Konfigurace nastavení Apache Sparku
Cluster HDInsight Spark zahrnuje instalaci knihovny Apache Spark. Každý cluster HDInsight obsahuje výchozí parametry konfigurace pro všechny nainstalované služby, včetně Sparku. Klíčovým aspektem správy clusteru HDInsight Apache Hadoop je monitorování úloh, včetně úloh Sparku. Pro nejlepší spuštění úloh Sparku zvažte konfiguraci fyzického clusteru při určování logické konfigurace clusteru.
Výchozí cluster HDInsight Apache Spark obsahuje následující uzly: tři uzly Apache ZooKeeper, dva hlavní uzly a jeden nebo více pracovních uzlů:
Počet virtuálních počítačů a velikostí virtuálních počítačů pro uzly v clusteru HDInsight může ovlivnit konfiguraci Sparku. Jiné než výchozí hodnoty konfigurace HDInsight často vyžadují jiné než výchozí hodnoty konfigurace Sparku. Když vytvoříte cluster HDInsight Spark, zobrazí se navrhované velikosti virtuálních počítačů pro každou z těchto komponent. V současné době jsou velikosti virtuálních počítačů s Linuxem optimalizované pro Paměť pro Azure D12 v2 nebo vyšší.
Verze Apache Sparku
Použijte nejlepší verzi Sparku pro váš cluster. Služba HDInsight zahrnuje několik verzí Samotného Sparku i HDInsightu. Každá verze Sparku zahrnuje sadu výchozích nastavení clusteru.
Když vytvoříte nový cluster, můžete si vybrat z několika verzí Sparku. Pokud chcete zobrazit úplný seznam, komponenty a verze SLUŽBY HDInsight.
Poznámka:
Výchozí verze Apache Sparku ve službě HDInsight se může bez předchozího upozornění změnit. Pokud máte závislost na verzi, Společnost Microsoft doporučuje určit konkrétní verzi při vytváření clusterů pomocí sady .NET SDK, Azure PowerShellu a Azure Classic CLI.
Apache Spark má tři umístění konfigurace systému:
- Vlastnosti Sparku řídí většinu parametrů aplikace a lze je nastavit pomocí objektu
SparkConfnebo prostřednictvím systémových vlastností Javy. - Proměnné prostředí se dají použít k nastavení jednotlivých počítačů, jako je IP adresa, prostřednictvím
conf/spark-env.shskriptu na každém uzlu. - Protokolování lze nakonfigurovat prostřednictvím
log4j.properties.
Když vyberete konkrétní verzi Sparku, váš cluster obsahuje výchozí nastavení konfigurace. Výchozí hodnoty konfigurace Sparku můžete změnit pomocí vlastního konfiguračního souboru Sparku. Příklad najdete níže.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
Výše uvedený příklad přepíše několik výchozích hodnot pro pět parametrů konfigurace Sparku. Tyto hodnoty jsou kodek komprese, Apache Hadoop MapReduce rozdělte minimální velikost a velikosti parketových bloků. Výchozí hodnoty jsou také v oddílu Spark SQL a otevíraly výchozí hodnoty velikosti souborů. Tyto změny konfigurace se vyberou, protože přidružená data a úlohy (v tomto příkladu genomická data) mají konkrétní charakteristiky. Tyto vlastnosti budou lépe používat tato vlastní nastavení konfigurace.
Zobrazení nastavení konfigurace clusteru
Před optimalizací výkonu v clusteru ověřte aktuální nastavení konfigurace clusteru HDInsight. Na webu Azure Portal spusťte řídicí panel HDInsight kliknutím na odkaz Řídicí panel v podokně clusteru Spark. Přihlaste se pomocí uživatelského jména a hesla správce clusteru.
