Automatické škálování clusterů Azure HDInsight
Funkce bezplatného automatického škálování Azure HDInsight může automaticky zvýšit nebo snížit počet pracovních uzlů ve vašem clusteru na základě metrik clusteru a zásad škálování přijatých zákazníky. Funkce automatického škálování funguje škálováním počtu uzlů v rámci přednastavených limitů na základě metrik výkonu nebo definovaného plánu operací vertikálního navýšení nebo snížení kapacity.
Jak to funguje
Funkce automatického škálování používá k aktivaci událostí škálování dva typy podmínek: prahové hodnoty pro různé metriky výkonu clusteru (označované jako škálování založené na zatížení) a triggery založené na čase (označované jako škálování založené na plánu). Škálování na základě zatížení změní počet uzlů v clusteru v rozsahu, který nastavíte, aby se zajistilo optimální využití procesoru a minimalizovalo provozní náklady. Škálování na základě plánu mění počet uzlů v clusteru na základě plánu operací vertikálního navýšení a snížení kapacity.
Následující video obsahuje přehled výzev, které automatické škálování řeší a jak vám může pomoct řídit náklady s HDInsightem.
Volba škálování na základě zatížení nebo podle plánu
Škálování na základě plánu je možné použít:
- Pokud se očekává, že se vaše úlohy budou spouštět podle pevných plánů a předvídatelné doby trvání nebo pokud očekáváte nízké využití v určitých časech dne. Například testovací a vývojová prostředí v pracovní době, koncové úlohy.
Můžete použít škálování na základě zatížení:
- Když vzorce zatížení během dne výrazně a nepředvídatelně kolísá. Můžete například uspořádat zpracování dat s náhodnými výkyvy ve vzorech zatížení na základě různých faktorů.
Metriky clusteru
Automatické škálování nepřetržitě monitoruje cluster a shromažďuje následující metriky:
| Metrický | Popis |
|---|---|
| Celkový počet nevyřízených procesorů | Celkový počet jader potřebných k zahájení spouštění všech čekajících kontejnerů. |
| Celková nevyřízená paměť | Celková paměť (v MB) potřebná ke spuštění spuštění všech čekajících kontejnerů. |
| Celkový počet bezplatných procesorů | Součet všech nepoužívaných jader na aktivních pracovních uzlech. |
| Celková paměť volného místa | Součet nevyužité paměti (v MB) na aktivních pracovních uzlech. |
| Využitá paměť na uzel | Zatížení pracovního uzlu. Pracovní uzel, na kterém se používá 10 GB paměti, se považuje za méně zatížení než pracovní uzel s 2 GB využité paměti. |
| Počet hlavních serverů aplikací na uzel | Početkontejnerůch Pracovní uzel, který hostuje dva kontejnery AM, je považován za důležitější než pracovní uzel, který hostuje nulové kontejnery AM. |
Výše uvedené metriky se kontrolují každých 60 sekund. Automatické škálování provádí rozhodnutí o vertikálním navýšení a snížení kapacity na základě těchto metrik.
Úplný seznam metrik clusteru najdete v tématu Podporované metriky pro Microsoft.HDInsight/clustery.
Podmínky škálování na základě zatížení
Když se zjistí následující podmínky, automatické škálování vydá žádost o škálování:
| Vertikální navýšení kapacity | Vertikální snížení kapacity |
|---|---|
| Celkový počet nevyřízených procesorů je větší než celkový bezplatný procesor za více než 3 až 5 minut. | Celkový počet nevyřízených procesorů je menší než celkový bezplatný procesor za více než 3 až 5 minut. |
| Celková nevyřízená paměť je větší než celková bezplatná paměť za více než 3 až 5 minut. | Celková nevyřízená paměť je menší než celková bezplatná paměť za více než 3 až 5 minut. |
U vertikálního navýšení kapacity vydá automatické škálování požadavek na vertikální navýšení kapacity, aby se přidal požadovaný počet uzlů. Vertikální navýšení kapacity vychází z toho, kolik nových pracovních uzlů je potřeba ke splnění aktuálních požadavků na procesor a paměť.
