Úvod do RAG ve vývoji umělé inteligence
Tento článek je úvodem k načítání rozšířené generace (RAG): co je, jak funguje, a klíčové koncepty.
Co je generování rozšířeného načítání?
RAG je technika, která umožňuje rozsáhlému jazykovému modelu (LLM) generovat rozšířené odpovědi rozšířením výzvy uživatele s podporou dat načtených z vnějšího zdroje informací. Díky začlenění těchto načtených informací RAG umožňuje LLM vytvářet přesnější a kvalitnější odpovědi v porovnání s tím, když výzva není rozšířena o další kontext.
Předpokládejme například, že vytváříte chatovacího robota pro otázky a odpovědi, který zaměstnancům pomůže zodpovědět otázky týkající se vlastnických dokumentů vaší společnosti. Samostatný LLM nebude moct přesně odpovídat na otázky týkající se obsahu těchto dokumentů, pokud na ně nebyl speciálně vytrénován. LLM může odmítnout odpovědět z důvodu nedostatku informací nebo ještě horší může vygenerovat nesprávnou odpověď.
RAG tento problém řeší tak, že nejprve načte relevantní informace z dokumentů společnosti na základě dotazu uživatele a pak poskytne načtené informace do LLM jako další kontext. LlM tak může vygenerovat přesnější odpověď tím, že na základě konkrétních podrobností nalezených v příslušných dokumentech vygeneruje přesnější odpověď. Rag v podstatě umožňuje LLM "konzultovat" načtené informace, aby formuloval svou odpověď.
Základní komponenty aplikace RAG
Aplikace RAG je příkladem složeného systému AI: Rozšiřuje možnosti jazyka samotného modelu tím, že ho zkombinuje s jinými nástroji a postupy.
Při použití samostatného LLM odešle uživatel do LLM žádost, například otázku, a LLM odpoví odpovědí výhradně na základě svých trénovacích dat.
Ve své nejzásadnější podobě dochází v aplikaci RAG k následujícím krokům:
- Načtení: Požadavek uživatele se používá k dotazování některých mimo zdroj informací. To může znamenat dotazování na úložiště vektorů, provádění vyhledávání klíčových slov přes nějaký text nebo dotazování databáze SQL. Cílem kroku načtení je získat podpůrná data , která pomáhají LLM poskytovat užitečnou odpověď.
- Rozšíření: Podpůrná data z kroku načítání se zkombinují s požadavkem uživatele, často pomocí šablony s dalším formátováním a pokyny k LLM, aby se vytvořila výzva.
- Generování: Výsledná výzva se předá LLM a LLM vygeneruje odpověď na požadavek uživatele.
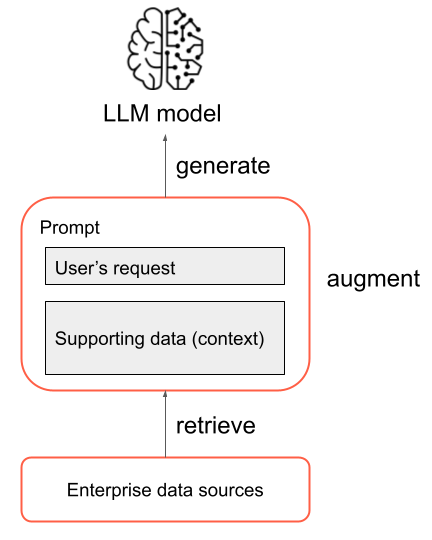
Jedná se o zjednodušený přehled procesu RAG, ale je důležité si uvědomit, že implementace aplikace RAG zahrnuje mnoho složitých úloh. Předběžné zpracování zdrojových dat, které je vhodné pro použití v RAG, efektivní načítání dat, formátování rozšířené výzvy a vyhodnocení vygenerovaných odpovědí vyžadují pečlivé zvážení a úsilí. Tato témata budou podrobněji popsána v dalších částech tohoto průvodce.
Proč používat RAG?
Následující tabulka popisuje výhody použití RAG oproti samostatnému LLM:
| Samotná LLM | Použití LLM s RAG |
|---|---|
| Žádné proprietární znalosti: LLM se obecně trénují na veřejně dostupná data, takže nemůžou přesně odpovídat na otázky týkající se interních nebo vlastnických dat společnosti. | Aplikace RAG můžou obsahovat proprietární data: Aplikace RAG může do LLM dodávat proprietární dokumenty, jako jsou memo, e-maily a návrhové dokumenty, což umožňuje odpovědět na otázky týkající se těchto dokumentů. |
| Znalosti se neaktualizují v reálném čase: LLM nemají přístup k informacím o událostech, ke kterým došlo po jejich vytrénované. Například samostatný LLM vám dnes o pohybech akcií nic neřekne. | Aplikace RAG můžou přistupovat k datům v reálném čase: Aplikace RAG může poskytnout LLM včasnými informacemi z aktualizovaného zdroje dat, což jí umožní poskytnout užitečné odpovědi na události po datu ukončení trénování. |
| Nedostatek citací: LLM nemůžou při odpovídání citovat konkrétní zdroje informací, takže uživatel nemůže ověřit, jestli je odpověď fakticky správná, nebo halucinace. | RAG může citovat zdroje: Při použití v rámci aplikace RAG může být LLM požádán o citování svých zdrojů. |
| Nedostatek řízení přístupu k datům (ACL): Samotné LLM nemůžou spolehlivě poskytovat různé odpovědi různým uživatelům na základě konkrétních uživatelských oprávnění. | RAG umožňuje zabezpečení dat nebo seznamy ACL: Krok načtení je možné navrhnout tak, aby našel pouze informace, ke kterým má uživatel přihlašovací údaje pro přístup, což aplikaci RAG umožňuje selektivně načíst osobní nebo proprietární informace. |
Typy RAG
Architektura RAG může fungovat se dvěma typy podpůrných dat:
| Strukturovaná data | Nestrukturovaná data | |
|---|---|---|
| Definice | Tabulková data uspořádaná do řádků a sloupců s určitým schématem, například tabulky v databázi. | Data bez konkrétní struktury nebo organizace, například dokumenty, které obsahují text a obrázky nebo multimediální obsah, jako je zvuk nebo videa. |
| Příklady zdrojů dat | - Záznamy zákazníků v systému BI nebo datového skladu – Transakční data z databáze SQL – Data z rozhraní API aplikací (například SAP, Salesforce atd.) |
- Záznamy zákazníků v systému BI nebo datového skladu – Transakční data z databáze SQL – Data z rozhraní API aplikací (například SAP, Salesforce atd.) – PDF soubory - Dokumenty Google nebo systém Microsoft Office - Wikiweby -Obrazy -Videa |
Výběr dat pro RAG závisí na vašem případu použití. Zbývající část kurzu se zaměřuje na RAG pro nestrukturovaná data.