Neúspěšné úlohy nebo exekutory se odebraly
Zobrazují se tedy neúspěšné úlohy nebo odebrané exekutory:
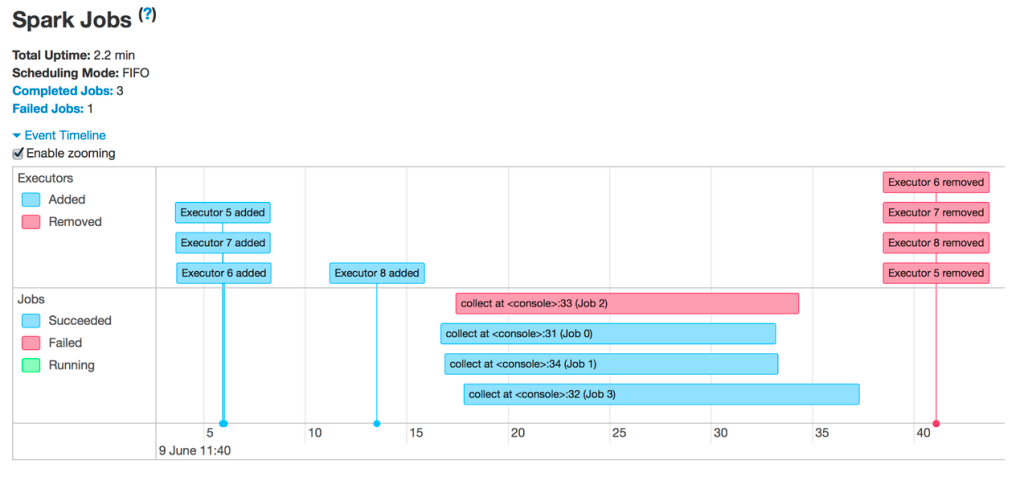
Mezi nejběžnější důvody odebrání exekutorů patří:
- Automatické škálování: V tomto případě se to očekává a nejedná se o chybu. Viz část Povolení automatického škálování.
- Ztráty spotových instancí: Poskytovatel cloudu přebírá zpět vaše virtuální počítače. Další informace o spotových instancích najdete tady.
- Exekutorům dochází paměť
Selhání úloh
Pokud se zobrazí nějaké neúspěšné úlohy, kliknutím na ně get na jejich stránky. Pak se posuňte dolů, abyste viděli neúspěšnou fázi a důvod selhání:

Může dojít k chybě get. Kliknutím na odkaz v popisu zjistíte, jestli můžete get další informace:

Pokud se na této stránce posunete dolů, uvidíte, proč každý úkol selhal. V takovém případě se stává jasné, že došlo k problému s pamětí:

Neúspěšné exekutory
Pokud chcete zjistit, proč vaše exekutory selhávají, nejprve budete chtít zkontrolovat protokol událostí výpočetních prostředků a zjistit, jestli nejsou nějaké vysvětlení, proč exekutory selhaly. Je například možné, že používáte spotové instance a poskytovatel cloudu je přebírá zpět.

Podívejte se, jestli neexistují nějaké události vysvětlující ztrátu exekutorů. Mohou se například zobrazit zprávy, které značí, že cluster se změnou velikosti nebo dochází ke ztrátě spotových instancí.
- Pokud používáte spotové instance, přečtěte si téma Ztráta spotových instancí.
- Pokud došlo ke změně velikosti výpočetních prostředků pomocí automatického škálování, očekává se to a nejedná se o chybu. Další informace o změně velikosti clusteru
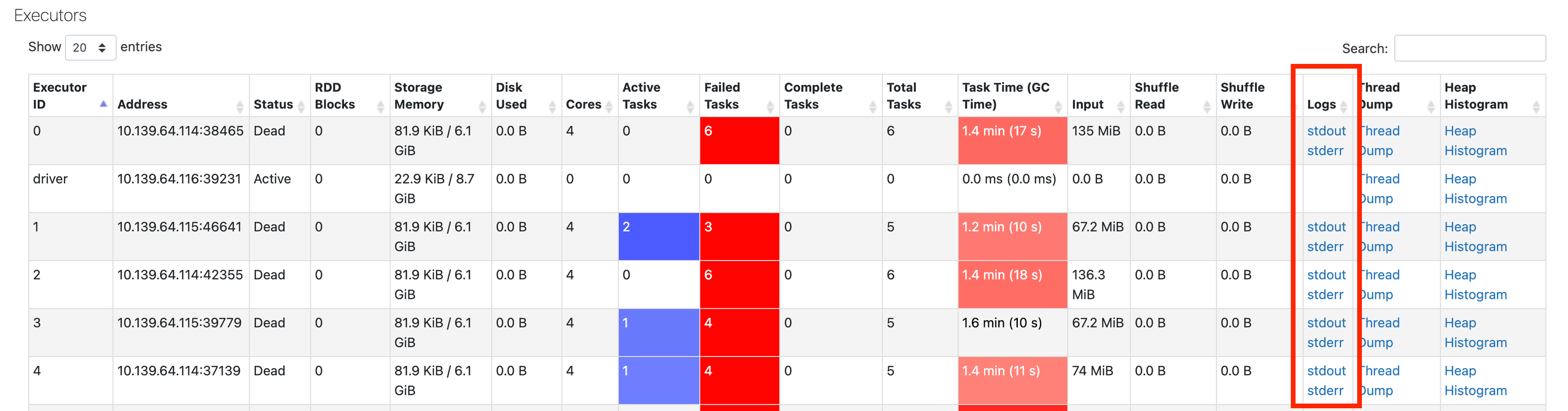
Pokud v protokolu událostí nevidíte žádné informace, přejděte zpět do uživatelského rozhraní Sparku a klikněte na kartu Exekutory :

Tady můžete get protokoly z neúspěšných běžících procesů:
Další krok
Pokud jste se tak daleko dostali, je nejobsáhlejším vysvětlením problém s pamětí. Dalším krokem je prozkoumat problémy s pamětí. Viz problémy s pamětí Sparku.