Pravidla datových typů SQL
Platí pro:![]() Databricks SQL
Databricks SQL ![]() Databricks Runtime
Databricks Runtime
Azure Databricks používá k řešení konfliktů mezi datovými typy několik pravidel:
- Povýšení bezpečně rozšíří typ na širší typ.
- Implicitní downcasting zúží typ. Opak povýšení.
- Implicitní křížové přetypování transformuje typ na typ jiné řady typů.
Můžete také explicitně přetypovat mezi mnoha typy:
- Přetypování funkce mezi většinou typů a vrací chyby, pokud není možné.
- try_cast funkce funguje jako funkce přetypování, ale při předání neplatných hodnot vrátí hodnotu NULL.
- Jiné předdefinované funkce přetypovávat mezi typy pomocí zadaných direktiv formátu.
Povýšení typu
Povýšení typu je proces přetypování typu do jiného typu stejné řady typů, která obsahuje všechny možné hodnoty původního typu.
Povýšení typu je proto bezpečná operace. Například TINYINT má rozsah od -128 do 127. Všechny jeho možné hodnoty mohou být bezpečně povýšeny na INTEGER.
Seznam priorit typů
Seznam priorit typů definuje, jestli lze hodnoty daného datového typu implicitně upřednostnět na jiný datový typ.
| Datový typ | Seznam priorit (od nejužšího po nejširší) |
|---|---|
| TINYINT | TINYINT -> SMALLINT -> INT -> BIGINT - DECIMAL ->> FLOAT (1) -> DOUBLE |
| SMALLINT | SMALLINT -> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| INT | INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| BIGINT | BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| DESETINNÝ | DESETINNÉ ČÍSLO -> FLOAT (1) -> DOUBLE |
| PLOUT | FLOAT (1) -> DOUBLE |
| DVOJITÝ | DVOJITÝ |
| DATE (Datum) | DATUM –> ČASOVÉ RAZÍTKO |
| ČASOVÉ RAZÍTKO | ČASOVÉ RAZÍTKO |
| POLE | MATICE (2) |
| BINÁRNÍ | BINÁRNÍ |
| BOOLEOVSKÝ | BOOLEOVSKÝ |
| INTERVAL | INTERVAL |
| MAPA | MAP (2) |
| ŘETĚZEC | STRING |
| STRUCT | STRUCT (2) |
| VARIANTA | VARIANT |
| OBJEKT | OBJEKT (3) |
(1) Pro nejméně běžné rozlišeníFLOAT typu se přeskočí, aby nedošlo ke ztrátě přesnosti.
(2) U komplexního typu se pravidlo priority rekurzivně vztahuje na jeho prvky komponent.
(3)OBJECT existuje pouze v rámci .VARIANT
Řetězce a HODNOTA NULL
Zvláštní pravidla platí pro STRING a nezatypovaná NULL:
-
NULLlze upřednostnět na jakýkoli jiný typ. -
STRINGmohou být povýšeny naBIGINT, ,BINARY,BOOLEANDATE,DOUBLE, ,INTERVALaTIMESTAMP. Pokud skutečnou hodnotu řetězce nelze přetypovat na nejméně běžný typ Azure Databricks, vyvolá chybu za běhu. Při povýšení naINTERVALhodnotu řetězce se musí shodovat s jednotkami intervalů.
Graf priorit typů
