Rozšíření rozsáhlého jazykového modelu o generování rozšířené načítání a vyladění
Články v této sérii popisují modely načítání znalostí, které LLM používají k vygenerování odpovědí. Ve výchozím nastavení má rozsáhlý jazykový model (LLM) přístup pouze k trénovacím datům. Model ale můžete rozšířit tak, aby zahrnoval data v reálném čase nebo soukromá data. Tento článek popisuje jeden ze dvou mechanismů pro rozšíření modelu.
Prvním mechanismem je načítání rozšířené generace (RAG), což je forma předběžného zpracování, která kombinuje sémantické vyhledávání s kontextovým primací (probírané v jiném článku).
Druhý mechanismus je vyladění, který odkazuje na proces dalšího trénování modelu na konkrétní datovou sadu po počátečním širokém trénování, s cílem přizpůsobit ho tak, aby lépe fungoval s úlohami nebo porozumět konceptům souvisejícím s danou datovou sadou. Tento proces pomáhá modelu specializovat nebo zlepšit jeho přesnost a efektivitu při zpracování konkrétních typů vstupů nebo domén.
Následující části popisují tyto dva mechanismy podrobněji.
Principy RAG
RAG se často používá k povolení scénáře "chatu přes moje data", kdy společnosti, které mají velký korpus textového obsahu (interní dokumenty, dokumentaci atd.) a chtějí tento korpus používat jako základ pro odpovědi na výzvy uživatelů.
Na vysoké úrovni vytvoříte položku databáze pro každý dokument (nebo část dokumentu označovanou jako blok dat). Blok dat je indexován při vkládání, vektor (pole) čísel, která představují omezující vlastnosti dokumentu. Když uživatel odešle dotaz, vyhledáte v databázi podobné dokumenty a pak odešlete dotaz a dokumenty do LLM, abyste mohli vytvořit odpověď.
Poznámka:
Termín Retrieval-Augmented Generation (RAG) accommodatively. Proces implementace chatovacího systému založeného na RAG, který je popsaný v tomto článku, se dá použít bez ohledu na to, jestli chcete použít externí data, která se mají použít v podpůrné kapacitě (RAG), nebo jako střed odpovědi (RCG). Toto drobné rozlišení není řešeno ve většině čtení souvisejících s RAG.
Vytvoření indexu vektorizovaných dokumentů
Prvním krokem k vytvoření chatovacího systému založeného na RAG je vytvoření vektorového úložiště dat obsahujícího vektorové vkládání dokumentu (nebo části dokumentu). Podívejte se na následující diagram, který popisuje základní kroky k vytvoření vektorizovaného indexu dokumentů.

Tento diagram představuje datový kanál, který zodpovídá za příjem, zpracování a správu dat používaných systémem. To zahrnuje předběžné zpracování dat, která mají být uložena v vektorové databázi, a zajištění toho, aby data předávaná do LLM byla ve správném formátu.
Celý proces je řízen konceptem vkládání, což je číselná reprezentace dat (obvykle slova, fráze, věty nebo dokonce celé dokumenty), která zachycuje sémantické vlastnosti vstupu způsobem, který lze zpracovávat modely strojového učení.
Pokud chcete vytvořit vkládání, odešlete blok obsahu (věty, odstavce nebo celé dokumenty) do rozhraní API azure OpenAI Embedding. To, co je vráceno z rozhraní API pro vložení, je vektor. Každá hodnota ve vektoru představuje určitou charakteristiku (dimenzi) obsahu. Dimenze můžou zahrnovat téma, sémantický význam, syntaxi a gramatiku, použití slov a frází, kontextové vztahy, styl a tón atd. Všechny hodnoty vektoru společně představují prostorový prostor obsahu. Jinými slovy, pokud si můžete představit 3D reprezentaci vektoru se třemi hodnotami, daný vektor žije v určité oblasti x, y, z roviny. Co když 1000 (nebo více) hodnot? I když není možné, aby lidé kreslili graf o rozměrech 1000 dimenzí na list papíru, aby byl srozumitelnější, počítače nemají žádný problém pochopit tento stupeň prostorového prostoru.
Další krok diagramu znázorňuje uložení vektoru spolu se samotným obsahem (nebo ukazatelem na umístění obsahu) a další metadata v databázi vektorů. Vektorová databáze je podobná jakémukoli typu databáze se dvěma rozdíly:
- Vektorové databáze používají vektor jako index k hledání dat.
- Vektorové databáze implementují algoritmus označovaný jako kosinus podobné hledání, označovaný také jako nejbližší soused, který používá vektory, které nejvíce odpovídají kritériím hledání.
S korpusem dokumentů uložených v vektorové databázi mohou vývojáři vytvořit komponentu retrieveru, která načítá dokumenty, které odpovídají dotazu uživatele z databáze, aby mohli zadat LLM s tím, co potřebuje k zodpovězení dotazu uživatele.
Odpovědi na dotazy pomocí dokumentů
Systém RAG nejprve používá sémantické vyhledávání k vyhledání článků, které by mohly být užitečné pro LLM při psaní odpovědi. Dalším krokem je odeslání odpovídajících článků spolu s původní výzvou uživatele k vytvoření odpovědi do LLM.
Představte si následující diagram jako jednoduchou implementaci RAG (někdy označovanou jako "naïve RAG").
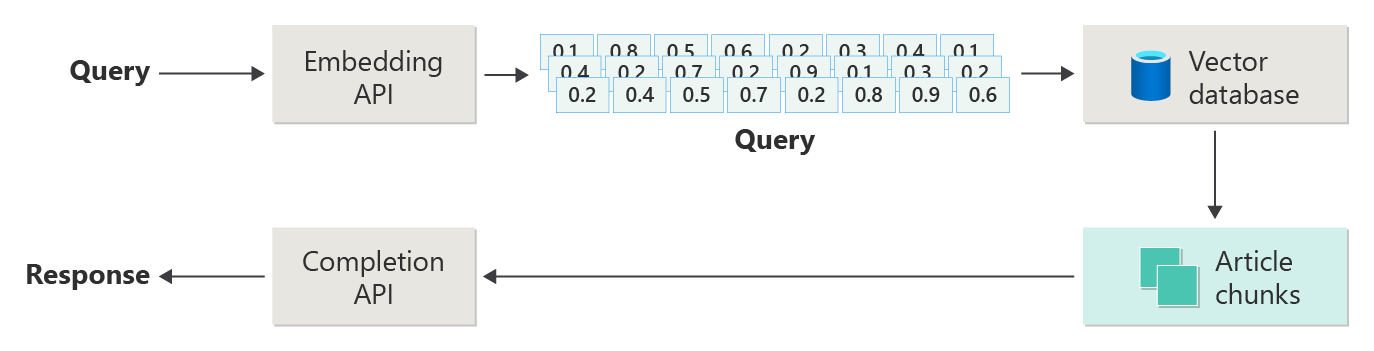
V diagramu uživatel odešle dotaz. Prvním krokem je vytvoření vložení pro výzvu uživatele k získání vektoru. Dalším krokem je prohledání vektorové databáze pro tyto dokumenty (nebo části dokumentů), které jsou "nejbližší soused" shodné.
Kosinus podobnost je míra, která slouží k určení způsobu, jakým jsou podobné dva vektory, v podstatě posuzuje kosinus úhlu mezi nimi. Kosinus podobnost blízko 1 označuje vysoký stupeň podobnosti (malý úhel), zatímco podobnost blízko -1 značí rozdílnost (úhel se blíží 180 stupňů). Tato metrika je zásadní pro úkoly, jako je podobnost dokumentu, kde cílem je najít dokumenty s podobným obsahem nebo významem.
Algoritmy "Nejbližší soused" fungují vyhledáním nejbližších vektorů (sousedů) k danému bodu ve vektorovém prostoru. V algoritmu k-nejbližších sousedů (KNN) odkazuje "k" na počet nejbližších sousedů, které je potřeba vzít v úvahu. Tento přístup se běžně používá při klasifikaci a regresi, kde algoritmus predikuje popisek nového datového bodu na základě většiny popisků jeho "k" nejbližších sousedů v trénovací sadě. KNN a kosinus podobnost se často používají společně v systémech, jako jsou moduly doporučení, kde cílem je najít položky, které jsou nejvíce podobné předvolbám uživatele, reprezentované jako vektory v prostoru pro vložení.
