Červenec 2020
Tyto funkce a vylepšení platformy Azure Databricks byly vydány v červenci 2020.
Poznámka:
Verze jsou připraveny. Váš účet Azure Databricks se nemusí aktualizovat až do týdne po počátečním datu vydání.
Webový terminál (Public Preview)
4. července 2020: Verze 3.25
Webový terminál poskytuje pohodlný a vysoce interaktivní způsob, jak uživatelům s oprávněním PŘIPOJIT SE KE clusteru ke spouštění příkazů prostředí, včetně editorů, jako jsou Vim nebo Emacs. Příkladem použití webového terminálu je monitorování využití prostředků a instalace linuxových balíčků.
Podrobnosti najdete v tématu Spouštění příkazů prostředí ve webovém terminálu Azure Databricks.
Nová a bezpečnější architektura globálních inicializačních skriptů (Public Preview)
29. července – 4. srpna 2020: Verze 3.25
Nová globální architektura inicializačních skriptů přináší významná vylepšení starších globálních inicializačních skriptů:
- Inicializační skripty jsou bezpečnější a vyžadují oprávnění správce k vytvoření, zobrazení a odstranění.
- Protokolují se chyby spuštění související se skripty.
- Můžete nastavit pořadí provádění více inicializačních skriptů.
- Inicializační skripty můžou odkazovat na proměnné prostředí související s clustery.
- Inicializační skripty je možné vytvářet a spravovat pomocí stránky nastavení správce nebo nového rozhraní REST API globálních inicializačních skriptů.
Databricks doporučuje migrovat stávající starší globální inicializační skripty do nové architektury , abyste mohli tato vylepšení využít.
Podrobnosti najdete v tématu Globální inicializační skripty.
Seznamy přístupu IP adres nově ve fázi obecné dostupnosti
29. července – 4. srpna 2020: Verze 3.25
Rozhraní API pro přístup k ip adresě je teď obecně dostupné.
Verze GA obsahuje jednu změnu, což je přejmenování list_type hodnot:
WHITELISTnaALLOWBLACKLISTnaBLOCK
Pomocí rozhraní API pro přístup k IP adresám nakonfigurujte pracovní prostory Azure Databricks tak, aby se uživatelé připojili ke službě pouze prostřednictvím stávajících podnikových sítí se zabezpečeným hraničním zařízením. Správci Azure Databricks můžou pomocí rozhraní API seznamu IP adres definovat sadu schválených IP adres, včetně seznamů povolených a blokovaných adres. Veškerý příchozí přístup k webové aplikaci a rozhraním REST API vyžaduje, aby se uživatel připojil z autorizované IP adresy, která zaručuje, že k pracovním prostorům nebude možné přistupovat z veřejné sítě, jako je kavárna nebo letiště, pokud uživatelé nepoužívají síť VPN.
Tato funkce vyžaduje plán Premium.
Další informace najdete v tématu Konfigurace přístupových seznamů IP adres pro pracovní prostory.
Nové dialogové okno pro nahrávání souborů
29. července – 4. srpna 2020: Verze 3.25
Teď můžete nahrávat malé tabulkové datové soubory (například sdílené svazky clusteru) a přistupovat k nim z poznámkového bloku tak, že v nabídce Soubor poznámkového bloku vyberete Přidat data. Vygenerovaný kód ukazuje, jak načíst data do pandas nebo datových rámců. Správci můžou tuto funkci zakázat na kartě Upřesnit konzoly pro správu.
Další informace naleznete v tématu Procházení souborů v DBFS.
Filtr rozhraní API pro SCIM a vylepšení řazení
29. července – 4. června 2020: Verze 3.25
Rozhraní API SCIM teď obsahuje tato vylepšení filtrování a řazení:
- Uživatelé s rolí správce mohou filtrovat uživatele podle atributu
active. - Všichni uživatelé můžou výsledky řadit pomocí
sortByparametrů dotazu asortOrderdotazu. Výchozí způsob řazení je podle ID.
Nové oblasti služby Azure Government
25. července 2020
Azure Databricks se nedávno stal dostupným v oblastech US Gov Arizona a US Gov Virginia pro entity státní správy USA a jejich partnery.
Obecná dostupnost Databricks Runtime 7.1
21. července 2020
Databricks Runtime 7.1 přináší mnoho dalších funkcí a vylepšení oproti Databricks Runtime 7.0, včetně:
- Konektor Google BigQuery
%pippříkazy pro správu knihoven Pythonu nainstalovaných v relaci poznámkového bloku- Nainstalované Koalas
- Mnoho vylepšení Delta Lake, mezi která patří:
- Nastavení metadat potvrzení definovaných uživatelem
- Získání verze posledního potvrzení napsaného aktuálním potvrzením
SparkSession - Převod tabulek Parquet vytvořených strukturovaným streamováním pomocí transakčního
_spark_metadataprotokolu MERGE INTOvylepšení výkonu
Podrobnosti najdete v kompletní zprávě k vydání verze Databricks Runtime 7.1 (EoS ).
Obecná dostupnost Databricks Runtime 7.1 ML
21. července 2020
Databricks Runtime 7.1 pro Machine Learning je postaven na Databricks Runtime 7.1 a přináší následující nové funkce a změny knihovny:
- Příkazy magic pip a Conda jsou ve výchozím nastavení povolené
- spark-tensorflow-distributor: 0.1.0
- polštář 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
Podrobnosti najdete v kompletní zprávě k vydání verze Databricks Runtime 7.1 pro ML (EoS ).
Obecná dostupnost Databricks Runtime 7.1 Genomics
21. července 2020
Databricks Runtime 7.1 pro Genomics je postaven na Databricks Runtime 7.1 a přináší následující nové funkce:
- Transformace LOCO
- Funkce reshaping výstupu GloWGR
- RNASeq výstupy nezarovná zarovnání
Databricks Connect 7.1 (Public Preview)
17. července 2020
Databricks Connect 7.1 je teď ve verzi Public Preview.
Aktualizace rozhraní API pro seznam přístupu IP adres
15. července 2020: Verze 3.24
Změnily se následující vlastnosti rozhraní API pro přístupový seznam IP adres:
updator_user_idnaupdated_bycreator_user_idnacreated_by
Poznámkové bloky Pythonu teď podporují více výstupů na jednu buňku
15. července 2020: Verze 3.24
Poznámkové bloky Pythonu teď podporují více výstupů na buňku. To znamená, že v buňce můžete mít libovolný počet příkazů zobrazení, displayHTML nebo print. Využijte možnost zobrazit nezpracovaná data a graf ve stejné buňce nebo všechny výstupy, které byly úspěšné, než dojde k chybě.
