Práce s tabulkami funkcí v úložišti funkcí pracovního prostoru (starší verze)
Poznámka:
Tato dokumentace se zabývá Úložištěm funkcí pro pracovní prostor. Databricks doporučuje využívat úpravu vlastností v Unity Catalog. Úložiště funkcí pracovního prostoru bude v budoucnu přestat být podporováno.
Informace o práci s tabulkami funkcí v katalogu Unity najdete v tématu Práce s tabulkami funkcí v katalogu Unity.
Tato stránka popisuje, jak vytvořit tabulky funkcí a pracovat s tabulkami funkcí v úložišti funkcí pracovního prostoru.
Poznámka:
Pokud je váš pracovní prostor povolený pro Katalog Unity, každá tabulka spravovaná katalogem Unity, která má primární klíč, je automaticky tabulka funkcí, kterou můžete použít pro trénování a odvozování modelu. Všechny funkce katalogu Unity, jako jsou zabezpečení, rodokmen, označování a přístup mezi pracovními prostory, jsou pro tabulku funkcí automaticky dostupné. Informace o práci s tabulkami funkcí v pracovním prostoru s podporou katalogu Unity najdete v tématu Práce s tabulkami funkcí v katalogu Unity.
Informace o sledování původu a aktuálnosti funkcí najdete v tématu Objevování funkcí a sledování jejich původu v úložišti funkcí pracovního prostoru (starší verze).
Poznámka:
Názvy tabulek databází a funkcí můžou obsahovat pouze alfanumerické znaky a podtržítka (_).
Vytvoření databáze pro tabulky funkcí
Před vytvořením tabulek funkcí je nutné vytvořit databázi pro jejich uložení.
%sql CREATE DATABASE IF NOT EXISTS <database-name>
Tabulky funkcí se ukládají jako tabulky Delta. Při vytváření tabulky funkcí s klientem create_table úložiště funkcí v0.3.6 a novějším nebo create_feature_table (v0.3.5 a novějším) je nutné zadat název databáze. Tento argument například vytvoří tabulku Delta pojmenovanou customer_features v databázi recommender_system.
name='recommender_system.customer_features'
Když publikujete tabulku funkcí do online obchodu, výchozí název tabulky a databáze jsou ty, které jsou zadané při vytváření tabulky; pomocí metody můžete zadat různé názvy publish_table .
Uživatelské rozhraní úložiště funkcí Databricks zobrazuje název tabulky a databáze v online úložišti spolu s dalšími metadaty.
Vytvoření tabulky funkcí v úložišti funkcí Databricks
Poznámka:
Existující tabulku Delta můžete také zaregistrovat jako tabulku funkcí. Viz Registrace existující tabulky Delta jako tabulky funkcí.
Základní postup vytvoření tabulky funkcí:
- Napište funkce Pythonu pro výpočet funkcí. Výstupem každé funkce by měl být datový rámec Apache Spark s jedinečným primárním klíčem. Primární klíč se může skládat z jednoho nebo více sloupců.
- Vytvořte tabulku funkcí vytvořením instance instance a
FeatureStoreClientpoužitícreate_table(v0.3.6 a vyšší) nebocreate_feature_table(v0.3.5 a novější). - Naplňte tabulku funkcí pomocí
write_tablefunkce .
Podrobnosti o příkazech a parametrech použitých v následujících příkladech najdete v referenčních informacích k rozhraní PYTHON API úložiště funkcí.
V0.3.6 a novější
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
name='recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_table call
# customer_feature_table = fs.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
V0.3.5 a novější
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
Registrace existující tabulky Delta jako tabulky funkcí
Pomocí verze 0.3.8 a vyšší můžete zaregistrovat existující tabulku Delta jako tabulku funkcí. Tabulka Delta musí existovat v metastoru.
Poznámka:
Pokud chcete aktualizovat registrovanou tabulku funkcí, musíte použít rozhraní PYTHON API úložiště funkcí.
fs.register_table(
delta_table='recommender.customer_features',
primary_keys='customer_id',
description='Customer features'
)
Řízení přístupu k tabulkám funkcí
Viz Řízení přístupu k tabulkám funkcí v úložišti funkcí pracovního prostoru (starší verze).
Aktualizace tabulky funkcí
Tabulku funkcí můžete aktualizovat přidáním nových funkcí nebo úpravou konkrétních řádků na základě primárního klíče.
Následující metadata tabulky funkcí nelze aktualizovat:
- Primární klíč
- Klíč oddílu
- Název nebo typ existující funkce
Přidání nových funkcí do existující tabulky funkcí
Nové funkce můžete do existující tabulky funkcí přidat jedním ze dvou způsobů:
- Aktualizujte stávající výpočetní funkci funkce a spusťte
write_tablevrácený datový rámec. Tím se aktualizuje schéma tabulky funkcí a sloučí se nové hodnoty funkcí na základě primárního klíče. - Vytvořte novou výpočetní funkci funkce pro výpočet nových hodnot funkcí. Datový rámec vrácený touto novou výpočetní funkcí musí obsahovat primární klíče tabulek funkcí a klíče oddílů (pokud jsou definovány). Spuštěním
write_tabledatového rámce zapište nové funkce do existující tabulky funkcí pomocí stejného primárního klíče.
Aktualizace pouze konkrétních řádků v tabulce funkcí
Použít mode = "merge" v write_table. Řádky, jejichž primární klíč v datovém rámci odeslaném write_table ve volání neexistuje, zůstanou beze změny.
fs.write_table(
name='recommender.customer_features',
df = customer_features_df,
mode = 'merge'
)
Naplánování úlohy pro aktualizaci tabulky funkcí
Aby funkce v tabulkách funkcí vždy měly nejnovější hodnoty, doporučuje Databricks vytvořit úlohu, která spouští poznámkový blok, aby pravidelně aktualizovala tabulku funkcí, například každý den. Pokud už máte neplánovaná úloha vytvořená, můžete ji převést na naplánovanou úlohu, abyste měli jistotu, že jsou hodnoty funkcí vždy aktuální. Viz Přehled orchestrace v databricks.
Kód pro aktualizaci tabulky funkcí používá mode='merge', jak je znázorněno v následujícím příkladu.
fs = FeatureStoreClient()
customer_features_df = compute_customer_features(data)
fs.write_table(
df=customer_features_df,
name='recommender_system.customer_features',
mode='merge'
)
Ukládání minulých hodnot denních funkcí
Definujte tabulku funkcí se složeným primárním klíčem. Zahrňte datum do primárního klíče. Například pro tabulku store_purchasesfunkcí můžete pro efektivní čtení použít složený primární klíč (date, user_id) a klíč date oddílu.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
Pak můžete vytvořit kód pro čtení z filtrování date tabulky funkcí do časového období zájmu.
Tabulku funkcí časových řad můžete vytvořit také zadáním date sloupce jako klíče časového razítka pomocí argumentutimestamp_keys.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
timestamp_keys=['date'],
schema=customer_features_df.schema,
description='Customer timeseries features'
)
To umožňuje vyhledávání k určitému bodu v čase při použití create_training_set nebo score_batch. Systém provádí spojení s časovým razítkem pomocí zadaného parametru timestamp_lookup_key .
Pokud chcete tabulku funkcí udržovat v aktualizovaném stavu, nastavte pravidelně naplánovanou úlohu pro zápis funkcí nebo streamujte nové hodnoty funkcí do tabulky funkcí.
Vytvoření výpočetního kanálu funkce streamování pro aktualizaci funkcí
Pokud chcete vytvořit výpočetní kanál funkce streamování, předejte streamování DataFrame jako argument .write_table Tato metoda vrátí StreamingQuery objekt.
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass # not shown
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fs.write_table(
df=stream_df,
name='recommender_system.customer_features',
mode='merge'
)
Čtení z tabulky funkcí
Slouží read_table ke čtení hodnot funkcí.
fs = feature_store.FeatureStoreClient()
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
Vyhledávání a procházení tabulek funkcí
K vyhledání nebo procházení tabulek funkcí použijte uživatelské rozhraní úložiště funkcí.
Na bočním panelu vyberte > funkcí machine learningu a zobrazte uživatelské rozhraní úložiště funkcí.
Do vyhledávacího pole zadejte celý nebo část názvu tabulky funkcí, funkce nebo zdroje dat používaného k výpočtu funkce. Můžete také zadat celý klíč nebo část klíče nebo hodnoty značky. Hledaný text nerozlišuje velká a malá písmena.

Získání metadat tabulky funkcí
Rozhraní API pro získání metadat tabulky funkcí závisí na verzi modulu runtime Databricks, kterou používáte. S v0.3.6 a vyšší použijte get_table. S v0.3.5 a níže použijte get_feature_table.
# this example works with v0.3.6 and above
# for v0.3.5, use `get_feature_table`
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.get_table("feature_store_example.user_feature_table")
Práce se značkami tabulky funkcí
Značky jsou páry klíč–hodnota, které můžete vytvořit a použít k vyhledávání tabulek vlastností. Značky můžete vytvářet, upravovat a odstraňovat pomocí uživatelského rozhraní úložiště funkcí nebo rozhraní Python API úložiště funkcí.
Práce se značkami tabulky funkcí v uživatelském rozhraní
K vyhledání nebo procházení tabulek funkcí použijte uživatelské rozhraní úložiště funkcí. Pokud chcete získat přístup k uživatelskému rozhraní, vyberte > funkcí Machine Learning.
Přidání značky pomocí uživatelského rozhraní úložiště funkcí
Klikněte,
 pokud ještě není otevřený. Zobrazí se tabulka značek.
pokud ještě není otevřený. Zobrazí se tabulka značek.
Klikněte do polí Název a Hodnota a zadejte klíč a hodnotu značky.
Klikněte na tlačítko Přidat.
Úprava nebo odstranění značky pomocí uživatelského rozhraní úložiště funkcí
Pokud chcete upravit nebo odstranit existující značku, použijte ikony ve sloupci Akce.

Práce se značkami tabulek funkcí pomocí rozhraní Python API úložiště funkcí
Na clusterech se systémem v0.4.1 a novějším můžete vytvářet, upravovat a odstraňovat značky pomocí rozhraní Python API úložiště funkcí.
Požadavky
Klient úložiště funkcí verze 0.4.1 a vyšší
Vytvoření tabulky funkcí se značkou pomocí rozhraní Python API úložiště funkcí
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
...
)
Přidání, aktualizace a odstranění značek pomocí rozhraní Python API úložiště funkcí
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Upsert a tag
fs.set_feature_table_tag(table_name="my_table", key="quality", value="gold")
# Delete a tag
fs.delete_feature_table_tag(table_name="my_table", key="quality")
Aktualizace zdrojů dat pro tabulku funkcí
Úložiště funkcí automaticky sleduje zdroje dat používané k výpočetním funkcím. Zdroje dat můžete také aktualizovat ručně pomocí rozhraní PYTHON API úložiště funkcí.
Požadavky
Klient úložiště funkcí verze 0.5.0 a vyšší
Přidání zdrojů dat pomocí rozhraní Python API úložiště funkcí
Tady je několik ukázkových příkazů. Podrobnosti najdete v dokumentaci k rozhraní API.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Use `source_type="table"` to add a table in the metastore as data source.
fs.add_data_sources(feature_table_name="clicks", data_sources="user_info.clicks", source_type="table")
# Use `source_type="path"` to add a data source in path format.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="dbfs:/FileStore/user_metrics.json", source_type="path")
# Use `source_type="custom"` if the source is not a table or a path.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="user_metrics.txt", source_type="custom")
Odstranění zdrojů dat pomocí rozhraní Python API úložiště funkcí
Podrobnosti najdete v dokumentaci k rozhraní API.
Poznámka:
Následující příkaz odstraní zdroje dat všech typů ("table", "path" a "custom"), které odpovídají názvům zdrojů.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.delete_data_sources(feature_table_name="clicks", sources_names="user_info.clicks")
Odstranění tabulky funkcí
Tabulku funkcí můžete odstranit pomocí uživatelského rozhraní úložiště funkcí nebo rozhraní Python API úložiště funkcí.
Poznámka:
- Odstranění tabulky funkcí může vést k neočekávaným chybám v nadřazených producentech a podřízených konzumentech (modely, koncové body a plánované úlohy). U poskytovatele cloudu musíte odstranit publikovaná online úložiště.
- Když odstraníte tabulku funkcí pomocí rozhraní API, odstraní se také podkladová tabulka Delta. Když odstraníte tabulku funkcí z uživatelského rozhraní, musíte podkladovou tabulku Delta odstranit samostatně.
Odstranění tabulky funkcí pomocí uživatelského rozhraní
Na stránce tabulky funkcí klikněte
 na pravé straně názvu tabulky funkcí a vyberte Odstranit. Pokud nemáte oprávnění CAN MANAGE pro tabulku funkcí, tato možnost se nezobrazí.
na pravé straně názvu tabulky funkcí a vyberte Odstranit. Pokud nemáte oprávnění CAN MANAGE pro tabulku funkcí, tato možnost se nezobrazí.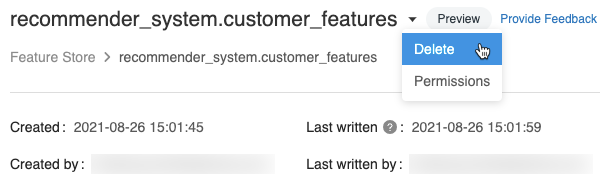
V dialogovém okně Odstranit tabulku funkcí potvrďte kliknutím na Odstranit .
Pokud chcete také odstranit podkladovou tabulku Delta, spusťte v poznámkovém bloku následující příkaz.
%sql DROP TABLE IF EXISTS <feature-table-name>;
Odstranění tabulky funkcí pomocí rozhraní Python API úložiště funkcí
Pomocí klienta úložiště funkcí verze 0.4.1 a vyšší můžete tabulku drop_table funkcí odstranit. Když odstraníte tabulku s drop_table, podkladová tabulka Delta se také zahodí.
fs.drop_table(
name='recommender_system.customer_features'
)