Připojení ke službě dbt Cloud
dbt (nástroj pro vytváření dat) je vývojové prostředí, které umožňuje datovým analytikům a datovým inženýrům transformovat data jednoduchým zápisem příkazů select. Dbt zpracovává přeměnu těchto příkazů select na tables a views. dbt zkompiluje váš kód do nezpracovaného SQL a potom tento kód spustí v zadané databázi v Azure Databricks. dbt podporuje vzory kódování na základě spolupráce a osvědčené postupy, jako je správa verzí, dokumentace a modularita.
dbt neextrahuje ani nenačítá data. Dbt se zaměřuje pouze na krok transformace s využitím architektury transformace po načtení. dbt předpokládá, že už máte kopii dat v databázi.
Tento článek se zaměřuje na dbt Cloud. dbt Cloud je vybaven podporou na klíč pro plánování úloh, CI/CD, obsluhou dokumentace, monitorováním a upozorňováním a integrovaným vývojovým prostředím (IDE).
K dispozici je také místní verze dbt s názvem dbt Core. dbt Core umožňuje psát kód dbt v textovém editoru nebo integrovaném vývojovém prostředí podle vašeho výběru na místním vývojovém počítači a pak spustit dbt z příkazového řádku. dbt Core obsahuje rozhraní příkazového řádku dbt (CLI). Rozhraní dbt CLI je zdarma a open-source. Další informace najdete v tématu Připojení k dbt Core.
Protože dbt Cloud a dbt Core můžou používat hostovaná úložiště Git (například na GitHubu, GitLabu nebo BitBucketu), můžete pomocí dbt Cloudu vytvořit projekt dbt a pak ho zpřístupnit uživatelům dbt Cloud a dbt Core. Další informace naleznete v tématu Vytvoření projektu dbt a Použití existujícího projektu na webu dbt.
Obecný přehled dbt najdete v následujícím videu YouTube (26 minut).
Připojení k dbt Cloudu pomocí Partnerského připojení
Tato část popisuje, jak připojit Databricks SQL Warehouse ke službě Dbt Cloud pomocí Partnerského připojení a pak udělit ke svým datům přístup ke čtení dbt Cloudu.
Rozdíly mezi standardem connections a dbt Cloud
Pokud se chcete připojit ke cloudu dbt pomocí Partnerského připojení, postupujte podle kroků v části Připojení k partnerům pro přípravu dat pomocí Partner Connect. Připojení dbt Cloud se liší od standardní přípravy a transformace dat connections následujícími způsoby:
- Kromě instančního objektu a osobního přístupového tokenu vytvoří Partner Connect ve výchozím nastavení SQL Warehouse (dříve koncový bod SQL) s názvem DBT_CLOUD_ENDPOINT .
Postup připojení
Pokud se chcete připojit ke službě dbt Cloud pomocí Partnerského připojení, postupujte takto:
Připojte se k partnerům přípravy dat pomocí Partner Connect.
Po připojení k dbt Cloudu se zobrazí řídicí panel dbt Cloud. Pokud chcete prozkoumat projekt dbt Cloud, v řádku nabídek vedle loga dbt select název vašeho účtu dbt z prvního rozevíracího seznamu, pokud se nezobrazí, a pak selectzkušební verzi Databricks Partner Connect projektu z druhé rozevírací nabídky, pokud se nezobrazí.
Tip
Pokud chcete zobrazit nastavení projektu, klikněte na nabídku Tři pruhy nebo hamburger, klikněte na > nastavení účtu a klikněte na název projektu. Chcete-li zobrazit nastavení připojení, klikněte na odkaz vedle připojení. Chcete-li změnit nastavení, klepněte na tlačítko Upravit.
Chcete-li zobrazit informace o osobním přístupovém tokenu Azure Databricks pro tento projekt, klikněte na ikonu 'osoba' na panelu nabídky, klikněte na Profil >Credentials> Zkušební Verze Databricks Partner Connecta poté klikněte na název projektu. Pokud chcete provést změnu, klikněte na Upravit.
