Zobrazení výsledků trénování pomocí spuštění MLflow
Tento článek popisuje, jak pomocí běhů MLflow zobrazit a analyzovat výsledky experimentu trénování modelu a jak spravovat a organizovat spuštění. Další informace o experimentech MLflow najdete v tématu Uspořádání trénovacích běhů pomocí experimentů MLflow.
Spuštění MLflow odpovídá jedinému spuštění kódu modelu. Každý běh zaznamenává informace, jako je poznámkový blok, který běh spustil, všechny modely vytvořené během, parametry modelu a metriky uložené jako páry klíč-hodnota, značky metadat běhu a všechny artefakty nebo výstupní soubory vytvořené během.
Všechna spuštění MLflow se protokolují do aktivního experimentu. Pokud jste experiment explicitně nenastavili jako aktivní, spuštění se zaprotokolují do experimentu poznámkového bloku.
Zobrazit podrobnosti o spuštění
K běhu můžete přistupovat buď ze stránky podrobností o experimentu, nebo přímo z poznámkového bloku, který běh spustil.
Na stránce s podrobnostmi o experimentu klikněte na název běhu v tabulce běhů.
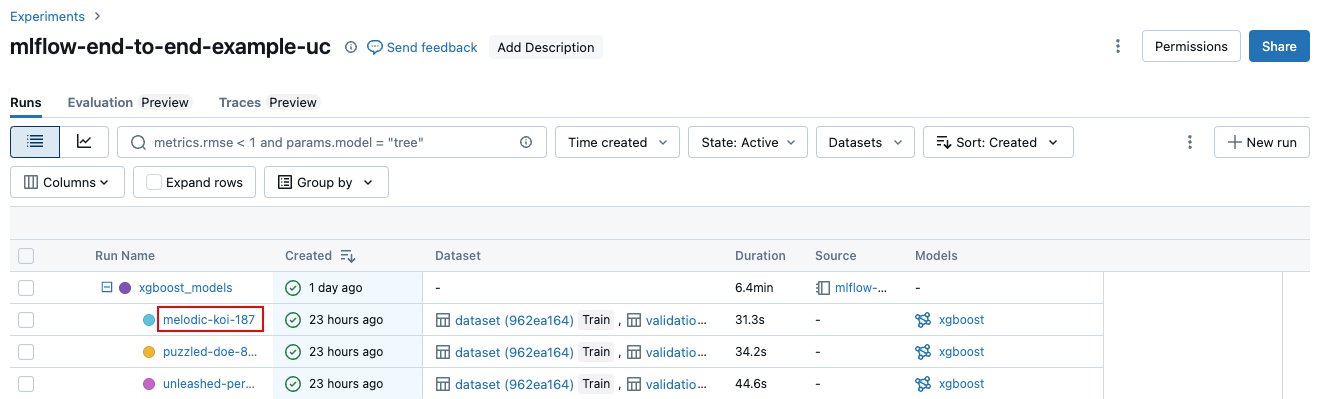
V poznámkovém bloku klikněte na název spuštění v bočním panelu s běhy experimentu.

Obrazovka spuštění zobrazuje ID spuštění, parametry použité pro spuštění, metriky, které jsou výsledkem spuštění, a podrobnosti o spuštění, včetně odkazu na zdrojový poznámkový blok. Artefakty uložené ze spuštění jsou k dispozici na záložce Artefakty.
