Automatické škálování SLUŽBY HDInsight v clusterech AKS
Důležitý
Azure HDInsight v AKS byl vyřazen 31. ledna 2025. Více informací v tomto oznámení .
Abyste se vyhnuli náhlému ukončení úloh, musíte migrovat úlohy do Microsoft Fabric nebo ekvivalentního produktu Azure.
Důležitý
Tato funkce je aktuálně ve verzi Preview. doplňkové podmínky použití pro preview verze Microsoft Azure obsahují další právní podmínky, které se vztahují na funkce Azure v beta verzi, preview nebo které ještě nejsou dostupné pro veřejné použití. Informace o tomto konkrétním náhledu najdete v tématu Azure HDInsight ve službě AKS. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a pro další aktualizace nás sledujte na komunitě Azure HDInsight.
Určení velikosti libovolného clusteru tak, aby splňovalo výkon úloh a spravuje náklady předem, je vždy složité a těžko určit! Jednou z lukrativních výhod vytváření datového jezera přes Cloud je jeho elasticita, což znamená použití funkce automatického škálování k maximalizaci využití prostředků v ruce. Automatické škálování pomocí Kubernetes je jedním z klíčových klíčů k vytvoření ekosystému optimalizovaného pro náklady. S různými vzory využití v libovolném podniku se můžou v průběhu času měnit zatížení clusteru, což by mohlo vést k tomu, že clustery jsou nedostatečně zřízené (špatný výkon) nebo nadměrně zřízené (zbytečné náklady způsobené nečinnými prostředky).
Funkce automatického škálování nabízená ve službě HDInsight v AKS může automaticky zvýšit nebo snížit počet pracovních uzlů ve vašem clusteru. Automatické škálování používá metriky clusteru a zásady škálování používané zákazníky.
Tato funkce je vhodná pro klíčové úlohy, které můžou mít
- Proměnlivé nebo nepředvídatelné vzorce provozu, které vyžadují SLA s vysokým výkonem a schopností škálovat, nebo
- Předem určený plán, aby byly požadované pracovní uzly k dispozici pro úspěšné spuštění úloh v clusteru.
Automatické škálování s HDInsight na clusterech AKS zajišťuje, že clustery jsou nákladově efektivní a elastické na Azure.
Díky automatickému škálování můžou zákazníci vertikálně snížit kapacitu clusterů, aniž by to mělo vliv na úlohy. Je vybavena pokročilými funkcemi, jako je řádné vyřazení z provozu a čas potřebný na chlazení. Tyto funkce umožňují uživatelům provádět informované volby o přidávání a odebírání uzlů na základě aktuálního zatížení clusteru.
Jak to funguje
Tato funkce funguje škálováním počtu uzlů v rámci přednastavených limitů na základě metrik clusteru nebo definovaného plánu operací vertikálního navýšení a snížení kapacity. Existují dva typy podmínek pro aktivaci událostí automatického škálování: triggery založené na prahových hodnotách pro různé metriky výkonu clusteru (označované jako škálování založené na zatížení) a triggery založené na čase (označované jako škálování založené na plánu).
Škálování na základě zatížení změní počet uzlů v clusteru v rozsahu, který nastavíte, aby se zajistilo optimální využití procesoru a minimalizovalo provozní náklady.
Škálování na základě plánu mění počet uzlů v clusteru podle plánu operací pro zvětšení a zmenšení kapacity.
Poznámka
Automatické škálování nepodporuje změnu typu skladové položky existujícího clusteru.
Kompatibilita clusteru
Následující tabulka popisuje typy clusterů, které jsou kompatibilní s funkcí automatického škálování a co je dostupné nebo plánované.
| Pracovní zátěž | Na základě zatížení | Na základě harmonogramu |
|---|---|---|
| Flink | Plánovaný | Ano |
| Trino | Ano** | Ano** |
| Jiskra | Ano** | Ano** |
**Řádné vyřazení z provozu je možné konfigurovat.
Metody škálování
škálování na základě plánu:
Pokud se očekává, že se vaše úlohy budou spouštět podle pevných plánů a s předvídatelnou délkou trvání nebo pokud očekáváte nízké využití v určitých časech dne, například testovací a vývojová prostředí po pracovní době, úlohy na konci dne.
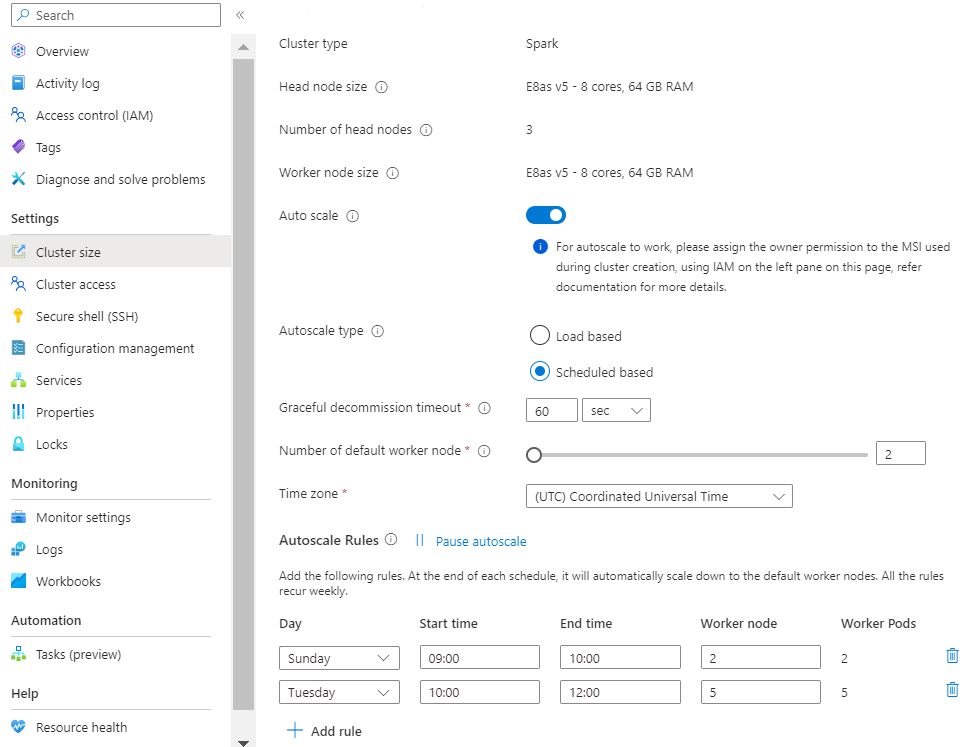
škálování na základě zatížení:
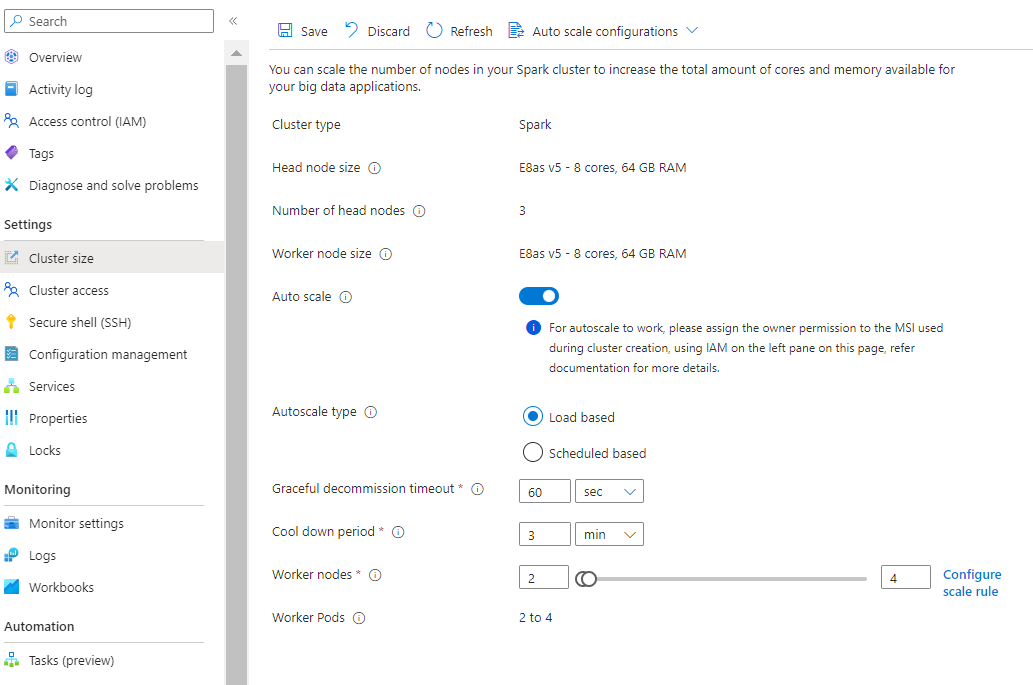
Pokud vzorce zatížení během dne výrazně a nepředvídatelně kolísají, například zpracování dat objednávek s náhodnými výkyvy zatížení na základě různých faktorů.