Toto je grafické znázornění hierarchie priorit, kombinování seznamu priorit typů a řetězců a pravidel NULL .
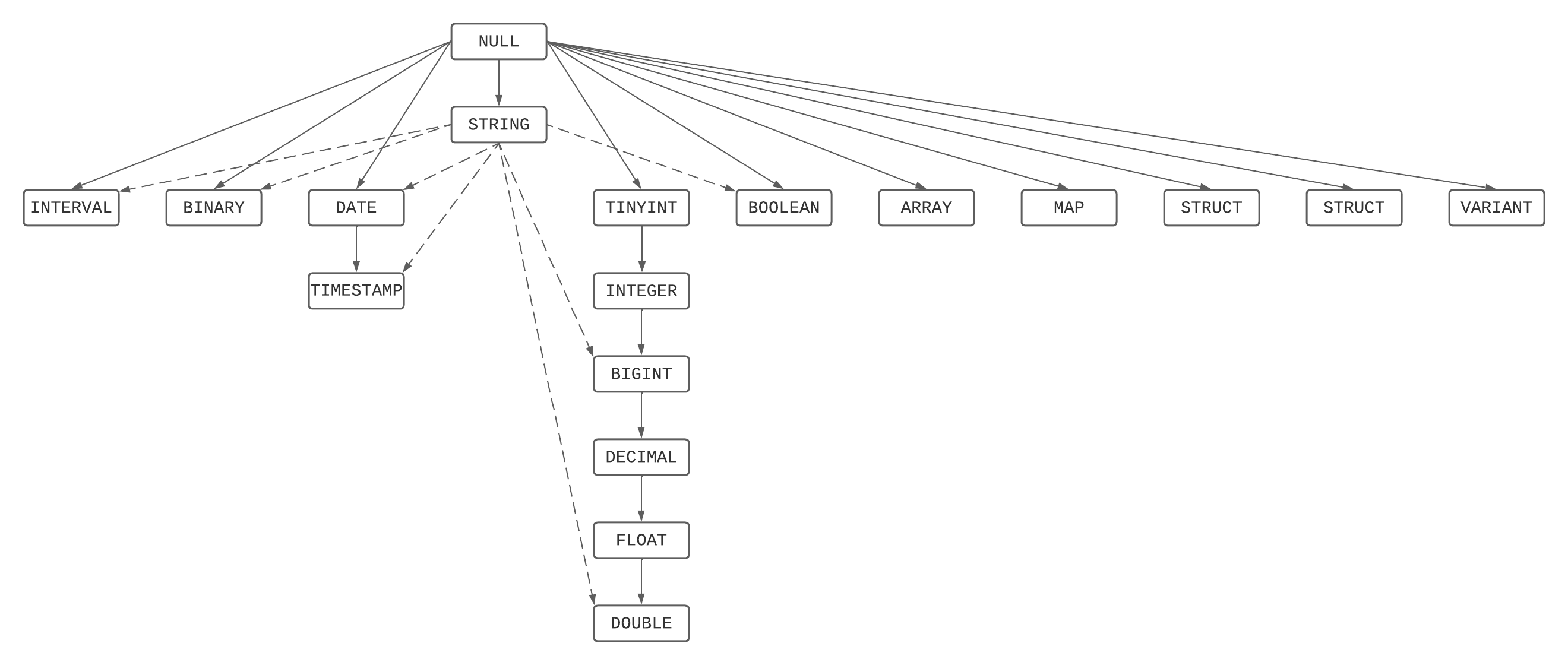
Nejméně běžné rozlišení typu
Nejmenší společný typ ze sady typů je nejužší typ dostupný z grafu priorit typů všemi prvky sady typů.
Nejméně běžné rozlišení typu se používá k:
- Rozhodněte se, jestli je možné vyvolat funkci, která očekává parametr daného typu, pomocí argumentu užšího typu.
- Odvodit typ argumentu pro funkci, která očekává typ sdíleného argumentu pro více parametrů, jako je například shod, in, least nebo greatest.
- Odvozujte typy operandů pro operátory, jako jsou aritmetické operace nebo porovnání.
- Odvozujte typ výsledku pro výrazy, jako je výraz velká a malá písmena.
- Odvození elementu, klíče nebo hodnotových typů pro maticové a mapové konstruktory
- Odvozujte typ výsledku operátorů UNION, INTERSECT nebo EXCEPT set.
Speciální pravidla se použijí, pokud se nejméně běžný typ přeloží na FLOAT. Pokud některý z typů přispívání je přesný číselný typ (TINYINT, SMALLINT, INTEGER, BIGINT, nebo DECIMAL) nejméně společný typ je vložen, aby DOUBLE se zabránilo potenciální ztrátě číslic.
Pokud je nejmenším běžným typem STRING, kolace se vypočítá podle pravidel priority kolace .
Implicitní downcasting a křížové vysílání
Azure Databricks využívá tyto formy implicitního přetypování pouze pro vyvolání funkce a operátoru a pouze tam, kde může jednoznačně určit záměr.
Implicitní downcasting
Implicitní downcasting automaticky přetypuje širší typ na užší typ, aniž byste museli explicitně zadat přetypování. Downcasting je pohodlný, ale nese riziko neočekávaných chyb za běhu, pokud skutečná hodnota není reprezentovatelná v úzkém typu.
Downcasting použije seznam priorit typů v obráceném pořadí.
Implicitní křížové vysílání
Implicitní křížové přetypování přetypuje hodnotu z jedné řady typů na jinou, aniž byste museli explicitně zadat přetypování.
Azure Databricks podporuje implicitní křížové vysílání z:
- Jakýkoli jednoduchý typ, s výjimkou
BINARY, doSTRING. - Do
STRINGlibovolného jednoduchého typu.
- Jakýkoli jednoduchý typ, s výjimkou
Přetypování funkce při vyvolání funkce
Vzhledem k vyřešené funkci nebo operátoru platí následující pravidla v pořadí, v jakém jsou uvedeny, pro každý parametr a dvojici argumentů:
Pokud je podporovaný typ parametru součástí grafu priority typu argumentu, Azure Databricks podporuje argument na tento typ parametru.
Ve většině případů popis funkce explicitně uvádí podporované typy nebo řetěz, například "jakýkoli číselný typ".
Například sin(výraz) funguje,
DOUBLEale přijme jakoukoli číselnou hodnotu.Pokud je očekávaný typ parametru
STRINGa argument je jednoduchý typ Azure Databricks crosscasts argumentu na typ parametru řetězce.Například substr(str, start, délka) očekává
str, že bude .STRINGMísto toho můžete předat číselný nebo typ data a času.Pokud je typ argumentu
STRINGa očekávaný typ parametru je jednoduchý typ, Azure Databricks křížově přetypuje řetězcový argument na nejširší podporovaný typ parametru.Například date_add(datum, dny) očekává a
DATEINTEGER.Pokud vyvoláte pomocí
date_add()dvouSTRINGs, Azure Databricks křížově zasměruje prvníSTRINGaDATEdruhýSTRINGna .INTEGERPokud funkce očekává číselný typ, například
INTEGERtyp neboDATEtyp, ale argument je obecnější typ, napříkladDOUBLETIMESTAMPnebo , Azure Databricks implicitně přetypuje argument na tento typ parametru.Například date_add(datum, dny) očekává a
DATEINTEGER.Pokud vyvoláte pomocí
date_add()a aTIMESTAMP, Azure Databricks downcastsBIGINTtoTIMESTAMPtím, že odebere časovou komponentuDATEa naBIGINT.INTEGERV opačném případě Azure Databricks vyvolá chybu.
Příklady
Funkce coalesce přijímá libovolnou sadu typů argumentů, pokud sdílejí nejméně společný typ.
Typ výsledku je nejmenším běžným typem argumentů.
-- The least common type of TINYINT and BIGINT is BIGINT
> SELECT typeof(coalesce(1Y, 1L, NULL));
BIGINT
-- INTEGER and DATE do not share a precedence chain or support crosscasting in either direction.
> SELECT typeof(coalesce(1, DATE'2020-01-01'));
Error: DATATYPE_MISMATCH.DATA_DIFF_TYPES
-- Both are ARRAYs and the elements have a least common type
> SELECT typeof(coalesce(ARRAY(1Y), ARRAY(1L)))
ARRAY<BIGINT>
-- The least common type of INT and FLOAT is DOUBLE
> SELECT typeof(coalesce(1, 1F))
DOUBLE
> SELECT typeof(coalesce(1L, 1F))
DOUBLE
> SELECT typeof(coalesce(1BD, 1F))
DOUBLE
-- The least common type between an INT and STRING is BIGINT
> SELECT typeof(coalesce(5, '6'));
BIGINT
-- The least common type is a BIGINT, but the value is not BIGINT.
> SELECT coalesce('6.1', 5);
Error: CAST_INVALID_INPUT
-- The least common type between a DECIMAL and a STRING is a DOUBLE
> SELECT typeof(coalesce(1BD, '6'));
DOUBLE
-- Two distinct explicit collations result in an error
> SELECT collation(coalesce('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE));
Error: COLLATION_MISMATCH.EXPLICIT
-- The resulting collation between two distinct implicit collations is indeterminate
> SELECT collation(coalesce(c1, c2))
FROM VALUES('hello' COLLATE UTF8_BINARY,
'world' COLLATE UNICODE) AS T(c1, c2);
NULL
-- The resulting collation between a explicit and an implicit collations is the explicit collation.
> SELECT collation(coalesce(c1 COLLATE UTF8_BINARY, c2))
FROM VALUES('hello',
'world' COLLATE UNICODE) AS T(c1, c2);
UTF8_BINARY
-- The resulting collation between an implicit and the default collation is the implicit collation.
> SELECT collation(coalesce(c1, ‘world’))
FROM VALUES('hello' COLLATE UNICODE) AS T(c1, c2);
UNICODE
-- The resulting collation between the default collation and the indeterminate collation is the default collation.
> SELECT collation(coalesce(coalesce(‘hello’ COLLATE UTF8_BINARY, ‘world’ COLLATE UNICODE), ‘world’));
UTF8_BINARY
Funkce podřetězce očekává argumenty typu STRING pro řetězec a INTEGER parametry začátku a délky.
-- Promotion of TINYINT to INTEGER
> SELECT substring('hello', 1Y, 2);
he
-- No casting
> SELECT substring('hello', 1, 2);
he
-- Casting of a literal string
> SELECT substring('hello', '1', 2);
he
-- Downcasting of a BIGINT to an INT
> SELECT substring('hello', 1L, 2);
he
-- Crosscasting from STRING to INTEGER
> SELECT substring('hello', str, 2)
FROM VALUES(CAST('1' AS STRING)) AS T(str);
he
-- Crosscasting from INTEGER to STRING
> SELECT substring(12345, 2, 2);
23
|| (CONCAT) umožňuje implicitní křížové přesměrování na řetězec.
-- A numeric is cast to STRING
> SELECT 'This is a numeric: ' || 5.4E10;
This is a numeric: 5.4E10
-- A date is cast to STRING
> SELECT 'This is a date: ' || DATE'2021-11-30';
This is a date: 2021-11-30
date_add lze vyvolat pomocí implicitního downcastingu TIMESTAMP nebo BIGINT z důvodu implicitního downcastu.
> SELECT date_add(TIMESTAMP'2011-11-30 08:30:00', 5L);
2011-12-05
date_add je možné vyvolat pomocí STRINGs z důvodu implicitního křížového vysílání.
> SELECT date_add('2011-11-30 08:30:00', '5');
2011-12-05