Případová studie architektury řešení s vysokou dostupností ve službě Azure HDInsight
Mechanismy replikace služby Azure HDInsight je možné integrovat do architektury vysoce dostupných řešení. V tomto článku se fiktivní případová studie společnosti Contoso Retail používá k vysvětlení možných přístupů k zotavení po havárii s vysokou dostupností, aspektů nákladů a jejich odpovídajících návrhů.
Doporučení pro zotavení po havárii s vysokou dostupností můžou mít mnoho permutací a kombinací. Tato řešení musí být doručena po deliberování výhod a nevýhod jednotlivých možností. Tento článek popisuje pouze jedno možné řešení.
Architektura zákazníka
Následující obrázek znázorňuje primární architekturu contoso retailu. Architektura se skládá z úlohy streamování, dávkové úlohy, obsluhující vrstvy, vrstvy spotřeby, vrstvy úložiště a správy verzí.
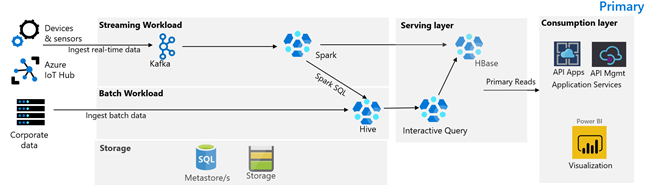
Úloha streamování
Zařízení a senzory vytvářejí data do HDInsight Kafka, což představuje architekturu zasílání zpráv. Příjemce SPARKu HDInsight čte z témat Kafka. Spark transformuje příchozí zprávy a zapíše je do clusteru HDInsight HBase na obslužné vrstvě.
Dávkové úlohy
Cluster HDInsight Hadoop se systémem Hive a MapReduce ingestuje data z místních transakčních systémů. Nezpracovaná data transformovaná Hivem a MapReduce se ukládají v tabulkách Hive v logickém oddílu datového jezera zálohovaného službou Azure Data Lake Storage Gen2. Data uložená v tabulkách Hive jsou také dostupná pro Spark SQL, která provádí dávkové transformace před uložením kurátorovaných dat do HBase pro obsluhu.
Obslužná vrstva
Cluster HDInsight HBase s Apache Phoenixem slouží k poskytování dat webovým aplikacím a řídicím panelům vizualizace. Cluster HDInsight LLAP slouží ke splnění interních požadavků na vytváření sestav.
Vrstva spotřeby
Vrstva Azure API Apps a API Management zpět veřejná webová stránka. Power BI splňuje interní požadavky na vytváření sestav.
Vrstva úložiště
Logicky dělené Azure Data Lake Storage Gen2 se používá jako podnikové datové jezero. Metastory HDInsight jsou podporovány službou Azure SQL DB.
Systém správy verzí
Systém správy verzí integrovaný do Azure Pipelines a hostovaný mimo Azure.
Požadavky na provozní kontinuitu zákazníků
Je důležité určit minimální obchodní funkce, které budete potřebovat, pokud dojde k havárii.
Požadavky společnosti Contoso Retail na kontinuitu podnikových procesů
- Musíme být chráněni před regionálním selháním nebo regionálním problémem se stavem služeb.
- Moji zákazníci nesmí nikdy vidět chybu 404. Veřejný obsah musí být vždy obsloužen. (RTO = 0)
- Ve většině částí roku můžeme zobrazit veřejný obsah, který je zastaralý o 5 hodin. (RPO = 5 hodin)
- Během svátků musí být náš veřejný obsah vždy aktuální. (RPO = 0)
- Moje interní požadavky na vytváření sestav nejsou pro provozní kontinuitu považovány za důležité.
- Optimalizujte náklady na provozní kontinuitu.
Navrhované řešení
Následující obrázek ukazuje architekturu zotavení po havárii společnosti Contoso Retail s vysokou dostupností.