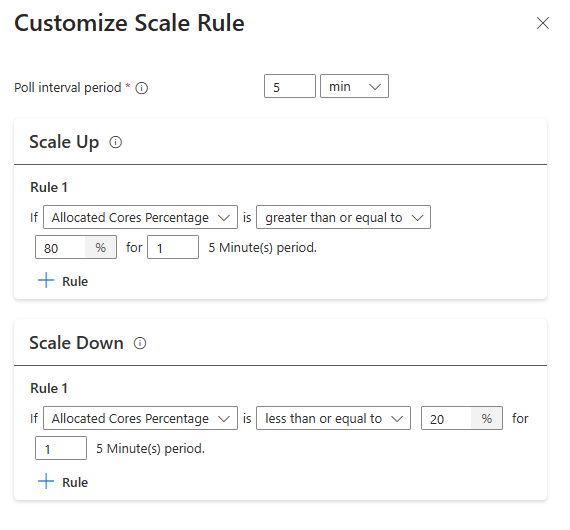
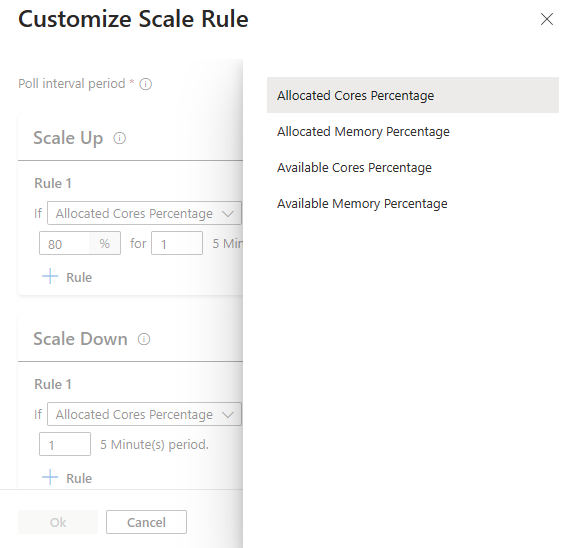
S novou možností konfigurace pravidla škálování můžete nyní přizpůsobit pravidla škálování.
Spropitné
- Pravidla vertikálního škálování mají přednost, když jsou spuštěna jedno nebo více pravidel. I když jen jedno z pravidel pro škálování nahoru naznačuje, že cluster má nedostatečné zdroje, cluster se pokusí škálovat nahoru. Aby bylo možné snížit kapacitu, nesmí se aktivovat žádné pravidlo pro navýšení kapacity.


Podmínky škálování na základě zatížení
Když se zjistí následující podmínky, Auto Scale vytvoří žádost o škálování.
| Vertikální navýšení kapacity | Snížení kapacity |
|---|---|
| Přidělená jádra přesahují 80% během 5minutového intervalu dotazování s kontrolním obdobím 1 minuty. | Přidělená jádra jsou menší nebo rovna 20% ve 5minutovém intervalu dotazování (1minutová kontrolní doba). |
Pro škálování vydá automatické škálování žádost o navýšení počtu uzlů podle potřeby. Vertikální navýšení kapacity vychází z toho, kolik nových pracovních uzlů je potřeba ke splnění aktuálních požadavků na procesor a paměť. Tato hodnota je omezena na maximální počet pracovních uzlů nastavených.
V případě vertikálního snížení kapacity vydá automatické škálování žádost o odebrání některých uzlů. Aspekty snížení kapacity zahrnují počet podů na uzel, aktuální požadavky na procesor a paměť a pracovní uzly, které jsou kandidáty na odebrání na základě aktuálního průběhu úloh. Operace vertikálního snížení kapacity nejprve vyřadí uzly z provozu a pak je odebere z clusteru.