V případě vertikálního snížení kapacity vydá automatické škálování žádost o odebrání některých uzlů. Vertikální snížení kapacity je založené na počtu kontejnerů hlavního serveru (AM) na jeden uzel. A aktuální požadavky na procesor a paměť. Služba také zjistí, které uzly jsou kandidáty na odebrání, na základě aktuálního spuštění úlohy. Operace vertikálního snížení kapacity nejprve vyřadí uzly z provozu a pak je odebere z clusteru.
Důležité informace o velikosti databáze Ambari pro automatické škálování
Doporučuje se, aby databáze Ambari správně zhodnotila výhody automatického škálování. Zákazníci by měli použít správnou úroveň databáze a používat vlastní databázi Ambari pro clustery s velkými velikostmi. Přečtěte si doporučení týkající se velikosti databáze a hlavního uzlu.
Kompatibilita clusteru
Důležité
Funkce automatického škálování Azure HDInsight se 7. listopadu 2019 vydala ve fázi obecné dostupnosti pro clustery Spark a Hadoop a zahrnovala vylepšení, která nebyla k dispozici ve verzi Preview této funkce. Pokud jste vytvořili cluster Spark před 7. listopadem 2019 a chcete v clusteru použít funkci automatického škálování, doporučujeme vytvořit nový cluster a enable Autoscale v novém clusteru.
Automatické škálování pro Interactive Query (LLAP) bylo vydáno pro obecnou dostupnost pro HDI 4.0 27. srpna 2020. Automatické škálování je dostupné jenom v clusterech Spark, Hadoop a Interactive Query.
Následující tabulka popisuje typy a verze clusterů, které jsou kompatibilní s funkcí automatického škálování.
| Verze | Spark | Hive | Interaktivní dotaz | HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 bez ESP | Ano | Yes | Ano* | No | Ne |
| HDInsight 4.0 s ESP | Ano | Yes | Ano* | No | Ne |
| HDInsight 5.0 bez ESP | Ano | Yes | Ano* | No | Ne |
| HDInsight 5.0 s ESP | Ano | Yes | Ano* | No | Ne |
* Clustery Interactive Query lze nakonfigurovat pouze pro škálování na základě plánu, nikoli na základě zatížení.
Začínáme
Vytvoření clusteru s automatickým škálováním na základě zatížení
Pokud chcete povolit funkci automatického škálování se škálováním na základě zatížení, proveďte v rámci normálního procesu vytváření clusteru následující kroky:
Na kartě Konfigurace a ceny zaškrtněte
Enable autoscalepolíčko.V části Typ automatického škálování vyberte na základě zatížení.
Zadejte požadované hodnoty pro následující vlastnosti:
- Počáteční počet uzlů pro pracovní uzel
- Minimální počet pracovníchuzlůch
- Maximální počet pracovníchuzlůch
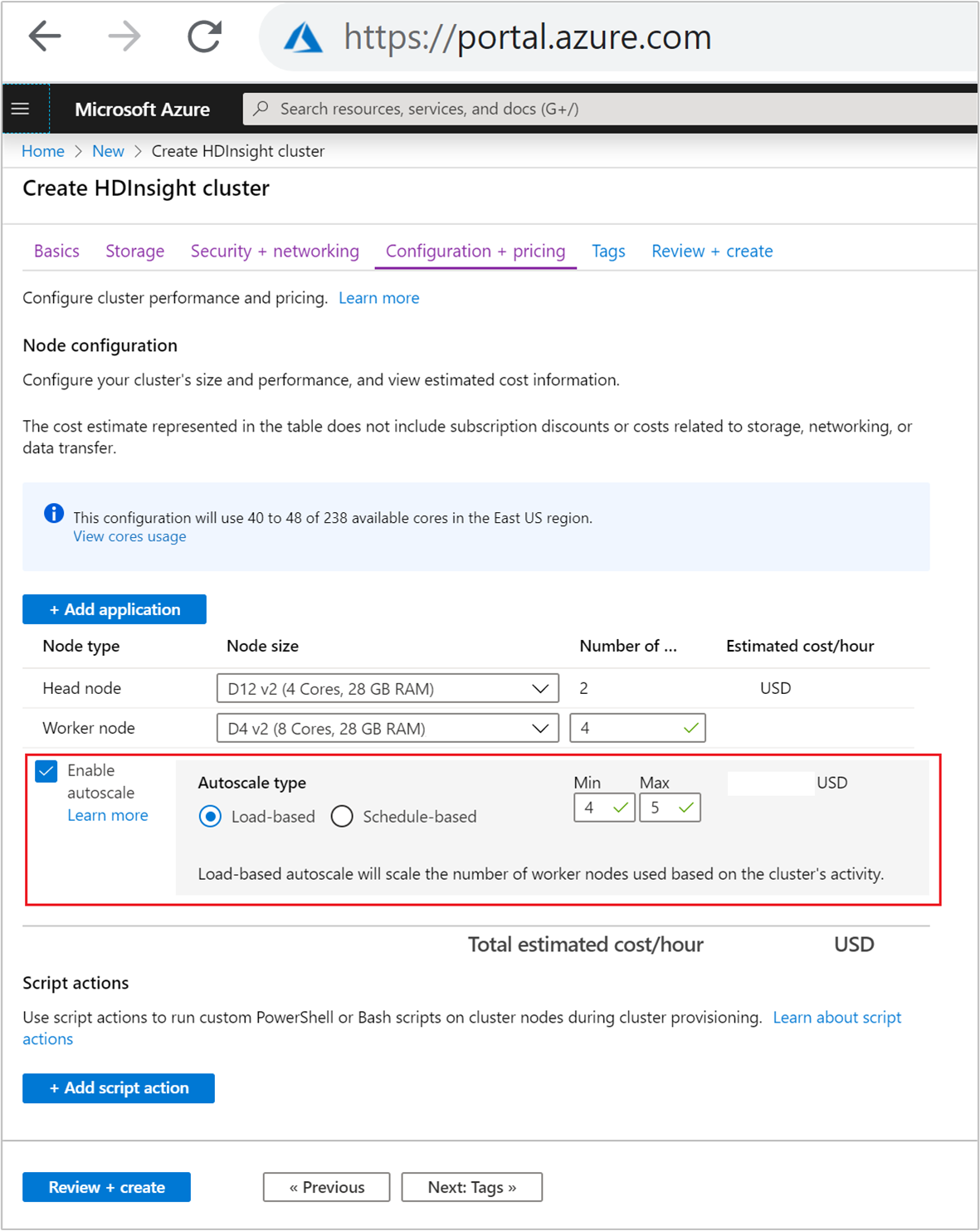
Počáteční počet pracovníchuzlůchch Tato hodnota definuje počáteční velikost clusteru při jeho vytvoření. Minimální počet pracovních uzlů by měl být nastaven na tři nebo více. Škálování clusteru na méně než tři uzly může způsobit zablokování v nouzovém režimu kvůli nedostatečné replikaci souborů. Další informace naleznete v tématu Zablokování v nouzovém režimu.
Vytvoření clusteru s automatickým škálováním na základě plánu
Pokud chcete povolit funkci automatického škálování se škálováním na základě plánu, proveďte v rámci normálního procesu vytváření clusteru následující kroky:
Na kartě Konfigurace a ceny zaškrtněte
Enable autoscalepolíčko.Zadejte početuzlůchch
V části Typ automatického škálování vyberte možnost Plán.
Výběrem možnosti Konfigurovat otevřete okno konfigurace automatického škálování.
Vyberte časové pásmo a potom klikněte na + Přidat podmínku.
Vyberte dny v týdnu, na které má nová podmínka platit.
Upravte čas, kdy se má podmínka projevit, a počet uzlů, na které se má cluster škálovat.
V případě potřeby přidejte další podmínky.
