Řešení potíží s procesorem událostí Služby Azure Event Hubs
Tento článek obsahuje řešení běžných problémů, se kterými se můžete setkat při použití EventProcessorClient typu. Pokud hledáte řešení jiných běžných problémů, se kterými se můžete setkat při používání služby Azure Event Hubs, přečtěte si téma Řešení potíží se službou Azure Event Hubs.
412 selhání předběžných podmínek při použití procesoru událostí
K chybám předběžné podmínky dochází, když se klient pokusí převzít nebo obnovit vlastnictví oddílu, ale místní verze záznamu vlastnictví je zastaralá. K tomuto problému dochází, když jiná instance procesoru ukradne vlastnictví oddílu. Další informace naleznete v následující části.
Změny vlastnictví oddílů se často mění
Když se počet EventProcessorClient instancí změní (to znamená, že se přidají nebo odeberou), spuštěné instance se pokusí vyrovnávat zatížení oddílů mezi sebou. Po několika minutách po změně počtu procesorů se očekává, že se vlastníci změní. Po vyvážení by mělo být vlastnictví oddílů stabilní a často se měnit. Pokud se vlastnictví oddílů často mění, když je počet procesorů konstantní, pravděpodobně to značí problém. Doporučujeme, abyste s protokoly a opakováním zakládali problém na GitHubu.
Vlastnictví oddílu se určuje prostřednictvím záznamů vlastnictví v souboru CheckpointStore. V každém intervalu vyrovnávání zatížení provede následující EventProcessorClient úlohy:
- Načtěte nejnovější záznamy vlastnictví.
- Zkontrolujte záznamy a zjistěte, které záznamy neaktualizovaly časové razítko v intervalu vypršení platnosti vlastnictví oddílu. Zvažují se pouze záznamy odpovídající tomuto kritériu.
- Pokud existují nějaké nevlastněné oddíly a zatížení není vyváženo mezi instancemi
EventProcessorClient, klient procesoru událostí se pokusí deklarovat oddíl. - Aktualizujte záznam vlastnictví pro oddíly, které vlastní, které mají aktivní propojení s tímto oddílem.
Intervaly vypršení platnosti vyrovnávání zatížení a vlastnictví můžete nakonfigurovat při vytváření EventProcessorClient prostřednictvím EventProcessorClientBuildernástroje , jak je popsáno v následujícím seznamu:
- Metoda loadBalancingUpdateInterval(Duration) označuje, jak často cyklus vyrovnávání zatížení běží.
- Metoda partitionOwnershipExpirationInterval(Duration) označuje minimální dobu od aktualizace záznamu vlastnictví, než procesor považuje oddíl bez vlastníka.
Pokud se například záznam o vlastnictví aktualizoval v 9:30 a partitionOwnershipExpirationInterval 2 minuty. Když dojde k cyklu vyrovnávání zatížení a všimne si, že se záznam vlastnictví během posledních 2 minut nebo 9:32 neaktualizoval, považuje se za oddíl bez vlastnictví.
Pokud dojde k chybě v jednom z příjemců oddílů, zavře odpovídající příjemce, ale nebude se pokoušet ho uvolnit až do dalšího cyklu vyrovnávání zatížení.
"... aktuální přijímač '<RECEIVER_NAME>' s epochou '0' se odpojí"
Celá chybová zpráva vypadá podobně jako v následujícím výstupu:
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
Tato chyba se očekává, když dojde k vyrovnávání zatížení po EventProcessorClient přidání nebo odebrání instancí. Vyrovnávání zatížení je probíhající proces. Když použijete BlobCheckpointStore s příjemcem každých přibližně 30 sekund (ve výchozím nastavení), příjemce zkontroluje, kteří příjemci mají deklaraci identity pro každý oddíl, a pak spustí logiku, která určí, jestli potřebuje "ukrást" oddíl od jiného příjemce. Mechanismus služby používaný k uplatnění výhradního vlastnictví oddílu se označuje jako Epocha.
Pokud se ale nepřidají ani neodeberou žádné instance, měl by se vyřešit základní problém. Další informace najdete v oddílu Změny vlastnictví oddílu a problémy s vytvářením GitHubu.
Vysoké využití procesoru
Vysoké využití procesoru je obvykle způsobeno tím, že instance vlastní příliš mnoho oddílů. Pro každé jádro procesoru doporučujeme maximálně tři oddíly. Pro každé jádro procesoru je lepší začít s 1,5 oddíly a pak testovat zvýšením počtu vlastněných oddílů.
Nedostatek paměti a volba velikosti haldy
K problému s nedostatkem paměti (OOM) může dojít v případě, že aktuální maximální halda virtuálního počítače JVM není dostatečná ke spuštění aplikace. Možná budete chtít změřit požadavek haldy aplikace. Pak na základě výsledku velikost haldy nastavením odpovídající maximální paměti haldy pomocí -Xmx možnosti JVM.
Neměli byste zadávat -Xmx hodnotu větší než dostupná paměť nebo omezení nastavené pro hostitele (virtuální počítač nebo kontejner), například paměť požadovanou v konfiguraci kontejneru. Pro podporu haldy Java byste měli přidělit dostatek paměti pro hostitele.
Následující kroky popisují typický způsob měření hodnoty maximální haldy Java:
Spusťte aplikaci v prostředí v blízkosti produkčního prostředí, kde aplikace odesílá, přijímá a zpracovává události v produkčním prostředí v očekávaném zatížení ve špičce.
