Konfigurace výpočetních prostředků pro úlohy
Tento článek obsahuje doporučení a prostředky pro konfiguraci výpočetních prostředků pro úlohy Databricks.
Důležité
Omezení výpočetních prostředků bez serveru pro úlohy zahrnují následující:
- Žádná podpora pro průběžné plánování.
- Ve strukturovaném streamování není podporována výchozí ani časově založená aktivační událost intervalu.
Další omezení najdete v tématu Omezení bezserverového výpočetního prostředí.
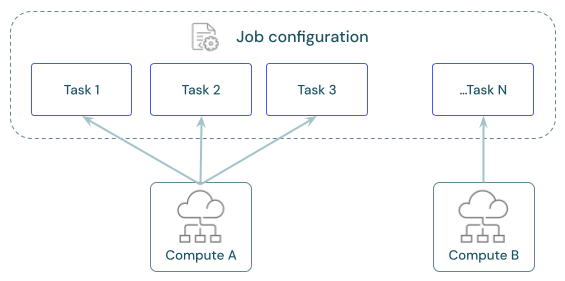
Každá úloha může mít jeden nebo více úkolů. Pro každý úkol definujete výpočetní prostředky. Stejný výpočetní prostředek může použít několik úkolů definovaných pro stejnou úlohu.
Jaké jsou doporučené výpočetní prostředky pro jednotlivé úlohy?
Následující tabulka uvádí doporučené a podporované typy výpočetních prostředků pro jednotlivé typy úloh.
Poznámka:
Bezserverové výpočetní prostředky pro úlohy mají omezení a nepodporují všechny úlohy. Viz Omezení výpočetních prostředků bez serveru.
| Úloha | Doporučené výpočetní prostředky | Podporované výpočetní prostředky |
|---|---|---|
| Poznámkové bloky | Úlohy bez serveru | Bezserverové úlohy, klasické úlohy, klasické all-purpose |
| Skript jazyka Python | Úlohy bez serveru | Bezserverové úlohy, klasické úlohy, klasické all-purpose |
| Kolečko Pythonu | Úlohy bez serveru | Bezserverové úlohy, klasické úlohy, klasické all-purpose |
| SQL | Bezserverový SQL Warehouse | Bezserverový SQL Warehouse, pro SQL Warehouse |
| Pracovní postup Delta Live Tables | Bezserverový kanál | Bezserverový kanál, klasický kanál |
| dbt | Bezserverový SQL Warehouse | Bezserverový SQL Warehouse, pro SQL Warehouse |
| příkazy rozhraní příkazového řádku dbt | Úlohy bez serveru | Bezserverové úlohy, klasické úlohy, klasické all-purpose |
| JAR | Klasické úlohy | Klasické úlohy, klasické all-purpose |
| Odeslání Sparku | Klasické úlohy | Klasické úlohy |
Ceny pro úlohy jsou svázané s výpočetními prostředky používanými ke spouštění úloh. Další podrobnosti najdete v tématu o cenách Databricks.
Návody nakonfigurovat výpočetní prostředky pro úlohy?
Klasické výpočetní úlohy se konfigurují přímo z uživatelského rozhraní úloh Databricks a tyto konfigurace jsou součástí definice úlohy. Všechny ostatní dostupné typy výpočetních prostředků ukládají své konfigurace s jinými prostředky pracovního prostoru. Další podrobnosti najdete v následující tabulce:
| Typ výpočetních prostředků | Detaily |
|---|---|
| Výpočetní prostředky klasických úloh | Výpočetní prostředky pro klasické úlohy konfigurujete pomocí stejného uživatelského rozhraní a nastavení, která jsou k dispozici pro výpočetní prostředí pro všechny účely. Viz referenční informace ke konfiguraci služby Compute. |
| Bezserverové výpočetní prostředky pro úlohy | Bezserverové výpočetní prostředky pro úlohy jsou výchozí pro všechny úlohy, které ho podporují. Databricks spravuje nastavení výpočetních prostředků pro bezserverové výpočetní prostředky. Viz Spuštění úlohy Azure Databricks s bezserverovými výpočetními prostředky pro pracovní postupy. Správce pracovního prostoru musí povolit bezserverové výpočetní prostředky, aby byla tato možnost viditelná. Viz Povolení výpočetních prostředků bez serveru. |
| SQL Warehouses | Bezserverové a profesionální služby SQL Warehouse konfigurují správci pracovního prostoru nebo uživatelé s neomezenými oprávněními k vytváření clusteru. Konfigurujete úlohy, které se mají spouštět s existujícími sklady SQL. Viz Připojení ke službě SQL Warehouse. |
| Výpočet potrubí Delta Live Tables | Při konfiguraci kanálu nastavujete nastavení výpočetního prostředí pro kanály Delta Live Tables. Viz Konfigurace výpočetních prostředků pro kanál Delta Live Tables. nn Azure Databricks spravuje výpočetní prostředky pro bezserverové kanály Delta Live Tables. Viz Konfigurovat bezserverový kanál Delta Live Tables. |
| Výpočetní prostředky pro všechny účely | Volitelně můžete nakonfigurovat úlohy pomocí klasického výpočetního prostředí pro všechny účely. Databricks tuto konfiguraci nedoporučuje pro produkční úlohy. Viz Referenční informace o konfiguraci výpočetních prostředků a Měli byste pro úlohy někdy používat výpočetní prostředky pro všechny účely. |
Sdílení výpočetních prostředků mezi úkoly
Nakonfigurujte úlohy tak, aby využívaly stejné výpočetní prostředky, a tím optimalizovaly využití zdrojů při práci s úlohami, které orchestrují více úloh. Sdílení výpočetních prostředků mezi úkoly může snížit latenci spojenou s časem spuštění.
Pomocí jednoho výpočetního prostředku úlohy můžete spouštět všechny úlohy, které jsou součástí úlohy, nebo více prostředků úloh optimalizovaných pro konkrétní úlohy. Všechny výpočetní úlohy nakonfigurované jako součást úlohy jsou k dispozici pro všechny ostatní úkoly v úloze.
Následující tabulka uvádí rozdíly mezi výpočetními úlohami nakonfigurovaným pro jeden úkol a výpočetními úlohami sdílenými mezi úkoly:
| Jeden úkol | Sdíleno mezi úkoly | |
|---|---|---|
| Spustit | Jakmile se spustí úloha, spustí se. | Když se spustí první úloha nakonfigurovaná tak, aby používala výpočetní prostředek, začne. |
| Terminate (Ukončení) | Po spuštění úlohy. | Po dokončení úlohy nakonfigurované pro použití výpočetního prostředku se spustí. |
| Nečinné výpočetní prostředky | Nevztahuje se. | Výpočetní prostředky zůstávají zapnuté a nečinné, zatímco úlohy, které nepoužívají spuštění výpočetního prostředku. |
Cluster sdílených úloh je vymezený na jeden spuštění úlohy a nemůže ho používat jiné úlohy ani spuštění stejné úlohy.
Knihovny nelze deklarovat v konfiguraci clusteru sdílených úloh. V nastavení úloh musíte přidat závislé knihovny.
Kontrola, konfigurace a prohození výpočetních úloh
Část Výpočty na panelu Podrobností úlohy obsahuje seznam všech výpočetních prostředků nakonfigurovaných pro úkoly v aktuální úloze.
Úkoly nakonfigurované tak, aby používaly výpočetní prostředek, se v grafu úkolů zvýrazní, když najedete myší na specifikaci výpočetních prostředků.
Pomocí tlačítka Prohodit můžete změnit výpočetní prostředky pro všechny úkoly přidružené k výpočetnímu prostředku.
Klasické výpočetní prostředky úloh mají možnost Konfigurovat . Další výpočetní prostředky umožňují zobrazit a upravit podrobnosti konfigurace výpočetních prostředků.
Doporučení pro konfiguraci výpočetních prostředků klasických úloh
Tato část se zaměřuje na obecná doporučení týkající se funkcí a konfigurací, které můžou užitek z některých pracovních postupů. Konkrétní doporučení pro konfiguraci velikosti a typů výpočetních prostředků se liší v závislosti na úloze.
Databricks doporučuje povolit Photon Acceleration, používat nejnovější verze Databricks Runtime a používat výpočty nakonfigurované pro Katalog Unity.
Bezserverové výpočetní prostředky pro úlohy spravují veškerou infrastrukturu a eliminují následující aspekty. Viz Spuštění úlohy Azure Databricks s bezserverovými výpočetními prostředky pro pracovní postupy.
Poznámka:
Pracovní postupy strukturovaného streamování mají konkrétní doporučení. Viz aspekty produkce strukturovaného streamování.
Použití režimu sdíleného přístupu
Databricks doporučuje pro úlohy používat režim sdíleného přístupu. Viz režimy Accessu.
Poznámka:
Režim sdíleného přístupu nepodporuje některé úlohy a funkce. Databricks doporučuje pro tyto úlohy režim přístupu jednoho uživatele. Viz omezení výpočetního přístupu v režimu pro katalog Unity.
Použití zásad clusteru
Databricks doporučuje, aby správci pracovního prostoru definovali zásady clusteru pro úlohy a vynucovali tyto zásady pro všechny uživatele, kteří konfigurují úlohy.
Zásady clusteru umožňují správcům pracovního prostoru nastavit řízení nákladů a omezit možnosti konfigurace uživatelů. Podrobnosti o konfiguraci zásad clusteru najdete v tématu Vytváření a správa zásad výpočetních prostředků.
Azure Databricks poskytuje výchozí zásady nakonfigurované pro úlohy. Správci můžou tuto zásadu zpřístupnit ostatním uživatelům pracovního prostoru. Viz Výpočty úloh.
Použití automatického škálování
Nakonfigurujte automatické škálování tak, aby dlouhotrvající úlohy mohly dynamicky přidávat a odebírat pracovní uzly během spuštění úloh. Viz část Povolení automatického škálování.
Použití fondu ke zkrácení doby spuštění clusteru
Fondy výpočetních prostředků umožňují rezervovat výpočetní prostředky od poskytovatele cloudu. Fondy jsou užitečné snížit čas spuštění nového clusteru úloh a zajistit dostupnost výpočetních prostředků. Viz referenční informace o konfiguraci fondu.
Použití spotových instancí
Nakonfigurujte spotové instance pro úlohy, které mají laxní požadavky na latenci pro optimalizaci nákladů. Viz spotové instance.
Měly by se pro úlohy někdy používat výpočetní prostředky pro všechny účely?
Databricks doporučuje pro úlohy používat výpočetní prostředky pro všechny účely, a to i z následujících důvodů:
- Azure Databricks účtuje výpočetní prostředky pro všechny účely za jinou sazbu než výpočetní prostředky úloh.
- Výpočetní výkon úloh se po dokončení úlohy automaticky ukončí. Všechny účely výpočetních prostředků podporují automatické ukončení, které je svázané s nečinností, a ne ke konci spuštění úlohy.
- Výpočetní prostředky pro celý účel se často sdílejí napříč týmy uživatelů. Úlohy naplánované na výpočetní prostředky pro všechny účely mají často zvýšenou latenci kvůli konkurenci výpočetních prostředků.
- Řada doporučení pro optimalizaci konfigurace výpočetních prostředků úloh není vhodná pro typ ad hoc dotazů a interaktivních úloh spuštěných na výpočetních prostředcích pro všechny účely.
Níže jsou uvedené případy použití, ve kterých se můžete rozhodnout pro použití výpočetních prostředků pro úlohy pro všechny účely:
- Iterativní vývoj nebo testování nových úloh. Doba spuštění výpočetních úloh může usnadnit iterativní vývoj. Výpočetní prostředky pro všechny účely umožňují rychle použít změny a spustit úlohu.
- Máte krátkodobé úlohy, které se musí spouštět často nebo podle určitého plánu. K aktuálně spuštěným výpočetním prostředkům pro všechny účely není přidružený žádný čas spuštění. Zvažte náklady spojené s nečinným časem, pokud používáte tento model.
Bezserverové výpočetní prostředky pro úlohy jsou doporučenou náhradou za většinu typů úloh, které byste mohli zvážit při použití výpočetních prostředků pro všechny účely.