Použití Apache Oozie s Apache Hadoopem k definování a spuštění pracovního procesu v linuxové službě Azure HDInsight
Naučte se používat Apache Oozie s Apache Hadoopem ve službě Azure HDInsight. Oozie je pracovní postup a koordinační systém, který spravuje úlohy Hadoopu. Oozie je integrovaná se zásobníkem Hadoop a podporuje následující úlohy:
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
Oozie můžete také použít k naplánování úloh specifických pro systém, jako jsou programy Java nebo skripty prostředí.
Poznámka:
Další možností definování pracovních postupů se službou HDInsight je použití služby Azure Data Factory. Další informace o službě Data Factory najdete v tématu Použití Apache Pigu a Apache Hivu se službou Data Factory. Pokud chcete používat Oozie na clusterech s balíčkem zabezpečení podniku, přečtěte si téma Spuštění Apache Oozie v clusterech HDInsight Hadoop s balíčkem zabezpečení podniku.
Požadavky
Cluster Hadoop ve službě HDInsight. Viz Začínáme se službou HDInsight v Linuxu.
Klient SSH. Viz Připojení ke službě HDInsight (Apache Hadoop) pomocí SSH.
Azure SQL Database. Viz Vytvoření databáze ve službě Azure SQL Database na webu Azure Portal. Tento článek používá databázi s názvem oozietest.
Schéma identifikátoru URI pro primární úložiště clusterů.
wasb://pro Azure Storage,abfs://pro Azure Data Lake Storage Gen2 neboadl://Azure Data Lake Storage Gen1. Pokud je pro Azure Storage povolený zabezpečený přenos, identifikátor URI by bylwasbs://. Viz také zabezpečený přenos.
Ukázkový pracovní postup
Pracovní postup použitý v tomto dokumentu obsahuje dvě akce. Akce jsou definice pro úlohy, jako je spuštění Hive, Sqoop, MapReduce nebo jiných procesů:
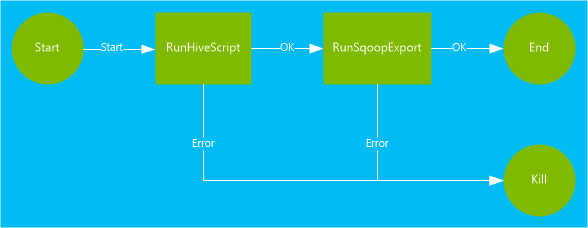
Akce Hive spustí skript HiveQL pro extrahování záznamů ze
hivesampletableslužby HDInsight. Každý řádek dat popisuje návštěvu z konkrétního mobilního zařízení. Formát záznamu se zobrazí jako následující text:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1Skript Hivu použitý v tomto dokumentu spočítá celkové návštěvy jednotlivých platforem, jako je Android nebo iPhone, a ukládá počty do nové tabulky Hive.
Další informace o Hivu najdete v tématu [Použití Apache Hivu se službou HDInsight][hdinsight-use-hive].
Akce Sqoop exportuje obsah nové tabulky Hive do tabulky vytvořené ve službě Azure SQL Database. Další informace o Sqoopu najdete v tématu Použití Apache Sqoop se službou HDInsight.
Poznámka:
Podporované verze Oozie v clusterech HDInsight najdete v tématu Co je nového ve verzích clusteru Hadoop poskytovaných službou HDInsight.
Vytvoření pracovního adresáře
Oozie očekává, že uložíte všechny prostředky potřebné pro úlohu ve stejném adresáři. Tento příklad používá wasbs:///tutorials/useoozie. Pokud chcete vytvořit tento adresář, proveďte následující kroky:
Upravte následující kód a nahraďte
sshuserho uživatelským jménem SSH pro cluster a nahraďteCLUSTERNAMEnázvem clusteru. Potom zadejte kód pro připojení ke clusteru HDInsight pomocí SSH.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netK vytvoření adresáře použijte následující příkaz:
hdfs dfs -mkdir -p /tutorials/useoozie/dataPoznámka:
Parametr
-pzpůsobí vytvoření všech adresářů v cestě. Adresářdatase používá k uložení dat používaných skriptemuseooziewf.hql.Upravte následující kód a nahraďte
sshuserho uživatelským jménem SSH. Pokud chcete mít jistotu, že Oozie může zosobnit váš uživatelský účet, použijte následující příkaz:sudo adduser sshuser usersPoznámka:
Chyby, které značí, že uživatel je již členem
usersskupiny, můžete ignorovat.