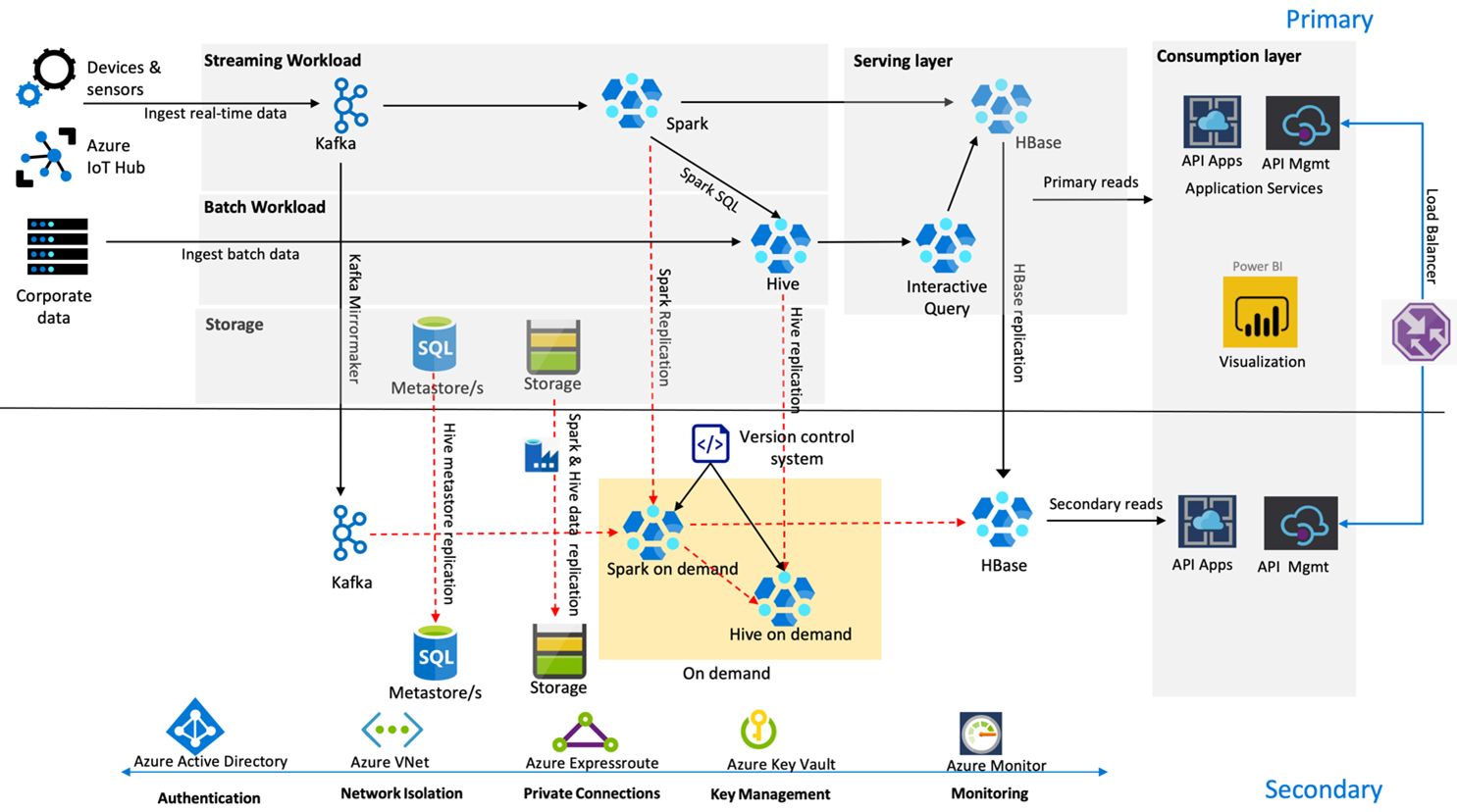
Kafka používá aktivní – pasivní replikaci k zrcadlení témat Kafka z primární oblasti do sekundární oblasti. Alternativou k replikaci Kafka může být vytvoření do Kafka v obou oblastech.
Hive a Spark používají aktivní primární – sekundární modely replikace na vyžádání v normálních časech. Proces replikace Hive se pravidelně spouští a doprovází replikaci účtu úložiště Hive a metastoru Azure SQL a účtu úložiště Hive. Účet úložiště Spark se pravidelně replikuje pomocí ADF DistCP. Přechodná povaha těchto clusterů pomáhá optimalizovat náklady. Replikace se naplánují každých 4 hodiny tak, aby dorazily do cíle bodu obnovení, který je v pětihodinovém požadavku.
Replikace HBase používá model Leader – Follower v normálních časech, aby se zajistilo, že se data vždy obsluhují bez ohledu na oblast a cíl bodu obnovení je velmi nízký.
Pokud v primární oblasti dojde k selhání oblasti, webová stránka a back-endový obsah se obsluhují ze sekundární oblasti po dobu 5 hodin s určitým stupněm nestaralosti. Pokud řídicí panel stavu služby Azure v pětihodinovém intervalu nezvýší ETA pro obnovení, vytvoří maloobchodní prodej společnosti Contoso vrstvu transformace Hive a Spark v sekundární oblasti a pak nasměruje všechny nadřazené zdroje dat do sekundární oblasti. Zápis sekundární oblasti by způsobil proces navrácení služeb po obnovení, který zahrnuje replikaci zpět do primární oblasti.
Během špičky nákupní sezóny je celý sekundární kanál vždy aktivní a spuštěný. Producenti Kafka generují replikaci HBase jak do oblastí, tak z nástroje Leader-Follower na Leader-Leader, aby se zajistilo, že veřejný obsah bude vždy aktuální.
Pro interní vytváření sestav není potřeba navrhovat žádné řešení převzetí služeb při selhání, protože pro provozní kontinuitu není důležité.
Další kroky
Další informace o položkách probíraných v tomto článku najdete tady: