Funkce rozšíření Sady prostředků Databricks
Rozšíření Databricks pro Visual Studio Code poskytuje další funkce v nástroji Visual Studio Code, které umožňují snadno definovat, nasazovat a spouštět sady prostředků Databricks a používat osvědčené postupy CI/CD pro úlohy Azure Databricks, kanály Delta Live Tables a zásobníky MLOps. Podívejte se, co jsou sady prostředků Databricks?
Pokud chcete nainstalovat rozšíření Databricks pro Visual Studio Code, přečtěte si téma Instalace rozšíření Databricks pro Visual Studio Code.
Podpora sad prostředků Databricks v projektech
Rozšíření Databricks pro Visual Studio Code přidává následující funkce pro projekty Sady prostředků Databricks:
- Snadné ověřování a konfigurace sad prostředků Databricks prostřednictvím uživatelského rozhraní editoru Visual Studio Code, včetně výběru profilu AuthType . Viz Nastavení autorizace pro rozšíření Databricks pro Visual Studio Code.
- Výběr cíle na panelu rozšíření Databricks pro rychlé přepínání mezi cílovými prostředími sady. Viz Změna pracovního prostoru cílového nasazení.
- Cluster Přepsat úlohy v sadě možnost na panelu rozšíření, aby bylo možné snadné přepsání clusteru.
- Zobrazení Průzkumník prostředků Bundles, které umožňuje procházet prostředky sady prostředků pomocí uživatelského rozhraní editoru Visual Studio Code, nasazovat místní prostředky sady prostředků Databricks do vzdáleného pracovního prostoru Azure Databricks jediným kliknutím a přejít přímo k nasazeným prostředkům v pracovním prostoru ze sady Visual Studio Code. Viz Průzkumník prostředků sady prostředků.
- Zobrazení proměnných sady bundles, které umožňuje procházet a upravovat proměnné sady pomocí uživatelského rozhraní editoru Visual Studio Code. Viz zobrazení proměnných sady.
Průzkumník prostředků sady prostředků
Průzkumník prostředků sady zobrazení v rozšíření Databricks pro Visual Studio Code používá definice prostředků v konfiguraci sady prostředků projektu k zobrazení prostředků, včetně datových sad kanálů a jejich schémat. Umožňuje také nasazovat a spouštět prostředky, ověřovat a provádět částečné aktualizace kanálů, zobrazit události spuštění kanálu a diagnostiku a přejít k prostředkům ve vzdáleném pracovním prostoru Azure Databricks. Informace o prostředcích konfigurace sady najdete v tématu prostředky.
Například s ohledem na jednoduchou definici úlohy:
resources:
jobs:
my-notebook-job:
name: "My Notebook Job"
tasks:
- task_key: notebook-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: notebooks/my-notebook.py
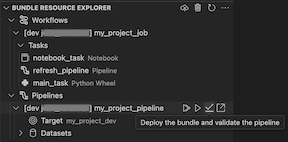
Zobrazení Průzkumníka prostředků sady prostředků v rozšíření zobrazí prostředek úlohy poznámkového bloku:
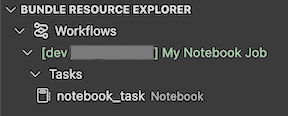
Nasazení a spuštění úlohy
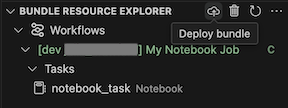
Pokud chcete sadu nasadit, klikněte na ikonu cloudu (nasadit sadu).
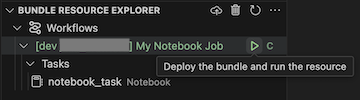
Pokud chcete úlohu spustit, v zobrazení Bundle Resource Explorer vyberte název úlohy, což je Úloha poznámkového bloku v tomto příkladu. Potom klikněte na ikonu přehrát (nasaďte sadu a spusťte prostředek).
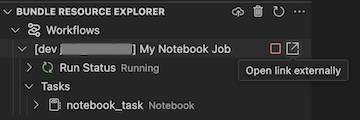
Pokud chcete zobrazit spuštěnou úlohu, rozbalte v zobrazení Průzkumník prostředků sady, rozbalte název úlohy, klikněte na spustit stav a potom klikněte na ikonu odkazu (otevřít odkaz externě).
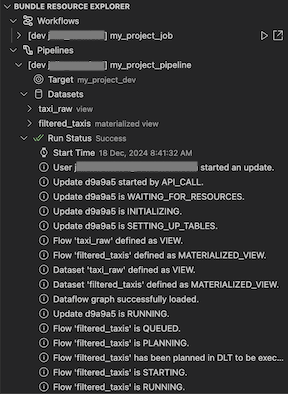
Ověření a diagnostika problémů s potrubím
V případě pipeline můžete aktivovat ověření a částečnou aktualizaci tím, že nejprve vyberete pipeline a poté kliknete na ikonu (Nasadit sadu a ověřit pipeline). Zobrazí se události spuštění a všechna selhání se dají diagnostikovat v nástroji Visual Studio Code problémy panelu.
 kanálu
kanálu
Zobrazení proměnných sady
Zobrazení Zobrazení proměnných sady prostředků v rozšíření Databricks pro Visual Studio Code zobrazí všechny vlastní proměnné a přidružená nastavení definovaná v konfiguraci sady prostředků. Můžete také definovat proměnné přímo pomocí zobrazení Bundles Variables. Tyto hodnoty přepíší ty, které jsou nastavené v konfiguračních souborech sady. Informace o vlastních proměnných najdete v tématu Vlastní proměnné.
Například zobrazení zobrazení Proměnné sady prostředků v rozšíření by zobrazilo následující:

Pro proměnnou my_custom_var definovanou v této konfiguraci sady:
variables:
my_custom_var:
description: "Max workers"
default: "4"
resources:
jobs:
my_job:
name: my_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: ${var.my_custom_var}