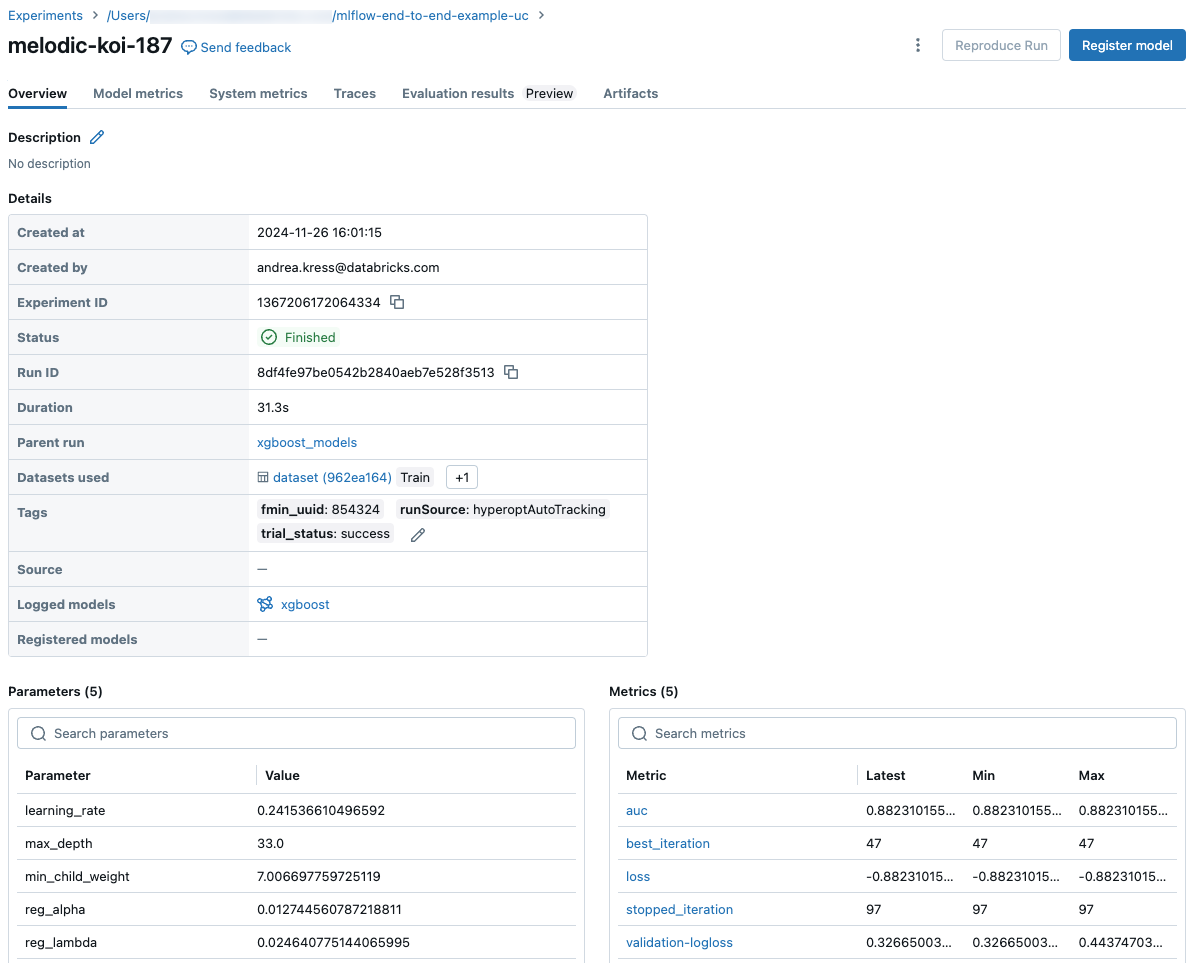
Fragmenty kódu pro predikci
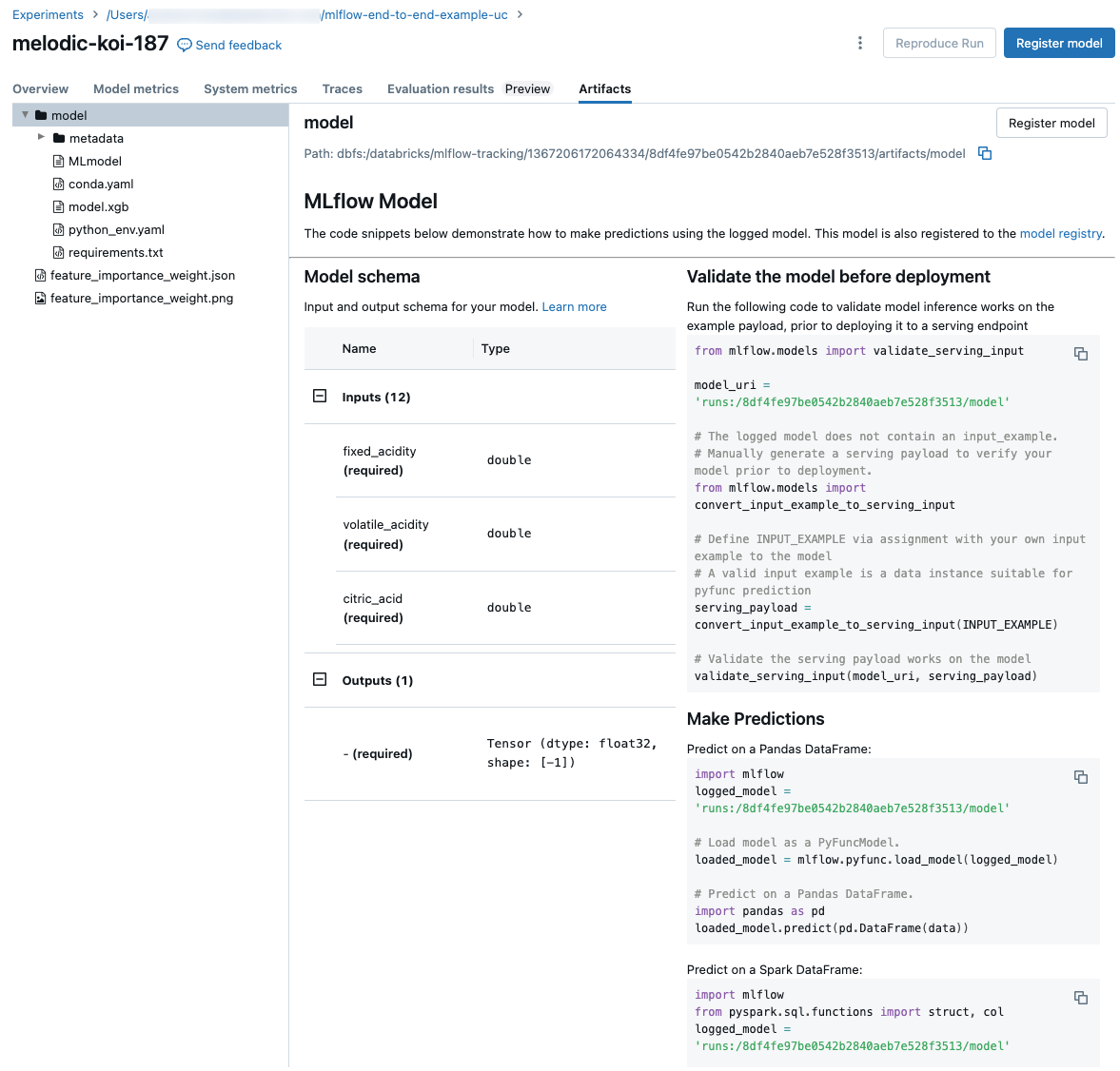
Pokud model zapíšete během spuštění, zobrazí se také na kartě Artifacts spolu s fragmenty kódu, které ilustrují, jak načíst a použít model k vytváření předpovědí pro datové rámce Spark a Pandas.
Zobrazení poznámkového bloku použitého pro spuštění
Zobrazení verze poznámkového bloku, který vytvořil spuštění:
- Na stránce podrobností experimentu klikněte na odkaz ve sloupci Zdroj.
- Na stránce spuštění klikněte na odkaz vedle položky Zdroj.
- V poznámkovém bloku klikněte na bočním panelu Spuštění experimentu na Notebook Version Iconikonu poznámkového bloku v poli pro spuštění experimentu.
Verze poznámkového bloku přidruženého ke spuštění se zobrazí v hlavním okně s panelem zvýraznění s datem a časem spuštění.
Přidání značky ke spuštění
Značky jsou páry klíč-hodnota, které můžete vytvořit a použít později k hledání spuštění.
V tabulce Podrobnosti na stránce spustitklikněte na Přidat vedle Značky.

Otevře se dialogové okno Přidat/Upravit značky. Do pole Klíč zadejte název klíče a klikněte na Přidat značku.
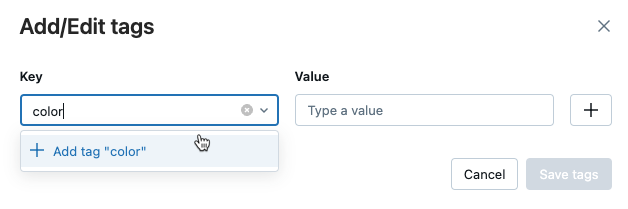
Do pole Hodnota zadejte hodnotu pro značku.
Klikněte na znaménko plus pro uložení dvojice klíč-hodnota, kterou jste právě zadali.
