Použití Delta Lake ve službě Azure HDInsight v AKS s clusterem Apache Spark™ (Preview)
Poznámka:
Azure HDInsight vyřadíme ze služby AKS 31. ledna 2025. Před 31. lednem 2025 budete muset migrovat úlohy do Microsoft Fabric nebo ekvivalentního produktu Azure, abyste se vyhnuli náhlému ukončení úloh. Zbývající clustery ve vašem předplatném se zastaví a odeberou z hostitele.
Do data vyřazení bude k dispozici pouze základní podpora.
Důležité
Tato funkce je aktuálně dostupná jako ukázková verze. Doplňkové podmínky použití pro Microsoft Azure Preview obsahují další právní podmínky, které se vztahují na funkce Azure, které jsou v beta verzi, ve verzi Preview nebo ještě nejsou vydány v obecné dostupnosti. Informace o této konkrétní verzi Preview najdete v tématu Azure HDInsight o službě AKS ve verzi Preview. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás o dalších aktualizacích v komunitě Azure HDInsight.
Azure HDInsight v AKS je spravovaná cloudová služba pro analýzy velkých objemů dat, která organizacím pomáhá zpracovávat velké objemy dat. V tomto kurzu se dozvíte, jak používat Delta Lake v Azure HDInsight v AKS s clusterem Apache Spark™.
Požadavek
Vytvoření clusteru Apache Spark™ ve službě Azure HDInsight v AKS
Spusťte scénář Delta Lake v Poznámkovém bloku Jupyter. Vytvořte poznámkový blok Jupyter a při vytváření poznámkového bloku vyberte Spark, protože následující příklad je v jazyce Scala.


Scénář
- Formát NYC Taxi Parquet Data - Seznam adres URL souborů Parquet jsou k dispozici od NYC Taxi & Limousine Komise.
- Pro každou adresu URL (soubor) proveďte určitou transformaci a uložení ve formátu Delta.
- Vypočítá průměrnou vzdálenost, průměrné náklady na míle a průměrné náklady z tabulky Delta pomocí přírůstkového zatížení.
- Uložte vypočítanou hodnotu z kroku 3 ve formátu Delta do výstupní složky klíčového ukazatele výkonu.
- Vytvoření tabulky Delta ve výstupní složce Delta Format (automatická aktualizace)
- Výstupní složka klíčového ukazatele výkonu má více verzí průměrné vzdálenosti a průměrné náklady na míli jízdy.
Poskytnutí vyžaduje konfigurace pro delta lake.
Delta Lake s maticí kompatibility Apache Sparku – Delta Lake, změna verze Delta Lake na základě verze Apache Sparku
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Výpis datového souboru
Poznámka:
Tyto adresy URL souborů pocházejí z NYC Taxi & Limousine Commission.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Vytvoření výstupního adresáře
Umístění, kam chcete vytvořit rozdílový formát výstupu, v případě potřeby změňte transformDeltaOutputPath hodnotu a avgDeltaOutputKPIPath proměnnou.
avgDeltaOutputKPIPath– uložení průměrného klíčového ukazatele výkonu v rozdílového formátutransformDeltaOutputPath– uložení transformovaného výstupu ve formátu delta
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Vytvoření rozdílového formátu dat z formátu Parquet
Vstupní data jsou z místa, odkud
listOfDataFilese data stahují https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.pagePokud chcete předvést časové cestování a verzi, načtěte data jednotlivě.
Proveďte transformaci a výpočetní výkon při přírůstkové zátěži s následujícím obchodním klíčovým ukazatelem výkonu:
- Průměrná vzdálenost
- Průměrné náklady na míle
- Průměrné náklady
Uložení transformovaných dat a klíčových ukazatelů výkonu ve formátu delta
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Čtení rozdílového formátu pomocí tabulky Delta
- čtení transformovaných dat
- čtení dat klíčového ukazatele výkonu
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Schéma tisku
- Vytiskněte schéma tabulky Delta pro transformovaná a průměrná data klíčových ukazatelů výkonu1.
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema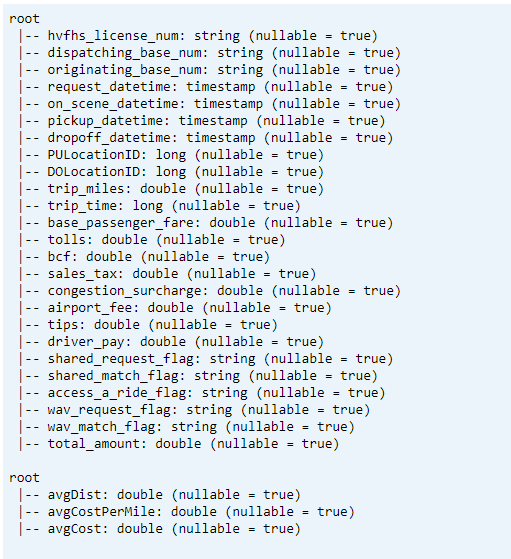
Zobrazení posledního vypočítaného klíčového ukazatele výkonu z tabulky dat
dtAvgKpi.toDF.show(false)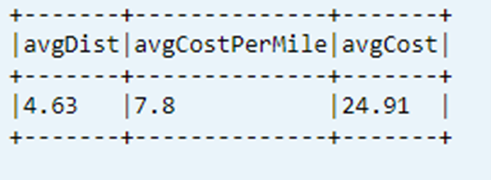


Zobrazení historie vypočítaných klíčových ukazatelů výkonu
Tento krok zobrazuje historii tabulky transakcí klíčových ukazatelů výkonu z _delta_log
dtAvgKpi.history().show(false)

Zobrazení dat klíčového ukazatele výkonu po každém načtení dat
- Pomocí časového cestování můžete zobrazit změny klíčových ukazatelů výkonu po každém načtení.
- Všechny změny verze můžete uložit ve formátu
avgMoMKPIChangePathCSV tak, aby power BI tyto změny mohl číst.
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Reference
- Názvy open source projektů Apache, Apache Spark, Apache Spark a přidružené jsou ochranné známky služby Apache Software Foundation (ASF).