Vývoj kódu kanálu pomocí Pythonu
DLT zavádí několik nových konstruktů Python kódu pro definování materializovaných zobrazení a streamovaných tabulek v pipelinech. Podpora Pythonu pro vývoj kanálů vychází ze základních funkcí PySpark DataFrame a rozhraní API strukturovaného streamování.
Pro uživatele, kteří nezná Python a datové rámce, databricks doporučuje používat rozhraní SQL. Viz Vývoj kódu kanálu pomocí SQL.
Úplná dokumentace syntaxe jazyka DLT Python je k dispozici v referenční příručce jazyka DLT Python.
Základy Pythonu pro vývoj pipelinů
Kód Pythonu, který vytváří datové sady DLT, musí vracet datové rámce.
Všechna rozhraní DLLT Python API se implementují v modulu dlt. Kód kanálu DLT implementovaný pomocí Pythonu musí explicitně importovat modul dlt v horní části poznámkových bloků a souborů Pythonu.
Čtení a zápisy se ve výchozím nastavení provádějí v katalogu a schématu zadaném během konfigurace kanálu. Viz Nastavení cílového katalogu aschématu .
Kód Pythonu specifický pro DLT se liší od jiných typů kódu Pythonu jedním kritickým způsobem: Kód kanálu Pythonu přímo nevyvolá funkce, které provádějí ingestování a transformaci dat za účelem vytváření datových sad DLT. Místo toho DLT interpretuje funkce dekorátoru z modulu dlt ve všech souborech zdrojového kódu nakonfigurovaných v zpracovatelském řetězci a sestaví graf toku dat.
Důležitý
Abyste se vyhnuli neočekávanému chování při spuštění kanálu, nezahrňte kód, který může mít vedlejší účinky, do funkcí, které definují datové sady. Další informace najdete v referenčních příručkách Pythonu.
Vytvoření materializovaného zobrazení nebo tabulky streamování pomocí Pythonu
Dekorátor @dlt.table přiřazuje úkol DLT, aby na základě výsledků vrácených funkcí vytvořil materializované zobrazení nebo dynamicky streamovanou tabulku. Výsledky dávkového čtení vytvoří materializovaný pohled, zatímco výsledky streamovaného čtení vytvoří streamovanou tabulku.
Ve výchozím nastavení jsou materializované názvy tabulek zobrazení a streamovaných tabulek odvozeny z názvů funkcí. Následující příklad kódu ukazuje základní syntaxi pro vytvoření materializované tabulky zobrazení a streamování:
Poznámka
Obě funkce odkazují na stejnou tabulku v katalogu samples a používají stejnou funkci dekorátoru. Tyto příklady zvýrazňují, že jediný rozdíl v základní syntaxi materializovaných zobrazení a streamovaných tabulek je použití spark.read oproti spark.readStream.
Ne všechny zdroje dat podporují čtení streamování. Některé zdroje dat by se měly vždy zpracovávat sémantikou streamování.
import dlt
@dlt.table()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Volitelně můžete název tabulky zadat pomocí argumentu name v dekorátoru @dlt.table. Následující příklad ukazuje tento model pro materializované zobrazení a streamovací tabulku:
import dlt
@dlt.table(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Načtení dat z úložiště objektů
DLT podporuje načítání dat ze všech formátů podporovaných službou Azure Databricks. Viz Možnosti formátu dat.
Poznámka
Tyto příklady používají data dostupná v /databricks-datasets automaticky připojená k vašemu pracovnímu prostoru. Databricks doporučuje používat cesty svazků nebo cloudové identifikátory URI k odkazování na data uložená v cloudovém úložišti objektů. Podívejte se na Co jsou svazky katalogu Unity?.
Databricks doporučuje používat Auto Loader a streamovací tabulky při konfiguraci úloh pro inkrementální příjem dat z dat uložených v cloudovém objektovém úložišti. Podívejte se na Co je Auto Loader?.
Následující příklad ukazuje, jak vytvořit streamovací tabulku ze souborů JSON pomocí Auto Loaderu:
import dlt
@dlt.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Následující příklad používá sémantiku dávky ke čtení adresáře JSON a vytvoření materializovaného zobrazení:
import dlt
@dlt.table()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Ověření dat s očekáváními
Pomocí očekávání můžete nastavit a vynutit omezení kvality dat. Viz Řídit kvalitu dat pomocí očekávání datového kanálu.
Následující kód pomocí @dlt.expect_or_drop definuje očekávanou pojmenovanou valid_data, která během příjmu dat zahodí záznamy, které mají hodnotu null:
import dlt
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Dotaz na materializovaná zobrazení a streamované tabulky definované ve vašem datovém proudu
Následující příklad definuje čtyři datové sady:
- Streamovaná tabulka s názvem
orders, která načítá data JSON. - Materializované zobrazení s názvem
customers, které načte data CSV. - Materializované zobrazení s názvem
customer_orders, které spojuje záznamy z datových sadordersacustomers, přetypuje časové razítko objednávky na datum a vybere polecustomer_id,order_number,stateaorder_date. - Materializované zobrazení s názvem
daily_orders_by_state, které agreguje denní počet objednávek pro každý stav.
Poznámka
Při dotazování zobrazení nebo tabulek v kanálu můžete přímo zadat katalog a schéma nebo můžete použít výchozí hodnoty nakonfigurované v kanálu. V tomto příkladu se tabulky orders, customersa customer_orders zapisují a čtou z výchozího katalogu a schématu nakonfigurovaného pro váš kanál.
Starší způsob publikace používá schéma LIVE k dotazování jiných materializovaných zobrazení a streamovaných tabulek definovaných ve vašem datovém toku. V nových potrubích je syntaxe schématu LIVE ignorována bez upozornění. Viz LIVE schema (starší verze).
import dlt
from pyspark.sql.functions import col
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dlt.table()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dlt.table()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dlt.table()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Vytváření tabulek ve smyčce for
Smyčky for Pythonu můžete použít k programovému vytvoření více tabulek. To může být užitečné v případě, že máte mnoho zdrojů dat nebo cílových datových sad, které se liší pouze několika parametry, což vede k menšímu celkovému kódu pro zachování a snížení redundance kódu.
Smyčka for vyhodnocuje logiku v sériovém pořadí, ale po dokončení plánování datových sad kanál spouští logiku paralelně.
Důležitý
Při použití tohoto vzoru pro definování datových sad se ujistěte, že seznam hodnot předaných do smyčky for je vždy aditivní. Pokud je datová sada dříve definovaná v kanálu vynechána z budoucího spuštění kanálu, tato datová sada se automaticky zahodí z cílového schématu.
Následující příklad vytvoří pět tabulek, které filtrují objednávky zákazníků podle oblastí. V tomto případě se název oblasti používá k nastavení názvu cílových materializovaných zobrazení a k filtrování zdrojových dat. Dočasná zobrazení slouží k definování spojení ze zdrojových tabulek používaných při vytváření konečných materializovaných zobrazení.
import dlt
from pyspark.sql.functions import collect_list, col
@dlt.view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dlt.view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dlt.table(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Následuje příklad grafu toku dat pro tento kanál:
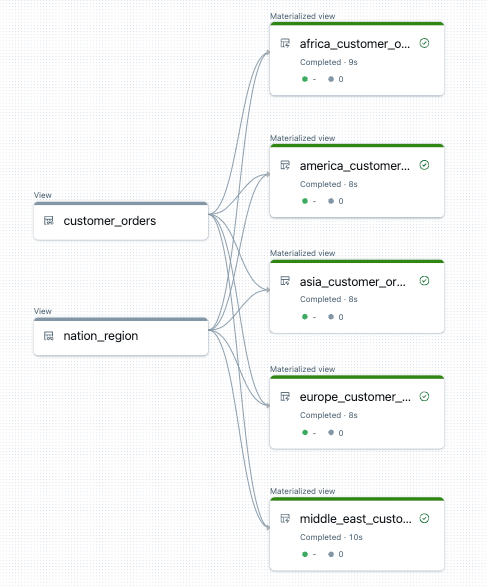
Řešení potíží: smyčka for vytváří mnoho tabulek se stejnými hodnotami
Opožděný model spouštění, který pipeliny používají k vyhodnocení kódu Pythonu, vyžaduje, aby logika přímo odkazovala na jednotlivé hodnoty, když je vyvolána funkce dekorovaná @dlt.table().
Následující příklad ukazuje dva správné přístupy k definování tabulek pomocí smyčky for. V obou příkladech je každý název tabulky ze seznamu tables explicitně odkazován v rámci funkce zdobené @dlt.table().
import dlt
# Create a parent function to set local variables
def create_table(table_name):
@dlt.table(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dlt.table()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
Následující příklad hodnoty odkazu správně. Tento příklad vytvoří tabulky s jedinečnými názvy, ale všechny tabulky načítají data z poslední hodnoty ve smyčce for:
import dlt
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table():
return spark.read.table(t_name)