Důležitý
Modul pravidel automatického škálování proaktivně vyprázdní staré události každých 30 minut za účelem optimalizace systémové paměti. V důsledku toho existuje horní mez 30 minut v intervalu pravidla škálování. Aby se zajistilo konzistentní a spolehlivé spouštění akcí škálování, je nezbytné nastavit interval pravidla škálování na hodnotu, která je nižší než limit. Dodržováním tohoto návodu můžete zaručit hladký a efektivní proces škálování při efektivní správě systémových prostředků.
Metriky clusteru
Automatické škálování nepřetržitě monitoruje cluster a shromažďuje následující metriky pro automatické škálování na základě zatížení:
Metriky clusteru dostupné pro účely škálování
| Metrický | Popis |
|---|---|
| Procento dostupných jader | Celkový počet jader dostupných v clusteru v porovnání s celkovým počtem jader v clusteru. |
| Dostupné procento paměti | Celková paměť (v MB) dostupná v clusteru ve srovnání s celkovým množstvím paměti v clusteru. |
| Procento přidělených jader | Celkový počet jader přidělených v clusteru v porovnání s celkovým počtem jader v clusteru. |
| Přidělené procento paměti | Množství paměti přidělené v clusteru v porovnání s celkovým množstvím paměti v clusteru. |
Ve výchozím nastavení se výše uvedené metriky kontrolují každých 300 sekund, je také možné nakonfigurovat při přizpůsobení intervalu dotazování s možností přizpůsobení automatického škálování. Automatické škálování provádí rozhodnutí o škálování nahoru nebo dolů na základě těchto metrik.
Poznámka
Ve výchozím nastavení automatické škálování používá výchozí kalkulačku prostředků pro YARN pro Apache Spark. Škálování na základě zatížení je k dispozici pro clustery Apache Spark.
Přívětivé vyřazení z provozu
Podniky potřebují způsoby, jak dosáhnout petabajtového škálování s automatickým škálováním a řádně vyřadit prostředky z provozu, když už nejsou potřeba. V takovém scénáři je užitečné funkce elegantního vyřazení z provozu.
Postupné vyřazování z provozu umožňuje dokončení úloh i poté, co automatické škálování spustilo vyřazení pracovních uzlů. Tato funkce umožňuje pokračovat ve zřizování uzlů, dokud nebudou úlohy dokončeny.
Trino: Ve výchozím nastavení mají pracovníci povolené řádné vyřazení z provozu. Koordinátor povoluje pracovníku dokončit své úkoly po nastavenou dobu před odebráním pracovníka z clusteru. Časový limit můžete nakonfigurovat buď pomocí nativního parametru Trino
shutdown.grace-period, nebo na stránce konfigurace služby webu Azure Portal.Apache Spark: Zmenšení kapacity může ovlivnit nebo zastavit jakékoli běžící úlohy v clusteru. Pokud na Azure Portalu povolíte nastavení pro řádné vyřazení z provozu, zahrnuje to řádné vyřazení uzlů YARN a zajistí, že se veškerá probíhající práce na pracovním uzlu dokončí před tím, než je uzel odstraněn ze služby HDInsight v clusteru AKS.
Období chladnutí
Aby se zabránilo průběžným operacím vertikálního navýšení kapacity, modul automatického škálování před zahájením jiné sady operací vertikálního navýšení kapacity počká na konfigurovatelný interval. Výchozí hodnota je nastavená na 180 sekund
Poznámka
- Ve vlastních pravidlech škálování nemůže mít žádná spouštěcí událost interval delší než 30 minut. Jakmile dojde k události automatického škálování, doba čekání před vynucením jiné zásady škálování.
- Období ochlazení by mělo být větší než interval politiky, aby se metriky clusteru mohly být resetovány.
Začněte
Aby automatické škálování fungovalo, musíte přiřadit vlastníka nebo přispěvateli oprávnění MSI (používané při vytváření clusteru) na úrovni clusteru pomocí IAM v levém podokně.
Podívejte se na následující ilustraci a kroky, jak přidat přiřazení role.
