Pomalá etapa Sparku s malými vstupně-výstupními operacemi
Pokud máte pomalou fázi, která nemá moc vstupně-výstupních operací, může to být způsobeno:
- Čtení velkého množství malých souborů
- Psaní velkého množství malých souborů
- Pomalé funkce definované uživatelem
- Kartézské spojení
- Rozbalení spojení
Téměř všechny tyto problémy je možné identifikovat pomocí dag SQL.
Otevřete SQL DAG
Pokud chcete otevřít SQL DAG, posuňte se nahoru na začátek stránky úlohy a klikněte na Přidružený dotaz SQL:

Teď byste měli vidět DAG. Pokud ne, posouvejte se trochu a měli byste ho vidět:
Než budete pokračovat, seznamte se s DAG a zjistěte, kde se tráví čas. Některé uzly v DAG mají užitečné informace o čase a jiné ne. Tento blok například trval 2,1 minuty a dokonce poskytuje ID fáze:

Tento uzel vyžaduje, abyste ho otevřeli, abyste zjistili, že trvalo 1,4 minuty:
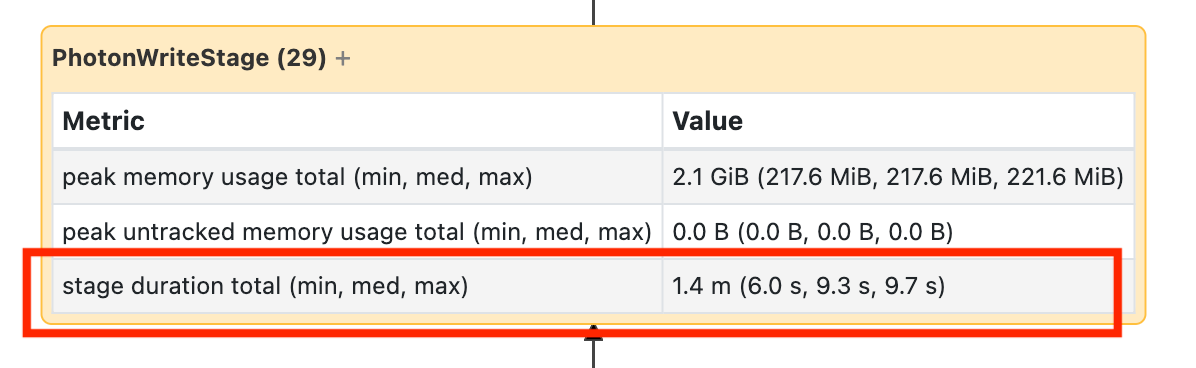
Tyto časy jsou kumulativní, takže se jedná o celkový čas strávený na všech úkolech, nikoli o čas na hodinkách. Je ale stále velmi užitečné, protože korelují s hodinovým časem a náklady.
Je užitečné se seznámit s tím, kde se v DAG tráví čas.
Čtení velkého množství malých souborů
Pokud zjistíte, že některý z vašich operátorů skenování trvá dlouho, otevřete ho a podívejte se na počet přečtených souborů.
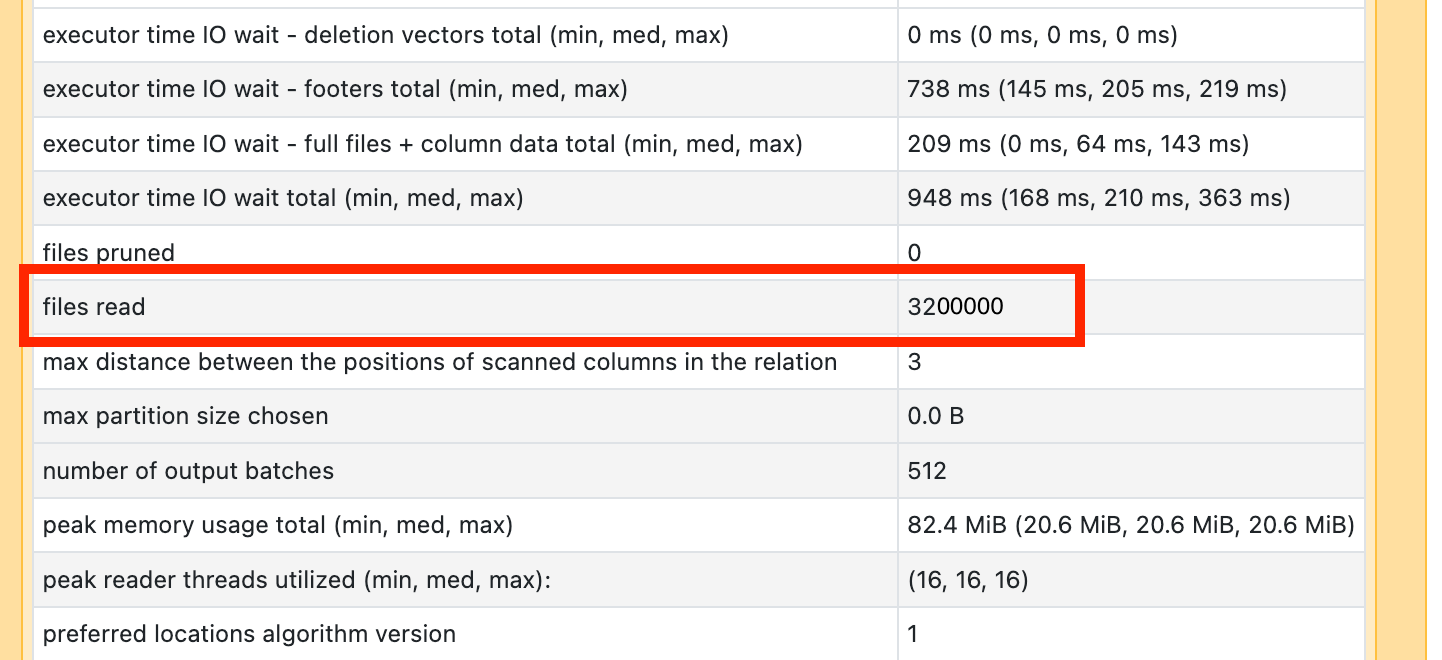
Pokud čtete desítky tisíc souborů nebo více, možná máte problém s mnoha malými soubory. Soubory by neměly být menší než 8 MB. Problém s malým souborem je nejčastěji způsoben dělením na příliš mnoho sloupců nebo sloupce s vysokou kardinalitou.
Pokud budete mít štěstí, mohlo by stačit spustit OPTIMIZE. Bez ohledu na to, musíte znovu zvážit rozložení souboru.
Psaní velkého množství malých souborů
Pokud vidíte, že zápis trvá dlouho, otevřete ho a vyhledejte počet souborů a počet zapsaných dat:
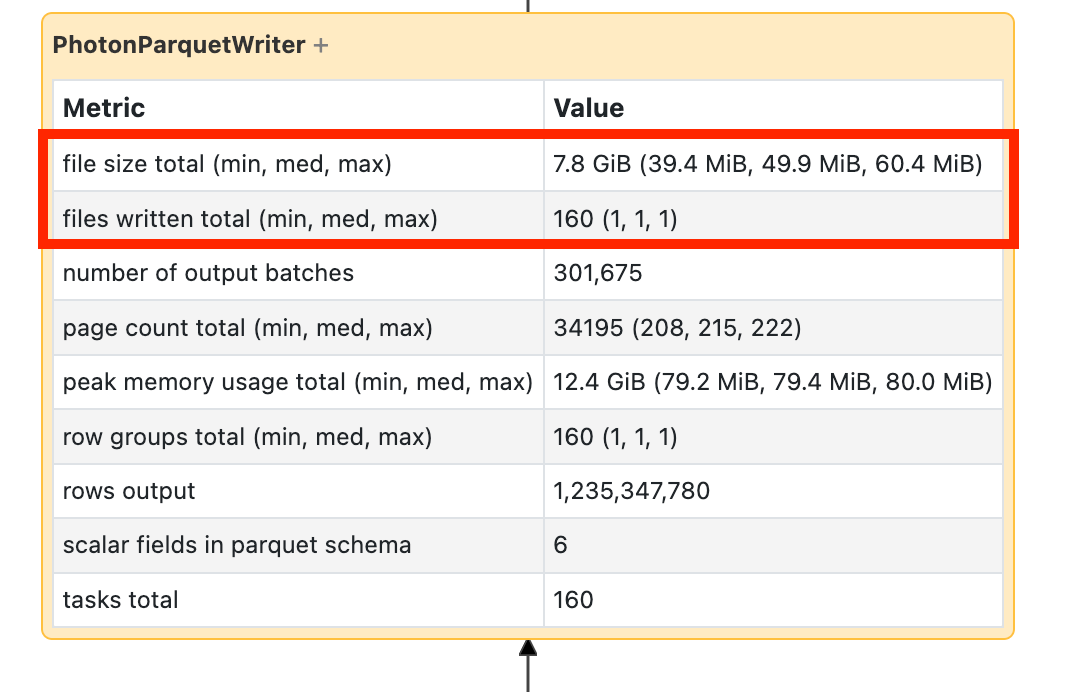
Pokud píšete desítky tisíc souborů nebo více souborů, možná máte problém s malým souborem. Soubory by neměly být menší než 8 MB. Problém s malým souborem je nejčastěji způsoben dělením na příliš mnoho sloupců nebo sloupce s vysokou kardinalitou. Musíte znovu zvážit rozložení souboru nebo zapnout optimalizované zápisy.
Pomalé funkce definované uživatelem
Pokud víte, že máte uživatelsky definované funkce, nebo se v DAG zobrazí něco podobného, můžete mít problémy s pomalými uživatelsky definovanými funkcemi:
Pokud si myslíte, že tímto problémem trpíte, zkuste komentovat UDF, abyste zjistili, jak to ovlivňuje rychlost pipeline. Pokud je UDF skutečně tam, kde se tráví čas, je nejlepším řešením přepsat UDF pomocí nativních funkcí. Pokud to není možné, zvažte počet úkolů ve fázi vykonávající vaše UDF. Pokud je menší než počet jader v clusteru, připravte svůj datový rámec pomocí repartition() před použitím funkce definované uživatelem.
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
Uživatelsky definované funkce mohou mít také problémy s pamětí. Vezměte v úvahu, že každý úkol může muset načíst všechna data v jeho oddílu do paměti. Pokud jsou tato data příliš velká, může to být velmi pomalé nebo nestabilní. Změna rozdělení může tento problém vyřešit také tím, že jednotlivé úlohy zmenší.
Kartézské spojení
Pokud v DAG uvidíte kartézské spojení nebo vnořené spojení smyčky, měli byste vědět, že tato spojení jsou velmi drahá. Ujistěte se, že je to, co jste chtěli, a zjistěte, jestli existuje jiný způsob.
Explozí spojení nebo explodování
Pokud vidíte, že do uzlu vstupuje několik řádků a vychází jich mnohem více, můžete čelit problému s expanzí JOINu nebo funkcí explode().

Přečtěte si další informace o explodech v průvodci optimalizace Databricks.