Zobrazí se webové uživatelské rozhraní Apache Ambari s řídicím panelem s metrikami využití klíčových prostředků clusteru. Na řídicím panelu Ambari se zobrazí konfigurace Apache Sparku a další nainstalované služby. Řídicí panel obsahuje kartu Historie konfigurace, kde zobrazíte informace o nainstalovaných službách, včetně Sparku.
Pokud chcete zobrazit konfigurační hodnoty pro Apache Spark, vyberte Historii konfigurace a pak vyberte Spark2. Vyberte kartu Konfigurace a pak v seznamu služeb vyberte Spark odkaz (nebo Spark2v závislosti na vaší verzi). Zobrazí se seznam konfiguračních hodnot pro váš cluster:
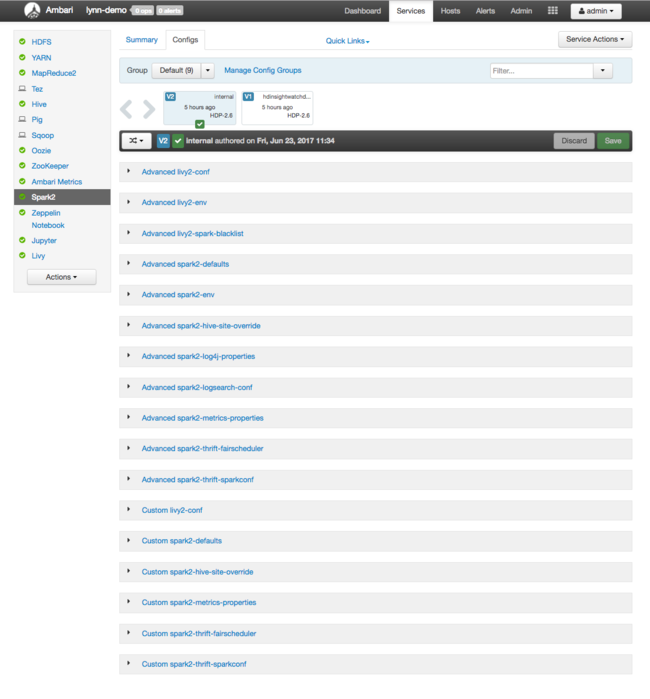
Pokud chcete zobrazit a změnit jednotlivé konfigurační hodnoty Sparku, vyberte v názvu libovolný odkaz se "sparkem". Mezi konfigurace Sparku patří vlastní i pokročilé konfigurační hodnoty v těchto kategoriích:
- Vlastní výchozí hodnoty Spark2
- Vlastní vlastnosti Metriky Spark2
- Pokročilé výchozí hodnoty Spark2
- Advanced Spark2-env
- Rozšířené přepsání spark2-hive-site-override
Pokud vytvoříte ne výchozí sadu hodnot konfigurace, zobrazí se historie aktualizací. Tato historie konfigurace může být užitečná, když zjistíte, která jiná než výchozí konfigurace má optimální výkon.
Poznámka:
Pokud chcete zobrazit, ale ne změnit běžná nastavení konfigurace clusteru Spark, vyberte kartu Prostředí v rozhraní uživatelského rozhraní úloh Sparku nejvyšší úrovně.
Konfigurace exekutorů Sparku
Následující diagram znázorňuje klíčové objekty Sparku: program ovladače a přidružený kontext Sparku a správce clusteru a jeho n pracovních uzlů. Každý pracovní uzel zahrnuje exekutor, mezipaměť a n instancí úloh.
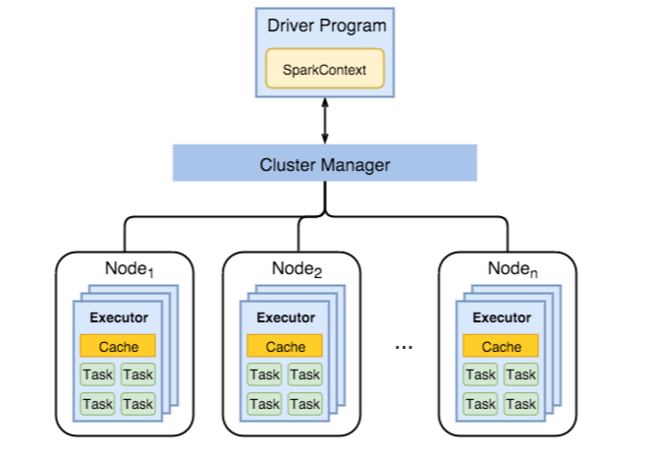
Úlohy Sparku používají pracovní prostředky, zejména paměť, takže je běžné upravovat hodnoty konfigurace Sparku pro exekutory pracovních uzlů.
Tři klíčové parametry, které jsou často upraveny tak, aby vyladily konfigurace Sparku za účelem zlepšení požadavků aplikace, jsou spark.executor.instances, spark.executor.coresa spark.executor.memory. Exekutor je proces spuštěný pro aplikaci Spark. Exekutor běží na pracovním uzlu a zodpovídá za úlohy aplikace. Počet pracovních uzlů a velikost pracovního uzlu určuje počet exekutorů a velikosti exekutorů. Tyto hodnoty jsou uložené v spark-defaults.conf hlavních uzlech clusteru. Tyto hodnoty můžete upravit ve spuštěném clusteru výběrem vlastních výchozích hodnot Sparku ve webovém uživatelském rozhraní Ambari. Po provedení změn se zobrazí výzva k restartování všech ovlivněných služeb v uživatelském rozhraní.
Poznámka:
Tyto tři konfigurační parametry je možné nakonfigurovat na úrovni clusteru (pro všechny aplikace spuštěné v clusteru) a také pro každou jednotlivou aplikaci.
Dalším zdrojem informací o prostředcích používaných exekutory Sparku je uživatelské rozhraní aplikace Spark. V uživatelském rozhraní zobrazují exekutory souhrnné zobrazení a zobrazení podrobností o konfiguraci a spotřebovaných prostředcích. Určete, jestli se mají měnit hodnoty exekutorů pro celý cluster nebo konkrétní sada spuštění úloh.
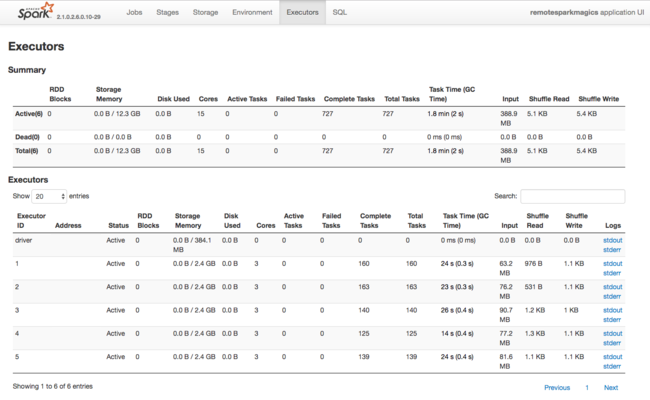
Nebo můžete pomocí rozhraní Ambari REST API programově ověřit nastavení konfigurace clusteru HDInsight a Spark. Další informace najdete v referenčních informacích k rozhraní Apache Ambari API na GitHubu.
V závislosti na konkrétní úloze Spark můžete zjistit, že jiná než výchozí konfigurace Sparku zajistí optimálnější provádění úloh Spark. Proveďte testování srovnávacích testů s ukázkovými úlohami a ověřte všechny konfigurace clusteru, které nejsou výchozí. Tady je několik běžných parametrů, jejichž úpravu můžete zvážit:
| Parametr | Popis |
|---|---|
| --num-executors | Nastaví počet exekutorů. |
| --executor-cores | Nastaví počet jader pro každý exekutor. Doporučujeme používat exekutory střední velikosti, protože jiné procesy využívají také část dostupné paměti. |
| --executor-memory | Řídí velikost paměti (velikost haldy) každého exekutoru v Apache Hadoop YARN a budete muset nechat paměť pro režijní náklady na spuštění. |
Tady je příklad dvou pracovních uzlů s různými hodnotami konfigurace:

Následující seznam ukazuje klíčové parametry paměti exekutoru Sparku.
| Parametr | Popis |
|---|---|
| spark.executor.memory | Definuje celkovou velikost paměti dostupnou pro exekutor. |
| spark.storage.memoryFraction | (výchozí hodnota ~60 %) definuje množství paměti dostupné pro ukládání trvalých sad RDD. |
| spark.shuffle.memoryFraction | (výchozí hodnota ~20 %) definuje množství paměti vyhrazené pro náhodné prohazování. |
| spark.storage.unrollFraction a spark.storage.safetyFraction | (celkem ~30 % celkové paměti) – tyto hodnoty se používají interně ve Sparku a neměly by se měnit. |
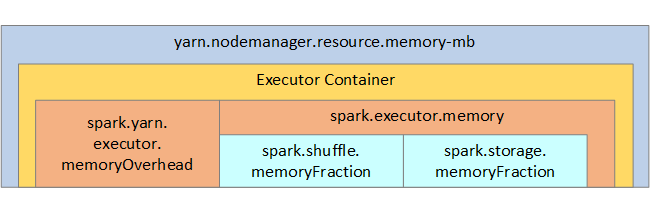
YARN řídí maximální součet paměti používané kontejnery na každém uzlu Sparku. Následující diagram znázorňuje vztahy mezi objekty konfigurace YARN a objekty Spark.
Změna parametrů pro aplikaci spuštěnou v Aplikaci Jupyter Notebook
Clustery Spark v HDInsight obsahují ve výchozím nastavení řadu komponent. Každá z těchto komponent zahrnuje výchozí hodnoty konfigurace, které je možné podle potřeby přepsat.
| Komponenta | Popis |
|---|---|
| Spark Core | Spark Core, Spark SQL, rozhraní API pro streamování Sparku, GraphX a Apache Spark MLlib. |
| Anaconda | Správce balíčků Pythonu. |
| Apache Livy | Rozhraní APACHE Spark REST API, které slouží k odesílání vzdálených úloh do clusteru HDInsight Spark. |
| Poznámkové bloky Jupyter a poznámkové bloky Apache Zeppelin | Interaktivní uživatelské rozhraní založené na prohlížeči pro interakci s clusterem Spark |
| Ovladač ODBC | Připojí clustery Spark v HDInsight k nástrojům business intelligence (BI), jako jsou Microsoft Power BI a Tableau. |
U aplikací spuštěných v poznámkovém bloku Jupyter použijte %%configure příkaz k provedení změn konfigurace přímo v poznámkovém bloku. Tyto změny konfigurace se použijí u úloh Sparku spuštěných z instance poznámkového bloku. Před spuštěním první buňky kódu proveďte takové změny na začátku aplikace. Změněná konfigurace se použije pro relaci Livy při jejím vytvoření.
Poznámka:
Pokud chcete konfiguraci změnit v pozdější fázi aplikace, použijte -f parametr (force). Veškerý pokrok v aplikaci se však ztratí.
Následující kód ukazuje, jak změnit konfiguraci aplikace spuštěné v aplikaci Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Závěr
Monitorujte základní nastavení konfigurace, abyste zajistili, že vaše úlohy Sparku běží předvídatelným a výkonným způsobem. Tato nastavení pomáhají určit nejlepší konfiguraci clusteru Spark pro konkrétní úlohy. Budete také muset monitorovat provádění dlouhotrvajících a nebo spouštění úloh Spark využívajících prostředky. Nejčastější výzvy jsou spojené s tlakem na paměť z nesprávných konfigurací, jako jsou například exekutory s nesprávnou velikostí. Také dlouhotrvající operace a úlohy, které vedou k kartézským operacím.