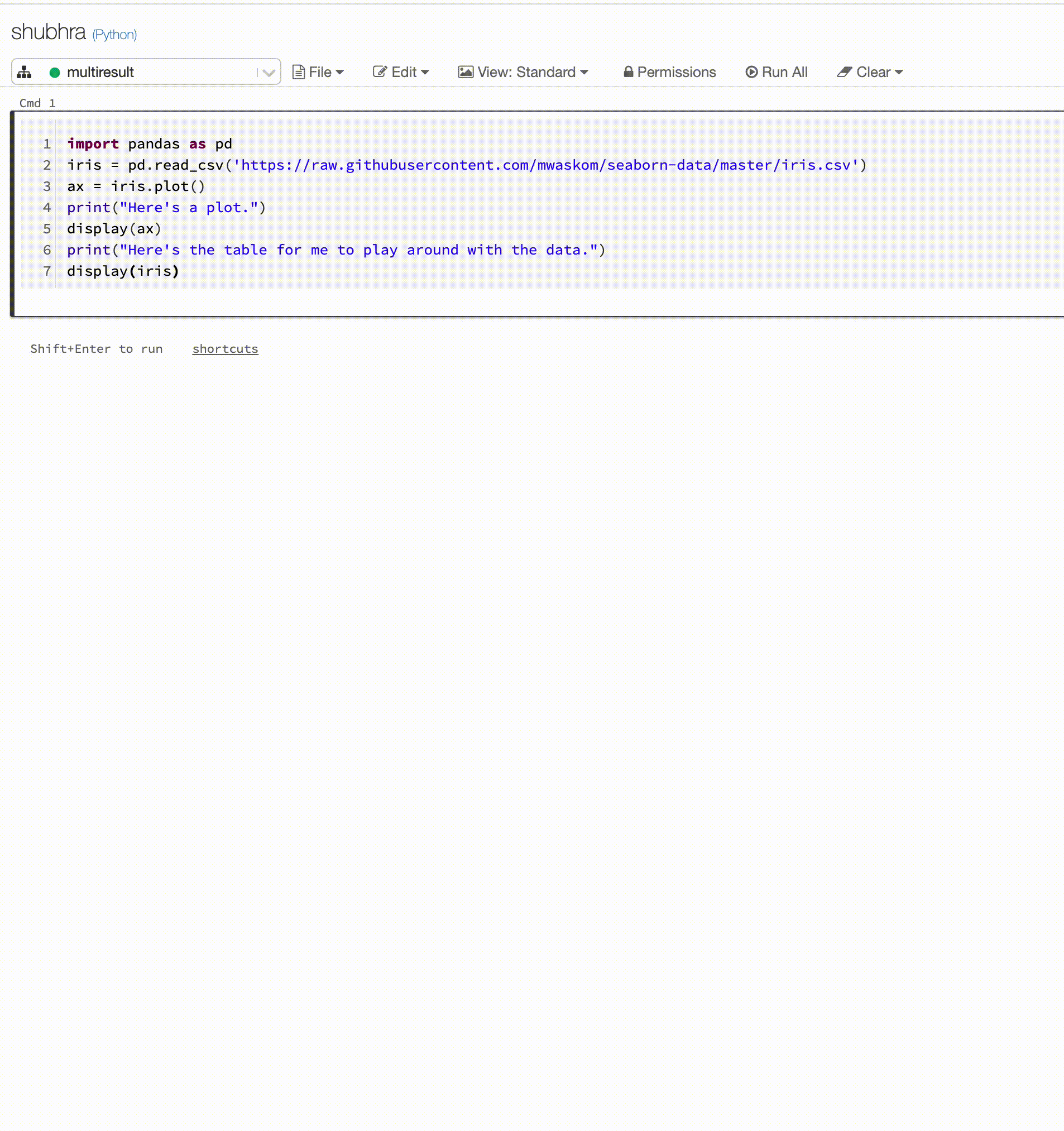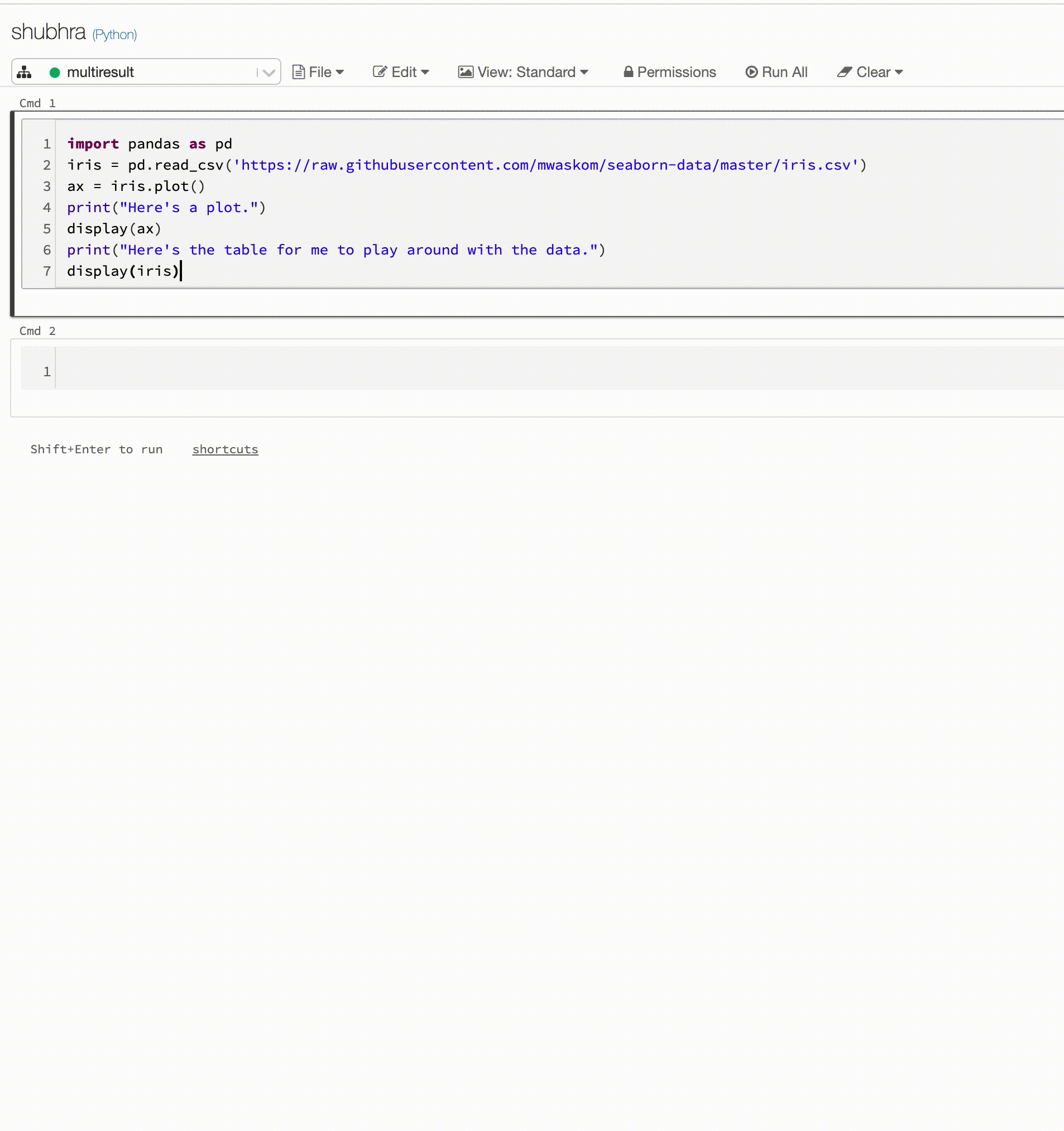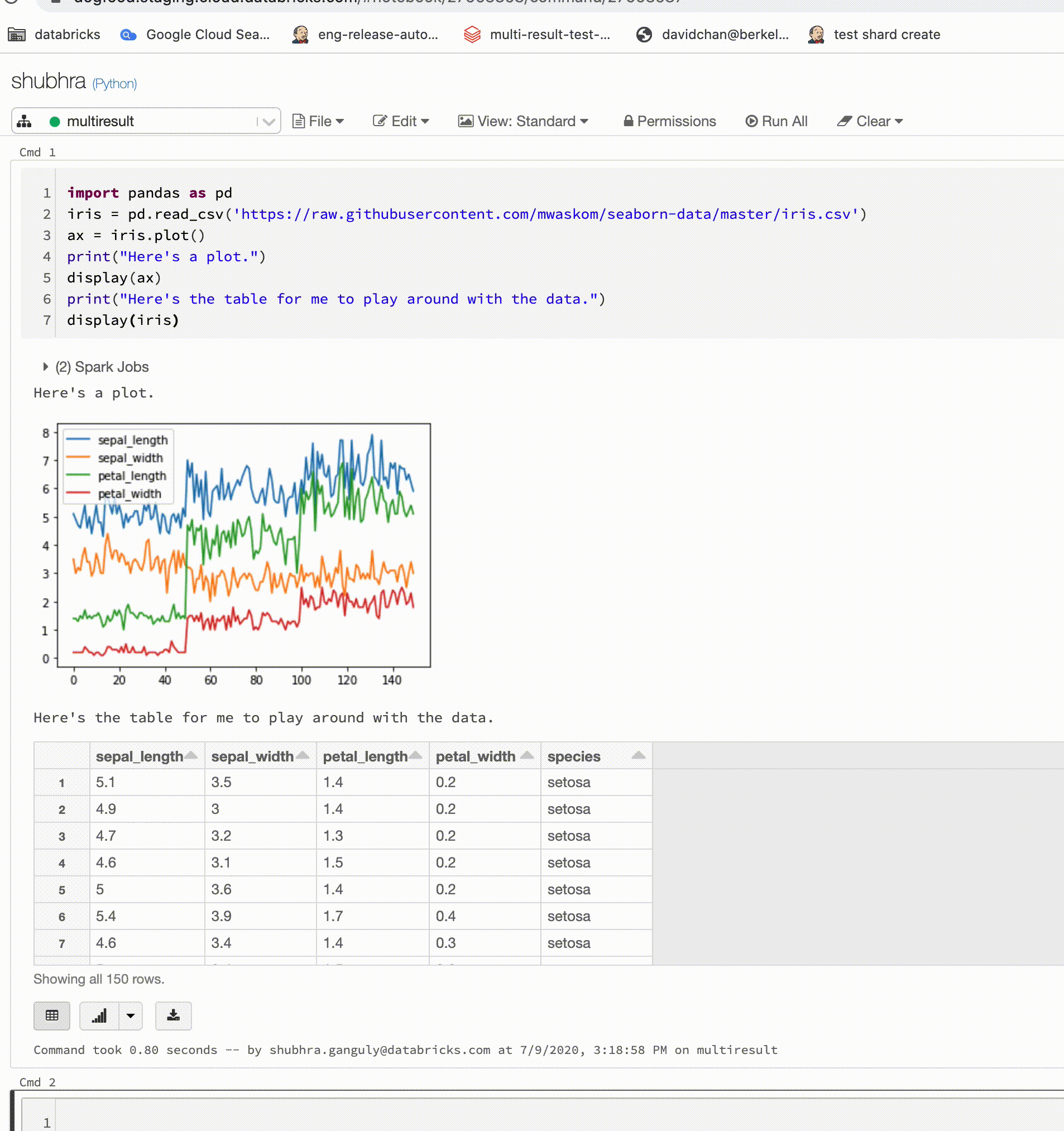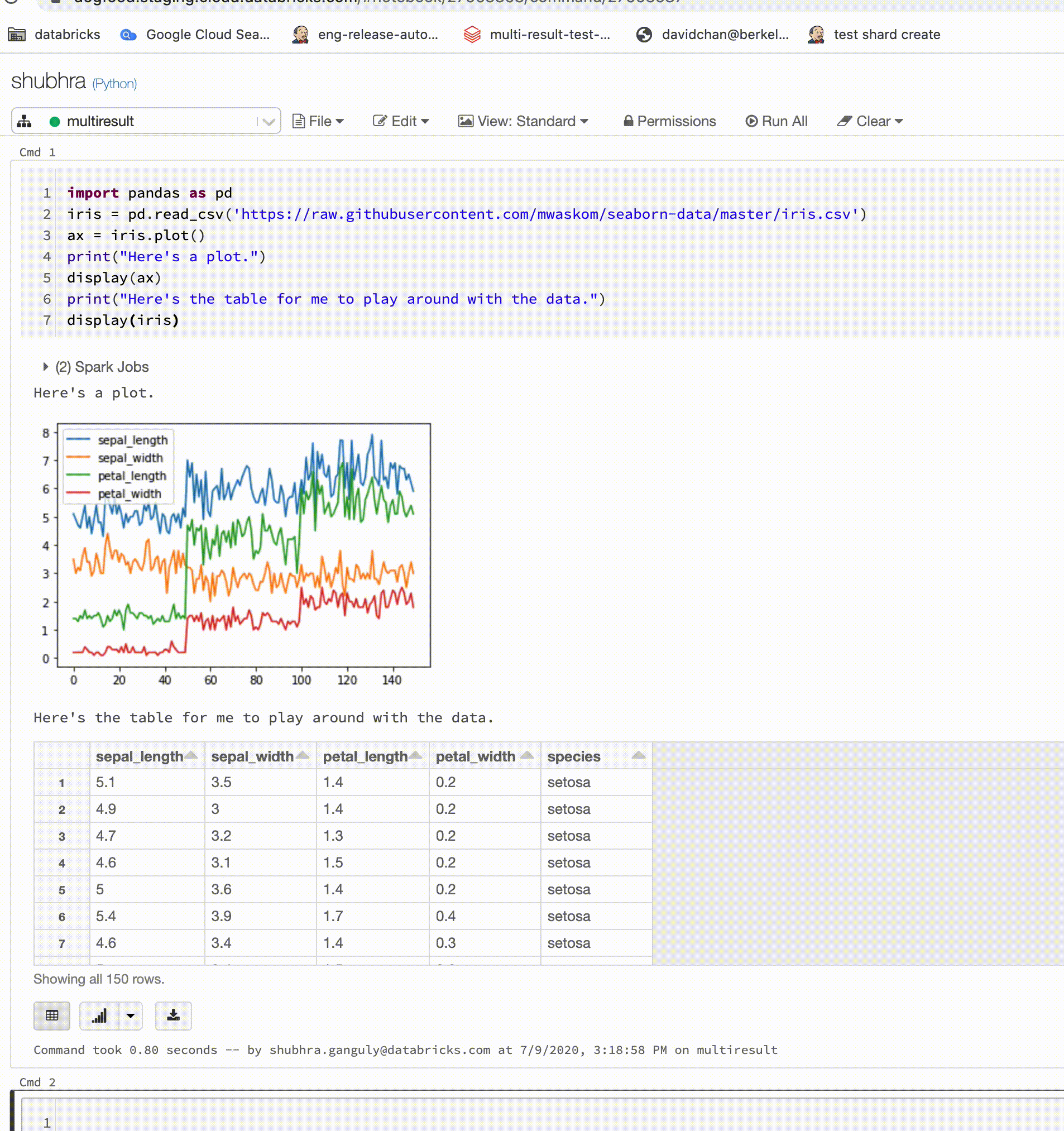
Tato funkce vyžaduje Databricks Runtime 7.1 nebo novější a ve výchozím nastavení je v Databricks Runtime 7.1 zakázaná. Povolte ho nastavením spark.databricks.workspace.multipleResults.enabled true.
Zobrazení kódu poznámkového bloku a buněk s výsledky vedle sebe
15. července 2020: Verze 3.24
Nová možnost zobrazení poznámkového bloku vedle sebe umožňuje zobrazit kód a výsledky vedle sebe. Tato možnost zobrazení spojí možnost Standardní (dříve Kód) a možnost Pouze výsledky.
Pozastavení plánů úloh
15. července 2020: Verze 3.24
Plány úloh teď obsahují tlačítka Pozastavit a Zrušit pozastavení , což usnadňuje pozastavení a obnovení úloh. Teď můžete provádět změny plánu úloh bez spuštění dalších úloh při provádění změn. Aktuální spuštění nebo spuštění aktivovaná spuštěním teď nejsou ovlivněny. Podrobnosti najdete v tématu Pozastavení a obnovení aktivačních událostí úlohy.