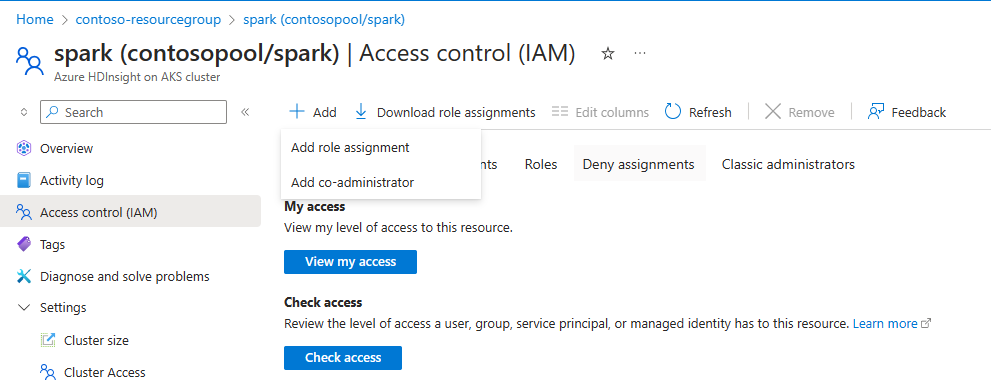
Vyberte a přidejte přiřazení role,
- Typ přiřazení: Role privilegovaného správce
- Role: vlastník nebo přispěvatel
- Členové: Vyberte Svěřenou identitu a zvolte uživatelsky přiřazenou svěřenou identitu, která byla přidělena během fáze vytváření clusteru.
- Přiřaďte roli.

Vytvoření clusteru s automatickým škálováním na základě plánu
Po vytvoření fondu clusterů vytvořte nový cluster s požadovanou úlohou (na typu clusteru) a proveďte další kroky v rámci normálního procesu vytváření clusteru.
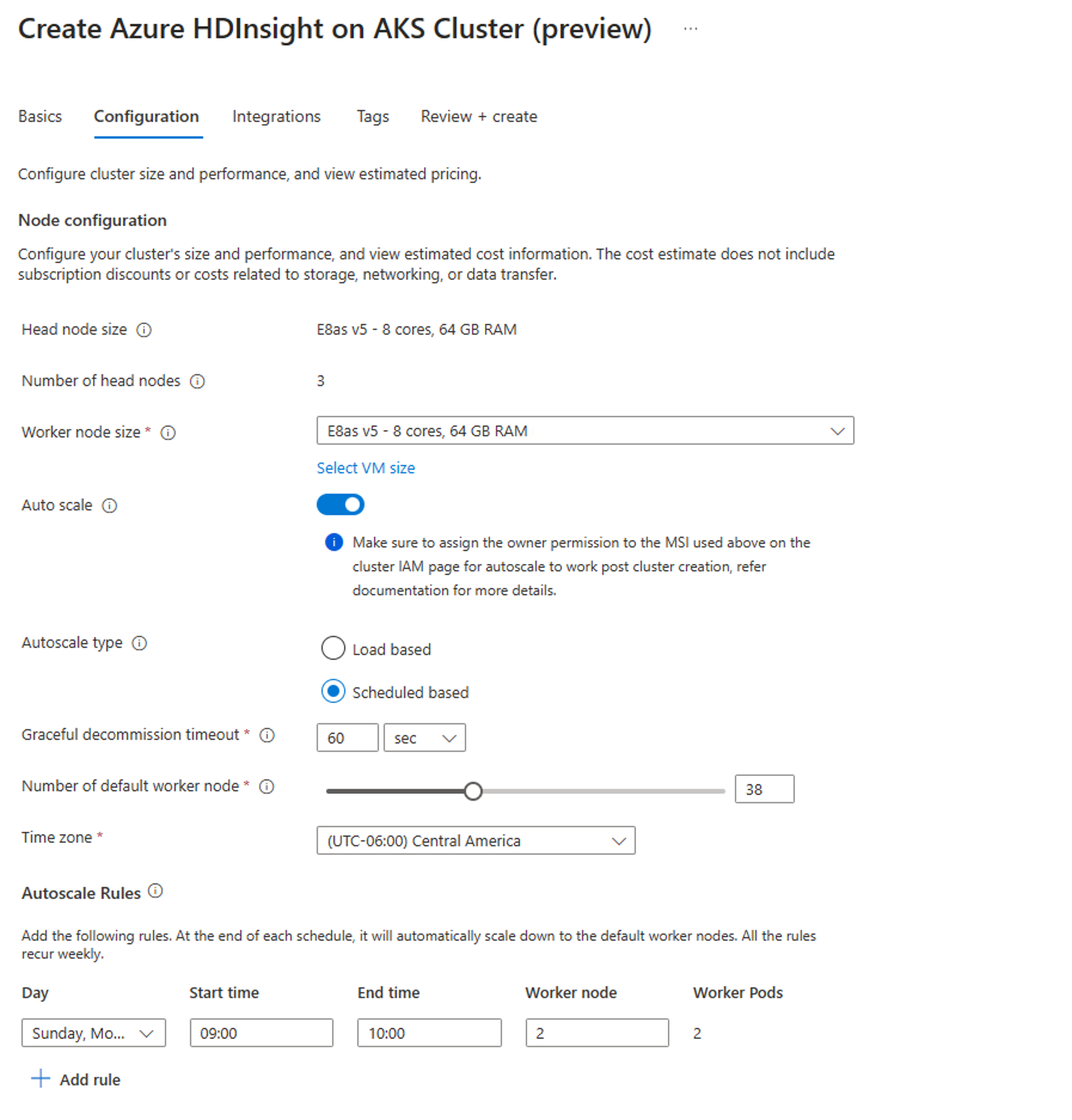
Na kartě Konfigurace povolte přepínač automatického škálování.
