Optimalizace využití paměti pro Apache Spark
Tento článek popisuje, jak optimalizovat správu paměti clusteru Apache Spark pro zajištění nejlepšího výkonu ve službě Azure HDInsight.
Přehled
Spark funguje umístěním dat do paměti. Správa prostředků paměti je tedy klíčovým aspektem optimalizace spouštění úloh Sparku. Existuje několik technik, které můžete použít k efektivnímu využití paměti clusteru.
- Upřednostňujte menší datové oddíly a upřednostňujte velikost dat, typy a distribuci ve vaší strategii dělení.
- Zvažte novější, efektivnější
Kryo data serialization, spíše než výchozí serializace Java. - Preferujte použití YARN, protože odděluje
spark-submitdávku. - Monitorování a ladění nastavení konfigurace Sparku
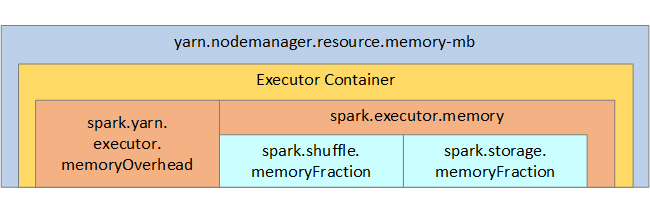
Pro vaši referenci se na následujícím obrázku zobrazí struktura paměti Sparku a některé parametry paměti exekutoru klíčů.
Aspekty paměti Sparku
Pokud používáte Apache Hadoop YARN, YARN řídí paměť používanou všemi kontejnery na každém uzlu Sparku. Následující diagram znázorňuje klíčové objekty a jejich vztahy.
Pokud chcete vyřešit zprávy typu nedostatek paměti, zkuste:
- Projděte si shuffles správy DAG. Snižte velikost odesílaných zdrojových dat na straně mapy, předem dělenou (nebo bucketize), maximalizujte jednoduché náhodné prohazování a snižte množství odesílaných dat.
- Preferujte
ReduceByKeys pevným limitem paměti ,GroupByKeykterý poskytuje agregace, okna a další funkce, ale má nevázaný limit paměti. - Preferujte
TreeReduce, což dělá více práce na exekutorech nebo oddílech, do , kteréReducevšechny pracují na ovladači. - Datové rámce používejte místo objektů RDD nižší úrovně.
- Vytvořte komplexní typy, které zapouzdřují akce, jako je například "Horní N", různé agregace nebo operace vytváření oken.
Další kroky pro řešení potíží najdete v tématu Výjimky OutOfMemoryError pro Apache Spark ve službě Azure HDInsight.