Postup poskytnutí přístupu ke čtení dat dbt Cloud
Partner Connect dává instančnímu objektu DBT_CLOUD_USER oprávnění pouze k vytvoření ve výchozím catalog. Postupujte podle těchto kroků v pracovním prostoru Azure Databricks a udělte DBT_CLOUD_USER instančnímu objektu přístup ke čtení dat, která zvolíte.
Upozorňující
Tyto kroky můžete přizpůsobit tak, aby dbt Cloud získal další přístup napříč catalogs, databázemi a tables v rámci vašeho pracovního prostoru. Jako osvědčený postup zabezpečení však Databricks důrazně doporučuje udělit přístup pouze k jednotlivým tables, které potřebujete, aby hlavní služební objekt DBT_CLOUD_USER mohl fungovat s těmito tables, a to pouze pro čtení.
Na bočním panelu klikněte na ikonu
 Catalog.
Catalog.Select SQL Warehouse (DBT_CLOUD_ENDPOINT) v rozevíracím list v pravém horním rohu.
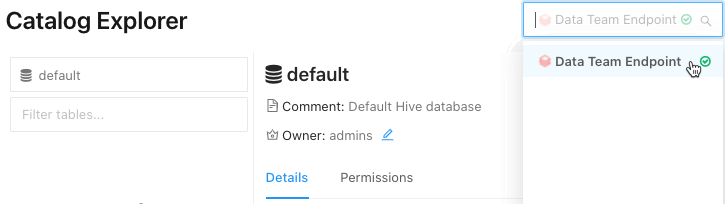
- V části Catalog Exploreru, selectcatalog, která obsahuje databázi pro váš table.
- Select databázi, která obsahuje váš table.
- Select vaše table.
Tip
Pokud ve výčtu nevidíte svůj catalog, databázi nebo table, zadejte libovolnou část názvu do polí Select Catalog, Select Databáze, nebo do polí Filtr tables, abyste omezili počet list.

Klikněte na Oprávnění.
Klikněte na Grant.
Chcete-li Typ přidat více uživatelů nebo skupin, selectDBT_CLOUD_USER. Toto je instanční objekt Azure Databricks, který pro vás partner Connect vytvořil v předchozí části.
Tip
Pokud DBT_CLOUD_USERnevidíte, začněte psát
DBT_CLOUD_USERdo pole Přidejte další uživatele nebo skupiny, dokud se neobjeví v list, a poté ho select.Grant přístup jen pro čtení výběrem
SELECTaREAD METADATA.Klikněte na OK.
Opakujte kroky 4 až 9 pro každou další table, kterým chcete udělit přístup ke čtení dbt Cloud.
Řešení potíží s připojením dbt Cloud
Pokud někdo odstraní projekt v dbt Cloudu pro tento účet a vy kliknete na dlaždici dbt , zobrazí se chybová zpráva s oznámením, že projekt nebyl nalezen. Chcete-li tento problém vyřešit, klepněte na tlačítko Odstranit připojení a potom začněte od začátku tohoto postupu vytvořit připojení znovu.
Ruční připojení ke službě dbt Cloud
Tato část popisuje, jak připojit cluster Azure Databricks nebo databricks SQL Warehouse v pracovním prostoru Azure Databricks ke službě Dbt Cloud.
Důležité
Databricks doporučuje připojení ke službě SQL Warehouse. Pokud nemáte nárok na přístup k Sql Databricks nebo pokud chcete spouštět modely Pythonu, můžete se místo toho připojit ke clusteru.
Požadavky
Cluster nebo SQL Warehouse v pracovním prostoru Azure Databricks
- Referenční informace ke konfiguraci výpočetních prostředků
- Vytvořte SQL Warehouse.
Podrobnosti o připojení pro váš cluster nebo SQL Warehouse, konkrétně název hostitele serveru server, porta cesta HTTPvalues.
Osobní přístupový token Azure Databricks nebo token Microsoft Entra ID (dříve Azure Active Directory). Pokud chcete vytvořit osobní přístupový token, postupujte podle kroků v osobních přístupových tokenech Azure Databricks pro uživatele pracovního prostoru.
Poznámka:
Osvědčeným postupem při ověřování pomocí automatizovaných nástrojů, systémů, skriptů a aplikací doporučuje Databricks místo uživatelů pracovního prostoru používat tokeny patního přístupu, které patří instančním objektům . Pokud chcete vytvořit tokeny pro instanční objekty, přečtěte si téma Správa tokenů instančního objektu.
Pro připojení dbt Cloudu k datům spravovaným Unity Catalogje vyžadována dbt verze 1.1 nebo vyšší.
Kroky v tomto článku vytvoří nové prostředí, které používá nejnovější verzi dbt. Informace o upgradu verze dbt pro existující prostředí najdete v dokumentaci k upgradu na nejnovější verzi dbt v cloudu .
Krok 1: Registrace do dbt Cloudu
Přejděte do dbt Cloudu – Zaregistrujte se a zadejte svůj e-mail, jméno a informace o společnosti. Vytvořte heslo a klikněte na Vytvořit můj účet.
Krok 2: Vytvoření projektu dbt
V tomto kroku vytvoříte projekt dbt, který obsahuje připojení ke clusteru Azure Databricks nebo SQL Warehouse, úložišti, které obsahuje váš zdrojový kód, a jedno nebo více prostředí (například testovací a produkční prostředí).
- Přihlaste se ke službě dbt Cloud.
- Klikněte na ikonu nastavení a potom klikněte na Nastavení účtu.
- Klikněte na tlačítko Nový projekt.
- Do pole Název zadejte jedinečný název projektu a klikněte na tlačítko Pokračovat.
-
Select výpočetní připojení Azure Databricks z rozevírací nabídky Vyberte připojení nebo vytvořte nové připojení
Klepněte na tlačítko Přidat nové připojení.
Na nové kartě se otevře průvodce Přidat nové připojení.
Klikněte na Databricksa potom klikněte na Další.
Poznámka:
Databricks doporučuje místo
dbt-sparkpoužívatdbt-databricks, která podporuje CatalogUnity . Ve výchozím nastavení používajídbt-databricksnové projekty . Pokud chcete migrovat existující projekt dodbt-databricks, přečtěte si téma Migrace z dbt-spark do dbt-databricks v dokumentaci dbt.V části Nastavení pro název hostitele serveru zadejte hodnotu názvu hostitele serveru z požadavků.
Do pole Cesta HTTP zadejte hodnotu cesty HTTP z požadavků.
Pokud je váš pracovní prostor Unity Catalogpovolený, zadejte v části Volitelná nastavenínázev catalog, který má dbt použít.
Klikněte na Uložit.
Vraťte se do průvodce Nový projekt a select připojení, které jste právě vytvořili z rozevírací nabídky Připojení.
- V části Development Credentials( pro Token) zadejte osobní přístupový token nebo token Microsoft Entra ID z požadavků.
- Pro Schemazadejte název schemawhere, který chcete, aby dbt vytvořilo jako tables a views.
- Klikněte na Otestovat připojení.
- Pokud se test úspěšně dokončí, klikněte na Uložit.
Další informace naleznete v tématu Připojení k rozhraní DATAbricks ODBC na webu dbt.
Tip
Chcete-li zobrazit nebo změnit nastavení pro tento projekt nebo úplně odstranit projekt, klikněte na ikonu nastavení, klikněte na položku > nastavení účtu a klikněte na název projektu. Chcete-li změnit nastavení, klepněte na tlačítko Upravit. Chcete-li projekt odstranit, klepněte na tlačítko Upravit > odstranit projekt.
Chcete-li zobrazit nebo změnit hodnotu osobního přístupového tokenu Azure Databricks pro tento projekt, klikněte na ikonu „osoba“, klikněte na Profil >Credentialsa klikněte na název projektu. Pokud chcete provést změnu, klikněte na Upravit.
Po připojení ke clusteru Azure Databricks nebo službě Databricks SQL Warehouse postupujte podle pokynů na obrazovce a nastavte úložiště a potom klikněte na Pokračovat.
Po nastavení set úložiště podle pokynů na obrazovce pozvěte uživatele, a poté klikněte na Dokončit. Nebo klikněte na Přeskočit a dokončit.
Kurz
V této části použijete projekt dbt Cloud k práci s některými ukázkovými daty. V této části se předpokládá, že jste projekt už vytvořili a máte otevřené integrované vývojové prostředí dbt Cloud pro tento projekt.