Vyberte automatické škálování na základě plánu
Vyberte časové pásmo a potom klikněte na + Přidat pravidlo
Vyberte dny v týdnu, na které má nová podmínka platit.
Upravte čas, kdy se má podmínka projevit, a počet uzlů, na které se má cluster škálovat.
Poznámka
- Aby automatické škálování fungovalo, měl by mít uživatel v MSI clusteru roli vlastníka nebo přispěvatele.
- Výchozí hodnota definuje počáteční velikost clusteru při jeho vytvoření.
- Rozdíl mezi dvěma plány je ve výchozím nastavení nastavený na 30 minut.
- Hodnota času se řídí 24hodinovým formátem.
- V případě průběžného intervalu delšího než 24 hodin v rámci dnů musíte nastavit plán automatického škálování napříč dny a automatické škálování předpokládá, že 23:59 je 00:00 (se stejným počtem uzlů) přesahující dva dny od 22:00 do 23:59, 00:00 až 02:00 jako 22:00 až 02:00.
- Plány jsou ve výchozím nastavení nastavené ve standardu UTC (Coordinated Universal Time). V rozevíracím seznamu můžete vždy aktualizovat časové pásmo, které odpovídá místnímu časovému pásmu. Pokud jste v časovém pásmu, které sleduje letní úspory, plán se automaticky neupraví, budete muset odpovídajícím způsobem spravovat aktualizace plánu.

Vytvoření clusteru s automatickým škálováním na základě zatížení
Po vytvoření fondu clusterů vytvořte nový cluster s požadovanou úlohou (na typu clusteru) a proveďte další kroky v rámci normálního procesu vytváření clusteru.
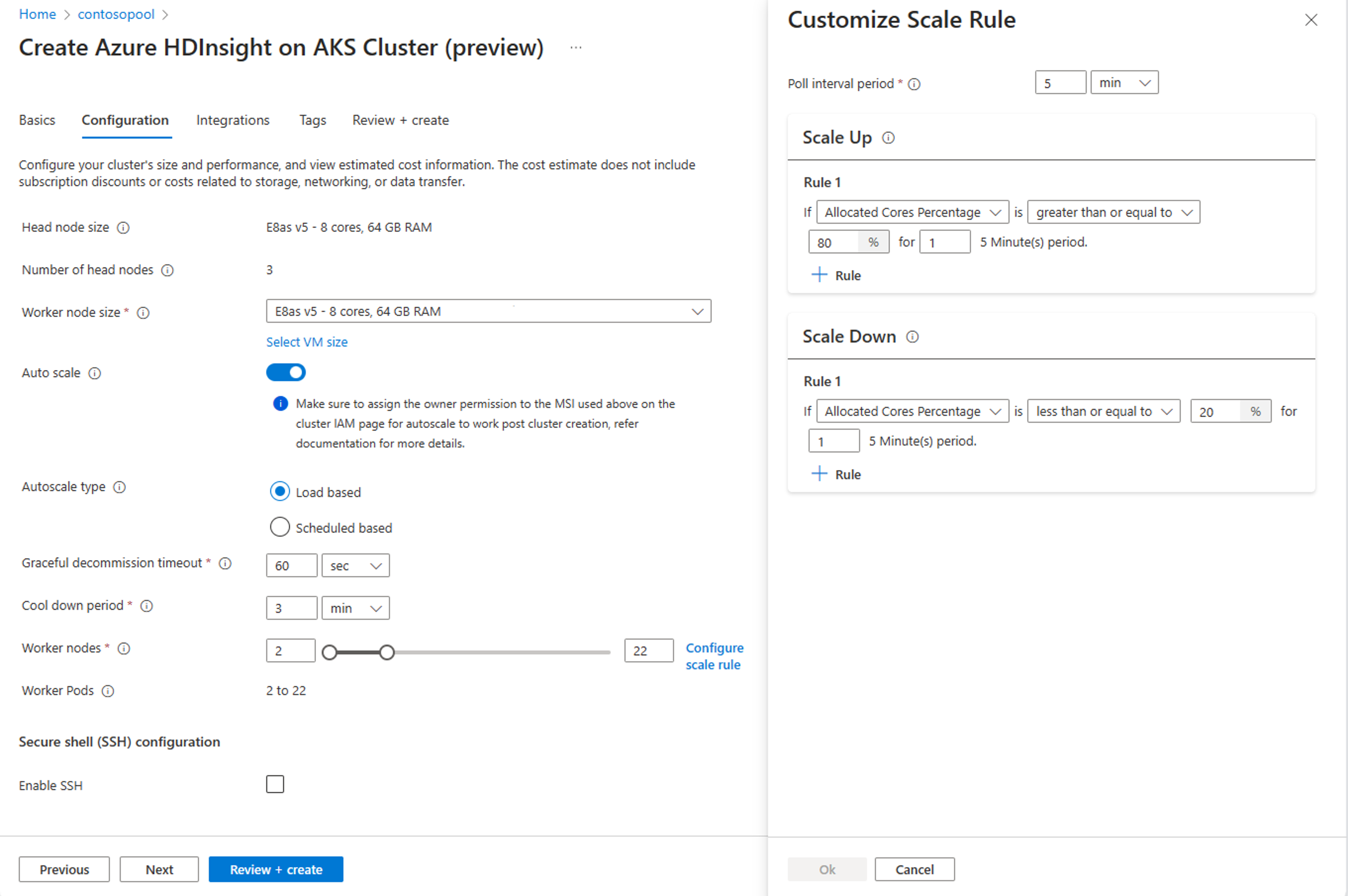
Na kartě Konfigurace povolte přepínač automatického škálování.
Výběr automatického škálování na základě zatížení
Na základě typu úlohy máte možnosti přidat pohodlné vyřazení z provozu s časovým limitem, období ochlazení
Vyberte minimální a maximální počet uzlů a v případě potřeby nakonfigurovat pravidla škálování, přizpůsobit automatické škálování vašim potřebám.
Spropitné
- Vaše předplatné má kvótu kapacity pro každou oblast. Celkový počet jader hlavních uzlů a maximální počet pracovních uzlů nesmí překročit kvótu kapacity. Tato kvóta je však měkkým limitem; Kdykoli můžete vytvořit lístek podpory, abyste ho mohli snadno zvýšit.
- Pokud překročíte limit celkové kvóty jader, zobrazí se chybová zpráva s informací, že
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Pravidla pro škálování nahoru mají přednost, když jsou spuštěna jedno nebo více pravidel. I když jen jedno z pravidel vertikálního navýšení kapacity navrhuje, aby cluster byl nedostatečně zřízený, cluster se pokusí vertikálně navýšit kapacitu. Aby mohlo dojít ke snížení kapacity, nemělo by se aktivovat žádné pravidlo pro navýšení kapacity.
- Ve verzi Public Preview podporuje HDInsight v AKS až 500 uzlů v clusteru.

Vytvoření clusteru pomocí šablony Resource Manageru
automatické škálování na základě plánu
Službu HDInsight můžete vytvořit v clusteru AKS s automatickým škálováním na základě plánu pomocí šablony Azure Resource Manageru přidáním automatického škálování do souboru clusterProfile –> oddílu automatického škálováníProfile.
Uzel automatického škálování obsahuje opakování s časovým pásmem a plánem, který popisuje, kdy se změna provede. Kompletní šablonu Resource Manageru najdete v ukázce JSON.
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Spropitné
- Abyste se vyhnuli selháním operace škálování, musíte pomocí nasazení ARM nastavit nekonfliktní harmonogramy.
automatické škálování na základě zatížení
Službu HDInsight můžete vytvořit na clusteru AKS s automatickým škálováním na základě zatížení pomocí šablony Azure Resource Manageru tak, že přidáte automatické škálování do částí clusterProfile -> autoscaleProfile.
Uzel automatického škálování obsahuje
- časový interval pro dotazování, doba vychladnutí
- řádné vyřazení z provozu,
- minimální a maximální počet uzlů,
- standardní prahová pravidla,
- metriky škálování, které popisují, kdy se změna provede.
Kompletní šablonu Resource Manageru najdete v ukázkovém formátu JSON následujícím způsobem:
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
Použití rozhraní REST API
Pokud chcete povolit nebo zakázat automatické škálování ve spuštěném clusteru pomocí rozhraní REST API, vytvořte požadavek PATCH na koncový bod automatického škálování: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Použijte příslušné parametry v datové části požadavku. Datová část JSON se dá použít k povolení automatického škálování.
- Použijte položku (autoscaleProfile: null) nebo použijte příznak (povoleno, false) k zakázání automatického škálování.
- Referenční informace najdete v ukázkách JSON uvedených v předchozím kroku.
Pozastavení automatického škálování pro spuštěný cluster
Zavedli jsme funkci pozastavení v automatickém škálování. Teď můžete pomocí webu Azure Portal pozastavit automatické škálování na spuštěném clusteru. Následující diagram znázorňuje výběr pozastavení a obnovení automatického škálování.

Jakmile budete chtít obnovit operace automatického škálování, můžete pokračovat.

Spropitné
Když nakonfigurujete více plánů a pozastavíte automatické škálování, neaktivuje se další plán. Počet uzlů zůstane stejný, i když jsou uzly v vyřazeném stavu.
Kopírování konfigurací automatického škálování
Pomocí webu Azure Portal teď můžete zkopírovat stejné konfigurace automatického škálování pro stejný obrazec clusteru napříč fondem clusterů. Tuto funkci můžete použít a exportovat nebo importovat stejné konfigurace.

Monitorování aktivit automatického škálování
Stav clusteru
Stav clusteru uvedený na webu Azure Portal vám může pomoct monitorovat aktivity automatického škálování. Všechny stavové zprávy clusteru, které se můžou zobrazit, jsou vysvětlené v seznamu.
| Stav clusteru | Popis |
|---|---|
| Uspěl | Cluster funguje normálně. Všechny předchozí aktivity automatického škálování byly úspěšně dokončeny. |
| Přijato | Operace clusteru (například škálování nahoru) byla přijata, nyní se čeká na její dokončení. |
| Neúspěšný | To znamená, že aktuální operace selhala z nějakého důvodu, cluster možná není funkční. |
| Zrušený | Aktuální operace je zrušena. |
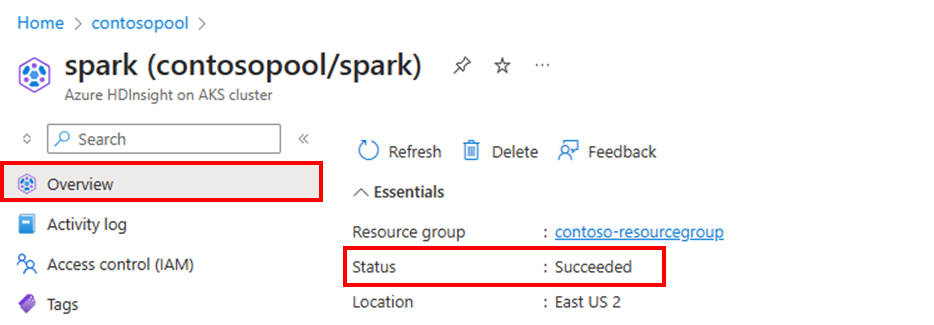
Pokud chcete zobrazit aktuální počet uzlů v clusteru, přejděte na graf Velikost clusteru na stránce Přehled clusteru.

Historie operací
Historii vertikálního navýšení a snížení kapacity clusteru můžete zobrazit jako součást metrik clusteru. Můžete také zobrazit seznam všech akcí škálování za poslední den, týden nebo jiné období.

další prostředky
ruční škálování – Azure HDInsight ve službě AKS