Počkejte, až aplikace dosáhne stabilního stavu. V této fázi by aplikace a JVM načetly všechny objekty domény, typy tříd, statické instance, fondy objektů (TCP, fondy připojení k databázi) atd.
Pod stabilním stavem uvidíte vzor stabilního pilového tvaru pro kolekci haldy, jak je znázorněno na následujícím snímku obrazovky:
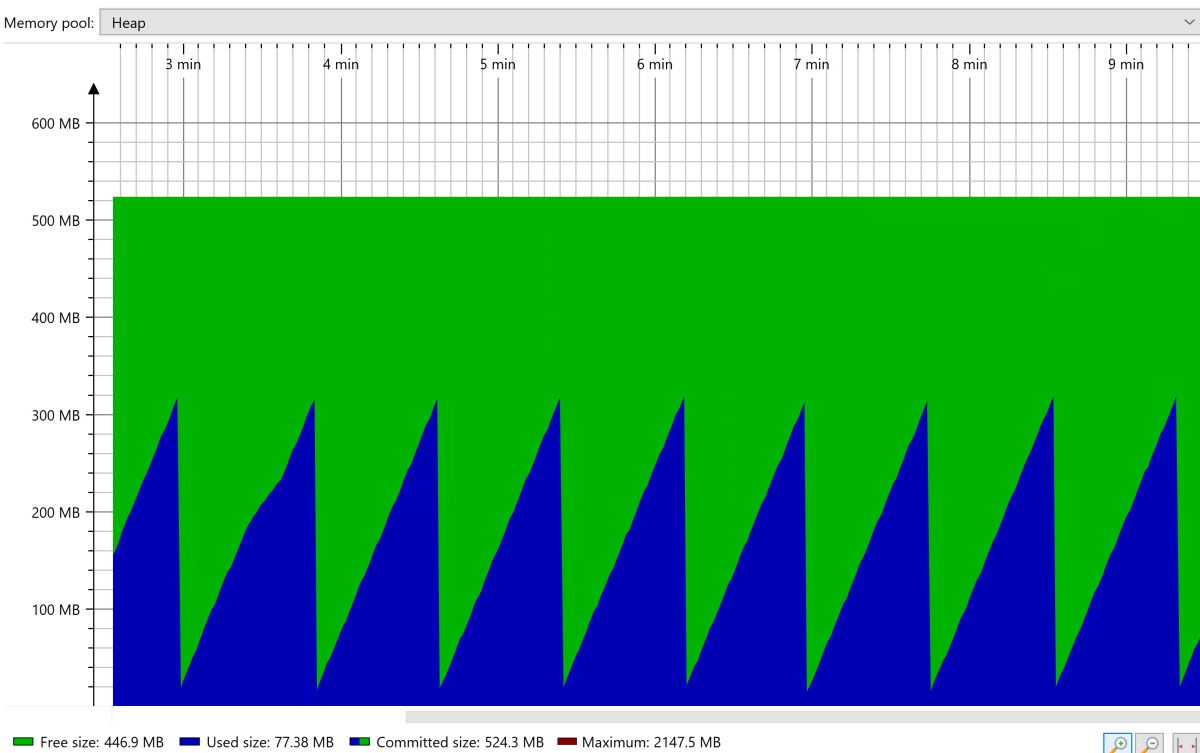
Jakmile aplikace dosáhne stabilního stavu, vynuťte úplné uvolňování paměti (GC) pomocí nástrojů, jako je JConsole. Sledujte zaplněnou paměť po úplném uvolňování paměti. Chcete zvětšit haldu tak, aby byla zaplněna pouze 30 % po úplném uvolňování paměti. Tuto hodnotu můžete použít k nastavení maximální velikosti haldy (pomocí
-Xmx).

Pokud jste v kontejneru, velikost kontejneru tak, aby měl extra ~1 GB paměti pro jinou instanci JVM.
Klient procesoru přestane přijímat
Klient procesoru často běží v hostitelské aplikaci po celé dny. Někdy si všimnete, že EventProcessorClient se nezpracová jeden nebo více oddílů. Obvykle není k dispozici dostatek informací, abyste zjistili, proč k výjimce došlo. Zastavení EventProcessorClient je příznakem základní příčiny (tj. stavu časování), ke které došlo při pokusu o zotavení z přechodné chyby. Informace, které požadujeme, najdete v tématu Problémy s vytvářením GitHubu.
Duplicitní data událostí přijatá při restartování procesoru
Služba EventProcessorClient Event Hubs zaručuje aspoň jedno doručení. Můžete přidat metadata pro rozlišení duplicitních událostí. Další informace najdete v tématu Zaručuje služba Azure Event Hubs alespoň jedno doručení? ve službě Stack Overflow. Pokud vyžadujete pouze jedno doručení, měli byste zvážit službu Service Bus, která čeká na potvrzení od klienta. Porovnání služeb zasílání zpráv najdete v tématu Volba mezi službami zasílání zpráv Azure.
Migrace ze starší verze do nové klientské knihovny
Průvodce migrací zahrnuje kroky migrace ze starší verze klienta a migraci starších kontrolních bodů.
Další kroky
Pokud pokyny k řešení potíží v tomto článku nepomáhají vyřešit problémy při použití sady Azure SDK pro klientské knihovny Java, doporučujeme vám založit problém v úložišti Azure SDK pro Javu na GitHubu.