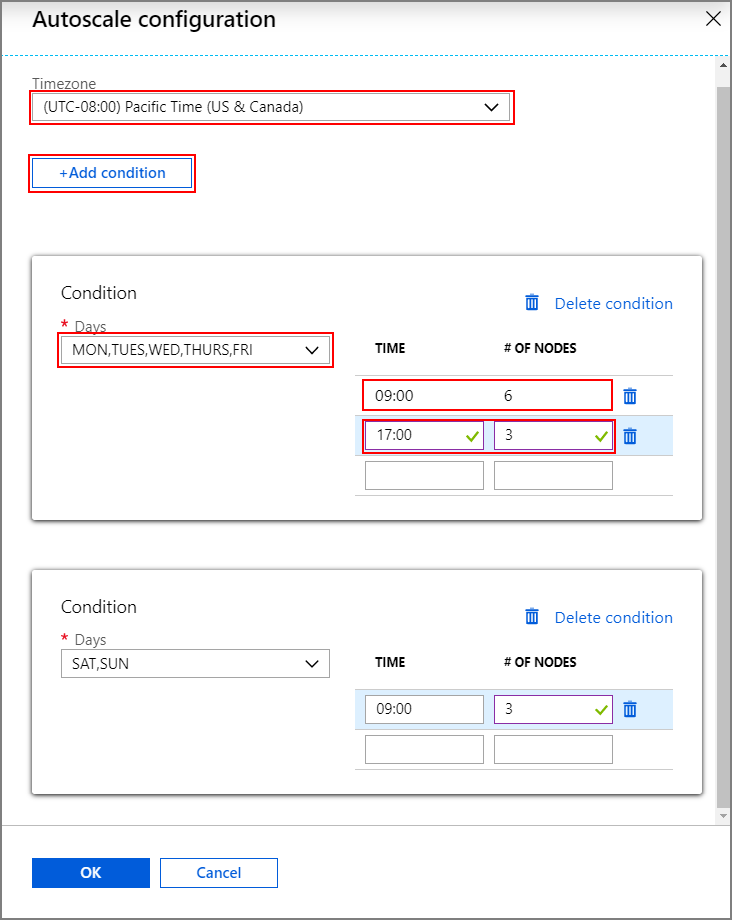
Počet uzlů musí být mezi 3 a maximálním počtem pracovních uzlů, které jste zadali před přidáním podmínek.
Konečné kroky vytvoření
Vyberte typ virtuálního počítače pro pracovní uzly tak, že v rozevíracím seznamu v části Velikost uzlu vyberete virtuální počítač. Po výběru typu virtuálního počítače pro každý typ uzlu se zobrazí odhadovaný rozsah nákladů pro celý cluster. Upravte typy virtuálních počítačů tak, aby odpovídaly rozpočtu.
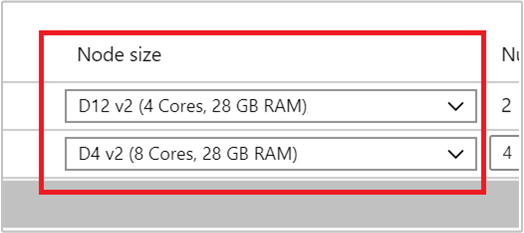
Vaše předplatné má kvótu kapacity pro každou oblast. Celkový počet jader hlavních uzlů a maximální počet pracovních uzlů nesmí překročit kvótu kapacity. Tato kvóta je však měkkým limitem; Kdykoli můžete vytvořit lístek podpory, abyste ho mohli snadno zvýšit.
Poznámka:
Pokud překročíte limit celkové kvóty jader, zobrazí se chybová zpráva s informací, že maximální počet uzlů překročil dostupné jádra v této oblasti, zvolte jinou oblast nebo požádejte podporu o navýšení kvóty.
Další informace o vytváření clusteru HDInsight pomocí webu Azure Portal najdete v tématu Vytváření clusterů založených na Linuxu ve službě HDInsight pomocí webu Azure Portal.
