Starší vizualizace
Tento článek popisuje starší vizualizace Azure Databricks. Informace o podpoře aktuální vizualizace najdete v poznámkových blocích Databricks.
Azure Databricks také nativně podporuje knihovny vizualizace v Pythonu a R a umožňuje instalaci a použití knihoven třetích stran.
Vytvoření starší vizualizace
Pokud chcete vytvořit původní vizualizaci z buňky výsledků, klikněte na + a selectLegacy Visualization.
Starší vizualizace podporují bohatou set typů grafu:
Volba a konfigurace staršího typu grafu
Pokud chcete vybrat pruhový graf, klikněte na ikonu  pruhového grafu:
pruhového grafu:
Pokud chcete zvolit jiný typ grafu, klikněte ![]() napravo od pruhového grafu a zvolte typ grafu.
napravo od pruhového grafu a zvolte typ grafu.
Panel nástrojů starší verze grafu
Spojnicové i pruhové grafy mají integrovaný panel nástrojů, který podporuje bohaté set interakcí na straně klienta.
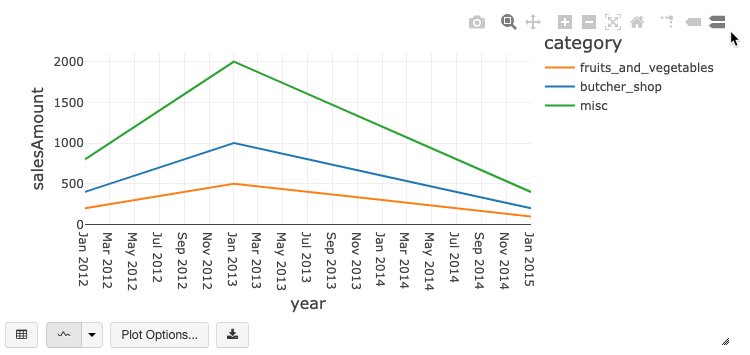
Pokud chcete nakonfigurovat graf, klikněte na tlačítko Plot options… (Možnosti grafu…).

Spojnicový graf obsahuje několik možností vlastního grafu: nastavení rozsahu osy Y, zobrazení a skrytí bodů a zobrazení osy Y s logaritmickým měřítkem.
Informace o starších typech grafů najdete v tématu:
Konzistence barev v různých grafech
Azure Databricks podporuje dva druhy konzistence barev napříč staršími grafy: řady set a globální.
řady set konzistence barev přiřadí stejnou barvu stejné hodnotě, pokud máte řadu se stejnými values, ale v různých pořadích (například A = ["Apple", "Orange", "Banana"] a B = ["Orange", "Banana", "Apple"]).
values se seřadí před vykreslením, takže obě legendy jsou seřazené stejným způsobem (["Apple", "Banana", "Orange"]) a stejné values mají stejné barvy. Pokud ale máte řadu C = ["Orange", "Banana"], nebyla by barva konzistentní s set A, protože set není stejná. Algoritmus řazení by přiřadil první barvu "Banán" v set C, ale druhou barvu na "Banán" v set A. Pokud chcete, aby byly tyto řady konzistentní s barvou, můžete určit, že grafy by měly mít globální konzistenci barev.
V globální konzistenci barev se každá hodnota vždy mapuje na stejnou barvu bez ohledu na to, co values dané řady mají. Pokud to chcete povolit pro každý graf, select zaškrtávací políčko globální konzistence barev.
Poznámka:
K dosažení této konzistence služba Azure Databricks zatřiďuje hodnoty hash přímo z values na barvy. Aby nedocházelo ke kolizím (where dvě values přejít na přesně stejnou barvu), hodnota hash je na velký set barev, který má vedlejší efekt, který hezky vypadající nebo snadno rozpoznatelné barvy nelze zaručit; s mnoha barvami jsou vázány na některé, které jsou velmi podobné.
Vizualizace strojového učení
Kromě standardních typů grafů podporují starší vizualizace následující trénování strojového učení parameters a výsledky:
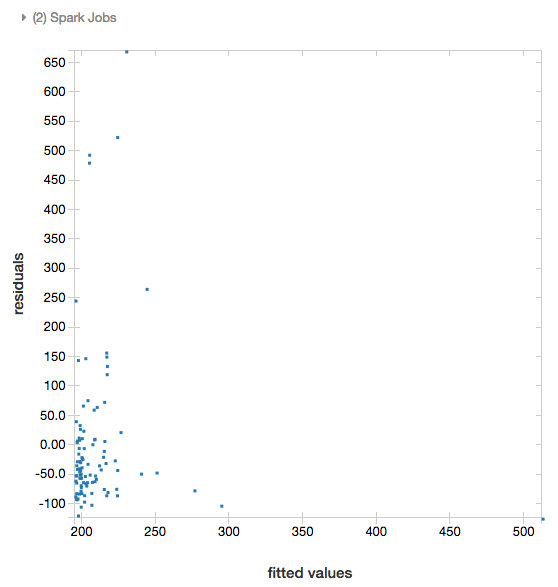
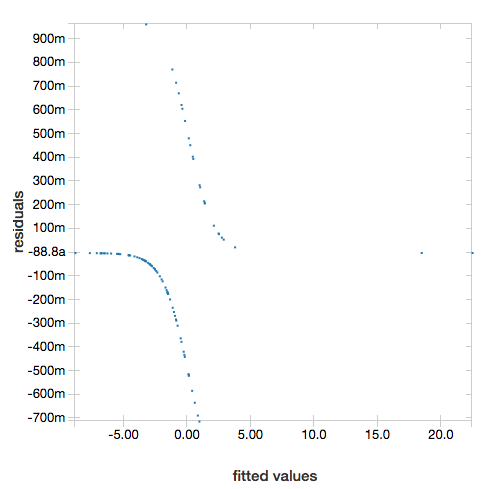
Rezidua
U lineárních a logistických regresí můžete vykreslit fitovaný graf a graf reziduí . Chcete-li získat tento graf, zadejte model a datový rámec.
V následujícím příkladu se spustí lineární regrese na populaci města k vytvoření dat o prodejních cenách nemovitostí a pak se zobrazí rezidua a fitované hodnoty.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
Křivky ROC
U logistických regresí můžete vykreslit křivku ROC . Chcete-li získat tento graf, zadejte model, předem zadaná fit data do metody a parametr "ROC".
Následující příklad vyvíjí klasifikátor, který předpovídá, jestli jednotlivec získá <=50K nebo >50k za rok z různých atributů jednotlivce. Datová sada Adult vychází z dat sčítání lidu a obsahuje informace o 48842 jednotlivcích a jejich ročních příjmech.
Vzorový kód v této části používá kódování one-hot.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
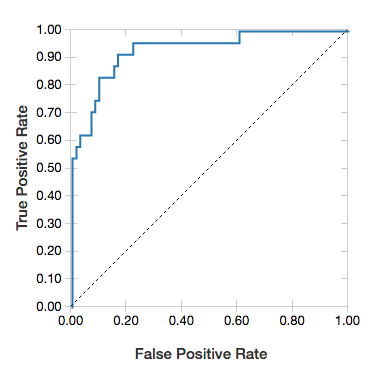
Pokud chcete zobrazit rezidua, vynechte parametr "ROC":
display(lrModel, preppedDataDF)
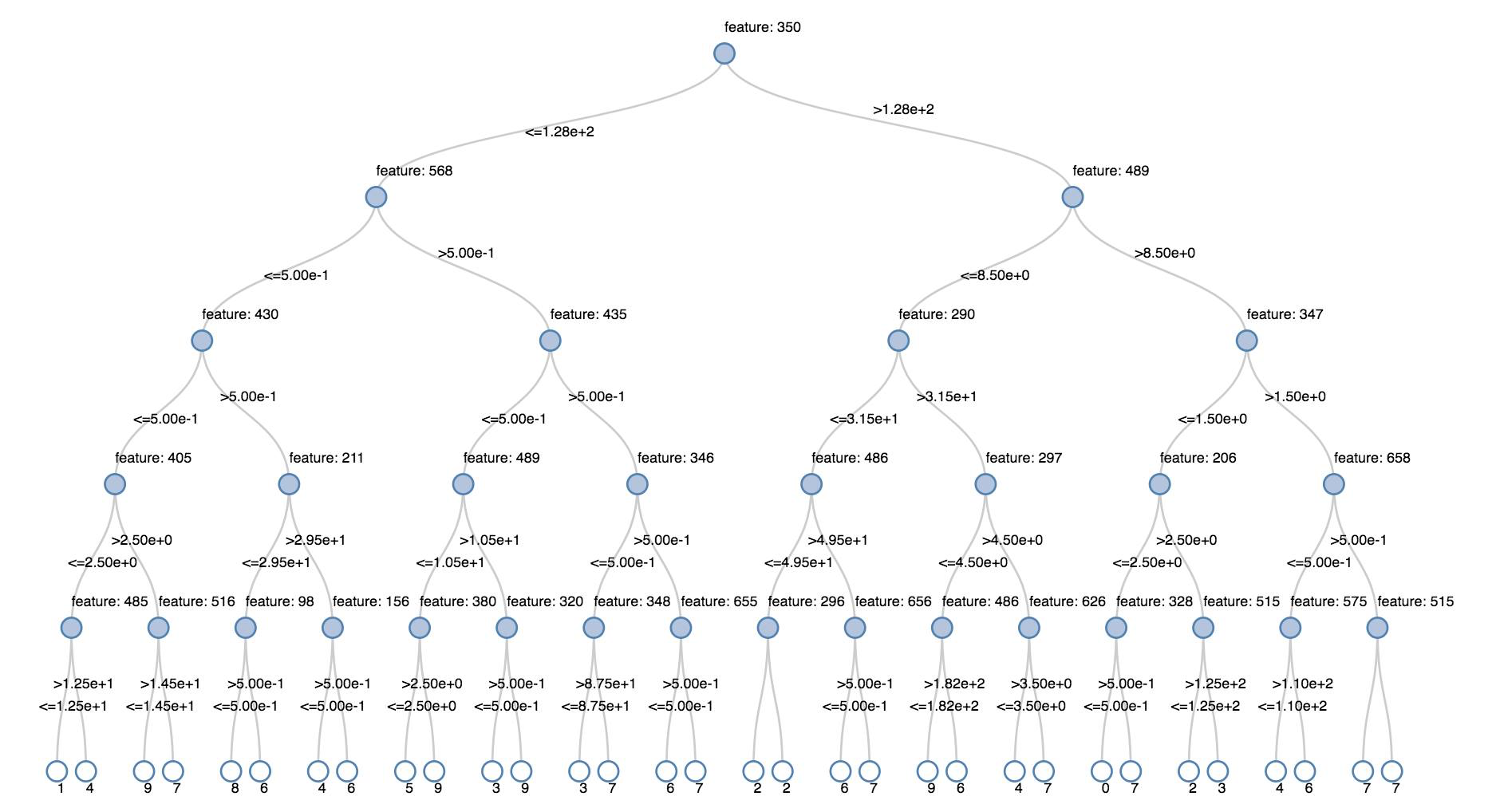
rozhodovací stromy
Starší vizualizace podporují vykreslování rozhodovacího stromu.
Pokud chcete tuto vizualizaci získat, zadejte model rozhodovacího stromu.
Následující příklady natrénují strom tak, aby rozpoznal číslice (0–9) v datové sadě MNIST obsahující obrázky s ručně psanými číslicemi, a následně zobrazí příslušný strom.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
Datové rámce strukturovaného streamování
K vizualizaci výsledku dotazu streamování v reálném čase můžete pomocí funkce display zobrazit datové rámce se strukturovaným streamováním v jazycích Scala a Python.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display podporuje následující volitelné parameters:
-
streamName: název dotazu streamování. -
trigger(Scala) aprocessingTime(Python): Definuje, jak často se spouští dotaz streamování. Pokud tento parametr nezadáte, systém zkontroluje dostupnost nových dat ihned po dokončení předchozího zpracování. Aby se snížily náklady v produkčním prostředí, Databricks doporučuje, abyste vždy set spouštěcí interval. Výchozí interval aktivační události je 500 ms. -
checkpointLocation: umístění, kde systém where zapíše všechny informace o kontrolním bodu. Pokud není zadáno, systém automaticky vygeneruje dočasné umístění pro kontrolní body v DBFS. Aby váš proud mohl pokračovat ve zpracovávání dat od where, kde skončil, musíte zadat umístění kontrolního bodu. Databricks doporučuje, abyste v produkčním prostředí vždy zadali možnostcheckpointLocation.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Další informace o těchto parametersnaleznete v tématu Spouštění dotazů streamování.
Funkce displayHTML
Poznámkové bloky programovacích jazyků pro Azure Databricks (Python, R a Scala) podporují grafiku HTML díky funkci displayHTML. Této funkci můžete předat libovolný kód HTML, CSS nebo JavaScript. Tato funkce podporuje interaktivní grafiku s využitím knihoven JavaScriptu, jako je D3.
Příklady použití displayHTML:
Poznámka:
Iframe displayHTML se obsluhuje z domény databricksusercontent.com a sandbox iframe zahrnuje atribut allow-same-origin. Doména databricksusercontent.com musí být přístupná z prohlížeče. Pokud je aktuálně blokována vaší podnikovou sítí, musí být přidána na seznam povolených list.
Obrazy
Columns obsahující datové typy obrázků se vykreslují jako formátovaný kód HTML. Azure Databricks se pokusí vykreslit miniatury obrázků pro spark.read.format('image') funkce. Pro image values generované jinými prostředky podporuje Azure Databricks vykreslování 1, 3 nebo 4 kanálových obrázků (where každý kanál se skládá z jednoho bajtu) s následujícími omezeními:
-
Obrázky s jedním kanálem:
modePole musí být rovno 0. Poleheight,widthanChannelsmusí přesně popisovat data binárního obrázku v polidata. -
Obrázky se třemi kanály:
modePole musí být rovno 16. Poleheight,widthanChannelsmusí přesně popisovat data binárního obrázku v polidata. Poledatamusí obsahovat pixelová data v blocích po třech bajtech s kanály v pořadí(blue, green, red)pro každý pixel. -
Obrázky se čtyřmi kanály:
modePole musí být rovno 24. Poleheight,widthanChannelsmusí přesně popisovat data binárního obrázku v polidata. Poledatamusí obsahovat pixelová data v blocích po čtyřech bajtech s kanály v pořadí(blue, green, red, alpha)pro každý pixel.
Příklad
Předpokládejme, že máte složku obsahující obrázky:

Pokud načtete obrázky do datového rámce a pak zobrazíte datový rámec, Azure Databricks vykreslí miniatury obrázků:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Vizualizace v Pythonu
V této části:
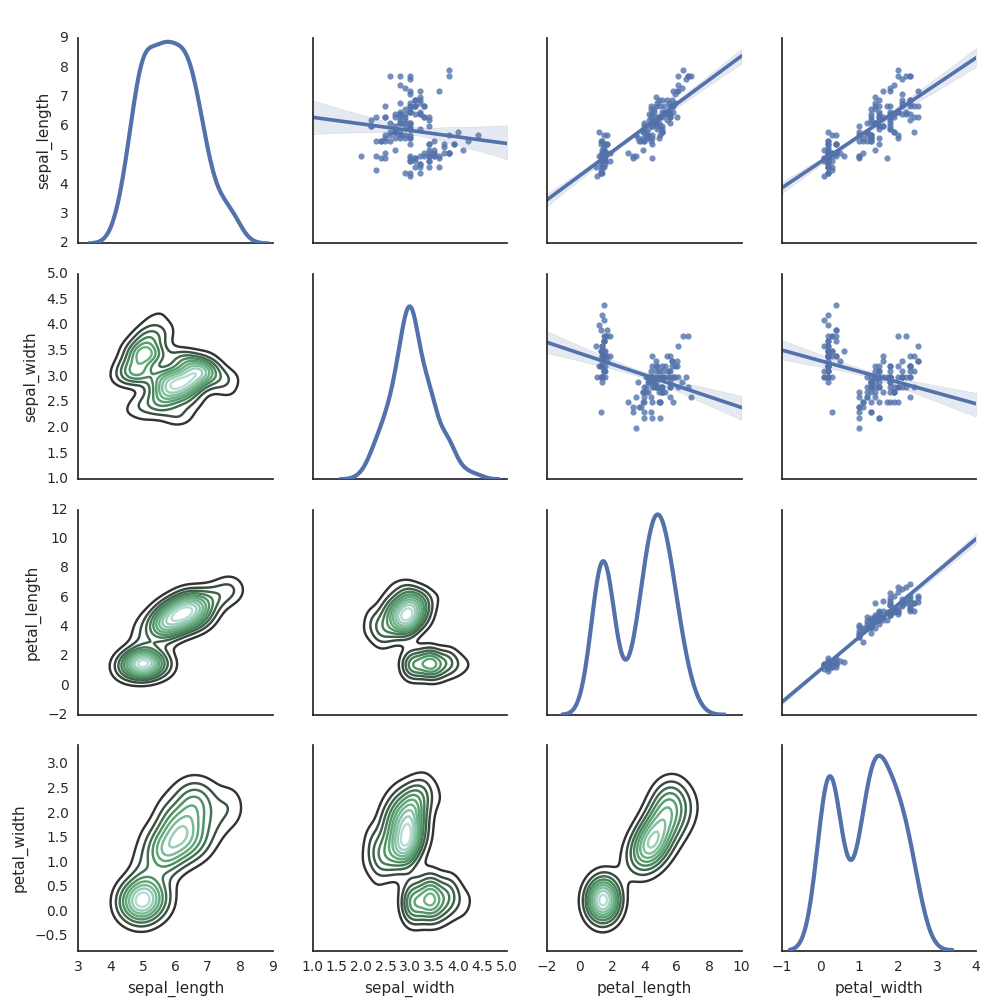
Seaborn
K generate grafů můžete použít také jiné knihovny Pythonu. Databricks Runtime obsahuje knihovnu vizualizací Seaborn. Pokud chcete vytvořit graf pomocí knihovny Seaborn, naimportujte ji, vytvořte graf a předejte ho funkci display.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Další knihovny pro Python
Vizualizace v jazyce R
Pokud chcete vykreslovat data v R, použijte funkci display následujícím způsobem:
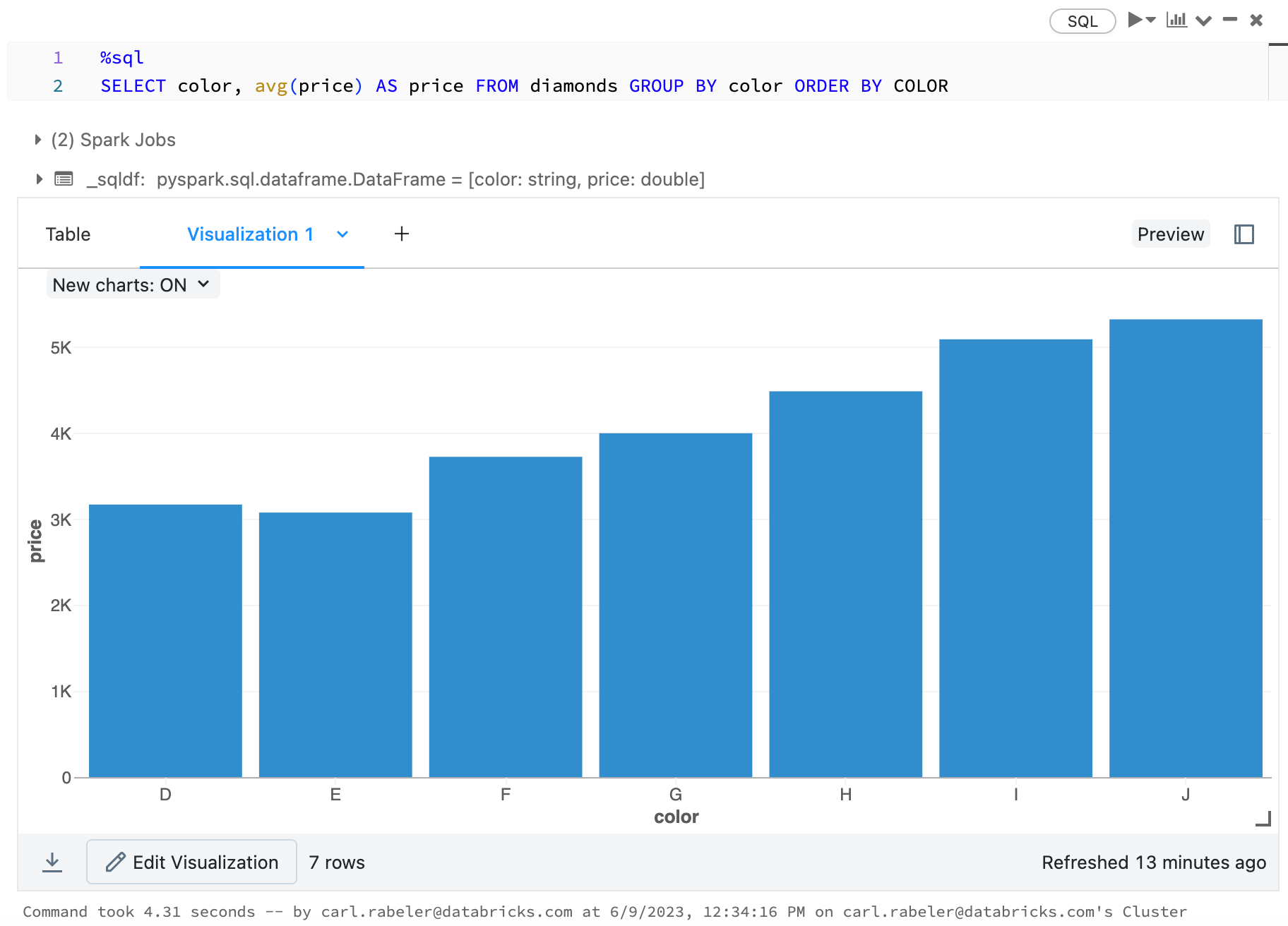
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Můžete použít výchozí funkci grafu v jazyce R.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
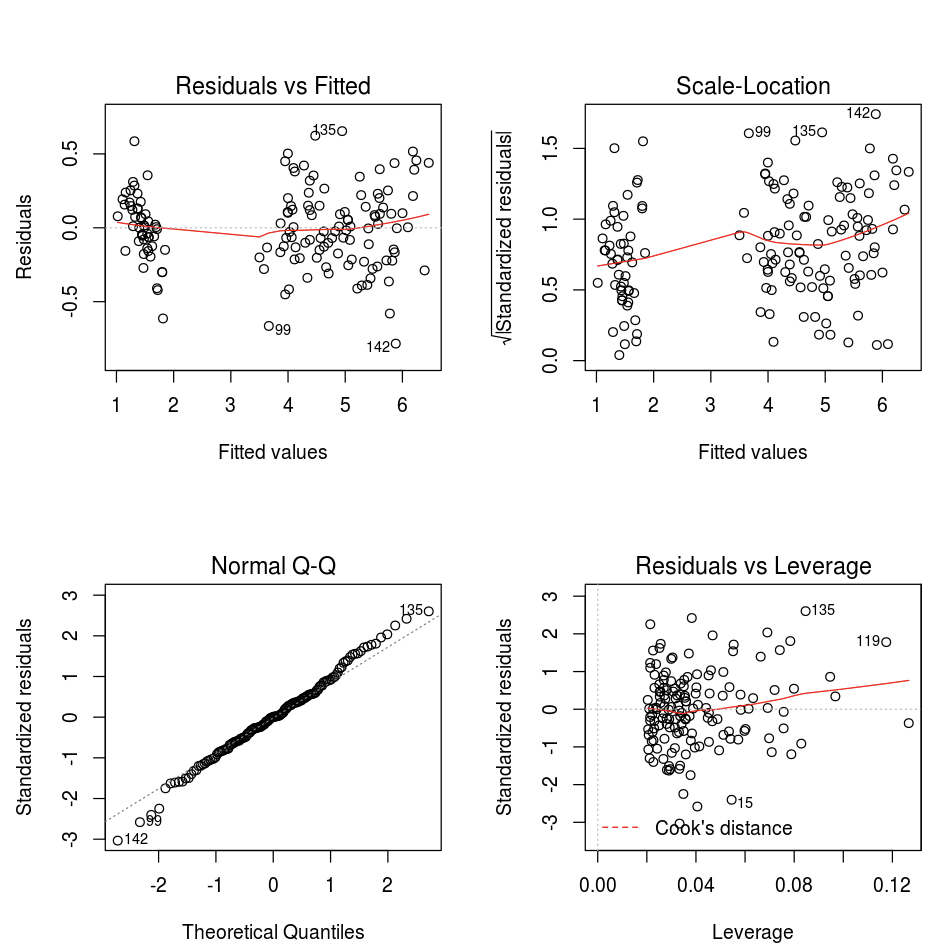
Můžete také použít libovolný balíček pro vizualizaci R. Poznámkový blok R zachytí výsledný graf jako .png a zobrazí ho jako vložený.
V této části:
Lattice
Balíček Lattice podporuje grafy s šikmou jemnou mřížkou, které zobrazují proměnnou nebo vztah mezi proměnnými podmíněně v jedné nebo více různých proměnných.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
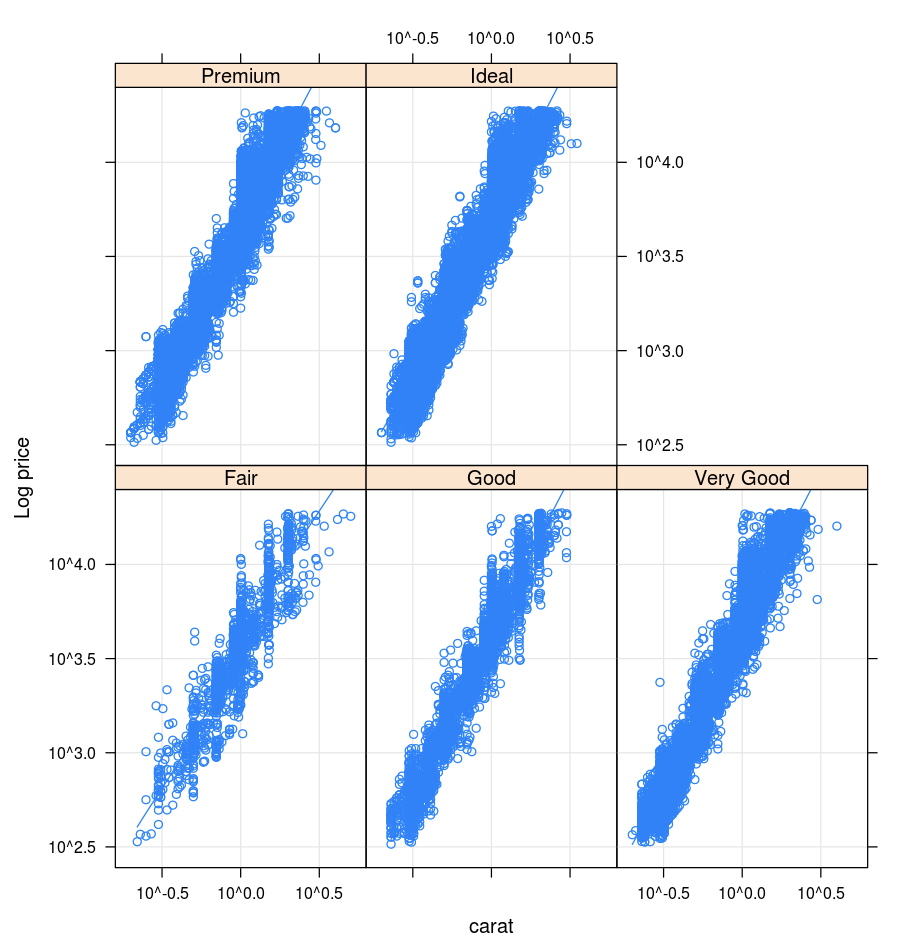
DandEFA
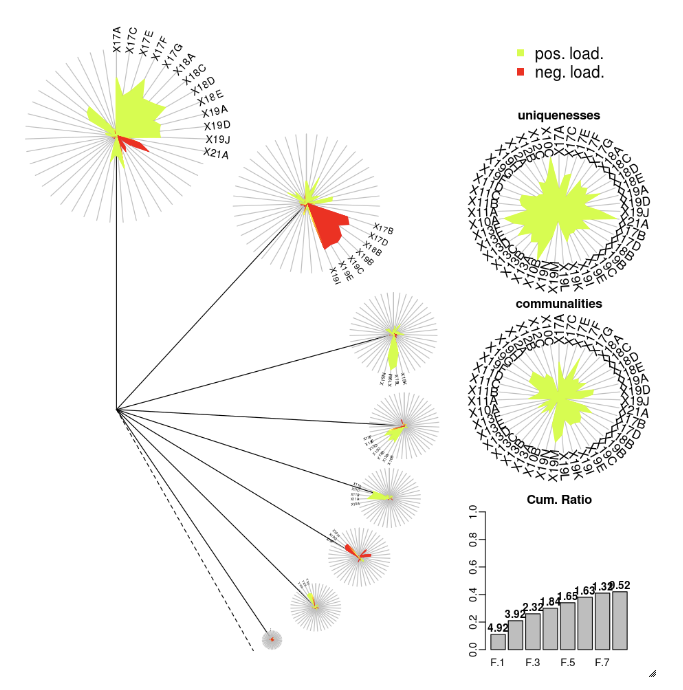
Balíček DandEFA podporuje grafy ve tvaru pampelišek.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Plotly
Balíček Plotly R spoléhá na htmlwidgety pro jazyk R. Pokyny k instalaci a poznámkový blok najdete v tématu htmlwidgets.
Další knihovny R
Vizualizace v jazyce Scala
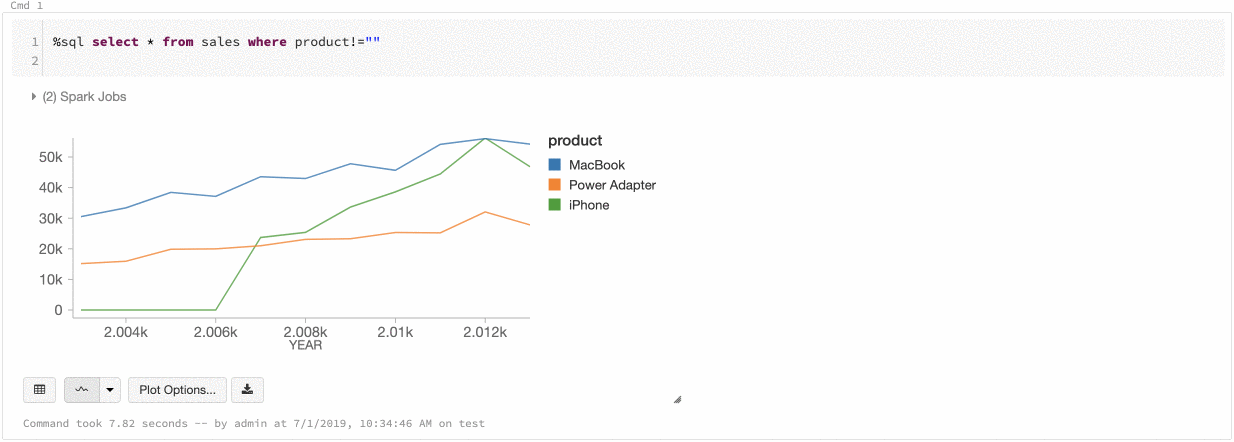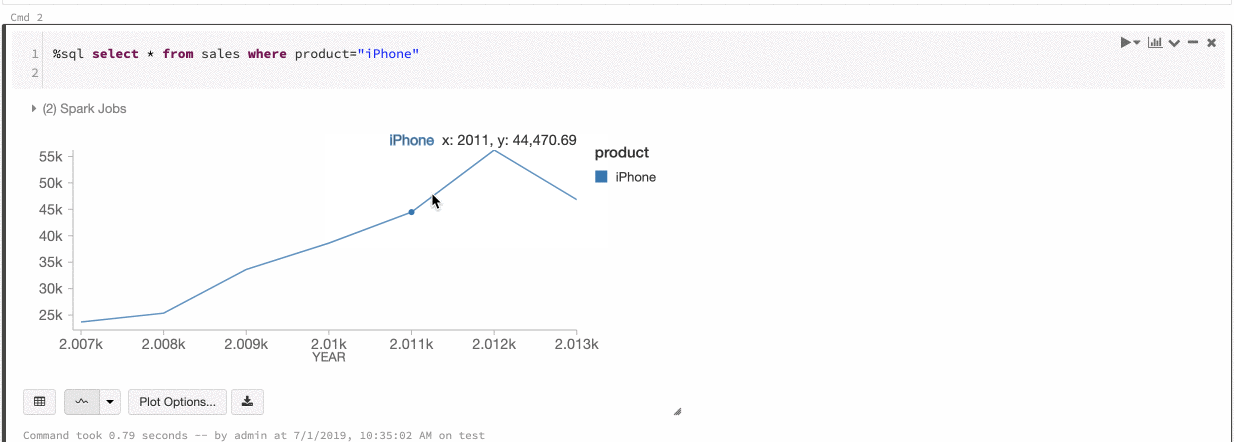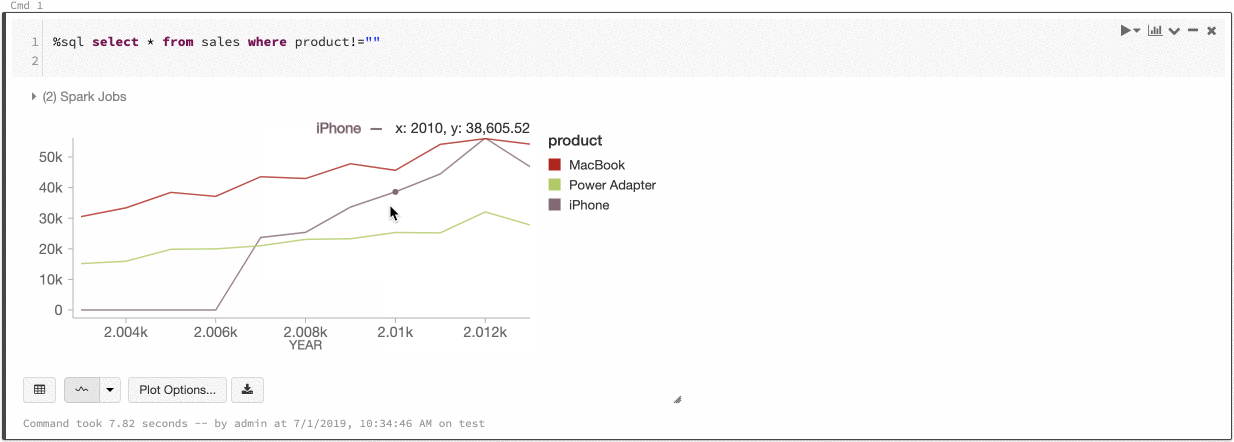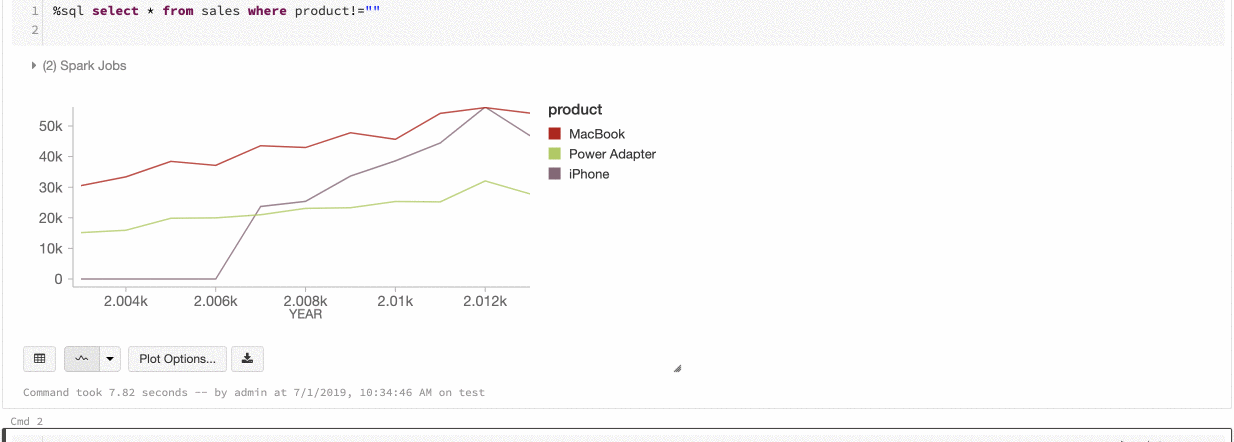
Pokud chcete vykreslovat data v jazyce Scala, použijte funkci display následujícím způsobem:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Podrobné poznámkové bloky pro Python a Scala
Podrobné informace o vizualizacích Pythonu najdete v poznámkovém bloku:
Podrobné informace o vizualizacích Scala najdete v poznámkovém bloku: