Integrace Apache Sparku a Apache Hivu s knihovnou Hive Warehouse Connector ve službě Azure HDInsight
Konektor Apache Hive Warehouse (HWC) je knihovna, která umožňuje snadněji pracovat s Apache Sparkem a Apache Hivem. Podporuje úlohy, jako je přesun dat mezi tabulkami Spark DataFrame a Hive. Také směrováním streamovaných dat Sparku do tabulek Hive. Konektor Hive Warehouse funguje jako most mezi Sparkem a Hivem. Podporuje také jazyk Scala, Java a Python jako programovací jazyky pro vývoj.
Konektor Hive Warehouse umožňuje využívat jedinečné funkce Hive a Sparku k vytváření výkonných aplikací pro velké objemy dat.
Apache Hive nabízí podporu databázových transakcí, které jsou Atomic, Consistent, Isolated a Durable (ACID). Další informace o ACID a transakcích v Hive naleznete v tématu Transakce Hive. Hive také nabízí podrobné kontrolní mechanismy zabezpečení prostřednictvím Apache Rangeru a LLAP (Low Latency Analytical Processing), které nejsou dostupné v Apache Sparku.
Apache Spark má rozhraní API strukturovaného streamování, které poskytuje možnosti streamování, které nejsou dostupné v Apache Hivu. Od VERZE HDInsight 4.0 mají Apache Spark 2.3.1 a Apache Hive 3.1.0 samostatné katalogy metastoru, které ztěžují interoperabilitu.
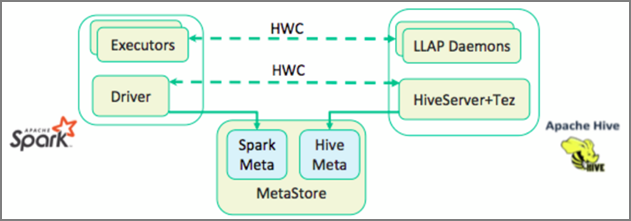
Konektor Hive Warehouse (HWC) usnadňuje společné použití Sparku a Hivu. Knihovna HWC načítá data z démonů LLAP do exekutorů Sparku paralelně. Díky tomuto procesu je efektivnější a přizpůsobitelná než standardní připojení JDBC ze Sparku k Hivu. Tím se pro HWC zobrazí dva různé režimy provádění:
- Režim Hive JDBC přes HiveServer2
- Režim Hive LLAP s využitím démonů LLAP [Doporučeno]
Ve výchozím nastavení je HWC nakonfigurovaný tak, aby používal démony Hive LLAP. Pokud chcete spouštět dotazy Hive (čtení i zápis) pomocí výše uvedených režimů s příslušnými rozhraními API, přečtěte si o rozhraních API HWC.
Mezi operace podporované konektorem Hive Warehouse Connector patří:
- Popis tabulky
- Vytvoření tabulky pro data ve formátu ORC
- Výběr dat Hive a načtení datového rámce
- Zápis datového rámce do Hivu v dávce
- Spuštění příkazu aktualizace Hive
- Čtení dat tabulky z Hivu, jejich transformace ve Sparku a zápis do nové tabulky Hive
- Zápis datového rámce nebo streamu Sparku do Hivu pomocí HiveStreamingu
Nastavení konektoru Hive Warehouse
Důležité
- Instance HiveServer2 Interactive nainstalovaná v clusterech balíčků zabezpečení Sparku 2.4 Enterprise se nepodporuje pro použití s konektorem Hive Warehouse Connector. Místo toho musíte nakonfigurovat samostatný cluster HiveServer2 Interactive pro hostování úloh HiveServer2 Interactive. Konfigurace konektoru Hive Warehouse, která využívá jeden cluster Spark 2.4, se nepodporuje.
- Knihovna konektoru Hive Warehouse (HWC) není podporovaná pro použití s clustery interaktivních dotazů, kde je povolená funkce správy úloh (WLM).
