Použití transformací dbt v úloze Azure Databricks
Projekty dbt Core můžete spustit jako úkol v úloze Azure Databricks. Spuštěním projektu dbt Core jako úlohy můžete využívat následující funkce úloh Azure Databricks:
- Automatizujte úlohy dbt a naplánujte pracovní postupy, které zahrnují úlohy dbt.
- Monitorujte transformace dbt a odesílejte oznámení o stavu transformací.
- Zahrňte projekt dbt do pracovního postupu s dalšími úkoly. Pracovní postup může například ingestovat data pomocí automatického zavaděče, transformovat data pomocí dbt a analyzovat data pomocí úlohy poznámkového bloku.
- Automatická archivace artefaktů ze spuštění úloh, včetně protokolů, výsledků, manifestů a konfigurace.
Další informace o dbt Core najdete v dokumentaci k dbt.
Vývojový a produkční pracovní postup
Databricks doporučuje vyvíjet projekty dbt ve službě Databricks SQL Warehouse. Pomocí skladu Databricks SQL můžete otestovat SQL vygenerované nástrojem dbt a pomocí historie dotazů skladu SQL ladit dotazy generované dbt.
Ke spuštění transformací dbt v produkčním prostředí doporučuje Databricks použít úlohu dbt v úloze Databricks. Ve výchozím nastavení úloha dbt spustí proces dbt Python pomocí výpočetních prostředků Azure Databricks a dbt vygenerovaného SQL pro vybraný SQL Warehouse.
Transformace dbt můžete spouštět na bezserverovém SQL Warehouse nebo pro SQL Warehouse, výpočetních prostředcích Azure Databricks nebo v jakémkoli jiném skladu podporovaném dbt. Tento článek popisuje první dvě možnosti s příklady.
Pokud je váš pracovní prostor Unity Catalogpovolený a bezserverové úlohy je ve výchozím nastavení povolená úloha na bezserverových výpočetních prostředcích.
Poznámka:
Vývoj modelů dbt pro SQL Warehouse a jejich spouštění v produkčním prostředí ve výpočetních prostředcích Azure Databricks může vést k drobným rozdílům v podpoře výkonu a jazyka SQL. Databricks doporučuje použít stejnou verzi Databricks Runtime pro výpočetní prostředky a SQL Warehouse.
Požadavky
Informace o tom, jak pomocí dbt Core a
dbt-databricksbalíčku vytvářet a spouštět projekty dbt ve vývojovém prostředí, najdete v tématu Připojení k dbt Core.Databricks doporučuje balíček dbt-databricks , nikoli balíček dbt-spark. Balíček dbt-databricks je větev balíčku dbt-spark optimalizovaná pro Databricks.
Pokud chcete v úloze Azure Databricks používat projekty dbt, musíte setintegraci Gitu pro složky Databricks Git. Z DBFS nelze spustit projekt dbt.
Musíte mít povolené bezserverové nebo pro SQL Warehouse.
Musíte mít nárok Sql na Databricks.
Vytvoření a spuštění první úlohy dbt
Následující příklad používá projekt jaffle_shop , ukázkový projekt, který demonstruje základní koncepty dbt. Pokud chcete vytvořit úlohu, která spustí projekt jaffle shopu, proveďte následující kroky.
Přejděte na cílovou stránku Azure Databricks a udělejte jednu z těchto věcí:
- Na bočním panelu klikněte na
 Pracovní postupy a klikněte na .
Pracovní postupy a klikněte na .
- Na bočním panelu klikněte na
 Nová a selectÚloha.
Nová a selectÚloha.
- Na bočním panelu klikněte na
V textovém poli úkolu na kartě Úkoly nahraďte přidat název vaší úlohy... názvem vaší úlohy.
Do pole Název úkolu zadejte název úkolu.
V Typselect typ úlohy dbt.
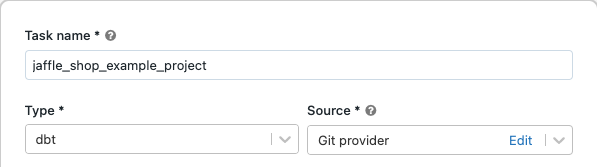
V rozevírací nabídce Source můžete zvolit selectpracovní prostor pro použití dbt projektu umístěného ve složce pracovního prostoru Azure Databricks, nebo poskytovatele Git pro projekt, který se nachází ve vzdáleném úložišti Git. Vzhledem k tomu, že tento příklad používá projekt jaffle shop umístěný v úložišti Git, selectposkytovatele Git, klikněte na Upravita zadejte podrobnosti o úložišti GitHub pro jaffle shop.
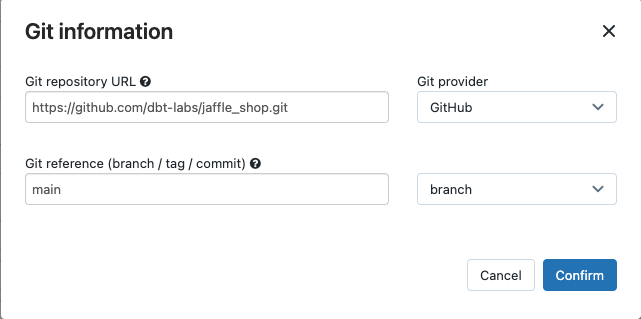
- V adrese URL úložiště Git zadejte adresu URL projektu jaffle shopu.
- V odkazu Gitu (větev / značka / potvrzení) zadejte
main. Můžete také použít značku nebo SHA.
Klikněte na tlačítko Potvrdit.
Do textových polí příkazů dbt zadejte příkazy dbt, které se mají spustit (deps, počáteční a spustit). Musíte předponovat každý příkaz pomocí
dbtpříkazu . Příkazy se spouští v zadaném pořadí.
V SQL Warehousese nachází select SQL sklad, který slouží ke spuštění SQL generovaného dbt. Rozevírací nabídka SQL Warehouse zobrazuje jenom bezserverové a profesionální sql warehouse.
(Volitelné) Můžete zadat schema pro výstup úkolu. Ve výchozím nastavení se používá schema
default.(Volitelné) Pokud chcete změnit konfiguraci výpočetních prostředků, na které běží dbt Core, klikněte na výpočetní prostředky rozhraní příkazového řádku dbt.
(Volitelné) Pro úlohu můžete zadat verzi dbt-databricks. Pokud chcete například připnout úlohu dbt na konkrétní verzi pro vývoj a produkci:
- V části Závislé knihovny klikněte na
 tlačítko vedle aktuální verze dbt-databricks.
tlačítko vedle aktuální verze dbt-databricks. - Klikněte na tlačítko Přidat.
- V dialogovém okně Přidat závislé knihovnyselectPyPI a do textového pole Package (například
dbt-databricks==1.6.0) zadejte verzi balíčku dbt. - Klikněte na tlačítko Přidat.

Poznámka:
Databricks doporučuje připnout úlohy dbt na konkrétní verzi balíčku dbt-databricks, aby se zajistila stejná verze pro vývojová a produkční spuštění. Databricks doporučuje verzi 1.6.0 nebo vyšší balíčku dbt-databricks.
- V části Závislé knihovny klikněte na
Klikněte na Vytvořit.
Chcete-li spustit úlohu nyní, klikněte na
 tlačítko .
tlačítko .
Zobrazení výsledků úlohy dbt
Po dokončení úlohy můžete výsledky otestovat spuštěním dotazů SQL z poznámkového bloku nebo spuštěním dotazů ve skladu Databricks. Podívejte se například na následující ukázkové dotazy:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Nahraďte <schema> názvem schema nakonfigurovaným v konfiguraci úlohy.
Příklad rozhraní API
Rozhraní API pro úlohy můžete také použít k vytváření a správě úloh, které zahrnují úlohy dbt. Následující příklad vytvoří úlohu s jednou úlohou dbt:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Upřesnit) Spuštění dbt s vlastním profilem
Pokud chcete spustit úlohu dbt pomocí SQL Warehouse (doporučeno) nebo výpočetních prostředků pro celý účel, použijte vlastní profiles.yml definování skladu nebo výpočetních prostředků Azure Databricks pro připojení. Pokud chcete vytvořit úlohu, která spouští projekt jaffle shopu s výpočetním prostředím skladu nebo pro celý účel, proveďte následující kroky.
Poznámka:
Jako cíl pro úlohu dbt je možné použít pouze výpočetní prostředky SQL Warehouse nebo pro všechny účely. Výpočetní prostředky úlohy nelze použít jako cíl pro dbt.
Vytvořte fork úložiště jaffle_shop .
Naklonujte forkované úložiště na plochu. Můžete například spustit příkaz podobný tomuto:
git clone https://github.com/<username>/jaffle_shop.gitNahraďte
<username>popisovačem GitHubu.Vytvořte v adresáři nový soubor
profiles.ymljaffle_shops následujícím obsahem:jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Nahraďte
<schema>názvem schema projektu tables. - Pokud chcete spustit úlohu dbt s SQL Warehouse, nahraďte
<http-host>hodnotu název hostitele serveru na kartě Podrobnosti připojení pro váš SQL Warehouse. Pokud chcete spustit úlohu dbt s výpočetními prostředky pro všechny účely, nahraďte<http-host>hodnotu názvu hostitele serveru na kartě Upřesnit možnosti JDBC/ODBC pro výpočetní prostředky Azure Databricks. - Pokud chcete spustit úlohu dbt s SQL Warehouse, nahraďte
<http-path>hodnotu cesty HTTP na kartě Podrobnosti připojení pro váš SQL Warehouse. Pokud chcete spustit úlohu dbt s výpočetními prostředky pro všechny účely, nahraďte<http-path>hodnotu cesty HTTP na kartě Upřesnit možnosti JDBC/ODBC pro výpočetní prostředky Azure Databricks.
V souboru nezadáte tajné kódy, jako jsou přístupové tokeny, protože tento soubor zkontrolujete do správy zdrojového kódu. Místo toho tento soubor používá funkce šablon dbt k dynamickému insertcredentials za běhu.
Poznámka:
Vygenerované credentials jsou platné po dobu spuštění, maximálně 30 dnů, a po ukončení jsou automaticky zneplatněny.
- Nahraďte
Zkontrolujte tento soubor do Gitu a nasdílejte ho do vašeho forku úložiště. Můžete například spouštět příkazy jako následující:
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushNa bočním panelu uživatelského rozhraní Databricks klikněte na
Pracovní postupy.Select úlohu dbt a klikněte na kartu Úkoly.
Ve zdroji klikněte na Upravit a zadejte podrobnosti o úložišti GitHubu pro forked jaffle shop.
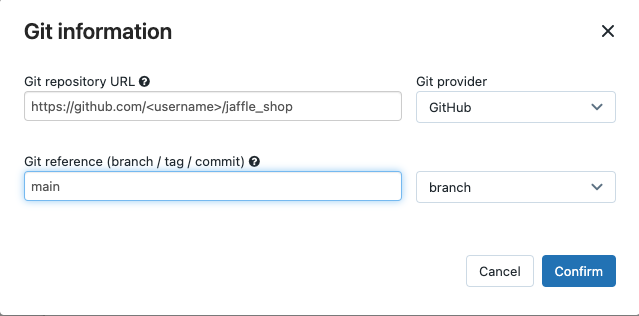
V SQL warehouse, selectNone (ruční).
V adresáři profilů zadejte relativní cestu k adresáři obsahujícímu
profiles.ymlsoubor. Ponechte hodnotu cesty prázdnou, pokud chcete použít výchozí hodnotu kořenového adresáře úložiště.
(Upřesnit) Použití modelů dbt Python v pracovním postupu
Poznámka:
Podpora dbt pro modely Pythonu je v beta verzi a vyžaduje dbt 1.3 nebo vyšší.
Dbt teď podporuje modely Pythonu v konkrétních datových skladech, včetně Databricks. Pomocí modelů dbt Python můžete pomocí nástrojů z ekosystému Python implementovat transformace, které se obtížně implementují pomocí SQL. Můžete vytvořit úlohu Azure Databricks, která spustí jeden úkol pomocí modelu dbt Python, nebo můžete úkol dbt zahrnout jako součást pracovního postupu, který zahrnuje více úkolů.
Modely Pythonu nelze spouštět v úloze dbt pomocí SQL Warehouse. Další informace o používání modelů dbt Python s Azure Databricks najdete v dokumentaci ke konkrétním datovým skladům.
Chyby a řešení problémů
Chyba souboru profilu neexistuje .
Chybová zpráva:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Možné příčiny:
Soubor profiles.yml nebyl v zadaném $PATH nalezen. Ujistěte se, že kořen projektu dbt obsahuje soubor profiles.yml.