Přidání ovladače databáze
Tento pracovní postup používá Sqoop k exportu dat do databáze SQL. Proto musíte zadat kopii ovladače JDBC, který se používá k interakci s databází SQL. Pokud chcete zkopírovat ovladač JDBC do pracovního adresáře, použijte následující příkaz z relace SSH:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Důležité
Ověřte skutečný ovladač JDBC, který existuje na adrese /usr/share/java/.
Pokud váš pracovní postup používal jiné prostředky, například soubor JAR, který obsahuje aplikaci MapReduce, musíte tyto prostředky přidat také.
Definování dotazu Hive
Pomocí následujícího postupu vytvořte skript dotazovacího jazyka Hive (HiveQL), který definuje dotaz. Dotaz použijete v pracovním postupu Oozie později v tomto dokumentu.
Pomocí následujícího příkazu z připojení SSH vytvořte soubor s názvem
useooziewf.hql:nano useooziewf.hqlPo otevření editoru GNU nano použijte jako obsah souboru následující dotaz:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;Ve skriptu se používají dvě proměnné:
${hiveTableName}: Obsahuje název tabulky, kterou chcete vytvořit.${hiveDataFolder}: Obsahuje umístění pro ukládání datových souborů tabulky.Definiční soubor pracovního postupu workflow.xml v tomto článku předá tyto hodnoty tomuto skriptu HiveQL za běhu.
Pokud chcete soubor uložit, vyberte Ctrl+X, zadejte Y a pak stiskněte Enter.
Pomocí následujícího příkazu zkopírujte
useooziewf.hql:wasbs:///tutorials/useoozie/useooziewf.hqlhdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlTento příkaz uloží
useooziewf.hqlsoubor do úložiště kompatibilního s HDFS pro cluster.
Definování pracovního postupu
Definice pracovních postupů Oozie jsou napsané v jazyce hPDL (Hadoop Process Definition Language), což je jazyk definice procesu XML. Pomocí následujících kroků definujte pracovní postup:
Pomocí následujícího příkazu vytvořte a upravte nový soubor:
nano workflow.xmlPo otevření editoru nano zadejte jako obsah souboru následující kód XML:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>V pracovním postupu jsou definovány dvě akce:
RunHiveScript: Tato akce je spouštěcí akce a spustíuseooziewf.hqlskript Hive.RunSqoopExport: Tato akce exportuje data vytvořená ze skriptu Hive do databáze SQL pomocí Sqoopu. Tato akce se spustí pouze v případě, žeRunHiveScriptje akce úspěšná.Pracovní postup obsahuje několik položek, například
${jobTracker}. Tyto položky nahradíte hodnotami, které použijete v definici úlohy. Definici úlohy vytvoříte později v tomto dokumentu.Všimněte si
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>také položky v oddílu Sqoop. Tato položka dává Oozie pokyn k zpřístupnění tohoto archivu pro Sqoop při spuštění této akce.
Pokud chcete soubor uložit, vyberte Ctrl+X, zadejte Y a pak stiskněte Enter.
Pomocí následujícího příkazu zkopírujte soubor do
workflow.xml/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Vytvoření tabulky
Poznámka:
Existuje mnoho způsobů, jak se připojit ke službě SQL Database a vytvořit tabulku. V následujících krocích se používá FreeTDS z clusteru HDInsight.
Pomocí následujícího příkazu nainstalujte FreeTDS do clusteru HDInsight:
sudo apt-get --assume-yes install freetds-dev freetds-binUpravte níže uvedený kód tak, aby se nahradil
<serverName>názvem logického sql serveru a<sqlLogin>přihlášením k serveru. Zadejte příkaz pro připojení k požadované databázi SQL. Zadejte heslo na příkazovém řádku.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestZobrazí se výstup podobný následujícímu textu:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>Na příkazovém řádku
1>zadejte následující řádky:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GOPo zadání příkazu
GOse vyhodnotí předchozí příkazy. Tyto příkazy vytvoří tabulku s názvemmobiledata, která je používána pracovním postupem.K ověření vytvoření tabulky použijte následující příkazy:
SELECT * FROM information_schema.tables GOZobrazí se výstup podobný následujícímu textu:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLEUkončete nástroj tsql zadáním
exitna příkazovém1>řádku.