Ve scénáři, kdy máte jenom úlohy Sparku a chcete používat knihovnu HWC, ujistěte se, že cluster Interactive Query nemá povolenou funkci Správy úloh (hive.server2.tez.interactive.queuekonfigurace není nastavená v konfiguracích Hive).
Pro scénář, ve kterém existují úlohy Sparku (HWC) i nativní úlohy LLAP, je potřeba vytvořit dva samostatné clustery Interactive Query se sdílenou databází metastoru. Jeden cluster pro nativní úlohy LLAP, kde je možné povolit funkci WLM na základě potřeby, a druhý cluster pro úlohy HWC, kde by neměla být nakonfigurovaná funkce WLM. Je důležité si uvědomit, že plány prostředků WLM můžete zobrazit z obou clusterů, i když je povolená pouze v jednom clusteru. V clusteru, ve kterém je funkce WLM zakázaná, neprovádejte žádné změny plánů prostředků, protože to může mít vliv na funkčnost WLM v jiném clusteru. - I když Spark podporuje výpočetní jazyk R pro zjednodušení analýzy dat, knihovna konektoru Hive Warehouse (HWC) se nepodporuje pro použití s jazykem R. Ke spouštění úloh HWC můžete spouštět dotazy ze Sparku do Hivu pomocí rozhraní API HiveWarehouseSession ve stylu JDBC, které podporuje pouze Scala, Java a Python.
- Spouštění dotazů (čtení i zápisu) prostřednictvím režimu HiveServer2 prostřednictvím režimu JDBC není podporováno u složitých datových typů, jako jsou Arrays, Struct/Map.
- HWC podporuje zápis pouze ve formátech souborů ORC. Zápisy jiné než ORC (např. parquet a formáty textových souborů) nejsou podporovány prostřednictvím HWC.
Konektor Hive Warehouse vyžaduje samostatné clustery pro úlohy Sparku a Interaktivní dotazy. Pomocí těchto kroků nastavte tyto clustery ve službě Azure HDInsight.
Podporované typy a verze clusteru
| Verze HWC | Verze Sparku | Verze InteractiveQuery |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interaktivní dotaz 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interaktivní dotaz 3.1 | HDI 5.0 |
Vytváření clusterů
Vytvořte cluster HDInsight Spark 4.0 s účtem úložiště a vlastní virtuální sítí Azure. Informace o vytvoření clusteru ve virtuální síti Azure najdete v tématu Přidání SLUŽBY HDInsight do existující virtuální sítě.
Vytvořte cluster HDInsight Interactive Query (LLAP) 4.0 se stejným účtem úložiště a virtuální sítí Azure jako cluster Spark.
Konfigurace nastavení HWC
Shromáždění předběžných informací
Ve webovém prohlížeči přejděte na
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVEmísto, kde LLAPCLUSTERNAME je název vašeho clusteru Interactive Query.Přejděte na souhrnnou>adresu URL HiveServer2 Interactive JDBC a poznamenejte si hodnotu. Hodnota může být podobná:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Přejděte na Configs>Advanced Advanced>hive-site>hive.zookeeper.kvorum a poznamenejte si hodnotu. Hodnota může být podobná:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Přejděte na Configs>Advanced>General>hive.metastore.uris a poznamenejte si hodnotu. Hodnota může být podobná:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Přejděte na Configs>Advanced Advanced>hive-interactive-site>hive.llap.daemon.service.hosts a poznamenejte si hodnotu. Hodnota může být podobná:
@llap0.
Konfigurace nastavení clusteru Spark
Ve webovém prohlížeči přejděte do
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configsumístění CLUSTERNAME název vašeho clusteru Apache Spark.Rozbalte vlastní výchozí hodnoty Spark2.
