Oprava chyby nedostatku paměti Apache Hivu ve službě Azure HDInsight
Zjistěte, jak opravit chybu Apache Hivu kvůli nedostatku paměti (OOM) při zpracování velkých tabulek konfigurací nastavení paměti Hive.
Spuštění dotazu Apache Hive na velké tabulky
Zákazník spustil dotaz Hive:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Některé drobné odlišnosti tohoto dotazu:
- T1 je alias pro velkou tabulku TABLE1, která obsahuje spoustu typů sloupců STRING.
- Jiné tabulky nejsou tak velké, ale mají mnoho sloupců.
- Všechny tabulky se vzájemně spojují, v některých případech s více sloupci v tabulce TABLE1 a dalšími.
Dokončení dotazu Hive na clusteru HDInsight s 24 uzly A3 trvalo 26 minut. Zákazník si všiml následujících zpráv upozornění:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Pomocí prováděcího modulu Apache Tez. Stejný dotaz běžel 15 minut a pak vyvolal následující chybu:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
Chyba zůstane při použití většího virtuálního počítače (například D12).
Ladění chyby nedostatku paměti
Naše týmy podpory a technické týmy společně našli jeden z problémů způsobujících chybu nedostatku paměti jako známý problém popsaný v Apache JIRA:
"Když hive.auto.convert.join.noconditionaltask = true zkontrolujeme noconditionaltask.size a pokud je součet velikostí tabulek ve spojení s mapou menší než noconditionaltask.size plán by vygeneroval spojení s mapou, problém s tím spočívá v tom, že výpočet nebere v úvahu režijní náklady zavedené jinou implementací HashTable jako výsledky, pokud je součet velikostí vstupu menší než velikost noconditionaltask malými dotazy okrajů dosáhne OOM."
Hive.auto.convert.join.noconditionaltask v souboru hive-site.xml byl nastaven na hodnotu true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Připojení k mapě je pravděpodobně příčinou chyby nedostatku paměti haldy Javy. Jak je vysvětleno v blogovém příspěvku Hadoop Yarn nastavení paměti v HDInsight, když prováděcí modul Tez použil místo haldy použité skutečně patří do kontejneru Tez. Viz následující obrázek popisující paměť kontejneru Tez.
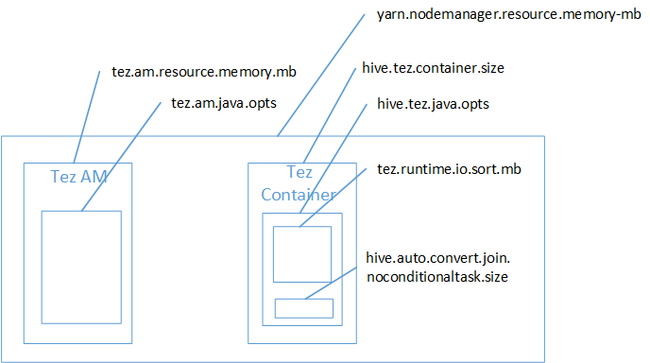
Jak napovídá příspěvek blogu, následující dvě nastavení paměti definují paměť kontejneru pro haldu: hive.tez.container.size a hive.tez.java.opts. Z našeho prostředí výjimka nedostatku paměti neznamená, že velikost kontejneru je příliš malá. To znamená, že velikost haldy Java (hive.tez.java.opts) je příliš malá. Takže kdykoli uvidíte nedostatek paměti, můžete se pokusit zvýšit hive.tez.java.opts. V případě potřeby možná budete muset zvýšit hive.tez.container.size. Nastavení java.opts by mělo být přibližně 80 % velikosti kontejneru.
Poznámka:
Nastavení hive.tez.java.opts musí být vždy menší než hive.tez.container.size.
Vzhledem k tomu, že počítač D12 má 28 GB paměti, rozhodli jsme se použít velikost kontejneru 10 GB (10240 MB) a přiřadit 80 % java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
S novým nastavením se dotaz úspěšně spustil za méně než 10 minut.
Další kroky
Chyba OOM nemusí nutně znamenat, že velikost kontejneru je příliš malá. Místo toho byste měli nakonfigurovat nastavení paměti tak, aby se zvětšila velikost haldy a byla alespoň 80 % velikosti paměti kontejneru. Informace o optimalizaci dotazů Hive najdete v tématu Optimalizace dotazů Apache Hive pro Apache Hadoop ve službě HDInsight.