Krok 1: Vytvoření a spuštění modelů
V tomto kroku použijete prostředí IDE cloudu dbt k vytvoření a spuštění modelů , což jsou příkazy select, které vytvářejí nové zobrazení (výchozí) nebo nové table v databázi na základě existujících dat ve stejné databázi. Tento postup vytvoří model na základě vzorku diamondstable z datových sad vzorku .
Pomocí následujícího kódu vytvořte tento table.
DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds USING CSV OPTIONS (path "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header "true")
Tento postup předpokládá, že tato table už byla vytvořena v databázi default ve vašem pracovním prostoru.
Otevřete projekt a v horní části uživatelského rozhraní klikněte na Vývoj .
Klikněte na Inicializovat projekt dbt.
Klepněte na tlačítko Potvrzení a sync, zadejte zprávu potvrzení a klepněte na tlačítko Potvrzení.
Klikněte na Vytvořit větev, zadejte název větve a potom klikněte na Odeslat.
Vytvořte první model: Klikněte na Vytvořit nový soubor.
V textovém editoru zadejte následující příkaz SQL. Tento příkaz vybere pouze karát, brus, barvu a čistotu podrobností o každém diamantu z
diamondstable. Blokconfigdává dbt pokyn k vytvoření table v databázi na základě tohoto příkazu.{{ config( materialized='table', file_format='delta' ) }}select carat, cut, color, clarity from diamondsTip
Další
configmožnosti, jakomergeje přírůstková strategie, najdete v dokumentaci k databázi v konfiguraci Databricks.Klikněte na Uložit jako.
Jako název souboru zadejte
models/diamonds_four_cs.sqla klepněte na tlačítko Vytvořit.Vytvoření druhého modelu: Klikněte
 (Vytvořit nový soubor) v pravém horním rohu.
(Vytvořit nový soubor) v pravém horním rohu.V textovém editoru zadejte následující příkaz SQL. Tento příkaz vybere jedinečné values ze
colorscolumn vdiamonds_four_cstablea seřadí výsledky podle abecedy od prvního do posledního. Vzhledem k tomu, že neexistuje žádnýconfigblok, tento model dává dbt pokyn k vytvoření zobrazení v databázi na základě tohoto příkazu.select distinct color from diamonds_four_cs sort by color ascKlikněte na Uložit jako.
Jako název souboru zadejte
models/diamonds_list_colors.sqla klepněte na tlačítko Vytvořit.Vytvoření třetího modelu: Klikněte
(Vytvořit nový soubor) v pravém horním rohu.V textovém editoru zadejte následující příkaz SQL. Tento výpis zprůměruje ceny diamantů podle barvy a výsledky seřadí podle průměrné ceny od nejvyšší po nejnižší. Tento model dává dbt pokyn k vytvoření zobrazení v databázi na základě tohoto příkazu.
select color, avg(price) as price from diamonds group by color order by price descKlikněte na Uložit jako.
Jako název souboru zadejte
models/diamonds_prices.sqla klikněte na Vytvořit.Spusťte modely: Na příkazovém řádku spusťte
dbt runpříkaz s cestami ke třem předchozím souborům. V databázidefaultvytvoří dbt jeden table pojmenovanýdiamonds_four_csa dva views pojmenovanédiamonds_list_colorsadiamonds_prices. dbt získá toto zobrazení a table názvy ze souvisejících.sqlnázvů souborů.dbt run --model models/diamonds_four_cs.sql models/diamonds_list_colors.sql models/diamonds_prices.sql... ... | 1 of 3 START table model default.diamonds_four_cs.................... [RUN] ... | 1 of 3 OK created table model default.diamonds_four_cs............... [OK ...] ... | 2 of 3 START view model default.diamonds_list_colors................. [RUN] ... | 2 of 3 OK created view model default.diamonds_list_colors............ [OK ...] ... | 3 of 3 START view model default.diamonds_prices...................... [RUN] ... | 3 of 3 OK created view model default.diamonds_prices................. [OK ...] ... | ... | Finished running 1 table model, 2 view models ... Completed successfully Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3Spusťte následující kód SQL a list informace o novém views a select všechny řádky z table a views.
Pokud se připojujete ke clusteru, můžete tento kód SQL spustit z poznámkového bloku připojeného ke clusteru a zadat SQL jako výchozí jazyk poznámkového bloku. Pokud se připojujete ke službě SQL Warehouse, můžete tento kód SQL spustit z dotazu.
SHOW views IN default+-----------+----------------------+-------------+ | namespace | viewName | isTemporary | +===========+======================+=============+ | default | diamonds_list_colors | false | +-----------+----------------------+-------------+ | default | diamonds_prices | false | +-----------+----------------------+-------------+SELECT * FROM diamonds_four_cs+-------+---------+-------+---------+ | carat | cut | color | clarity | +=======+=========+=======+=========+ | 0.23 | Ideal | E | SI2 | +-------+---------+-------+---------+ | 0.21 | Premium | E | SI1 | +-------+---------+-------+---------+ ...SELECT * FROM diamonds_list_colors+-------+ | color | +=======+ | D | +-------+ | E | +-------+ ...SELECT * FROM diamonds_prices+-------+---------+ | color | price | +=======+=========+ | J | 5323.82 | +-------+---------+ | I | 5091.87 | +-------+---------+ ...
Krok 2: Vytvoření a spuštění složitějších modelů
V tomto kroku vytvoříte složitější modely pro set souvisejících dat tables. Tato data tables obsahují informace o fiktivní sportovní lize tří týmů hrajících sezónu šesti her. Tento postup vytvoří data tables, vytvoří modely a spustí modely.
Spuštěním následujícího kódu SQL vytvořte potřebná data tables.
Pokud se připojujete ke clusteru, můžete tento kód SQL spustit z poznámkového bloku připojeného ke clusteru a zadat SQL jako výchozí jazyk poznámkového bloku. Pokud se připojujete ke službě SQL Warehouse, můžete tento kód SQL spustit z dotazu.
tables a views v tomto kroku začínají s
zzz_, aby je bylo možné v tomto příkladu identifikovat. Tento vzor nemusíte dodržovat pro vaše vlastní tables a views.DROP TABLE IF EXISTS zzz_game_opponents; DROP TABLE IF EXISTS zzz_game_scores; DROP TABLE IF EXISTS zzz_games; DROP TABLE IF EXISTS zzz_teams; CREATE TABLE zzz_game_opponents ( game_id INT, home_team_id INT, visitor_team_id INT ) USING DELTA; INSERT INTO zzz_game_opponents VALUES (1, 1, 2); INSERT INTO zzz_game_opponents VALUES (2, 1, 3); INSERT INTO zzz_game_opponents VALUES (3, 2, 1); INSERT INTO zzz_game_opponents VALUES (4, 2, 3); INSERT INTO zzz_game_opponents VALUES (5, 3, 1); INSERT INTO zzz_game_opponents VALUES (6, 3, 2); -- Result: -- +---------+--------------+-----------------+ -- | game_id | home_team_id | visitor_team_id | -- +=========+==============+=================+ -- | 1 | 1 | 2 | -- +---------+--------------+-----------------+ -- | 2 | 1 | 3 | -- +---------+--------------+-----------------+ -- | 3 | 2 | 1 | -- +---------+--------------+-----------------+ -- | 4 | 2 | 3 | -- +---------+--------------+-----------------+ -- | 5 | 3 | 1 | -- +---------+--------------+-----------------+ -- | 6 | 3 | 2 | -- +---------+--------------+-----------------+ CREATE TABLE zzz_game_scores ( game_id INT, home_team_score INT, visitor_team_score INT ) USING DELTA; INSERT INTO zzz_game_scores VALUES (1, 4, 2); INSERT INTO zzz_game_scores VALUES (2, 0, 1); INSERT INTO zzz_game_scores VALUES (3, 1, 2); INSERT INTO zzz_game_scores VALUES (4, 3, 2); INSERT INTO zzz_game_scores VALUES (5, 3, 0); INSERT INTO zzz_game_scores VALUES (6, 3, 1); -- Result: -- +---------+-----------------+--------------------+ -- | game_id | home_team_score | visitor_team_score | -- +=========+=================+====================+ -- | 1 | 4 | 2 | -- +---------+-----------------+--------------------+ -- | 2 | 0 | 1 | -- +---------+-----------------+--------------------+ -- | 3 | 1 | 2 | -- +---------+-----------------+--------------------+ -- | 4 | 3 | 2 | -- +---------+-----------------+--------------------+ -- | 5 | 3 | 0 | -- +---------+-----------------+--------------------+ -- | 6 | 3 | 1 | -- +---------+-----------------+--------------------+ CREATE TABLE zzz_games ( game_id INT, game_date DATE ) USING DELTA; INSERT INTO zzz_games VALUES (1, '2020-12-12'); INSERT INTO zzz_games VALUES (2, '2021-01-09'); INSERT INTO zzz_games VALUES (3, '2020-12-19'); INSERT INTO zzz_games VALUES (4, '2021-01-16'); INSERT INTO zzz_games VALUES (5, '2021-01-23'); INSERT INTO zzz_games VALUES (6, '2021-02-06'); -- Result: -- +---------+------------+ -- | game_id | game_date | -- +=========+============+ -- | 1 | 2020-12-12 | -- +---------+------------+ -- | 2 | 2021-01-09 | -- +---------+------------+ -- | 3 | 2020-12-19 | -- +---------+------------+ -- | 4 | 2021-01-16 | -- +---------+------------+ -- | 5 | 2021-01-23 | -- +---------+------------+ -- | 6 | 2021-02-06 | -- +---------+------------+ CREATE TABLE zzz_teams ( team_id INT, team_city VARCHAR(15) ) USING DELTA; INSERT INTO zzz_teams VALUES (1, "San Francisco"); INSERT INTO zzz_teams VALUES (2, "Seattle"); INSERT INTO zzz_teams VALUES (3, "Amsterdam"); -- Result: -- +---------+---------------+ -- | team_id | team_city | -- +=========+===============+ -- | 1 | San Francisco | -- +---------+---------------+ -- | 2 | Seattle | -- +---------+---------------+ -- | 3 | Amsterdam | -- +---------+---------------+Vytvořte první model: Klikněte
(Vytvořit nový soubor) v pravém horním rohu.V textovém editoru zadejte následující příkaz SQL. Tento příkaz vytvoří table, který poskytuje podrobnosti o jednotlivých hrách, jako jsou názvy týmů a skóre. Blok
configdává dbt pokyn k vytvoření table v databázi na základě tohoto příkazu.-- Create a table that provides full details for each game, including -- the game ID, the home and visiting teams' city names and scores, -- the game winner's city name, and the game date.{{ config( materialized='table', file_format='delta' ) }}-- Step 4 of 4: Replace the visitor team IDs with their city names. select game_id, home, t.team_city as visitor, home_score, visitor_score, -- Step 3 of 4: Display the city name for each game's winner. case when home_score > visitor_score then home when visitor_score > home_score then t.team_city end as winner, game_date as date from ( -- Step 2 of 4: Replace the home team IDs with their actual city names. select game_id, t.team_city as home, home_score, visitor_team_id, visitor_score, game_date from ( -- Step 1 of 4: Combine data from various tables (for example, game and team IDs, scores, dates). select g.game_id, go.home_team_id, gs.home_team_score as home_score, go.visitor_team_id, gs.visitor_team_score as visitor_score, g.game_date from zzz_games as g, zzz_game_opponents as go, zzz_game_scores as gs where g.game_id = go.game_id and g.game_id = gs.game_id ) as all_ids, zzz_teams as t where all_ids.home_team_id = t.team_id ) as visitor_ids, zzz_teams as t where visitor_ids.visitor_team_id = t.team_id order by game_date descKlikněte na Uložit jako.
Jako název souboru zadejte
models/zzz_game_details.sqla klepněte na tlačítko Vytvořit.Vytvoření druhého modelu: Klikněte
(Vytvořit nový soubor) v pravém horním rohu.V textovém editoru zadejte následující příkaz SQL. Tento příkaz vytvoří zobrazení se seznamem záznamů o výhrách týmu pro sezónu.