Získáte nejlepší výsledky z hledání a odešlete odpovídající obsah spolu s výzvou uživatele k vygenerování odpovědi, která (snad) bude informována odpovídajícím obsahem.
Výzvy a důležité informace
Implementace systému RAG se dodává se sadou výzev. Ochrana osobních údajů je nejdůležitější, protože systém musí zpracovávat uživatelská data zodpovědně, zejména při načítání a zpracování informací z externích zdrojů. Výpočetní požadavky mohou být také významné, protože procesy načítání i generování jsou náročné na prostředky. Dalším důležitým aspektem je zajištění přesnosti a relevance odpovědí při správě předsudků v datech nebo modelu. Vývojáři musí tyto výzvy pečlivě procházet a vytvářet efektivní, etické a cenné systémy RAG.
Další článek v této sérii: Vytváření pokročilých systémů načítání rozšířené generace poskytuje podrobnější informace o vytváření dat a odvozování kanálů umožňujících systém RAG připravený pro produkční prostředí.
Pokud chcete začít experimentovat s vytvářením řešení generující umělé inteligence okamžitě, doporučujeme se podívat na začínáme s chatem pomocí vlastní ukázky dat pro Python. K dispozici jsou také verze tohoto kurzu v .NET, Javě a JavaScriptu.
Vyladění modelu
Vyladění v kontextu LLM odkazuje na proces úpravy parametrů modelu v datové sadě specifické pro doménu po počátečním trénování na velké a různorodé datové sadě.
LLM se trénují (předem natrénované) na široké datové sadě, chápou strukturu jazyka, kontext a širokou škálu znalostí. Tato fáze zahrnuje výuku obecných jazykových vzorů. Vyladění přidává do předem natrénovaného modelu další trénování na základě menší konkrétní datové sady. Cílem této sekundární fáze trénování je přizpůsobit model tak, aby lépe fungoval s konkrétními úlohami nebo pochopit konkrétní domény, což zvyšuje jeho přesnost a význam pro tyto specializované aplikace. Při vyladění se váhy modelu upraví tak, aby lépe předpovídaly nebo porozuměly nuancí této menší datové sady.
Několik důležitých informací:
- Specializace: Jemné vyladění modelu přizpůsobí konkrétním úkolům, jako je analýza právních dokumentů, interpretace lékařského textu nebo interakce zákaznických služeb. Díky tomu je model v těchto oblastech efektivnější.
- Efektivita: Je efektivnější vyladit předem natrénovaný model pro konkrétní úlohu, než vytrénovat model od začátku, protože vyladění vyžaduje méně dat a výpočetních prostředků.
- Přizpůsobitelnost: Jemné ladění umožňuje přizpůsobení novým úkolům nebo doménám, které nebyly součástí původních trénovacích dat, což umožňuje univerzální nástroje LLM pro různé aplikace.
- Vylepšený výkon: U úloh, které se liší od dat, na které byl model původně natrénovaný, může vyladění vést k lepšímu výkonu, protože model upraví tak, aby porozuměl konkrétnímu jazyku, stylu nebo terminologii použité v nové doméně.
- Přizpůsobení: V některých aplikacích může vyladění pomoci přizpůsobit odpovědi nebo předpovědi modelu tak, aby vyhovovaly konkrétním potřebám nebo preferencím uživatele nebo organizace. Vyladění má ale určitá nevýhoda a omezení. Pochopení těchto možností může pomoct při rozhodování, kdy se rozhodnout pro vyladění a alternativy, jako je načítání rozšířené generace (RAG).
- Požadavek na data: Vyladění vyžaduje dostatečně velkou a vysoce kvalitní datovou sadu specifickou pro cílovou úlohu nebo doménu. Shromažďování a kurátorování této datové sady může být náročné a náročné na prostředky.