Vytvoření clusteru pomocí šablony Resource Manageru
Automatické škálování na základě zatížení
Cluster HDInsight s automatickým škálováním založeným na zatížení můžete vytvořit pomocí šablony Azure Resource Manageru tak, že do computeProfile>workernode oddílu přidáte autoscale uzel s vlastnostmi minInstanceCount a maxInstanceCount jak je znázorněno v fragmentu kódu JSON. Kompletní šablonu Resource Manageru najdete v tématu Rychlý start: Nasazení clusteru Spark s povoleným automatickým škálováním na základě zatížení.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Automatické škálování na základě plánu
Cluster HDInsight s automatickým škálováním založeným na plánu můžete vytvořit pomocí šablony Azure Resource Manageru přidáním autoscale uzlu do oddílu>computeProfileworkernode. Uzel autoscale obsahuje recurrence uzel, který obsahuje timezone a schedule který popisuje, kdy se změna provede. Kompletní šablonu Resource Manageru najdete v tématu Nasazení clusteru Spark s povoleným automatickým škálováním založeným na plánu.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Povolení a zakázání automatického škálování pro spuštěný cluster
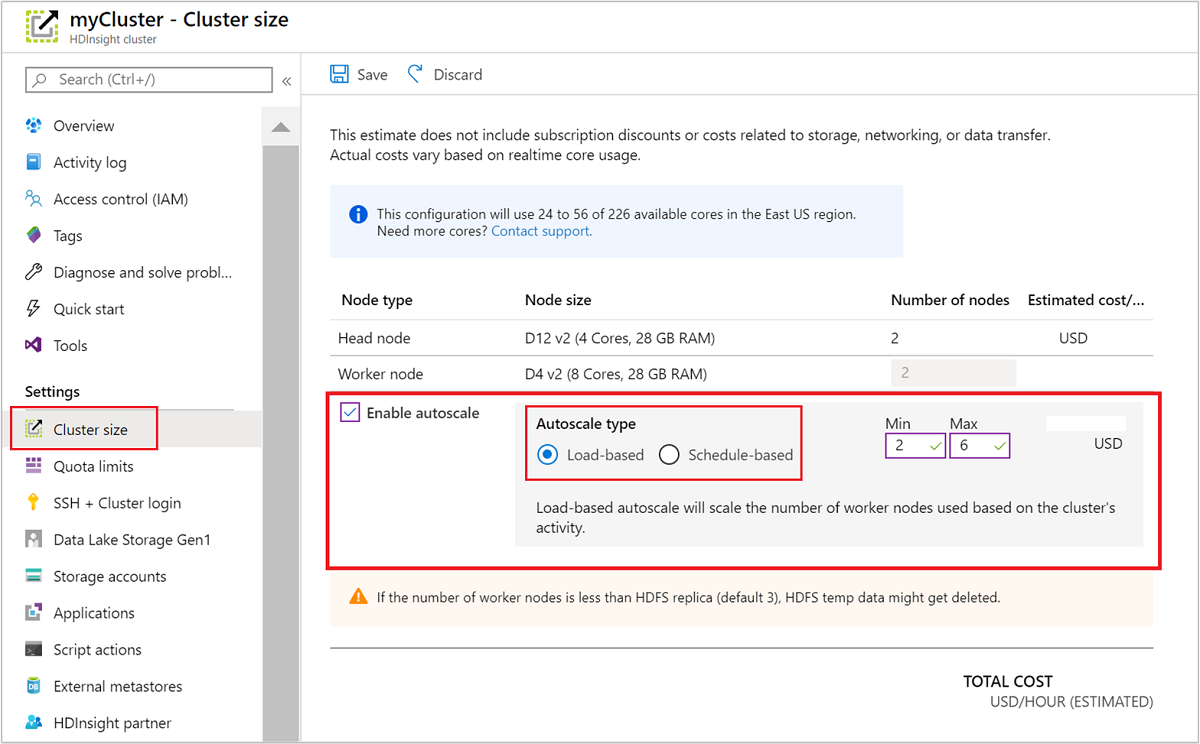
Pomocí webu Azure Portal
Pokud chcete povolit automatické škálování ve spuštěném clusteru, vyberte v části Nastavení velikost clusteru. Pak vyberte Enable autoscale. Vyberte požadovaný typ automatického škálování a zadejte možnosti pro škálování na základě zatížení nebo podle plánu. Nakonec vyberte Uložit.
S využitím REST API
Pokud chcete povolit nebo zakázat automatické škálování spuštěného clusteru pomocí rozhraní REST API, nastavte požadavek POST na koncový bod automatického škálování:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Použijte příslušné parametry v datové části požadavku. Následující datovou část JSON je možné použít k enable Autoscale. Pomocí datové části {autoscale: null} zakažte automatické škálování.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Úplný popis všech parametrů datové části najdete v předchozí části povolení automatického škálování založeného na zatížení. Nedoporučuje se v běžícím clusteru zakázat službu automatického škálování vynuceně.
Monitorování aktivit automatického škálování
Stav clusteru
Stav clusteru uvedený na webu Azure Portal vám může pomoct monitorovat aktivity automatického škálování.