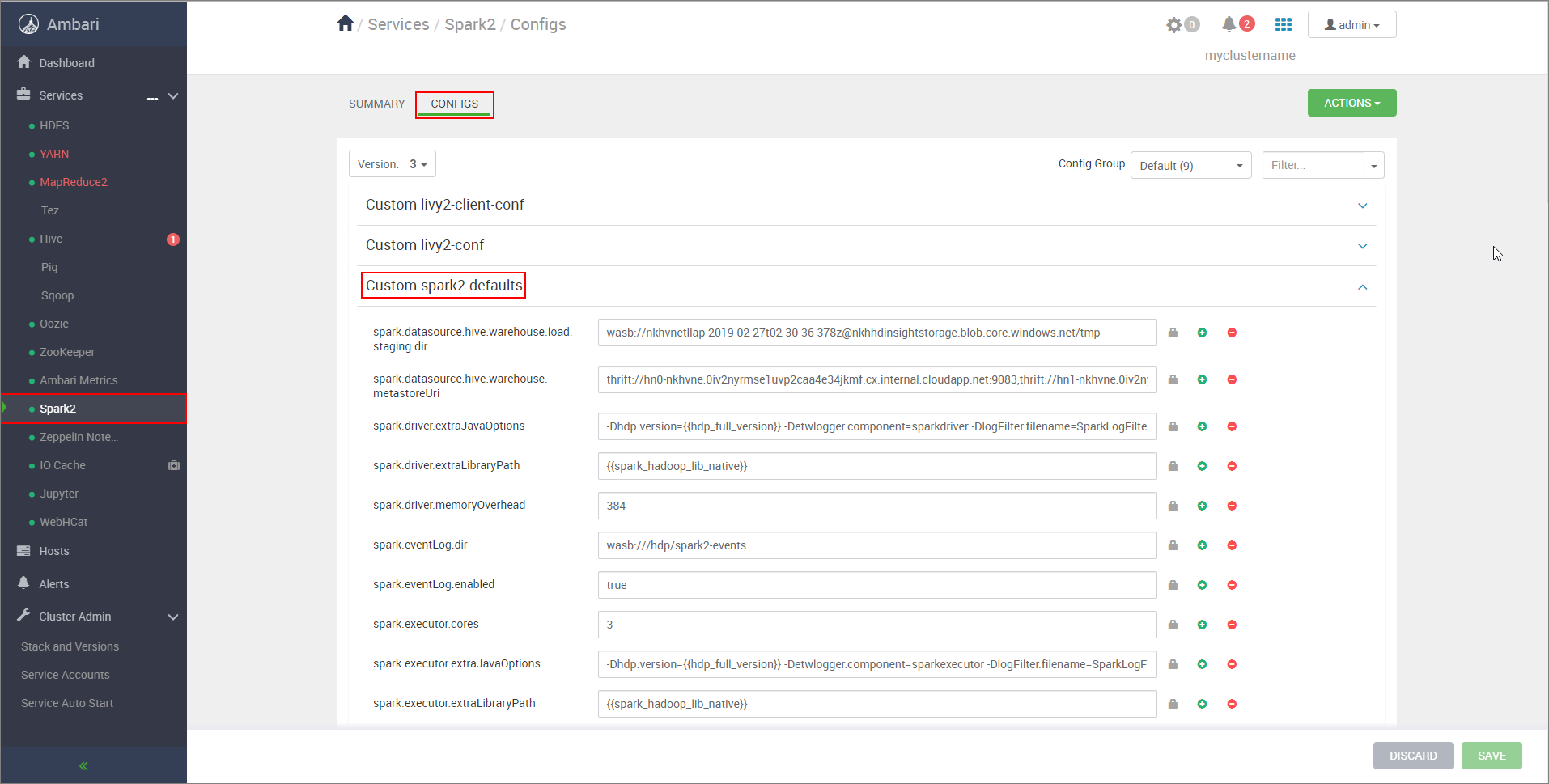
Vyberte Přidat vlastnost... a přidejte následující konfigurace:
Konfigurace Hodnota spark.datasource.hive.warehouse.load.staging.dirPokud používáte účet úložiště ADLS Gen2, použijte abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Pokud používáte účet služby Azure Blob Storage, použijtewasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Nastavte vhodný pracovní adresář kompatibilní s HDFS. Pokud máte dva různé clustery, pracovní adresář by měl být složka v pracovním adresáři účtu úložiště clusteru LLAP, aby k němu měl přístup HiveServer2. NahraďteSTORAGE_ACCOUNT_NAMEnázvem účtu úložiště, který cluster používá, aSTORAGE_CONTAINER_NAMEnázvem kontejneru úložiště.spark.sql.hive.hiveserver2.jdbc.urlHodnota, kterou jste získali dříve z adresy URL HiveServer2 Interactive JDBC spark.datasource.hive.warehouse.metastoreUriHodnota, kterou jste získali dříve z hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtruepro režim clusteru YARN afalsepro klientský režim YARN.spark.hadoop.hive.zookeeper.quorumHodnota, kterou jste získali dříve z hive.zookeeper.kvora. spark.hadoop.hive.llap.daemon.service.hostsHodnota, kterou jste získali dříve z hive.llap.daemon.service.hosts. Uložte změny a restartujte všechny ovlivněné součásti.