Vytvoření definice úlohy
Definice úlohy popisuje, kde najít workflow.xml. Popisuje také, kde najít jiné soubory používané pracovním postupem, například useooziewf.hql. Definuje také hodnoty vlastností použitých v rámci pracovního postupu a přidružených souborů.
Pokud chcete získat úplnou adresu výchozího úložiště, použijte následující příkaz. Tato adresa se používá v konfiguračním souboru, který vytvoříte v dalším kroku.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlTento příkaz vrátí informace, jako je následující XML:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Poznámka:
Pokud cluster HDInsight jako výchozí úložiště používá Službu Azure Storage, začíná
wasbs://obsah elementu<value>. Pokud se místo toho použije Azure Data Lake Storage Gen1, začínáadl://na . Pokud se používá Azure Data Lake Storage Gen2, začínáabfs://na .Uložte obsah elementu
<value>, jak se používá v dalších krocích.Následujícím způsobem upravte soubor XML:
Hodnota zástupného symbolu Nahrazená hodnota wasbs://mycontainer@mystorageaccount.blob.core.windows.net Hodnota přijatá z kroku 1 správce Vaše přihlašovací jméno clusteru HDInsight, pokud není správce. serverName Název serveru Azure SQL Database sqlLogin Přihlášení k serveru Azure SQL Database sqlPassword Přihlašovací heslo serveru Azure SQL Database. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>Většina informací v tomto souboru slouží k naplnění hodnot použitých v souborech workflow.xml nebo ooziewf.hql, například
${nameNode}. Pokud jewasbscesta cestou, musíte použít úplnou cestu. Zkracujte ho jenwasbs:///. Položkaoozie.wf.application.pathdefinuje, kde najít workflow.xml soubor. Tento soubor obsahuje pracovní postup spuštěný touto úlohou.K vytvoření konfigurace definice úlohy Oozie použijte následující příkaz:
nano job.xmlPo otevření editoru nano vložte upravený kód XML jako obsah souboru.
Pokud chcete soubor uložit, vyberte Ctrl+X, zadejte Y a pak stiskněte Enter.
Odeslání a správa úlohy
Následující kroky používají příkaz Oozie k odeslání a správě pracovních postupů Oozie v clusteru. Příkaz Oozie je přátelské rozhraní přes rozhraní Oozie REST API.
Důležité
Při použití příkazu Oozie musíte použít plně kvalifikovaný název domény pro hlavní uzel HDInsight. Tento plně kvalifikovaný název domény je přístupný jenom z clusteru nebo pokud je cluster ve virtuální síti Azure, z jiných počítačů ve stejné síti.
Pokud chcete získat adresu URL služby Oozie, použijte následující příkaz:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlTato funkce vrátí informace jako následující kód XML:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>Část
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozieje adresa URL, která se má použít s příkazem Oozie.Upravte kód tak, aby nahradil adresu URL dříve přijatou adresou URL. Pokud chcete vytvořit proměnnou prostředí pro adresu URL, použijte následující příkaz, takže ho nemusíte zadávat pro každý příkaz:
export OOZIE_URL=http://HOSTNAMEt:11000/oozieK odeslání úlohy použijte následující kód:
oozie job -config job.xml -submitTento příkaz načte informace o
job.xmlúloze a odešle je do Oozie, ale nespustí je.Po dokončení příkazu by se mělo vrátit ID úlohy,
0000005-150622124850154-oozie-oozi-Wnapříklad . Toto ID slouží ke správě úlohy.Upravte následující kód a nahraďte
<JOBID>ho ID vráceným v předchozím kroku. Pokud chcete zobrazit stav úlohy, použijte následující příkaz:oozie job -info <JOBID>Vrátí informace podobné následujícímu textu:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------Tato úloha má stav
PREP. Tento stav označuje, že se úloha vytvořila, ale nezačala.Upravte níže uvedený kód a nahraďte
<JOBID>ho dříve vráceným ID. Pokud chcete úlohu spustit, použijte následující příkaz:oozie job -start <JOBID>Pokud zkontrolujete stav po tomto příkazu, je ve spuštěném stavu a informace se vrátí pro akce v rámci úlohy. Dokončení úlohy bude trvat několik minut.