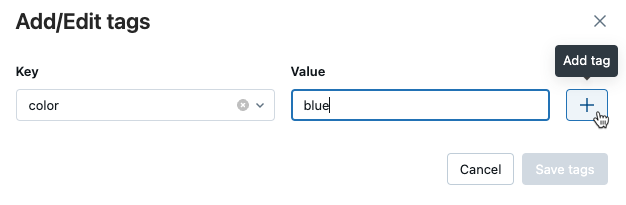
Pokud chcete přidat další značky, opakujte kroky 2 až 4.
Až budete hotovi, klikněte na Uložit značky.
Úprava nebo odstranění značky pro spuštění
V tabulce Podrobnosti na stránce spustitklikněte na
vedle existujících značek.

Otevře se dialogové okno Přidat/Upravit značky.
Pokud chcete odstranit značku, klikněte na symbol X na této značce.
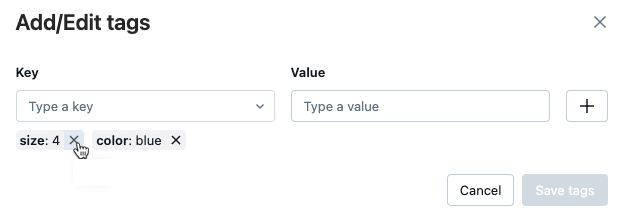
Pokud chcete upravit značku, vyberte klíč z rozevírací nabídky a upravte hodnotu v poli Hodnota. Kliknutím na znaménko plus uložte změnu.
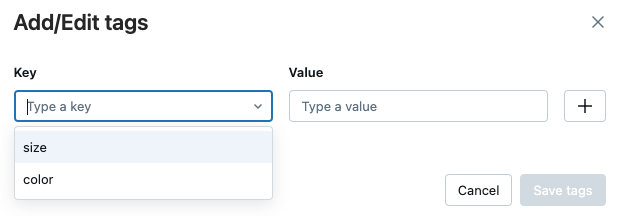
Až budete hotovi, klikněte na Uložit značky.
Reprodukujte softwarové prostředí spuštění.
Přesné softwarové prostředí pro spuštění můžete reprodukovat kliknutím na Reprodukovat spuštění v pravém horním rohu stránky spuštění. Zobrazí se následující dialogové okno:
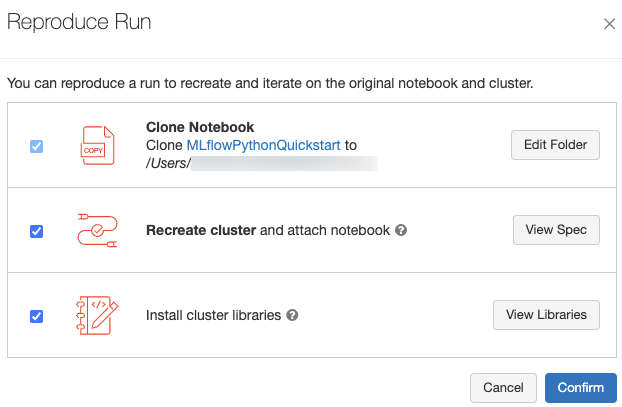
Při použití výchozího nastavení klepněte na tlačítko Potvrdit:
- Poznámkový blok se naklonuje do umístění zobrazeného v dialogovém okně.
- Pokud původní cluster stále existuje, klonovaný poznámkový blok se připojí k původnímu clusteru a cluster se spustí.
- Pokud původní cluster již neexistuje, vytvoří se a spustí nový cluster se stejnou konfigurací, včetně nainstalovaných knihoven. Poznámkový blok je připojený k novému clusteru.
Pro klonovaný poznámkový blok můžete vybrat jiné umístění a zkontrolovat konfiguraci clusteru a nainstalované knihovny:
- Chcete-li vybrat jinou složku pro uložení klonovaného poznámkového bloku, klikněte na Upravit složku.
- Pokud chcete zobrazit specifikaci clusteru, klikněte na Zobrazit specifikaci. Pokud chcete klonovat jenom poznámkový blok, ne cluster, zrušte zaškrtnutí této možnosti.
- Pokud původní cluster již neexistuje, zobrazí se knihovny nainstalované v původním clusteru kliknutím na Zobrazit knihovny. Pokud původní cluster stále existuje, bude tato část zašedlá.
