Vytvoření trénovacího spuštění pomocí rozhraní API pro vyladění základního modelu
Důležité
Tato funkce je ve verzi Public Preview v následujících oblastech: centralus, eastus, eastus2, northcentralusa westus.
Tento článek popisuje, jak vytvořit a nakonfigurovat trénovací běh pomocí rozhraní API pro vyladění základního modelu (nyní součástí rozhraní API Pro trénování modelů AI) a popisuje všechny parametry použité při volání rozhraní API. Spuštění můžete vytvořit také pomocí uživatelského rozhraní. Pokyny najdete v tématu Vytvoření trénovacího spuštění pomocí uživatelského rozhraní pro vyladění základního modelu.
Požadavky
Viz Požadavky.
Vytvoření trénovacího spuštění
K programovému vytvoření trénovacích běhů použijte create() funkci. Tato funkce trénuje model na poskytnuté datové sadě a převede konečný kontrolní bod Composer na kontrolní bod naformátovaný hugging face pro odvozování.
Požadované vstupy jsou model, který chcete trénovat, umístění trénovací datové sady a kde se má model zaregistrovat. Existují také volitelné parametry, které umožňují provádět vyhodnocení a měnit hyperparametry spuštění.
Po dokončení spuštění se uloží dokončené spuštění a konečný kontrolní bod, model se naklonuje a tento klon se zaregistruje do katalogu Unity jako verze modelu pro odvozování.
Model z dokončeného spuštění, nikoli klonovaná verze modelu v katalogu Unity, a jeho kontrolní body Composer a Hugging Face se uloží do MLflow. Kontrolní body Composer lze použít pro pokračování v vyladění úkolů.
Podrobnosti o argumentech pro funkci najdete v tématu create().
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Konfigurace trénovacího spuštění
Následující tabulka shrnuje parametry pro funkci foundation_model.create().
| Parametr | Požaduje se | Type | Description |
|---|---|---|---|
model |
linka | Str | Název modelu, který se má použít. Viz Podporované modely. |
train_data_path |
linka | Str | Umístění trénovacích dat Může se jednat o umístění v katalogu Unity (<catalog>.<schema>.<table> nebo dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl) nebo v datové sadě HuggingFace.Pro INSTRUCTION_FINETUNEdata by měla být naformátována každý řádek obsahující a promptresponse pole.Pro CONTINUED_PRETRAIN, to je složka .txt souborů. Viz Příprava dat pro jemné ladění modelu pro akceptované formáty dat a doporučenou velikost dat pro trénování modelu pro doporučení velikosti dat. |
register_to |
linka | Str | Katalog a schéma Unity Catalog (<catalog>.<schema> nebo <catalog>.<schema>.<custom-name>), kam se model registruje po tréninku pro snadné nasazení. Pokud custom-name není zadaný, toto výchozí nastavení je název spuštění. |
data_prep_cluster_id |
Str | ID clusteru, které se má použít ke zpracování dat Sparku. To se vyžaduje pro úlohy trénování instrukcí, ve kterých jsou trénovací data v tabulce Delta. Informace o tom, jak najít ID clusteru, najdete v tématu Získání ID clusteru. | |
experiment_path |
Str | Cesta k experimentu MLflow, kde se uloží výstup běhu tréninku (metriky a kontrolní body). Výchozí hodnota je název spuštění v osobním pracovním prostoru uživatele (tj. /Users/<username>/<run_name>). |
|
task_type |
Str | Typ úlohy, která se má spustit. Může být CHAT_COMPLETION (výchozí), CONTINUED_PRETRAINnebo INSTRUCTION_FINETUNE. |
|
eval_data_path |
Str | Vzdálené umístění zkušebních dat (pokud existuje). Musí se řídit stejným formátem jako train_data_path. |
|
eval_prompts |
List[str] | Seznam řetězců výzev k vygenerování odpovědí během vyhodnocení Výchozí hodnota je None (nevygenerujte výzvy). Výsledky se do experimentu zaprotokolují při každém vytvoření kontrolního bodu modelu. Generace probíhají v každém kontrolním bodu modelu s následujícími parametry generování: max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
Str | Vzdálené umístění kontrolního bodu vlastního modelu pro trénování. Výchozí hodnota je , což znamená None, že spuštění začíná od původních předem natrénovaných hmotností zvoleného modelu. Pokud jsou k dispozici vlastní váhy, použijí se tyto váhy místo původních předtrénovaných hmotností modelu. Tyto váhy musí být kontrolním bodem Composer a musí odpovídat architektuře model zadané hodnoty. Viz Build on custom model weights |
|
training_duration |
Str | Celková doba trvání spuštění Výchozí hodnota je jedna epocha nebo 1ep. Lze zadat v epochách (10ep) nebo tokenech (1000000tok). |
|
learning_rate |
Str | Rychlost výuky pro trénování modelu. Pro všechny jiné modely než Llama 3.1 405B Pokyn, výchozí rychlost učení je 5e-7. Pro Llama 3.1 405B Pokyn, výchozí rychlost učení je 1.0e-5. Optimalizátor je OddělenýLionW s beta verzemi 0,99 a 0,95 a bez snížení hmotnosti. Plánovač rychlosti učení je LinearWithWarmupSchedule s rozcvičením 2 % celkové doby trénování a násobitelem konečné rychlosti učení 0. |
|
context_length |
Str | Maximální délka sekvence vzorku dat. Používá se ke zkrácení všech dat, která jsou příliš dlouhá, a k zabalení kratších sekvencí společně za účelem efektivity. Výchozí hodnota je 8192 tokenů nebo maximální délka kontextu pro zadaný model podle toho, co je nižší. Tento parametr můžete použít ke konfiguraci délky kontextu, ale konfigurace nad rámec maximální délky kontextu každého modelu se nepodporuje. Maximální podporovanou délku kontextu jednotlivých modelů najdete v podporovaných modelech . |
|
validate_inputs |
Logická hodnota | Zda před odesláním úlohy trénování ověříte přístup ke vstupním cestám. Výchozí hodnota je True. |
Sestavování na váze vlastních modelů
Vyladění základního modelu podporuje přidání vlastních hmotností pomocí volitelného parametru custom_weights_path pro trénování a přizpůsobení modelu.
Pokud chcete začít, nastavte custom_weights_path na cestu kontrolního bodu Composer z předchozího trénovacího běhu. Cesty kontrolních bodů najdete na kartě Artefakty předchozího spuštění MLflow. Název složky kontrolního bodu odpovídá dávce a epochě konkrétního snímku, například ep29-ba30/.

- Pokud chcete poskytnout nejnovější kontrolní bod z předchozího spuštění, nastavte
custom_weights_pathna kontrolní bod Composer. Napříkladcustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Pokud chcete poskytnout dřívější kontrolní bod, nastavte
custom_weights_pathna cestu ke složce obsahující.distcpsoubory odpovídající požadovanému kontrolnímu bodu, napříkladcustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Dále aktualizujte parametr model tak, aby odpovídal základnímu modelu kontrolního bodu, který jste předali custom_weights_path.
V následujícím příkladu ift-meta-llama-3-1-70b-instruct-ohugkq je předchozí spuštění, které jemně-tunes meta-llama/Meta-Llama-3.1-70B. Pokud chcete vyladit nejnovější kontrolní bod z ift-meta-llama-3-1-70b-instruct-ohugkq, nastavte model a custom_weights_path proměnné následujícím způsobem:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Viz Konfigurace tréninkové úlohy pro konfiguraci dalších parametrů při ladění.
Získání ID clusteru
Načtení ID clusteru:
V levém navigačním panelu pracovního prostoru Databricks klikněte na Výpočetní prostředky.
V tabulce klikněte na název clusteru.
Klikněte na tlačítko
 v pravém horním rohu a v rozevírací nabídce vyberte Zobrazit JSON.
v pravém horním rohu a v rozevírací nabídce vyberte Zobrazit JSON.Zobrazí se soubor JSON clusteru. Zkopírujte ID clusteru, což je první řádek v souboru.
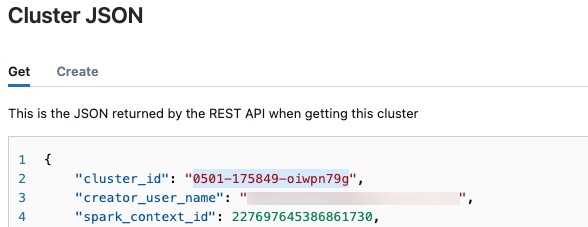
Získání stavu spuštění
Průběh spuštění můžete sledovat pomocí stránky Experiment v uživatelském rozhraní Databricks nebo pomocí příkazu get_events()rozhraní API . Podrobnosti najdete v tématu Zobrazení, správa a analýza spuštění jemného ladění základního modelu.
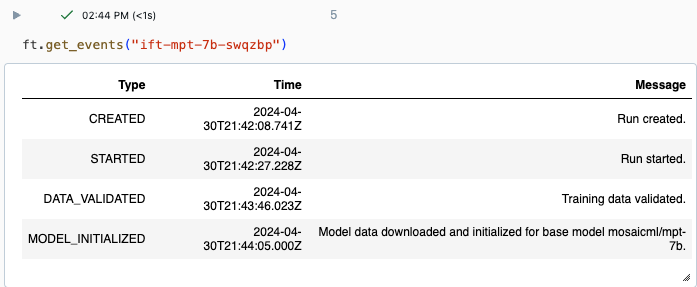
Příklad výstupu z get_events():
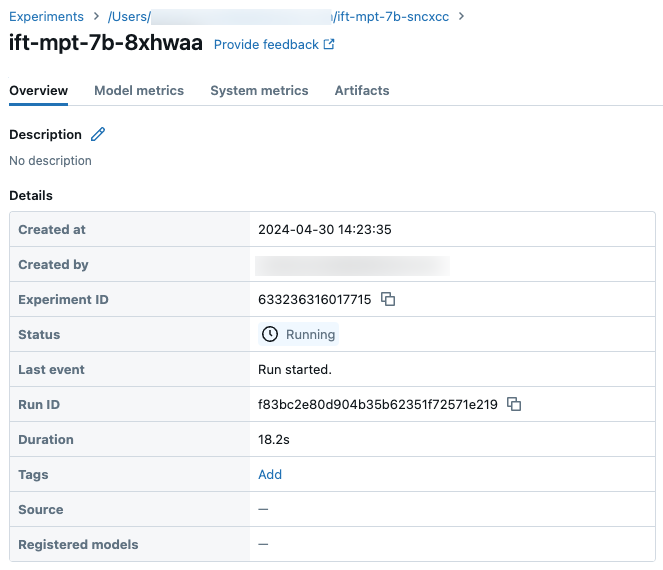
Ukázkové podrobnosti o spuštění na stránce Experiment:
Další kroky
Po dokončení trénovacího spuštění můžete zkontrolovat metriky v MLflow a nasadit model pro odvozování. Projděte si kroky 5 až 7 kurzu: Vytvoření a nasazení spuštění ladění základního modelu.
Podívejte se na podrobné ladění instrukcí: Pojmenovaný poznámkový blok ukázky rozpoznávání entit pro příklad podrobného ladění instrukcí, který vás provede přípravou dat, vyladěním konfigurace a nasazením trénovacího spuštění.
Příklad poznámkového bloku
Následující poznámkový blok ukazuje příklad generování syntetických dat pomocí Meta Llama 3.1 405B Pokyn modelu a použití těchto dat k vyladění modelu:
Generování syntetických dat pomocí instruktážního notebooku Llama 3.1 405B
Získání poznámkového bloku