Spouštění dotazů Apache Hivu pomocí Nástrojů Data Lake pro Visual Studio
Naučte se používat nástroje Data Lake pro Visual Studio k dotazování Apache Hivu. Nástroje Data Lake umožňují snadno vytvářet, odesílat a monitorovat dotazy Hive do Apache Hadoopu ve službě Azure HDInsight.
Požadavky
Cluster Apache Hadoop ve službě HDInsight. Informace o vytvoření této položky naleznete v tématu Vytvoření clusteru Apache Hadoop v Azure HDInsight pomocí šablony Resource Manageru.
Visual Studio. Kroky v tomto článku používají Visual Studio 2019.
Nástroje HDInsight pro Visual Studio nebo nástroje Azure Data Lake pro Visual Studio Informace o instalaci a konfiguraci nástrojů najdete v tématu Instalace nástrojů Data Lake pro Visual Studio.
Spouštění dotazů Apache Hive pomocí sady Visual Studio
Vytvářet a spouštět dotazy Hive můžete dvěma způsoby:
- Vytváření ad hoc dotazů
- Vytvořte aplikaci Hive.
Vytvoření ad hoc dotazu Hive
Ad hoc dotazy je možné spouštět v dávkovém nebo interaktivním režimu.
Spusťte Visual Studio a vyberte Pokračovat bez kódu.
V Průzkumníku serveru klikněte pravým tlačítkem na Azure, vyberte Připojit k předplatnému Microsoft Azure... a dokončete proces přihlášení.
Rozbalte HDInsight, klikněte pravým tlačítkem na cluster, ve kterém chcete dotaz spustit, a pak vyberte Napsat dotaz Hive.
Zadejte následující dotaz Hive:
SELECT * FROM hivesampletable;Vyberte Provést. Režim spuštění je ve výchozím nastavení interaktivní.
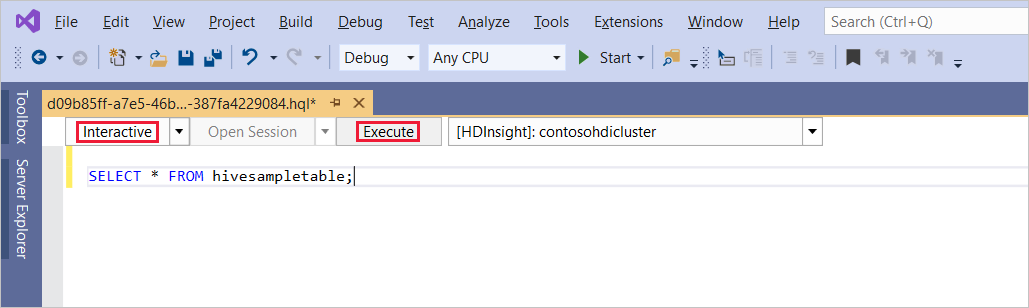
Pokud chcete spustit stejný dotaz v režimu Batch , přepněte rozevírací seznam z Interactive na Batch. Tlačítko spuštění se změní z příkazu Provést na odeslat.

Editor Hive podporuje technologii IntelliSense. Nástroje Data Lake pro Visual Studio podporují načítání vzdálených metadat při úpravách skriptu Hive. Pokud například zadáte
SELECT * FROM, IntelliSense zobrazí seznam všech navrhovaných názvů tabulek. Pokud zadáte název tabulky, IntelliSense vypíše názvy sloupců. Nástroje podporují většinu příkazů DML Hive, poddotazů a integrovaných UDF. IntelliSense navrhuje pouze metadata clusteru vybraného na panelu nástrojů služby HDInsight.Na panelu nástrojů dotazu (oblast pod kartou dotazu a nad textem dotazu) vyberte Odeslat nebo vyberte šipku rozevíracího seznamu vedle možnosti Odeslat a v seznamu pro stažení zvolte Upřesnit. Pokud vyberete druhou možnost,
Pokud jste vybrali možnost rozšířeného odeslání, nakonfigurujte název úlohy, argumenty, další konfigurace a adresář stavu v dialogovém okně Odeslat skript. Pak vyberte Odeslat.
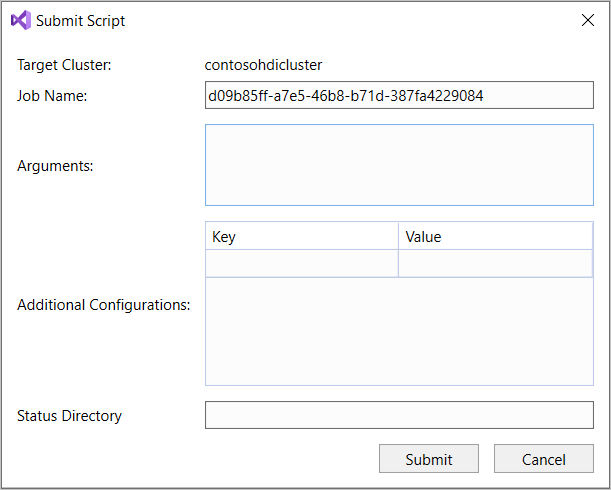
Vytvoření aplikace Hive
Pokud chcete spustit dotaz Hive vytvořením aplikace Hive, postupujte takto:
Otevřete Visual Studio.