Přejmenovat spuštění
Chcete-li přejmenovat spuštění, klikněte na nabídku kebab ![]() v pravém horním rohu stránky spuštění (vedle tlačítka Oprávnění) a vyberte Přejmenovat.
v pravém horním rohu stránky spuštění (vedle tlačítka Oprávnění) a vyberte Přejmenovat.
Výběr sloupců, které se mají zobrazit
Pokud chcete ovládat sloupce zobrazené v tabulce běhů na stránce podrobností experimentu, klikněte na Sloupce a vyberte z rozevírací nabídky.
Spuštění filtru
V tabulce na stránce s podrobnostmi o experimentu můžete vyhledávat spuštění podle hodnot parametrů či metrik. Můžete také vyhledat spuštění podle značky.
Pokud chcete vyhledat spuštění, která odpovídají výrazu obsahujícímu hodnoty parametrů a metrik, zadejte do vyhledávacího pole dotaz a stiskněte Enter. Mezi příklady syntaxe dotazů patří:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Ve výchozím nastavení se hodnoty metrik filtrují na základě poslední zaprotokolované hodnoty. Pomocí
MINneboMAXmůžete vyhledávat spuštění na základě minimálních nebo maximálních hodnot metrik. Po srpnu 2024 se protokolují pouze spuštění s minimálními a maximálními hodnotami metrik.Pokud chcete vyhledat spuštění podle značky, zadejte značky ve formátu:
tags.<key>="<value>". Řetězcové hodnoty musí být uzavřeny v uvozovkách, jak je znázorněno.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Klíče i hodnoty můžou obsahovat mezery. Pokud klíč obsahuje mezery, musíte ho uzavřít do backtick, jak je znázorněno.
tags.`my custom tag` = "my value"
Můžete také filtrovat spuštění podle jejich stavu (Aktivní nebo Odstraněno), kdy se spuštění vytvořilo a jaké datové sady se použily. Uděláte to tak, že si vyberete z rozevíracích nabídek Čas vytvoření, Stavnebo Datové sady.
Stahování spuštění
Běhy můžete stáhnout z podrobností experimentu na stránce následujícími kroky:
Kliknutím na
 otevřete nabídku kebabu.
otevřete nabídku kebabu.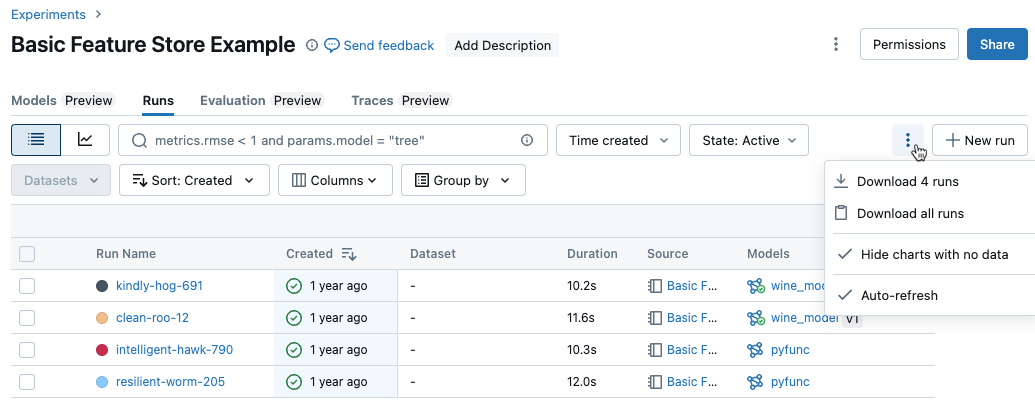
Pokud chcete stáhnout soubor ve formátu CSV obsahujícím všechny zobrazené běhy (maximálně 100), vyberte Stáhnout
<n>běhy. MLflow vytvoří a stáhne soubor s jedním spuštěním na řádek, který obsahuje následující pole pro každé spuštění:Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...Pokud chcete stáhnout více než 100 běhů nebo chcete stahovat běhy programově, vyberte Stáhnout všechna spuštění. Otevře se dialogové okno s fragmentem kódu, který můžete zkopírovat nebo otevřít v poznámkovém bloku. Po spuštění tohoto kódu v buňce poznámkového bloku vyberte Stáhnout všechny řádky z výstupu buňky.
Odstranění spuštění
Záznamy můžete odstranit ze stránky s podrobnostmi experimentu pomocí následujícího postupu:
- Při experimentu vyberte jeden nebo více běhů kliknutím na zaškrtávací políčko vlevo od běhu.