-- Create a view that summarizes the season's win and loss records by team. -- Step 2 of 2: Calculate the number of wins and losses for each team. select winner as team, count(winner) as wins, -- Each team played in 4 games. (4 - count(winner)) as losses from ( -- Step 1 of 2: Determine the winner and loser for each game. select game_id, winner, case when home = winner then visitor else home end as loser from zzz_game_details ) group by winner order by wins descKlikněte na Uložit jako.
Jako název souboru zadejte
models/zzz_win_loss_records.sqla klepněte na tlačítko Vytvořit.Spusťte modely: Na příkazovém řádku spusťte
dbt runpříkaz s cestami ke dvěma předchozím souborům. V databázidefault(jak je uvedeno v nastavení projektu) vytvoří dbt jeden table pojmenovanýzzz_game_detailsa jedno zobrazení s názvemzzz_win_loss_records. dbt získá názvy zobrazení a názvy table ze souvisejících názvů souborů.sql.dbt run --model models/zzz_game_details.sql models/zzz_win_loss_records.sql... ... | 1 of 2 START table model default.zzz_game_details.................... [RUN] ... | 1 of 2 OK created table model default.zzz_game_details............... [OK ...] ... | 2 of 2 START view model default.zzz_win_loss_records................. [RUN] ... | 2 of 2 OK created view model default.zzz_win_loss_records............ [OK ...] ... | ... | Finished running 1 table model, 1 view model ... Completed successfully Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2Spusťte následující kód SQL pro list informace o novém zobrazení a select všechny řádky z table a tohoto zobrazení.
Pokud se připojujete ke clusteru, můžete tento kód SQL spustit z poznámkového bloku připojeného ke clusteru a zadat SQL jako výchozí jazyk poznámkového bloku. Pokud se připojujete ke službě SQL Warehouse, můžete tento kód SQL spustit z dotazu.
SHOW VIEWS FROM default LIKE 'zzz_win_loss_records';+-----------+----------------------+-------------+ | namespace | viewName | isTemporary | +===========+======================+=============+ | default | zzz_win_loss_records | false | +-----------+----------------------+-------------+SELECT * FROM zzz_game_details;+---------+---------------+---------------+------------+---------------+---------------+------------+ | game_id | home | visitor | home_score | visitor_score | winner | date | +=========+===============+===============+============+===============+===============+============+ | 1 | San Francisco | Seattle | 4 | 2 | San Francisco | 2020-12-12 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 2 | San Francisco | Amsterdam | 0 | 1 | Amsterdam | 2021-01-09 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 3 | Seattle | San Francisco | 1 | 2 | San Francisco | 2020-12-19 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 4 | Seattle | Amsterdam | 3 | 2 | Seattle | 2021-01-16 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 5 | Amsterdam | San Francisco | 3 | 0 | Amsterdam | 2021-01-23 | +---------+---------------+---------------+------------+---------------+---------------+------------+ | 6 | Amsterdam | Seattle | 3 | 1 | Amsterdam | 2021-02-06 | +---------+---------------+---------------+------------+---------------+---------------+------------+SELECT * FROM zzz_win_loss_records;+---------------+------+--------+ | team | wins | losses | +===============+======+========+ | Amsterdam | 3 | 1 | +---------------+------+--------+ | San Francisco | 2 | 2 | +---------------+------+--------+ | Seattle | 1 | 3 | +---------------+------+--------+
Krok 3: Vytvoření a spuštění testů
V tomto kroku vytvoříte testy, což jsou kontrolní výrazy, které vytvoříte pro své modely. Když tyto testy spustíte, dbt vám řekne, jestli každý test v projektu projde nebo selže.
Existují dva typy testů. Schema testy, napsané v YAML, vrátí počet záznamů, které neprojdou ověřením. Pokud je toto číslo nula, všechny záznamy projdou, a proto testy projdou. Datové testy jsou specifické dotazy, které musí vrátit nulové záznamy, které se mají předat.