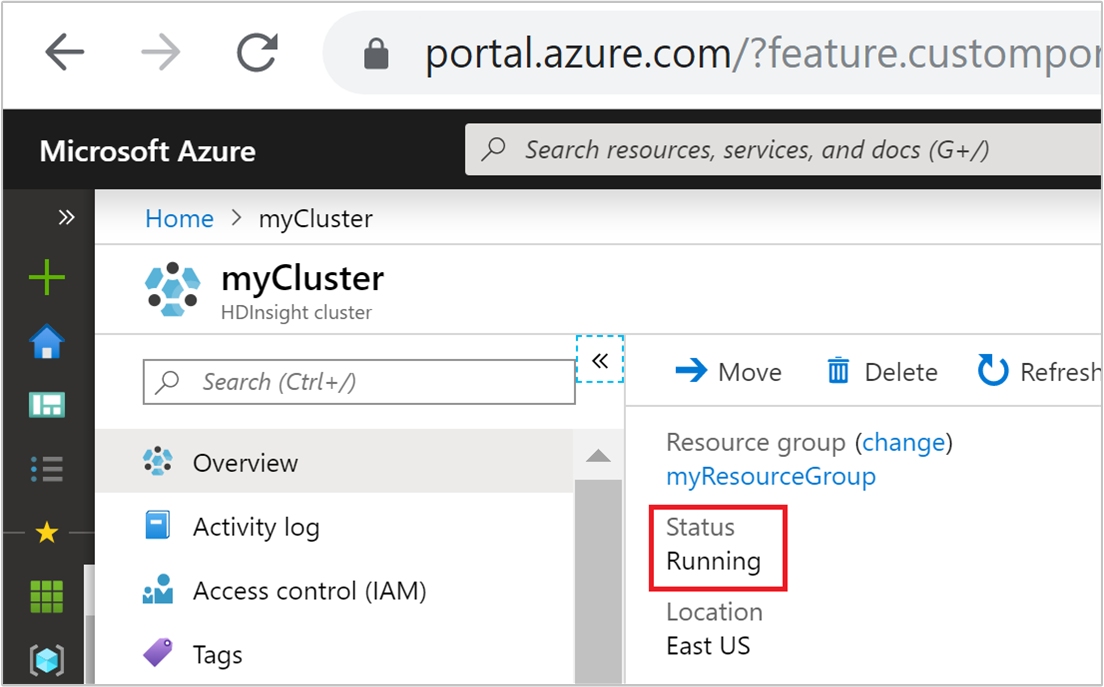
Všechny stavové zprávy clusteru, které se můžou zobrazit, jsou vysvětlené v následujícím seznamu.
| Stav clusteru | Popis |
|---|---|
| Spuštěno | Cluster funguje normálně. Všechny předchozí aktivity automatického škálování byly úspěšně dokončeny. |
| Aktualizace | Aktualizuje se konfigurace automatického škálování clusteru. |
| Konfigurace HDInsightu | Probíhá operace vertikálního navýšení nebo snížení kapacity clusteru. |
| Chyba při aktualizaci | Během aktualizace konfigurace automatického škálování došlo k problémům se službou HDInsight. Zákazníci se můžou rozhodnout, jestli aktualizaci zopakovat, nebo zakázat automatické škálování. |
| Chyba | Něco je v clusteru špatně a není použitelné. Odstraňte tento cluster a vytvořte nový. |
Pokud chcete zobrazit aktuální počet uzlů v clusteru, přejděte na graf velikostí clusteru na stránce Přehled vašeho clusteru. Nebo vyberte velikost clusteru v části Nastavení.
