Proč přírůstkové zpracování datových proudů?
Dnešní firmy řízené daty neustále vytvářejí data, což vyžaduje datové kanály přípravy, které nepřetržitě ingestují a transformují tato data. Tyto kanály by měly být schopné zpracovávat a dodávat data přesně jednou, dosahovat výsledků s latencí menší než 200 milisekund a vždy se snažit minimalizovat náklady.
Tento článek popisuje přístupy dávkového a inkrementálního zpracování datových proudů pro návrh datových tras, proč je inkrementální zpracování datových proudů lepší volbou, a jak začít s nabídkami Databricks pro inkrementální zpracování datových proudů, Streamování v Azure Databricks a Co je Delta Live Tables?. Tyto funkce umožňují rychle psát a spouštět kanály, které zaručují sémantiku doručení, latenci, náklady a další.
Nástrahy opakovaných dávkových úloh
Při nastavování datového kanálu můžete nejprve zapisovat opakované dávkové úlohy do příjmu dat. Například každou hodinu můžete spustit úlohu Sparku, která čte ze zdroje a zapisuje data do jímky, jako je Delta Lake. Problém s tímto přístupem je přírůstkově zpracovávat váš zdroj, protože úloha Sparku, která se spouští každou hodinu, musí začít tam, kde skončila poslední. Můžete zaznamenat nejnovější časové razítko dat, která jste zpracovali, a pak vybrat všechny řádky s časovými razítky, které jsou novější než toto časové razítko, ale existují nástrahy:
Pokud chcete spustit průběžný datový kanál, můžete se pokusit naplánovat hodinovou dávkovou úlohu, která přírůstkově čte z vašeho zdroje, provede transformace a zapíše výsledek do jímky, jako je Delta Lake. Tento přístup může mít nástrahy:
- Úloha Sparku, která se dotazuje na všechna nová data po časovém razítku, vynechá pozdní data.
- Úloha Sparku, která selže, může vést k porušení přesně jednou záruk, pokud není pečlivě zpracována.
- Úloha Sparku, která uvádí obsah umístění cloudového úložiště, aby našla nové soubory, bude nákladná.
Pak je stále potřeba tato data opakovaně transformovat. Můžete napsat opakované dávkové úlohy, které pak agregují data nebo používají jiné operace, což dále komplikuje a snižuje efektivitu kanálu.
Příklad dávky
Pokud chcete plně porozumět úskalím dávkového příjmu a transformace vašeho kanálu, zvažte následující příklady.
Zmeškaná data
Vzhledem k tématu Kafka s daty o využití, která určují, kolik se mají účtovat zákazníkům a kanál ingestuje v dávkách, může posloupnost událostí vypadat takto:
- První dávka má dva záznamy v 8:30 a 8:30.
- Aktualizujete nejnovější časové razítko na 8:30.
- Dostanete další záznam v 8:15 ráno.
- Vaše druhé dávkové dotazy na všechno po 8:30, takže zmeškáte záznam v 8:15.
Kromě toho nechcete přebít nebo podvyplňování vašich uživatelů, abyste měli jistotu, že ingestujete každý záznam přesně jednou.
Redundantní zpracování
Dále předpokládejme, že vaše data obsahují řádky uživatelských nákupů a chcete agregovat prodeje za hodinu, abyste věděli nejoblíbenější časy ve vašem obchodě. Pokud nákupy pro stejnou hodinu přicházejí do různých dávek, budete mít více dávek, které vytvářejí výstupy za stejnou hodinu:
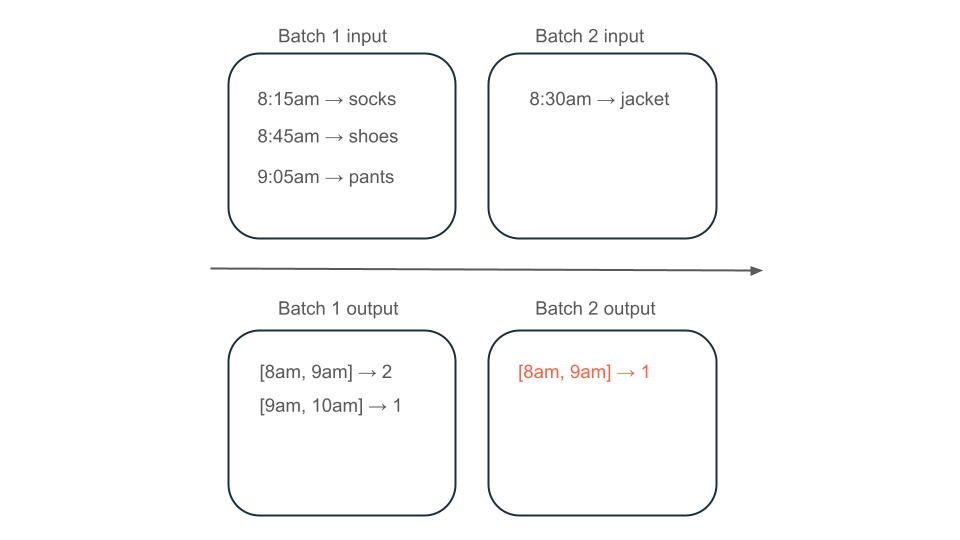
Má okno 8:00 do 9:00 dva prvky (výstup dávky 1), jeden prvek (výstup dávky 2) nebo tři (výstup žádné dávky)? Data potřebná k vytvoření daného časového intervalu se zobrazí v několika dávkách transformace. Pokud chcete tento problém vyřešit, můžete data rozdělit podle dne a znovu zpracovat celý oddíl, když potřebujete vypočítat výsledek. Potom můžete výsledky ve své jímce přepsat:
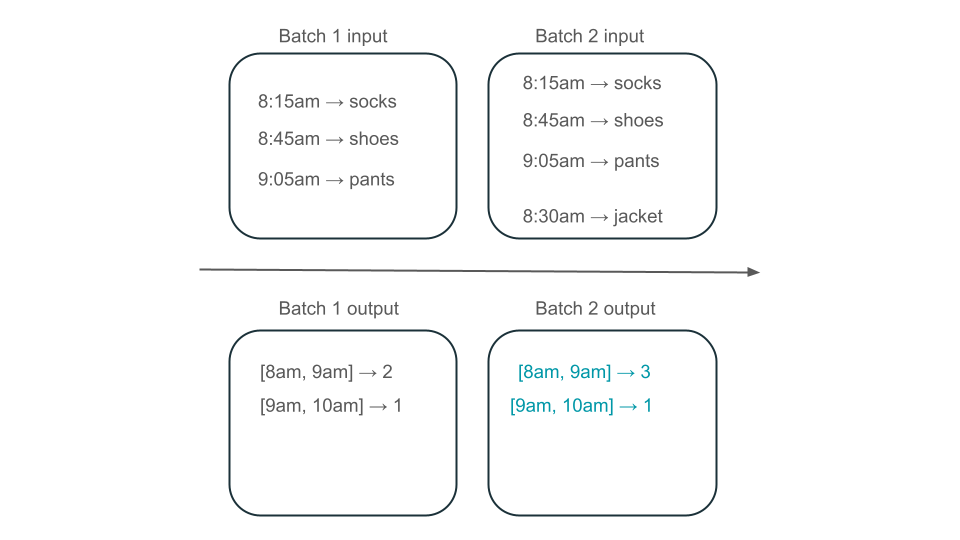