Konfigurace clusterů HWC pro balíčky zabezpečení podniku (ESP)
Balíček zabezpečení podniku (ESP) poskytuje funkce na podnikové úrovni, jako je ověřování založené na službě Active Directory, podpora více uživatelů a řízení přístupu na základě role pro clustery Apache Hadoop ve službě Azure HDInsight. Další informace o ESP naleznete v tématu Použití balíčku zabezpečení podniku v HDInsight.
Kromě konfigurací uvedených v předchozí části přidejte následující konfiguraci pro použití HWC v clusterech ESP.
Ve webovém uživatelském rozhraní clusteru Spark v Ambari přejděte do vlastních výchozích hodnot Spark2 CONFIGS>Spark2.>
Aktualizujte následující vlastnost.
Konfigurace Hodnota spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>Ve webovém prohlížeči přejděte do
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summaryumístění CLUSTERNAME název vašeho clusteru Interactive Query. Klikněte na HiveServer2 Interactive. Zobrazí se plně kvalifikovaný název domény (FQDN) hlavního uzlu, na kterém je LLAP spuštěný, jak je znázorněno na snímku obrazovky. Nahraďte<llap-headnode>touto hodnotou.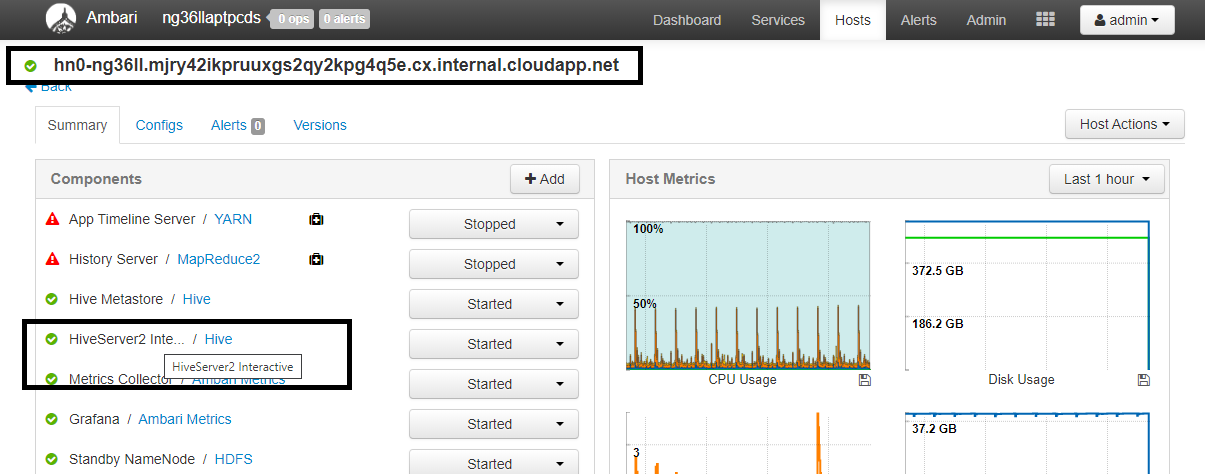
Pomocí příkazu ssh se připojte ke clusteru Interactive Query.
default_realmVyhledejte parametr v/etc/krb5.confsouboru. Nahraďte<AAD-DOMAIN>touto hodnotou jako řetězec velkými písmeny, jinak se přihlašovací údaje nenajdou.
