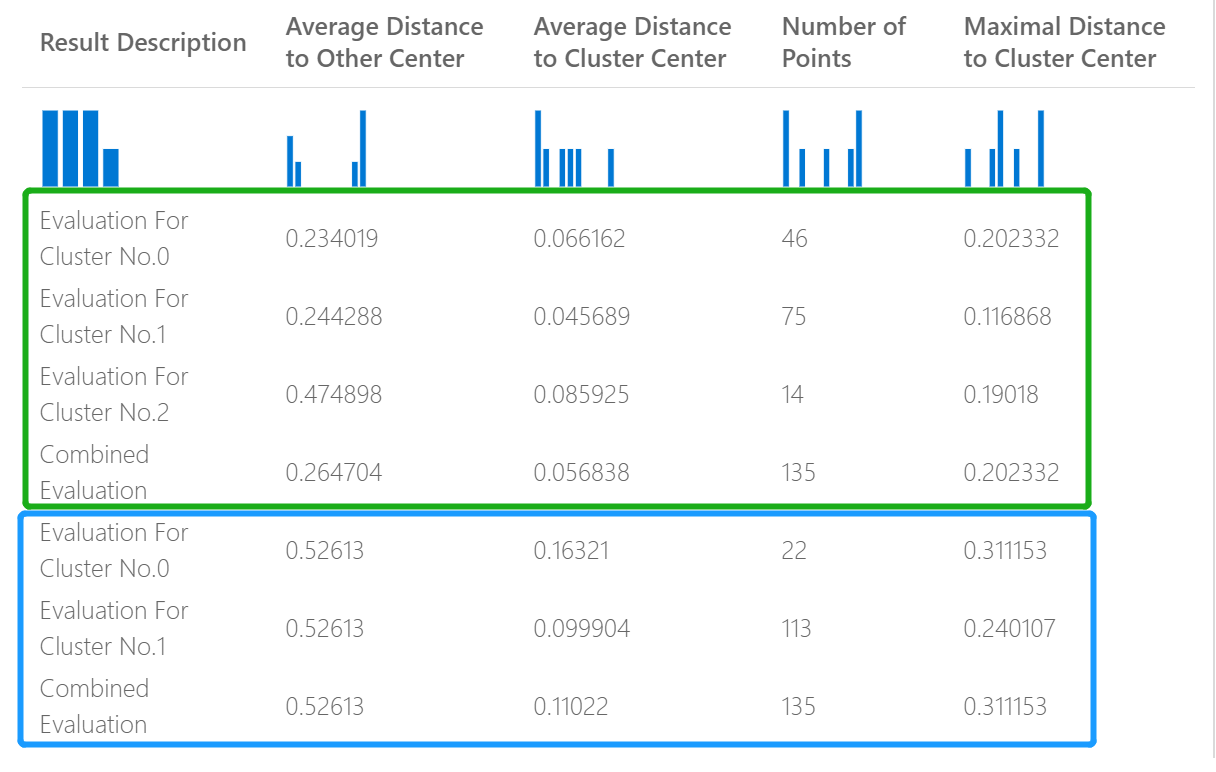
Vzhledem k tomu, že se jedná o clusteringový model, výsledky vyhodnocení se liší od porovnání skóre ze dvou regresních modelů nebo porovnání dvou klasifikačních modelů. Celková prezentace je ale stejná.
Metriky
Tato část popisuje metriky vrácené pro konkrétní typy modelů podporovaných pro použití s vyhodnocením modelu:
Metriky pro klasifikační modely
Při vyhodnocování binárních klasifikačních modelů jsou hlášeny následující metriky.
Přesnost měří dobrou hodnotu klasifikačního modelu jako poměr pravdivých výsledků k celkovým případům.
Přesnost je poměr pravdivých výsledků oproti všem pozitivním výsledkům. Přesnost = TP/(TP+FP)
Úplnost je zlomek celkového množství relevantních instancí, které byly skutečně načteny. Odvolání = TP/(TP+FN)
Skóre F1 se vypočítá jako vážený průměr přesnosti a úplnosti mezi 0 a 1, kde ideální hodnota skóre F1 je 1.