- Klepněte na tlačítko Odstranit.
- Pokud je spuštěním nadřazené spuštění, rozhodněte se, jestli chcete odstranit také následná spuštění. Ve výchozím nastavení je tato možnost vybrána.
- Kliknutím na Odstranit potvrďte. Odstraněná spuštění se ukládají po dobu 30 dnů. Chcete-li zobrazit odstraněná spuštění, vyberte v poli Stav možnost Odstraněno.
Hromadné odstranění se spouští na základě času vytvoření.
Python můžete použít k hromadnému odstranění spuštění experimentu, který byl vytvořen před nebo v časovém razítku systému UNIX.
Pomocí Databricks Runtime 14.1 nebo novější můžete volat mlflow.delete_runs rozhraní API k odstranění spuštění a vrácení počtu odstraněných spuštění.
Následují parametry mlflow.delete_runs:
-
experiment_id: ID experimentu obsahujícího spuštění, která se mají odstranit. -
max_timestamp_millis: Maximální časové razítko vytváření v milisekundách od epochy UNIX pro odstranění spuštění. Odstraní se pouze spuštění vytvořená před nebo v tomto časovém razítku. -
max_runs:Volitelný. Kladné celé číslo označující maximální počet spuštění, která se mají odstranit. Maximální povolená hodnota pro max_runs je 1 0000. Pokud není zadáno,max_runsvýchozí hodnota je 1 0000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Pomocí Databricks Runtime 13.3 LTS nebo starší můžete v poznámkovém bloku Azure Databricks spustit následující klientský kód.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Informace o parametrech a specifikacích návratových hodnot pro odstraňování spuštění na základě času vytvořenínajdete v dokumentaci k rozhraní API služby Azure Databricks Experiments.
Obnovení běhů
Dříve odstraněná spuštění můžete obnovit z uživatelského rozhraní následujícím způsobem:
- Na stránce Experiment v poli Stav vyberte Odstraněné, aby se zobrazila odstraněná spuštění.
- Chcete-li vybrat jeden nebo více běhů, klikněte na zaškrtávací políčko vlevo od běhu.
- Klikněte na Obnovit.
- Klikněte na Obnovit pro potvrzení. Obnovené spuštění se teď zobrazí, když v poli Stav vyberete Aktivní.
Hromadná obnova se provádí na základě času odstranění.
Python můžete použít také k hromadnému obnovení spuštění experimentu, který byl odstraněn v časovém razítku systému UNIX nebo po ní.
Pomocí Databricks Runtime 14.1 nebo novějšího můžete volat rozhraní API mlflow.restore_runs k obnovení spuštění a získání počtu obnovených spuštění.
Následují parametry mlflow.restore_runs:
-
experiment_id: ID experimentu obsahujícího spuštění k obnovení. -
min_timestamp_millis: Minimální časové razítko odstranění v milisekundách od epochy UNIX pro obnovení spuštění. Spustí se pouze po obnovení tohoto časového razítka nebo po tomto časovém razítku. -
max_runs:Volitelný. Kladné celé číslo, které označuje maximální počet spuštění k obnovení. Maximální povolená hodnota pro max_runs je 1 0000. Pokud není zadáno, max_runs výchozí hodnota 1 0000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Pomocí Databricks Runtime 13.3 LTS nebo starší můžete v poznámkovém bloku Azure Databricks spustit následující klientský kód.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Informace o parametrech a specifikacích návratových hodnot pro obnovení na základě času odstraněnínajdete v dokumentaci k rozhraní API služby Azure Databricks Experiments.
Porovnání spuštění
Můžete porovnat spuštění z jednoho experimentu nebo z několika experimentů. Stránka Porovnání spuštění obsahuje informace o vybraných spuštěních v tabulkovém formátu. Můžete také vytvářet vizualizace výsledků spuštění a tabulek informací o spuštění, parametrů spuštění a metrik. Viz Porovnat běhy MLflow pomocí grafů a diagramů.
Tabulky Parametry a Metriky zobrazují parametry a metriky všech vybraných běhů. Sloupce v těchto tabulkách jsou identifikované podrobnostmi Spuštění tabulce bezprostředně nad ní. Pro zjednodušení můžete skrýt parametry a metriky, které jsou ve všech vybraných spuštěních stejné, přepnutím tlačítka  .