Například
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Podle potřeby uložte změny a restartujte součásti.
Využití konektoru Hive Warehouse
Můžete si vybrat mezi několika různými metodami připojení ke clusteru Interactive Query a spouštění dotazů pomocí konektoru Hive Warehouse Connector. Mezi podporované metody patří následující nástroje:
Níže je několik příkladů připojení k HWC ze Sparku.
Spark-shell
Jedná se o způsob, jak spustit Spark interaktivně prostřednictvím upravené verze prostředí Scala.
Pomocí příkazu ssh se připojte ke clusteru Apache Spark. Upravte následující příkaz nahrazením clusteru názvem clusteru a zadáním příkazu:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netV relaci ssh spusťte následující příkaz, který si poznamenejte
hive-warehouse-connector-assemblyverzi:ls /usr/hdp/current/hive_warehouse_connectorUpravte níže uvedený kód s
hive-warehouse-connector-assemblyverzí uvedenou výše. Pak spuštěním příkazu spusťte prostředí Spark:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falsePo spuštění prostředí Spark je možné spustit instanci konektoru Hive Warehouse pomocí následujících příkazů:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Odeslání Sparku
Spark-submit je nástroj pro odeslání libovolného programu Sparku (nebo úlohy) do clusterů Spark.
Úloha spark-submit nastaví a nakonfiguruje konektor Sparku a Hive Warehouse podle našich pokynů, spustí program, který jí předáme, a pak čistě uvolní použité prostředky.
Jakmile sestavíte kód scala/java spolu se závislostmi do souboru JAR sestavení, spusťte aplikaci Spark pomocí následujícího příkazu. Nahraďte <VERSION>hodnoty a <APP_JAR_PATH> skutečnými hodnotami.
Klientský režim YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarRežim clusteru YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Tento nástroj se také používá, když jsme napsali celou aplikaci v pySpark a zabalili do .py souborů (Python), abychom mohli odeslat celý kód do clusteru Spark ke spuštění.
V případě aplikací v Pythonu předejte soubor .py místo /<APP_JAR_PATH>/myHwcAppProject.jara přidejte do cesty hledání následující konfigurační soubor (Python .zip) s příponou --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Spouštění dotazů v clusterech Enterprise Security Package (ESP)
Použijte kinit před spuštěním spark-shellu nebo spark-submit. Nahraďte uživatelské jméno názvem účtu domény oprávněními pro přístup ke clusteru a pak spusťte následující příkaz:
kinit USERNAME
Zabezpečení dat v clusterech Spark ESP
Vytvořte tabulku
demos ukázkovými daty zadáním následujících příkazů:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Obsah tabulky zobrazíte pomocí následujícího příkazu. Než zásadu použijete,
demozobrazí se v tabulce celý sloupec.hive.executeQuery("SELECT * FROM demo").show()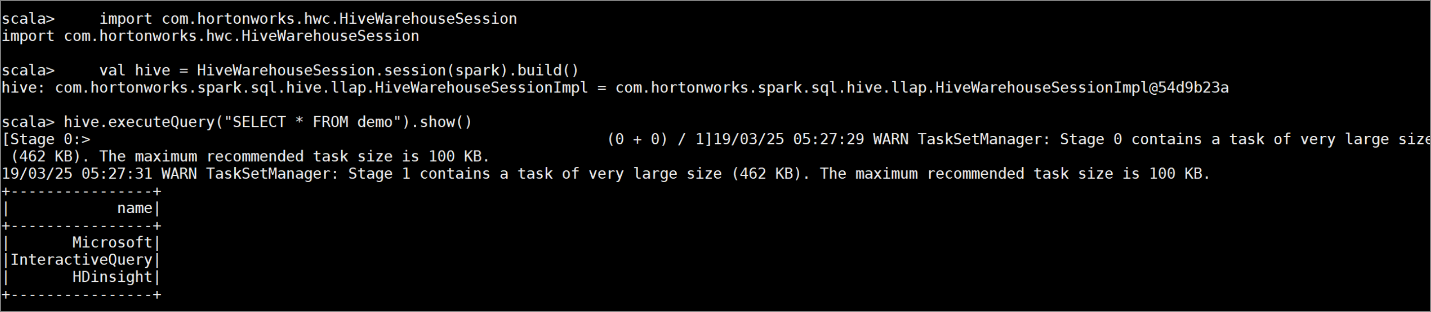
Použijte zásadu maskování sloupce, která zobrazuje pouze poslední čtyři znaky sloupce.
Přejděte do uživatelského rozhraní správce Ranger na adrese
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Klikněte na službu Hive pro váš cluster v části Hive.
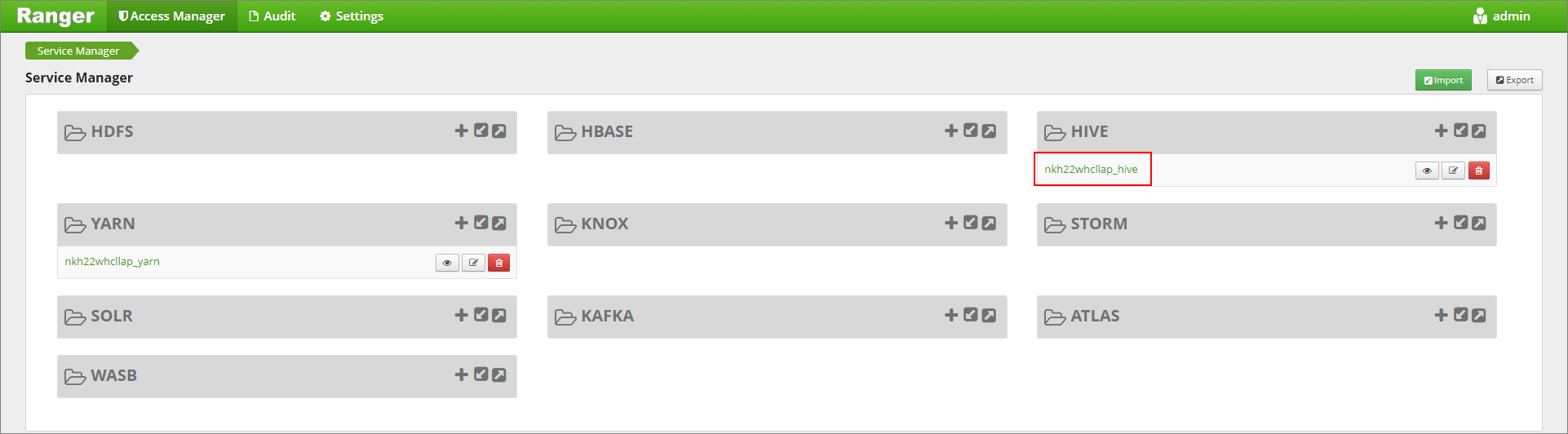
Klikněte na kartu Masking (Masking) a potom Add New Policy (Přidat novou zásadu).