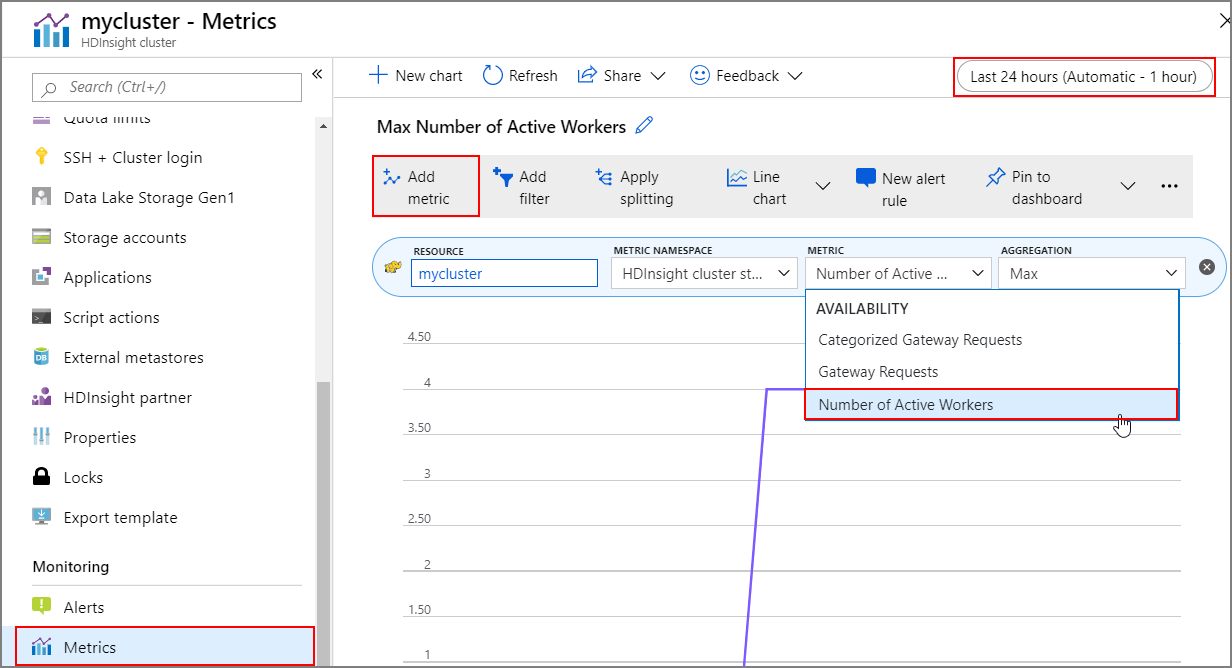
Historie operací
Historii vertikálního navýšení a snížení kapacity clusteru můžete zobrazit jako součást metrik clusteru. Můžete také zobrazit seznam všech akcí škálování za poslední den, týden nebo jiné časové období.
V části Monitorování vyberte metriky. Potom v rozevíracím seznamu Metrika vyberte Přidat metriku a Počet aktivních pracovních procesů. Výběrem tlačítka v pravém horním rohu změňte časový rozsah.
Osvědčené postupy
Zvažte latenci operací vertikálního navýšení a snížení kapacity.
Dokončení celkové operace škálování může trvat 10 až 20 minut. Při nastavování přizpůsobeného plánu naplánujte toto zpoždění. Pokud například potřebujete velikost clusteru 20 v 9:00, nastavte aktivační událost plánu na dřívější čas, například 8:30 AM nebo starší, aby operace škálování dokončila do 9:00.
Příprava na vertikální snížení kapacity
Během procesu vertikálního snížení kapacity clusteru automatické škálování vyřadí uzly z provozu, aby splňovaly cílovou velikost. Pokud na těchto uzlech běží úlohy na základě zatížení, automatické škálování počká, dokud se úlohy nedokončí pro clustery Spark a Hadoop. Vzhledem k tomu, že každý pracovní uzel také obsluhuje roli v HDFS, dočasná data se přesunou na zbývající pracovní uzly. Ujistěte se, že je na zbývajících uzlech dostatek místa pro hostování všech dočasných dat.
Poznámka:
V případě vertikálního snížení kapacity na základě plánu není podporované řádné vyřazení z provozu. To může způsobit selhání úloh během operace vertikálního snížení kapacity a doporučuje se naplánovat plány na základě předpokládaných vzorů plánu úloh tak, aby zahrnovaly dostatečný čas na dokončení probíhajících úloh. Plány můžete nastavit tak, aby se zabránilo selháním úloh.
Konfigurace automatického škálování založeného na plánu na základě vzoru využití
Při konfiguraci automatického škálování na základě plánu je potřeba porozumět vzoru využití clusteru. Řídicí panel Grafana vám může pomoct pochopit vaše sloty načítání a spouštění dotazů. Z řídicího panelu můžete získat dostupné sloty exekutoru a celkové sloty exekutoru.
Tady je způsob, jak odhadnout, kolik pracovních uzlů je potřeba. Doporučujeme dát další 10% vyrovnávací paměť pro zpracování variace úlohy.
Počet použitých slotů exekutoru = Celkový počet slotů exekutoru – celkový počet dostupných slotů exekutoru.
Počet požadovaných pracovních uzlů = počet skutečně použitých slotů exekutoru / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size).
*hive.llap.daemon.num.executors je konfigurovatelná a výchozí hodnota je 4.
*hive.llap.daemon.task.scheduler.wait.queue.size je konfigurovatelná a výchozí hodnota je 10.
Akce vlastních skriptů
Akce vlastních skriptů se většinou používají k přizpůsobení uzlů (HeadNode / WorkerNodes), které našim zákazníkům umožňují konfigurovat určité knihovny a nástroje, které je používají. Jedním z běžných případů použití jsou úlohy, které běží v clusteru, můžou mít určité závislosti na knihovně třetí strany, která je vlastníkem zákazníka, a měla by být k dispozici na uzlech, aby úloha uspěla. U automatického škálování aktuálně podporujeme akce vlastních skriptů, které jsou trvalé, takže pokaždé, když se do clusteru přidají nové uzly jako součást operace vertikálního navýšení kapacity, tyto trvalé akce skriptů se spustí a použijí se pro ně kontejnery nebo úlohy. I když akce vlastních skriptů pomáhají s spouštěním nových uzlů, doporučuje se zachovat minimální kapacitu, protože by se přidala k celkové latenci vertikálního navýšení kapacity a mohlo by to mít vliv na naplánované úlohy.
Mějte na paměti minimální velikost clusteru.
Vertikálně navyšujte kapacitu clusteru na méně než tři uzly. Škálování clusteru na méně než tři uzly může způsobit zablokování v nouzovém režimu kvůli nedostatečné replikaci souborů. Další informace najdete v tématu Zablokování v nouzovém režimu.
Operace microsoft Entra Domain Services a škálování
Pokud používáte cluster HDInsight s balíčkem zabezpečení podniku (ESP), který je připojený ke spravované doméně služby Microsoft Entra Domain Services, doporučujeme omezení zatížení služby Microsoft Entra Domain Services. Ve složitých adresářových strukturách s vymezenou synchronizací doporučujeme vyhnout se dopadu na operace škálování.
Nastavení maximálního celkového počtu souběžných dotazů Hive pro scénář využití ve špičce
Události automatického škálování nemění konfiguraci Hive Maximální celkový počet souběžných dotazů v Ambari. To znamená, že interaktivní služba Hive Server 2 dokáže zpracovat pouze daný počet souběžných dotazů v libovolném okamžiku, a to i v případě, že je počet démonů interaktivních dotazů škálován nahoru a dolů na základě zatížení a plánu. Obecné doporučení je nastavit tuto konfiguraci pro scénář použití ve špičce, aby se zabránilo ručnímu zásahu.
Pokud ale existuje jenom několik pracovních uzlů a hodnota maximálního celkového počtu souběžných dotazů je příliš vysoká, může dojít k selhání restartování Hive Serveru 2. Minimálně potřebujete minimální počet pracovních uzlů, které se dají přizpůsobit danému Tez Ams počtu (rovnající se konfiguraci maximálního počtu souběžných dotazů).
Omezení
Počet démon interaktivních dotazů
Pokud jsou clustery Interactive Query s povoleným automatickým škálováním, událost automatického škálování také vertikálně navyšuje nebo snižuje počet démonů Interaktivních dotazů na počet aktivních pracovních uzlů. Změna počtu démonů se v konfiguraci v Ambari neuchová num_llap_nodes . Pokud se služby Hive restartují ručně, počet démonů Interaktivních dotazů se resetuje podle konfigurace v Ambari.
Pokud je služba Interactive Query ručně restartována, musíte ručně změnit num_llap_node konfiguraci (počet uzlů potřebných ke spuštění démona Hive Interactive Query) v rozšířeném podregistru Hive-interactive-env tak, aby odpovídal aktuálnímu počtu aktivních pracovních uzlů. Interaktivní cluster dotazů podporuje pouze automatické škálování založené na plánu.
Další kroky
Přečtěte si o pokynech pro ruční škálování clusterů v pokynech ke škálování.