Ověření ID spuštění s využitím koncových bodů rozhraní API pro úlohy
15. července 2020: Verze 3.24
jobs/runs/output Koncové jobs/runs/cancel body rozhraní API teď ověřují platnost parametrurun_id. Pro neplatné parametry teď tyto koncové body rozhraní API vrací stavový kód HTTP 400 místo kódu 500.
Tokeny ID Microsoft Entra pro autorizaci do ga rozhraní REST API Databricks
15. července 2020: Verze 3.24
Použití tokenů ID Microsoft Entra k ověření v rozhraní API pracovního prostoru je nyní obecně dostupné. Tokeny ID Microsoft Entra umožňují automatizovat vytváření a nastavení nových pracovních prostorů. Instanční objekty jsou objekty aplikace v Microsoft Entra ID. K automatizaci pracovních postupů můžete také použít instanční objekty v pracovních prostorech Azure Databricks. Podrobnosti najdete v tématu Ověřování přístupu k prostředkům Azure Databricks.
Automatické formátování SQL v poznámkových blocích
15. července 2020: Verze 3.24
Buňky poznámkového bloku SQL teď můžete formátovat z klávesové zkratky, místní nabídky příkazů a nabídky Upravit poznámkový blok (vyberte Upravit > formát buněk SQL). Formátování SQL usnadňuje čtení a údržbu kódu s malým úsilím. Funguje pro poznámkové bloky SQL i %sql buňky.

Reprodukovatelné pořadí instalace pro knihovny Mavenu a knihovny CRAN
1. července 2020: Verze 3.23
Azure Databricks teď zpracovává knihovny Maven a CRAN v pořadí, v jakém byly nainstalované v clusteru.
Převzetí kontroly nad osobními přístupovými tokeny uživatelů s využitím rozhraní API pro správu tokenů (verze Public Preview)
1. července 2020: Verze 3.23
Správci Azure Databricks teď můžou pomocí rozhraní API pro správu tokenů spravovat osobní přístupové tokeny Azure Databricks uživatelů:
- Monitorování a odvolávání osobních přístupových tokenů uživatelů
- Řízení životnosti budoucích tokenů ve vašem pracovním prostoru
- Určete, kteří uživatelé můžou vytvářet a používat tokeny.
Viz Monitorování a odvolávání tokenů patového přístupu.
Obnovení oříznutých buněk poznámkového bloku
1. července 2020: Verze 3.23
Buňky poznámkového bloku, které byly vyjmuty, teď můžete obnovit pomocí klávesové zkratky (Z) nebo výběrem možnosti Upravit > vyjmout buňky zpět. Tato funkce je podobná této funkci pro vrácení odstraněných buněk zpět.
Přiřazení úloh MŮŽE SPRAVOVAT oprávnění uživatelům, kteří nejsou správci
1. července 2020: Verze 3.23
Teď můžete uživatelům a skupinám, kteří nejsou správci, přiřadit oprávnění CAN MANAGE pro úlohy. Tato úroveň oprávnění umožňuje uživatelům spravovat všechna nastavení úlohy, včetně přiřazování oprávnění, změny vlastníka a změny konfigurace clusteru (například přidávání knihoven a úpravy specifikace clusteru). Viz Řízení přístupu k úloze.
Uživatelé Azure Databricks, kteří nejsou správci, mohou zobrazovat a filtrovat podle uživatelského jména pomocí rozhraní API SCIM
1. července 2020: Verze 3.23
Uživatelé bez oprávnění správce teď můžou zobrazovat uživatelská jména a filtrovat uživatele podle uživatelského jména pomocí koncového bodu SCIM /Users.
Odkaz na zobrazení specifikace clusteru při zobrazování podrobností o spuštění úlohy
1. července 2020: Verze 3.23
Když teď zobrazíte podrobnosti o spuštění úlohy, můžete kliknutím na odkaz na stránku konfigurace clusteru zobrazit specifikaci clusteru. Dříve byste museli zkopírovat ID úlohy z adresy URL a přejít na seznam clusterů, abyste ho mohli vyhledat.