Upravte níže uvedený kód tak, aby se nahradil
<serverName>názvem vašeho serveru a<sqlLogin>přihlášením k serveru. Po úspěšném dokončení úlohy můžete pomocí následujícího příkazu ověřit, že se data vygenerovala a exportovala do tabulky databáze SQL. Zadejte heslo na příkazovém řádku.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestNa příkazovém
1>řádku zadejte následující dotaz:SELECT * FROM mobiledata GOVrácené informace se podobaly následujícímu textu:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Další informace o příkazu Oozie naleznete v nástroji příkazového řádku Apache Oozie.
Oozie REST API
S rozhraním Oozie REST API můžete vytvářet vlastní nástroje, které pracují s Oozie. Následující informace specifické pro HDInsight o použití rozhraní Oozie REST API:
Identifikátor URI: K rozhraní REST API můžete přistupovat mimo cluster na adrese
https://CLUSTERNAME.azurehdinsight.net/oozie.Ověřování: K ověření použijte rozhraní API účtu HTTP clusteru (správce) a hesla. Příklad:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Další informace o tom, jak používat rozhraní Oozie REST API, naleznete v tématu Apache Oozie Web Services API.
Webové uživatelské rozhraní Oozie
Webové uživatelské rozhraní Oozie poskytuje webové zobrazení stavu úloh Oozie v clusteru. Pomocí webového uživatelského rozhraní můžete zobrazit následující informace:
- Stav úlohy
- Definice úlohy
- Konfigurace
- Graf akcí v úloze
- Protokoly pro úlohu
Můžete také zobrazit podrobnosti o akcích v rámci úlohy.
Pokud chcete získat přístup k webovému uživatelskému rozhraní Oozie, proveďte následující kroky:
Vytvořte tunel SSH ke clusteru HDInsight. Další informace najdete v tématu Použití tunelového propojení SSH se službou HDInsight.
Po vytvoření tunelu otevřete webové uživatelské rozhraní Ambari ve webovém prohlížeči pomocí identifikátoru URI
http://headnodehost:8080.Na levé straně stránky vyberte Oozie>Rychlé odkazy>Oozie Webové uživatelské rozhraní.
Ve výchozím nastavení webového uživatelského rozhraní Oozie se zobrazí spuštěné úlohy pracovního postupu. Pokud chcete zobrazit všechny úlohy pracovního postupu, vyberte Všechny úlohy.
Pokud chcete zobrazit další informace o úloze, vyberte úlohu.
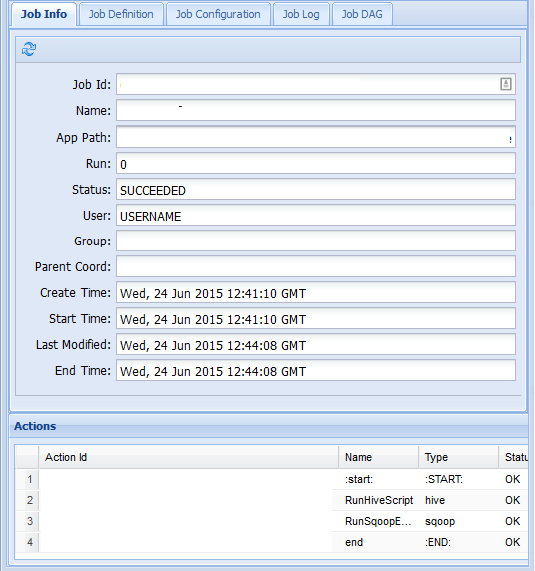
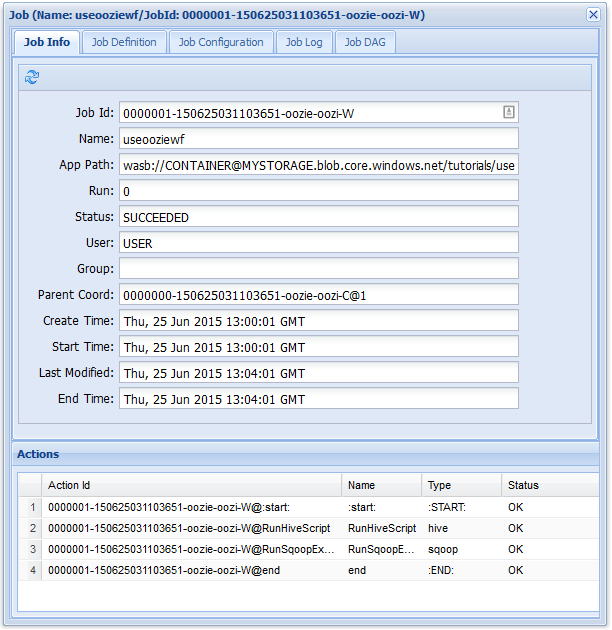
Na kartě Informace o úloze můžete zobrazit základní informace o úloze a jednotlivé akce v rámci úlohy. Karty v horní části můžete použít k zobrazení definice úlohy, konfigurace úlohy, přístupu k protokolu úloh nebo zobrazení řízeného acyklického grafu (DAG) úlohy v části DaG úlohy.