V okně Start vyberte Vytvořit nový projekt.
V okně Vytvořit nový projekt zadejte do pole Hledat šablony Hive. Pak zvolte Aplikaci Hive a vyberte Další.
V okně Konfigurovat nový projekt zadejte název projektu, vyberte nebo vytvořte umístění pro nový projekt a pak vyberte Vytvořit.
Otevřete soubor Script.hql vytvořený pomocí tohoto projektu a vložte následující příkazy HiveQL:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Tyto příkazy provádějí následující akce:
DROP TABLE: Odstraní tabulku, pokud existuje.CREATE EXTERNAL TABLE: Vytvoří novou externí tabulku v Hive. Externí tabulky ukládají pouze definici tabulky v Hive. (Data zůstanou v původním umístění.)Poznámka:
Externí tabulky by se měly použít, když očekáváte, že se podkladová data aktualizují externím zdrojem, jako je úloha MapReduce nebo služba Azure.
Vyřazení externí tabulky neodstraní data, pouze definici tabulky.
ROW FORMAT: Řekne Hivu, jak se data formátují. V tomto případě jsou pole v každém protokolu oddělena mezerou.STORED AS TEXTFILE LOCATION: Říká Hivu, že data jsou uložená v příkladu nebo adresáři dat a že jsou uložená jako text.SELECT: Vybere počet všech řádků, ve kterých sloupect4obsahuje hodnotu[ERROR]. Tento příkaz vrátí hodnotu3, protože tři řádky obsahují tuto hodnotu.INPUT__FILE__NAME LIKE '%.log': Říká Hivu, aby vracela jenom data ze souborů končících na .log. Tato klauzule omezuje vyhledávání na soubor sample.log , který obsahuje data.
Na panelu nástrojů souboru dotazu (který se podobá panelu nástrojů ad hoc dotazu) vyberte cluster HDInsight, který chcete pro tento dotaz použít. Pak změňte Interaktivní na Batch (v případě potřeby) a výběrem příkazu Odeslat spusťte příkazy jako úlohu Hive.
Zobrazí se souhrn úlohy Hive a zobrazí informace o spuštěné úloze. Pomocí odkazu Aktualizovat aktualizujte informace o úloze, dokud se stav úlohy nezmění na Dokončeno.
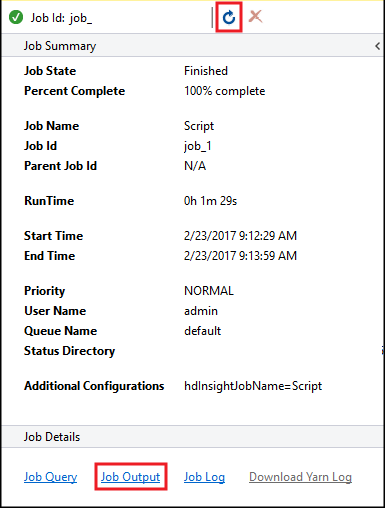
Výběrem výstupu úlohy zobrazíte výstup této úlohy. Zobrazí
[ERROR] 3hodnotu vrácenou tímto dotazem.
Další příklad
Následující příklad spoléhá na log4jLogs tabulku vytvořenou v předchozím postupu , Vytvoření aplikace Hive.
V Průzkumníku serveru klikněte pravým tlačítkem na cluster a vyberte Napsat dotaz Hive.
Zadejte následující dotaz Hive:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Tyto příkazy provádějí následující akce:
CREATE TABLE IF NOT EXISTS: Vytvoří tabulku, pokud ještě neexistuje.EXTERNALProtože se klíčové slovo nepoužívá, vytvoří tento příkaz interní tabulku. Interní tabulky se ukládají do datového skladu Hive a spravuje je Hive.Poznámka:
Na rozdíl od
EXTERNALtabulek odstraní interní tabulka také podkladová data.STORED AS ORC: Ukládá data ve sloupcovém formátu optimalizovaného řádku (ORC). ORC je vysoce optimalizovaný a efektivní formát pro ukládání dat Hive.INSERT OVERWRITE ... SELECT: Vybere řádky zlog4jLogstabulky, která obsahuje[ERROR], a pak vloží data doerrorLogstabulky.
V případě potřeby změňte Interaktivní na Batch a pak vyberte Odeslat.
Pokud chcete ověřit, že úloha vytvořila tabulku, přejděte do Průzkumníka serveru a rozbalte Azure>HDInsight. Rozbalte cluster HDInsight a pak rozbalte výchozí databázi Hive>. Tabulka errorLogs a tabulka Log4jLogs jsou uvedené.
Další kroky
Jak vidíte, nástroje HDInsight pro Visual Studio poskytují snadný způsob, jak pracovat s dotazy Hive ve službě HDInsight.
Obecné informace o Hivu ve službě HDInsight najdete v tématu Co je Apache Hive a HiveQL ve službě Azure HDInsight?
Informace o dalších způsobech práce s Hadoopem ve službě HDInsight najdete v tématu Použití MapReduce v Apache Hadoopu ve službě HDInsight.
Další informace o nástrojích HDInsight pro Visual Studio najdete v tématu Použití nástrojů Data Lake pro Visual Studio pro připojení ke službě Azure HDInsight a spuštění dotazů Apache Hive.