- Riziko přeurčení: Existuje riziko přeurčení, zejména u malé datové sady. Přeurčení umožňuje, aby model dobře fungoval s trénovacími daty, ale špatně na nových, nezobjených datech, což snižuje jeho generalizovatelnost.
- Náklady a zdroje: I když méně náročné na zdroje než trénování od začátku, vyladění stále vyžaduje výpočetní prostředky, zejména u velkých modelů a datových sad, což může být pro některé uživatele nebo projekty zakázané.
- Údržba a aktualizace: Jemně vyladěné modely můžou vyžadovat pravidelné aktualizace, aby zůstaly efektivní, protože se informace specifické pro doménu v průběhu času mění. Tato průběžná údržba vyžaduje další prostředky a data.
- Posun modelu: Vzhledem k tomu, že je model jemně vyladěný pro konkrétní úlohy, může přijít o některé obecné porozumění jazyku a všestrannost, což vede k jevu známému jako posun modelu.
Přizpůsobení modelu pomocí jemného ladění vysvětluje, jak model vyladit. Na vysoké úrovni zadáte datovou sadu JSON s potenciálními dotazy a upřednostňovaným odpověďmi. Dokumentace naznačuje, že existují znatelná vylepšení tím, že poskytuje 50 až 100 dvojic otázek a odpovědí, ale správné číslo se výrazně liší v případě použití.
Vyladění a generování rozšířeného načítání
Na povrchu se může zdát, že se mezi jemně vyladěnou a rozšířenou generaci načítáním trochu překrývají. Volba mezi vyladěním a načítáním rozšířené generace závisí na konkrétních požadavcích vaší úlohy, včetně očekávání výkonu, dostupnosti prostředků a potřeby specificity pro doménu a generalizovatelnosti.
Kdy preferovat jemné ladění před generováním rozšířeného načítání:
- Výkon specifický pro úlohy – Vyladění je vhodnější, pokud je vysoký výkon u konkrétní úlohy kritický a existuje dostatek dat specifických pro doménu pro efektivní trénování modelu bez významných rizik přeurčení.
- Kontrola nad daty – Pokud máte proprietární nebo vysoce specializovaná data, která se výrazně liší od dat, na kterých byl základní model natrénován, můžete toto jedinečné znalosti začlenit do modelu.
- Omezená potřeba aktualizací v reálném čase – Pokud úloha nevyžaduje neustálé aktualizace modelu nejnovějšími informacemi, může být vyladění efektivnější, protože modely RAG obvykle potřebují přístup k aktuálním externím databázím nebo internetu, aby mohly získat nejnovější data.
Kdy preferovat generování rozšířeného načítání před vyladěním:
- Dynamický nebo vyvíjející se obsah – RAG je vhodnější pro úlohy, u kterých je nejdůležitější mít nejaktuálnější informace. Vzhledem k tomu, že modely RAG můžou přijímat data z externích zdrojů v reálném čase, jsou vhodnější pro aplikace, jako je generování zpráv nebo odpovídání na otázky týkající se nedávných událostí.
- Generalizace Nad specializace – pokud je cílem zachovat silný výkon v široké škále témat, a ne excelovat v úzké doméně, může být rag vhodnější. Používá externí znalostní báze, což umožňuje generovat odpovědi napříč různými doménami bez rizika přeurčení konkrétní datové sady.
- Omezení zdrojů – Pro organizace s omezenými zdroji pro shromažďování dat a trénování modelů může použití přístupu RAG nabídnout nákladově efektivní alternativu k jemnému ladění, zejména pokud základní model již provádí přiměřeně dobře na požadovaných úkolech.
Konečné aspekty, které můžou ovlivnit rozhodnutí o návrhu aplikace
Tady je krátký seznam věcí, které je potřeba vzít v úvahu, a další poznatky z tohoto článku, které ovlivňují rozhodnutí o návrhu vaší aplikace:
- Rozhodněte se mezi vyladěním a načítáním rozšířené generace na základě konkrétních potřeb vaší aplikace. Vyladění může nabídnout lepší výkon pro specializované úlohy, zatímco RAG může poskytovat flexibilitu a aktuální obsah pro dynamické aplikace.