AUC měří oblast pod křivkou vynesenou skutečnými pozitivními výsledky na ose y a falešně pozitivními výsledky na ose x. Tato metrika je užitečná, protože poskytuje jedno číslo, které umožňuje porovnat modely různých typů. AUC je invariantní klasifikace-prahová hodnota. Měří kvalitu predikcí modelu bez ohledu na to, jaká prahová hodnota klasifikace je zvolena.
Metriky pro regresní modely
Metriky vrácené pro regresní modely jsou navržené k odhadu množství chyb. Model se považuje za vhodný pro data, pokud je rozdíl mezi pozorovanými a predikovanými hodnotami malý. Při pohledu na vzor reziduí (rozdíl mezi libovolným předpovězeným bodem a odpovídající skutečnou hodnotou) však můžete zjistit hodně o potenciálních předsudkech v modelu.
Pro vyhodnocení lineárních regresních modelů jsou hlášeny následující metriky. Jiné regresní modely, jako je regrese Fast Forest Quantile, můžou mít různé metriky.
Střední absolutní chyba (MAE) měří, jak blízko jsou předpovědi skutečným výsledkům, a proto je lepší nižší skóre.
Odmocněná střední kvadratická chyba (RMSE) vytvoří jednu hodnotu, která shrnuje chybu v modelu. Díky rozdělení rozdílu metrika ignoruje rozdíl mezi předpovědí a podpovědí.
Relativní absolutní chyba (RAE) je relativní absolutní rozdíl mezi očekávanými a skutečnými hodnotami; relativní, protože střední rozdíl je dělený aritmetickou střední hodnotou.
Relativní kvadratická chyba (RSE) podobně normalizuje celkovou kvadratická chybu predikovaných hodnot tak, že vydělí celkovou kvadratická chyba skutečných hodnot.
Koeficient určení, často označovaný jako R2, představuje prediktivní výkon modelu jako hodnotu mezi 0 a 1. Nula znamená, že model je náhodný (vysvětluje nic); 1 znamená, že je perfektní. Při interpretaci hodnot R2 je však třeba opatrnosti, protože nízké hodnoty mohou být zcela normální a vysoké hodnoty mohou být podezřelé.
Metriky pro modely clusteringu
Vzhledem k tomu, že se modely clusteringu výrazně liší od klasifikačních a regresních modelů v mnoha ohledech, vrátí funkce Evaluate Model také jinou sadu statistik pro modely clusteringu.
Statistiky vrácené pro clusteringový model popisují, kolik datových bodů bylo přiřazeno ke každému clusteru, množství oddělení mezi clustery a jak úzce jsou datové body v rámci každého clusteru rozděleny.
Statistiky pro model clusteringu se průměrují přes celou datovou sadu s dalšími řádky obsahujícími statistiky na cluster.
Při vyhodnocování modelů clusteringu se hlásí následující metriky.
Skóre ve sloupci Average Distance to Other Center (Průměrná vzdálenost do jiného středu) představují v průměru, že každý bod v clusteru je centroidy všech ostatních shluků.
Skóre ve sloupci Average Distance to Cluster Center (Průměrná vzdálenost ke středu clusteru) představují blízkost všech bodů v clusteru k centroidu tohoto clusteru.
Sloupec Počet bodů ukazuje, kolik datových bodů bylo přiřazeno ke každému clusteru, spolu s celkovým celkovým počtem datových bodů v libovolném clusteru.
Pokud je počet datových bodů přiřazených ke clusterům menší než celkový počet dostupných datových bodů, znamená to, že datové body nelze přiřadit ke clusteru.
Skóre ve sloupci Maximální vzdálenost ke středu clusteru představují maximální vzdálenost mezi jednotlivými body a centroidem tohoto bodu.
Pokud je toto číslo vysoké, může to znamenat, že cluster je široce rozptýlený. Tuto statistiku byste měli zkontrolovat společně s průměrnou vzdáleností ke středu clusteru a určit rozložení clusteru.
Kombinované hodnocení v dolní části každé části výsledků uvádí průměrné skóre pro clustery vytvořené v tomto konkrétním modelu.
Další kroky
Podívejte se na sadu komponent dostupných pro Azure Machine Learning.