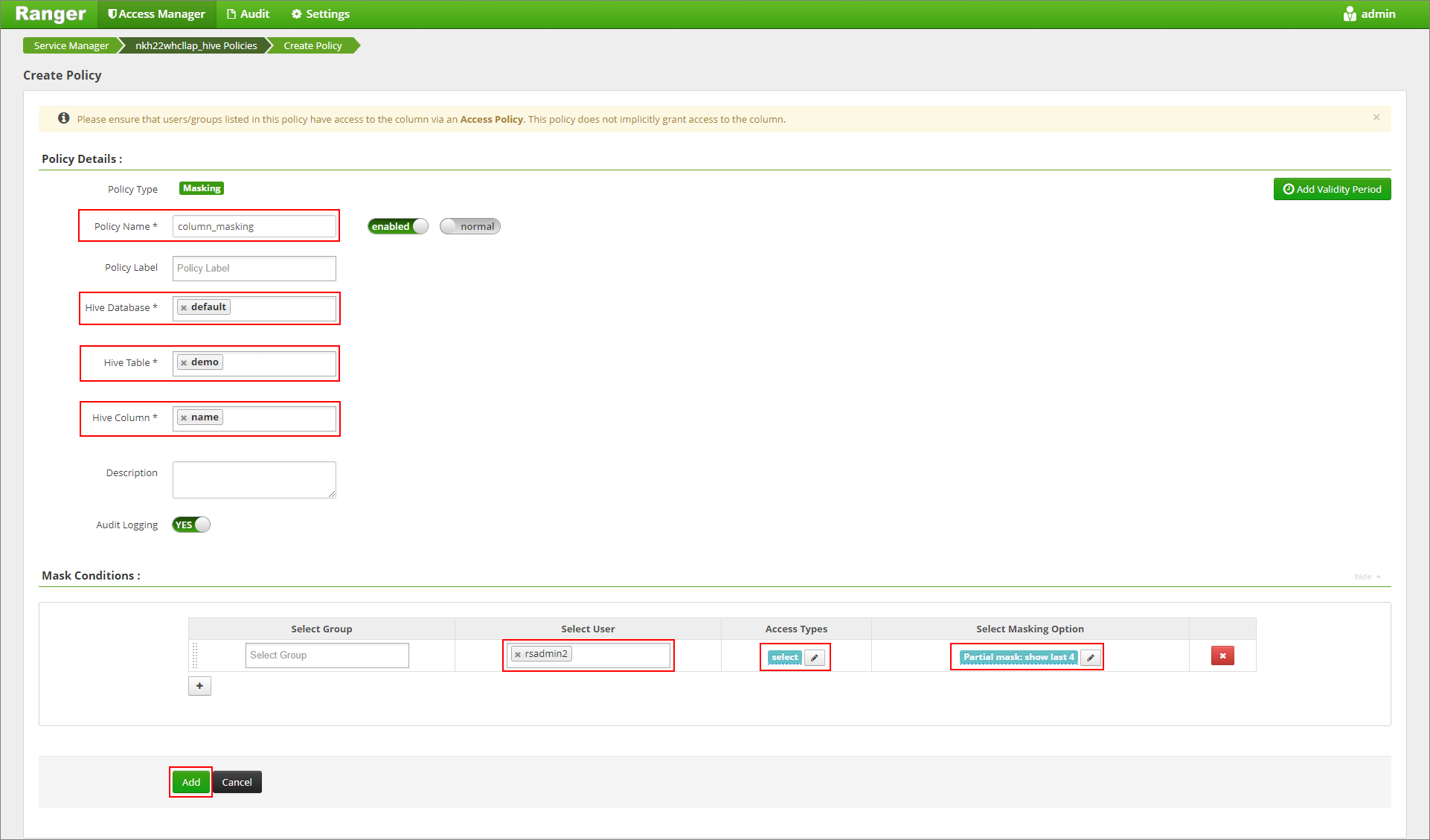
Zadejte požadovaný název zásady. Vyberte databázi: Výchozí, Tabulka Hive: demo, Sloupec Hive: name, User: rsadmin2, Access Types: select a Partial mask: show last 4 from the Select Masking Option menu. Klikněte na tlačítko Přidat.
Znovu zobrazte obsah tabulky. Po použití zásad rangeru uvidíme pouze poslední čtyři znaky sloupce.