Protokol úloh: Vyberte tlačítko Získat protokoly , abyste získali všechny protokoly pro úlohu, nebo pomocí
Enter Search Filterpole vyfiltrujte protokoly.
DaG úlohy: DAG je grafický přehled datových cest, které procházejí pracovním postupem.
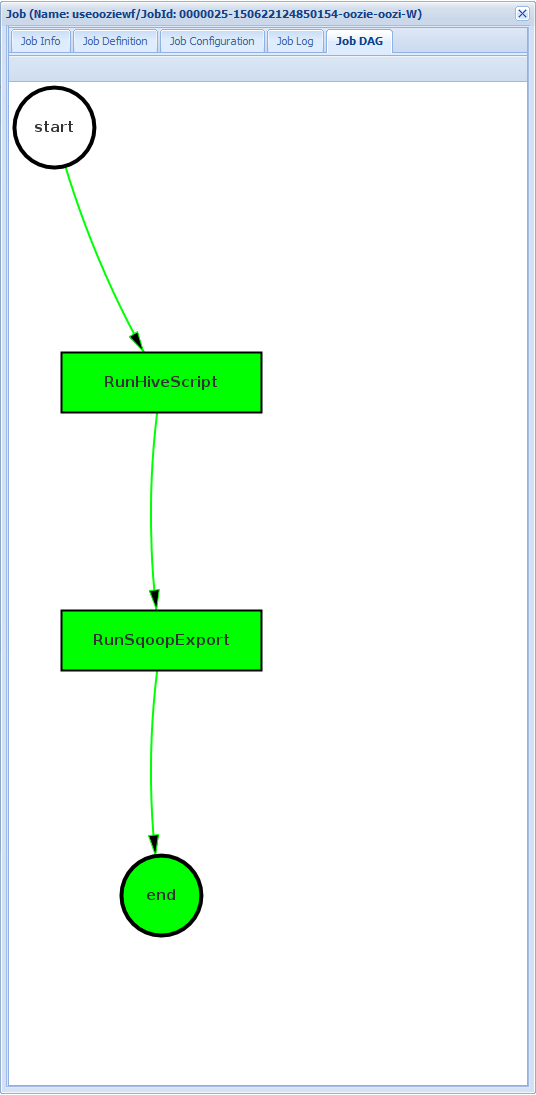
Pokud vyberete jednu z akcí na kartě Informace o úloze, zobrazí se informace o akci. Vyberte například akci RunSqoopExport .
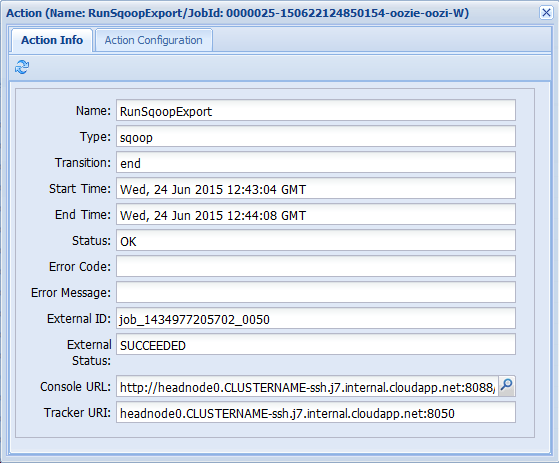
Můžete zobrazit podrobnosti o akci, například odkaz na adresu URL konzoly. Pomocí tohoto odkazu můžete zobrazit informace o sledování úloh pro úlohu.