Vytvořte schema testy: Klikněte na ikonu
(Vytvořit nový soubor) v pravém horním rohu.V textovém editoru zadejte následující obsah. Tento soubor obsahuje schema testy, které určují, zda zadané columns mají jedinečné values, nemají hodnotu null, mají pouze zadanou valuesnebo kombinaci.
version: 2 models: - name: zzz_game_details columns: - name: game_id tests: - unique - not_null - name: home tests: - not_null - accepted_values: values: ['Amsterdam', 'San Francisco', 'Seattle'] - name: visitor tests: - not_null - accepted_values: values: ['Amsterdam', 'San Francisco', 'Seattle'] - name: home_score tests: - not_null - name: visitor_score tests: - not_null - name: winner tests: - not_null - accepted_values: values: ['Amsterdam', 'San Francisco', 'Seattle'] - name: date tests: - not_null - name: zzz_win_loss_records columns: - name: team tests: - unique - not_null - relationships: to: ref('zzz_game_details') field: home - name: wins tests: - not_null - name: losses tests: - not_nullKlikněte na Uložit jako.
Jako název souboru zadejte
models/schema.ymla klepněte na tlačítko Vytvořit.Vytvoření prvního testu dat: Klikněte
(Vytvořit nový soubor) v pravém horním rohu.V textovém editoru zadejte následující příkaz SQL. Tento soubor obsahuje datový test, který určuje, jestli se některé hry nestaly mimo pravidelnou sezónu.
-- This season's games happened between 2020-12-12 and 2021-02-06. -- For this test to pass, this query must return no results. select date from zzz_game_details where date < '2020-12-12' or date > '2021-02-06'Klikněte na Uložit jako.
Jako název souboru zadejte
tests/zzz_game_details_check_dates.sqla klepněte na tlačítko Vytvořit.Vytvoření druhého testu dat: Klikněte
(Vytvořit nový soubor) v pravém horním rohu.V textovém editoru zadejte následující příkaz SQL. Tento soubor obsahuje datový test, který určuje, jestli byly nějaké skóre záporné nebo jakékoli hry byly svázané.
-- This sport allows no negative scores or tie games. -- For this test to pass, this query must return no results. select home_score, visitor_score from zzz_game_details where home_score < 0 or visitor_score < 0 or home_score = visitor_scoreKlikněte na Uložit jako.
Jako název souboru zadejte
tests/zzz_game_details_check_scores.sqla klepněte na tlačítko Vytvořit.Vytvoření třetího testu dat: Klikněte
(Vytvořit nový soubor) v pravém horním rohu.V textovém editoru zadejte následující příkaz SQL. Tento soubor obsahuje datový test, který určuje, jestli některé týmy měly negativní záznamy o výhrách nebo ztrátách, měly více záznamů o výhrách nebo ztrátách než hry, nebo hrály více her, než bylo povoleno.
-- Each team participated in 4 games this season. -- For this test to pass, this query must return no results. select wins, losses from zzz_win_loss_records where wins < 0 or wins > 4 or losses < 0 or losses > 4 or (wins + losses) > 4Klikněte na Uložit jako.
Jako název souboru zadejte
tests/zzz_win_loss_records_check_records.sqla klepněte na tlačítko Vytvořit.Spusťte testy: Na příkazovém řádku spusťte
dbt testpříkaz.
Krok 4: Vyčištění
Spuštěním následujícího kódu SQL můžete odstranit tables a views, které jste vytvořili v tomto příkladu.
Pokud se připojujete ke clusteru, můžete tento kód SQL spustit z poznámkového bloku připojeného ke clusteru a zadat SQL jako výchozí jazyk poznámkového bloku. Pokud se připojujete ke službě SQL Warehouse, můžete tento kód SQL spustit z dotazu.
DROP TABLE zzz_game_opponents;
DROP TABLE zzz_game_scores;
DROP TABLE zzz_games;
DROP TABLE zzz_teams;
DROP TABLE zzz_game_details;
DROP VIEW zzz_win_loss_records;
DROP TABLE diamonds;
DROP TABLE diamonds_four_cs;
DROP VIEW diamonds_list_colors;
DROP VIEW diamonds_prices;
Další kroky
- Přečtěte si další informace o modelech dbt.
- Naučte se testovat projekty dbt.
- Naučte se používat jinja , jazyk šablon, pro programování SQL v projektech dbt.
- Seznamte se s osvědčenými postupy dbt.