To ale má na úkor latence a nákladů, protože druhá dávka musí provádět zbytečnou práci při zpracování dat, která už mohla zpracovat.
Žádné nástrahy s přírůstkovým zpracováním datových proudů
Přírůstkové zpracování datových proudů usnadňuje vyhnout se všem úskalím opakovaných dávkových úloh ingestování a transformaci dat. Databricks strukturované streamování a Delta Live Tables spravují složitosti implementace streamování, abyste se mohli soustředit pouze na obchodní logiku. Stačí zadat, ke kterému zdroji se připojit, k jakým transformacím se mají data provádět a kam se má výsledek zapisovat.
Přírůstkový příjem dat
Přírůstkové příjem dat v Databricks využívá strukturované streamování Apache Sparku, které může přírůstkově využívat zdroj dat a zapisovat je do jímky. Modul strukturovaného streamování může zpracovávat data přesně jednou a modul dokáže zpracovat data mimo pořadí. Modul je možné spustit buď v poznámkových blocích, nebo pomocí streamovaných tabulek v Delta Live Tables.
Modul strukturovaného streamování v Databricks poskytuje proprietární zdroje streamování, jako je autoloader, který může přírůstkově zpracovávat cloudové soubory nákladově efektivním způsobem. Databricks také poskytuje konektory pro další oblíbené sběrnice zpráv, jako jsou Apache Kafka, Amazon Kinesis, Apache Pulsear a Google Pub/Sub.
Přírůstková transformace
Přírůstková transformace v Databricks se strukturovaným streamováním umožňuje zadat transformace do datových rámců se stejným rozhraním API jako dávkové dotazy, ale sleduje data napříč dávkami a agregovanými hodnotami v průběhu času, takže nemusíte. Nikdy není nutné znovu zpracovávat data, takže je rychlejší a nákladově efektivnější než opakované dávkové úlohy. Strukturované streamování vytváří datový proud, který může připojit k jímce, jako je Delta Lake, Kafka nebo jakýkoli jiný podporovaný konektor.
materializovaná zobrazení v Delta Live Tables jsou poháněna enzymovým motorem. Enzym stále postupně zpracovává váš zdroj, ale místo vytváření streamu vytvoří materializované zobrazení, což je předem vypočítaná tabulka, která ukládá výsledky dotazu, který zadáte. Enzym dokáže efektivně určit, jak nová data ovlivňují výsledky dotazu, a udržuje předem vypočítanou tabulku up-to-date.
Materializovaná zobrazení vytvářejí zobrazení nad agregací, která se vždy efektivně aktualizuje, takže například ve výše popsaném scénáři víte, že okno 8:00 do 9:00 má tři prvky.
Strukturované streamování nebo živé tabulky Delta?
Významným rozdílem mezi strukturovaným streamováním a dynamickými tabulkami Delta je způsob, jakým zprovozňujete dotazy streamování. Ve strukturovaném streamování ručně zadáte řadu konfigurací a budete muset dotazy ručně spojovat. Musíte explicitně spouštět dotazy, čekat na jejich ukončení, zrušit je při selhání a další akce. V Delta Live Tables deklarativně poskytujete své datové toky pro spuštění a systém zajišťuje jejich nepřetržitý provoz.
Delta Live Tables má také funkce, jako jsou materiálizovaná zobrazení, která efektivně a přírůstkově předvypočítávají transformace vašich dat.
Další informace o těchto funkcích najdete v tématu Streamování v Azure Databricks a Co jsou živé tabulky Delta?.
Další kroky
Vytvořte svůj první datový tok s Delta Live Tables. Viz Návod: Spusťte svůj první Delta Live Tables pipeline.
Spusťte první dotazy strukturovaného streamování v Databricks. Viz Spuštění první úlohy strukturovaného streamování.
Použijte materializované zobrazení. Viz Použití materializovaných zobrazení v Databricks SQL.