Použití Apache Hivu jako nástroje pro extrakci, transformaci a načítání (ETL)
Před načtením do cíle vhodného pro analýzu obvykle potřebujete vyčistit a transformovat příchozí data. Operace extrakce, transformace a načítání (ETL) slouží k přípravě dat a jejich načtení do cíle dat. Apache Hive ve službě HDInsight může číst v nestrukturovaných datech, zpracovávat data podle potřeby a pak je načíst do relačního datového skladu pro systémy podpory rozhodování. V tomto přístupu se data extrahují ze zdroje. Pak se uloží v přizpůsobitelném úložišti, jako jsou objekty blob služby Azure Storage nebo Azure Data Lake Storage. Data se pak transformují pomocí posloupnosti dotazů Hive. Pak se v rámci Hivu připraví k hromadnému načítání do cílového úložiště dat.
Přehled případů použití a modelu
Následující obrázek ukazuje přehled případu použití a modelu pro automatizaci ETL. Vstupní data se transformují tak, aby vygenerovala příslušný výstup. Během této transformace se změní tvar dat, datový typ a dokonce jazyk. Procesy ETL můžou převést Imperial na metriku, změnit časová pásma a zlepšit přesnost, aby správně odpovídaly stávajícím datům v cíli. Procesy ETL mohou také kombinovat nová data s existujícími daty, aby byly sestavy aktuální, nebo poskytovat další přehled o existujících datech. Aplikace, jako jsou nástroje pro vytváření sestav a služby, pak mohou tato data využívat v požadovaném formátu.
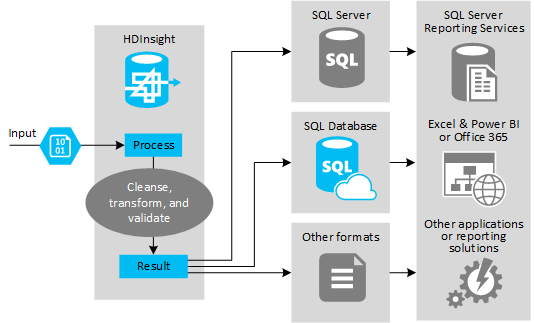
Hadoop se obvykle používá v procesech ETL, které importuje velký počet textových souborů (například sdílených svazků clusteru). Nebo menší, ale často se měnící počet textových souborů nebo obojí. Hive je skvělý nástroj, který slouží k přípravě dat před jejich načtením do cíle dat. Hive umožňuje vytvořit schéma přes sdílený svazek clusteru a pomocí jazyka podobného JAZYKu SQL generovat programy MapReduce, které pracují s daty.
Typický postup použití Hivu k etL je následující:
Načtěte data do Služby Azure Data Lake Storage nebo Azure Blob Storage.
Vytvořte databázi úložiště metadat (pomocí Azure SQL Database) pro použití Hivem při ukládání vašich schémat.
Vytvořte cluster HDInsight a připojte úložiště dat.
Definujte schéma, které se má použít při čtení dat v úložišti dat:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Transformujte data a načtěte je do cíle. Během transformace a načítání můžete Hive použít několika způsoby:
- Dotazujte a připravte data pomocí Hivu a uložte je jako sdílený svazek clusteru ve službě Azure Data Lake Storage nebo v úložišti objektů blob Azure. Pak pomocí nástroje, jako je SQL Server Integration Services (SSIS), získejte tyto sdílené svazky clusteru a načtěte data do cílové relační databáze, jako je SQL Server.
- Dotazujte se na data přímo z Excelu nebo jazyka C# pomocí ovladače Odbc Hive.
- Pomocí Apache Sqoopu můžete číst připravené ploché soubory CSV a načíst je do cílové relační databáze.
Zdroje dat
Zdroje dat jsou obvykle externí data, která se dají spárovat s existujícími daty v úložišti dat, například:
- Data sociálních médií, soubory protokolů, senzory a aplikace, které generují datové soubory.
- Datové sady získané od poskytovatelů dat, jako jsou statistiky počasí nebo prodejní čísla dodavatelů.
- Streamování dat zachycených, filtrovaných a zpracovaných prostřednictvím vhodného nástroje nebo architektury
Výstupní cíle
Hive můžete použít k výstupu dat do různých druhů cílů, mezi které patří:
- Relační databáze, jako je SQL Server nebo Azure SQL Database.
- Datový sklad, jako je Azure Synapse Analytics.
- Excel.
- Azure Table a Blob Storage.
- Aplikace nebo služby, které vyžadují zpracování dat do konkrétních formátů, nebo jako soubory, které obsahují konkrétní typy informační struktury.
- Úložiště dokumentů JSON, jako je Azure Cosmos DB.
Důležité informace
Model ETL se obvykle používá v následujících případech:
* Načtěte data streamu nebo velké objemy částečně strukturovaných nebo nestrukturovaných dat z externích zdrojů do existující databáze nebo informačního systému.
* Před načtením data vyčistíte, transformujte a ověříte, například pomocí více než jedné transformace procházející clusterem.
* Generujte sestavy a vizualizace, které se pravidelně aktualizují. Pokud například generování sestavy trvá příliš dlouho, můžete naplánovat spuštění sestavy v noci. K automatickému spuštění dotazu Hive můžete použít Azure Logic Apps a PowerShell.
Pokud cíl dat není databáze, můžete vygenerovat soubor v příslušném formátu v dotazu, například csv. Tento soubor pak můžete importovat do Excelu nebo Power BI.
Pokud potřebujete v rámci procesu ETL provést několik operací s daty, zvažte, jak je spravujete. Při operacích řízených externím programem, nikoli jako pracovním postupem v rámci řešení, se rozhodněte, jestli se některé operace dají spustit paralelně. A zjistit, kdy se každá úloha dokončí. Použití mechanismu pracovního postupu, jako je Oozie v rámci Systému Hadoop, může být jednodušší než pokus o orchestraci posloupnosti operací pomocí externích skriptů nebo vlastních programů.