.
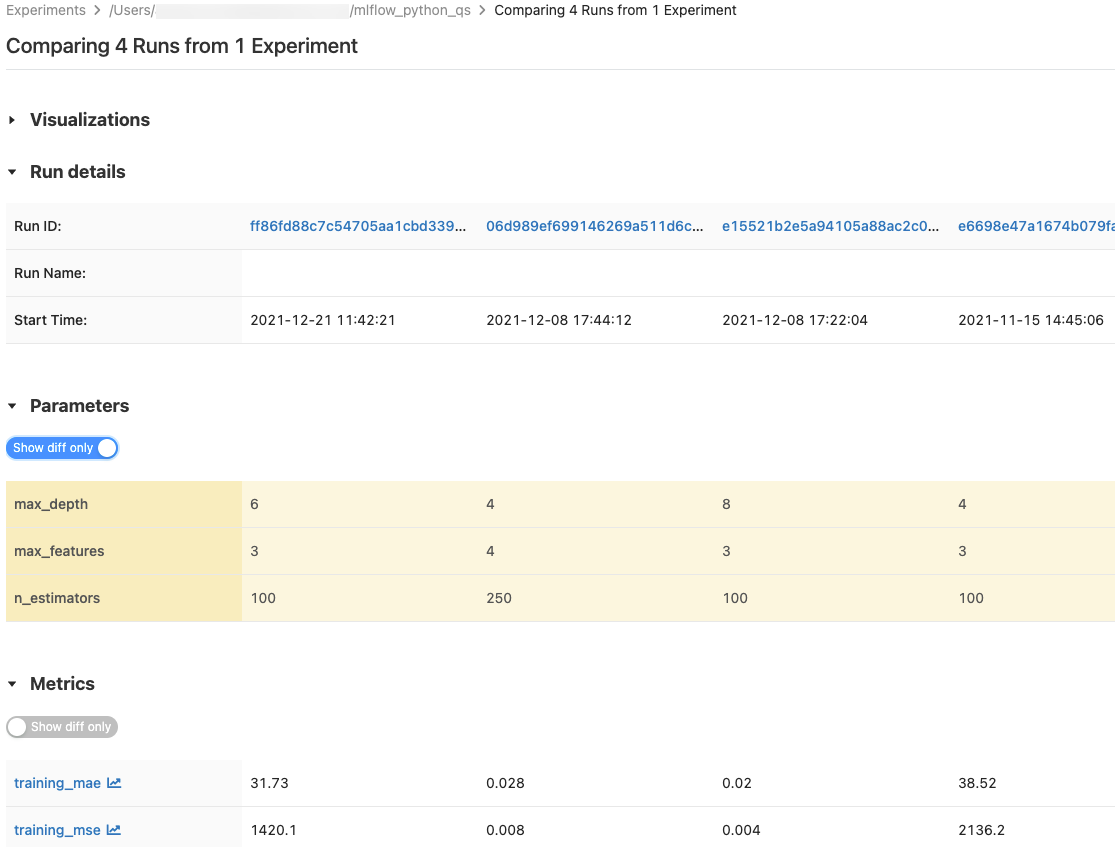
Porovnání spuštění z jednoho experimentu
- Na stránce spodrobnostmi o
experimentu vyberte dvě nebo více spuštění kliknutím na zaškrtávací políčko vlevo od spuštění nebo zaškrtnutím políčka zaškrtněte políčko v horní části sloupce. - Klikněte na Porovnat. Zobrazí se obrazovka Porovnání
<N>spuštění.
Porovnání spuštění z několika experimentů
- Na stránce experimentyvyberte experimenty, které chcete porovnat, kliknutím do pole nalevo od názvu experimentu.
- Klikněte na Porovnat (n) (n je počet experimentů, které jste vybrali). Zobrazí se obrazovka zobrazující všechna spuštění z vybraných experimentů.
- Vyberte dvě nebo více spuštění kliknutím na zaškrtávací políčko vlevo od spuštění, nebo vyberte všechna spuštění zaškrtnutím políčka v horní části sloupce.
- Klikněte na Porovnat. Zobrazí se obrazovka Porovnání
<N>spuštění.
Kopírování probíhá mezi pracovními prostory
K importu nebo exportu MLflow do nebo z pracovního prostoru Databricks můžete použít opensourcový opensourcový projekt MLflow Export-Import řízené komunitou.