Plánování úloh
Koordinátor můžete použít k určení počátečního, koncového a četnosti výskytů úloh. Pokud chcete definovat plán pracovního postupu, proveďte následující kroky:
Pomocí následujícího příkazu vytvořte soubor s názvem coordinator.xml:
nano coordinator.xmlJako obsah souboru použijte následující kód XML:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Poznámka:
Proměnné
${...}se nahradí hodnotami v definici úlohy za běhu. Proměnné jsou:${coordFrequency}: Doba mezi spuštěním instancí úlohy.${coordStart}: Čas spuštění úlohy.${coordEnd}: Čas ukončení úlohy.${coordTimezone}: Úlohy koordinátoru jsou v pevném časovém pásmu bez letního času, obvykle reprezentované pomocí utc. Toto časové pásmo se označuje jako časové pásmo zpracování Oozie.${wfPath}: Cesta k workflow.xml.
Pokud chcete soubor uložit, vyberte Ctrl+X, zadejte Y a pak stiskněte Enter.
Pokud chcete zkopírovat soubor do pracovního adresáře pro tuto úlohu, použijte následující příkaz:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlPokud chcete upravit
job.xmlsoubor, který jste vytvořili dříve, použijte následující příkaz:nano job.xmlProveďte následující změny:
Chcete-li dát Oozie pokyn ke spuštění koordinačního souboru místo pracovního postupu, změňte
<name>oozie.wf.application.path</name>na<name>oozie.coord.application.path</name>.Pokud chcete nastavit proměnnou
workflowPathpoužívanou koordinátorem, přidejte následující kód XML:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>wasbs://mycontainer@mystorageaccount.blob.core.windowsNahraďte text hodnotou použitou v ostatních položkách v souboru job.xml.Pokud chcete definovat začátek, konec a frekvenci koordinátoru, přidejte následující kód XML:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Tyto hodnoty nastaví počáteční čas na 12:00 10. května 2018 a koncový čas na 12. května 2018. Interval spuštění této úlohy je nastavený na denní. Frekvence je v minutách, takže 24 hodin x 60 minut = 1440 minut. Nakonec je časové pásmo nastavené na UTC.
Pokud chcete soubor uložit, vyberte Ctrl+X, zadejte Y a pak stiskněte Enter.
K odeslání a spuštění úlohy použijte následující příkaz:
oozie job -config job.xml -runPokud přejdete do webového uživatelského rozhraní Oozie a vyberete kartu Úlohy koordinátoru, zobrazí se informace jako na následujícím obrázku:

Položka Další materializace obsahuje při příštím spuštění úlohy.
Podobně jako v předchozí úloze pracovního postupu vyberete položku úlohy ve webovém uživatelském rozhraní, zobrazí se informace o úloze:
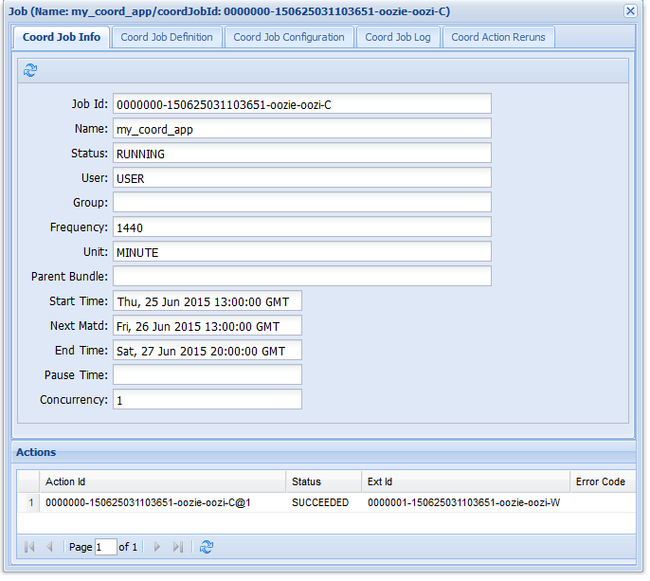
Poznámka:
Tento obrázek ukazuje pouze úspěšná spuštění úlohy, nikoli jednotlivé akce v rámci naplánovaného pracovního postupu. Pokud chcete zobrazit jednotlivé akce, vyberte jednu z položek akce .
Další kroky
V tomto článku jste zjistili, jak definovat pracovní postup Oozie a jak spustit úlohu Oozie. Další informace o tom, jak pracovat se službou HDInsight, najdete v následujících článcích: