CI/CD s Jenkinsem v Azure Databricks
Poznámka:
Tento článek se zabývá Jenkinsem, který vyvíjí třetí strana. Pokud chcete kontaktovat poskytovatele, přečtěte si nápovědu Jenkinse.
Ke správě a spouštění kanálů CI/CD můžete použít celou řadu nástrojů CI/CD. Tento článek ukazuje, jak používat automatizační server Jenkinse . CI/CD je vzor návrhu, takže kroky a fáze popsané v tomto článku by se měly přenést s několika změnami jazyka definice kanálu v jednotlivých nástrojích. Většina kódu v tomto ukázkovém kanálu navíc spouští standardní kód Pythonu, který můžete vyvolat v jiných nástrojích. Přehled CI/CD v Azure Databricks najdete v tématu Co je CI/CD v Azure Databricks?.
Informace o použití Azure DevOps s Azure Databricks najdete v tématu Kontinuální integrace a doručování v Azure Databricks pomocí Azure DevOps.
Pracovní postup vývoje CI/CD
Databricks navrhuje následující pracovní postup pro vývoj CI/CD s Využitím Jenkinse:
- Vytvořte úložiště nebo použijte existující úložiště s vaším poskytovatelem Gitu třetí strany.
- Připojte místní vývojový počítač ke stejnému úložišti třetích stran. Pokyny najdete v dokumentaci poskytovatele Gitu třetí strany.
- Přetáhněte všechny existující aktualizované artefakty (například poznámkové bloky, soubory kódu a skripty sestavení) z úložiště třetí strany do místního vývojového počítače.
- Podle potřeby vytvořte, aktualizujte a otestujte artefakty na místním vývojovém počítači. Pak nasdílejte všechny nové a změněné artefakty z místního vývojového počítače do úložiště třetí strany. Pokyny najdete v dokumentaci poskytovatele Gitu třetí strany.
- Podle potřeby opakujte kroky 3 a 4.
- Jenkins se pravidelně používá jako integrovaný přístup k automatickému načítání artefaktů z úložiště třetí strany do místního vývojového počítače nebo pracovního prostoru Azure Databricks. sestavování, testování a spouštění kódu na místním vývojovém počítači nebo pracovním prostoru Azure Databricks; a hlášení výsledků testů a spuštění. I když jenkinse můžete spustit ručně, v implementacích v reálném světě byste svému externímu poskytovateli Gitu řekli, aby spouštěl Jenkinse pokaždé, když dojde k určité události, jako je například žádost o přijetí změn úložiště.
Zbytek tohoto článku používá ukázkový projekt, který popisuje jeden ze způsobů, jak pomocí Jenkinse implementovat předchozí pracovní postup vývoje CI/CD.
Informace o používání Azure DevOps místo Jenkinse najdete v tématu Kontinuální integrace a doručování v Azure Databricks pomocí Azure DevOps.
Nastavení místního vývojového počítače
Příklad tohoto článku používá Jenkinse k tomu, aby dal pokyn k sadě prostředků Databricks a Databricks k provedení následujících kroků:
- Vytvořte soubor kola Pythonu na místním vývojovém počítači.
- Nasaďte vytvořený soubor kola Pythonu spolu s dalšími soubory Pythonu a poznámkovými bloky Pythonu z místního vývojového počítače do pracovního prostoru Azure Databricks.
- Otestujte a spusťte nahraný soubor kol Pythonu a poznámkové bloky v daném pracovním prostoru.
Pokud chcete nastavit místní vývojový počítač, aby dal pracovnímu prostoru Azure Databricks pokyn k provedení fází sestavení a nahrání v tomto příkladu, udělejte na místním vývojovém počítači následující:
Krok 1: Instalace požadovaných nástrojů
V tomto kroku nainstalujete nástroje pro sestavení kol Jenkinse, Jenkinse a Databricks jqna místním vývojovém počítači. Tyto nástroje jsou potřeba ke spuštění tohoto příkladu.
Pokud jste to ještě neudělali, nainstalujte Databricks CLI verze 0.205 nebo vyšší. Jenkins používá rozhraní příkazového řádku Databricks k předání tohoto příkladu testu a spuštění pokynů k vašemu pracovnímu prostoru. Viz Instalace nebo aktualizace rozhraní příkazového řádku Databricks.
Pokud jste to ještě neudělali, nainstalujte a spusťte Jenkinse. Viz Instalace Jenkinse pro Linux, macOS nebo Windows.
Nainstalujte jq. Tento příklad používá
jqk analýze výstupu příkazu ve formátu JSON.Použijte
pipk instalaci nástrojů pro sestavení kol Pythonu pomocí následujícího příkazu (některé systémy můžou vyžadovat, abyste místopip3pip):pip install --upgrade wheel
Krok 2: Vytvoření kanálu Jenkinse
V tomto kroku pomocí Jenkinse vytvoříte kanál Jenkinse pro příklad tohoto článku. Jenkins nabízí několik různých typů projektů pro vytváření kanálů CI/CD. Jenkins Pipelines poskytuje rozhraní pro definování fází v kanálu Jenkinse pomocí kódu Groovy pro volání a konfiguraci modulů plug-in Jenkins.
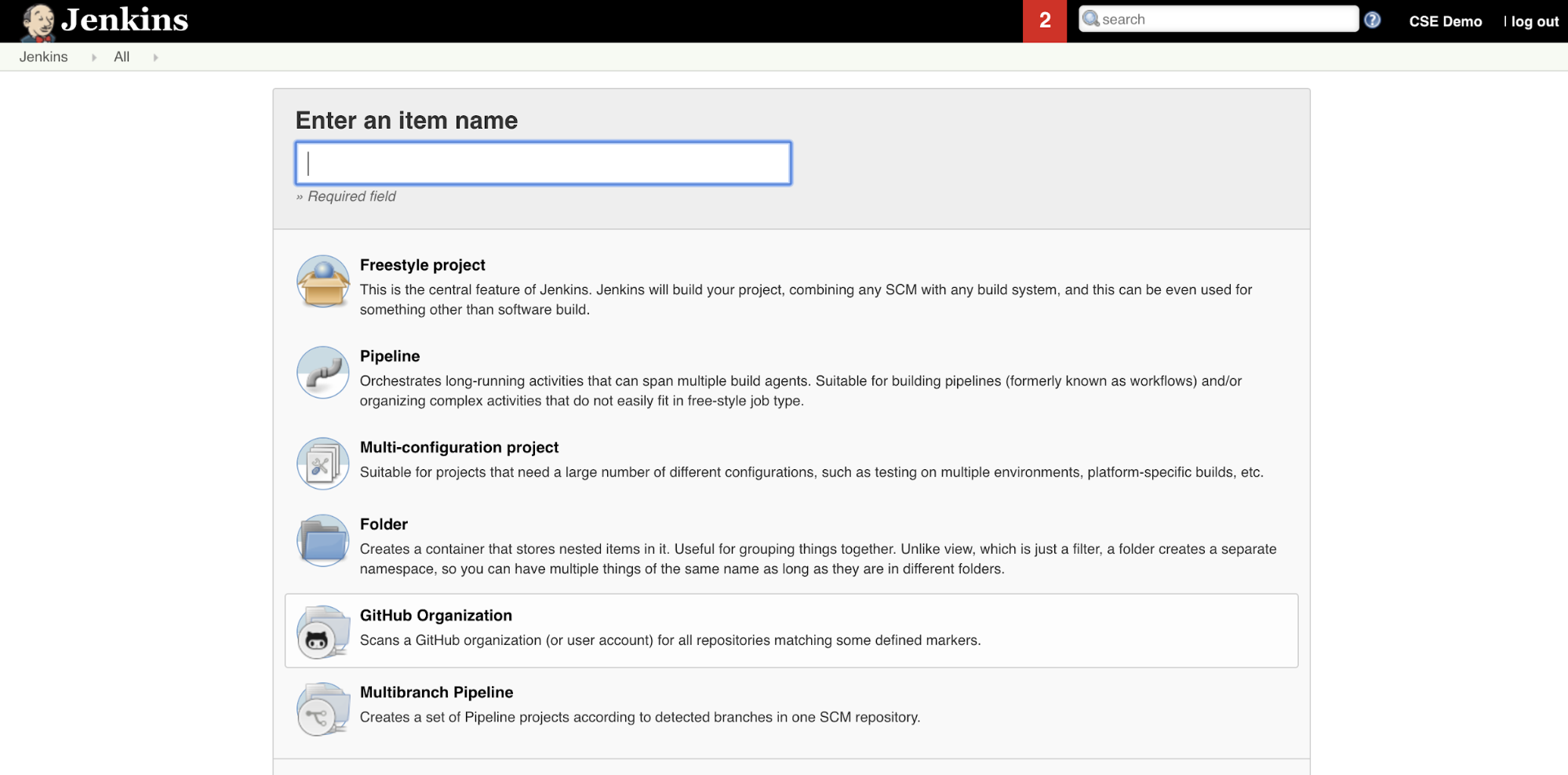
Vytvoření kanálu Jenkinse v Jenkinsi:
- Po spuštění Jenkinse klikněte na řídicím panelu Jenkinse na Nová položka.
- Jako název položky zadejte název kanálu Jenkinse, například
jenkins-demo. - Klikněte na ikonu typu projektu kanálu .
- Klikněte na OK. Zobrazí se stránka Konfigurace kanálu Jenkinse.
- V oblasti Kanálu vyberte v rozevíracím seznamu Defintion skript kanálu z SCM.
- V rozevíracím seznamu SCM vyberte Git.
- Jako adresu URL úložiště zadejte adresu URL úložiště, které je hostované vaším poskytovatelem Git třetí části.
- Jako specifikátor větve zadejte
*/<branch-name>, kde<branch-name>je název větve ve vašem úložišti, který chcete použít, například*/main. - Pro cestu ke skriptu zadejte
Jenkinsfile, pokud ještě není nastaven. Později v tomto článku vytvoříteJenkinsfile. - Zrušte zaškrtnutí políčka s názvem Lightweight checkout(pokud už je zaškrtnuté).
- Klikněte na Uložit.
Krok 3: Přidání globálních proměnných prostředí do Jenkinse
V tomto kroku přidáte do Jenkinse tři globální proměnné prostředí. Jenkins tyto proměnné prostředí předává do rozhraní příkazového řádku Databricks. Rozhraní příkazového řádku Databricks potřebuje hodnoty těchto proměnných prostředí k ověření v pracovním prostoru Azure Databricks. V tomto příkladu se pro instanční objekt používá ověřování M2M (machine-to-machine) OAuth (i když jsou k dispozici i jiné typy ověřování). Chcete-li nastavit autentizaci OAuth M2M pro váš pracovní prostor Azure Databricks, přečtěte si téma Autorizace bezobslužného přístupu k prostředkům Azure Databricks pomocí služebního principálu a OAuth.
V tomto příkladu jsou tři globální proměnné prostředí:
-
DATABRICKS_HOST, nastavte adresu URL pracovního prostoru Azure Databricks počínaje .https://Viz názvy instancí pracovního prostoru, adresy URL a ID. -
DATABRICKS_CLIENT_ID, nastavte na ID klienta instančního objektu, které se označuje také jako ID aplikace. -
DATABRICKS_CLIENT_SECRET, nastavte tajný klíč Azure Databricks OAuth instančního objektu.
Pokud chcete nastavit globální proměnné prostředí v Jenkinse, na řídicím panelu Jenkinse:
- Na bočním panelu klikněte na Spravovat Jenkinse.
- V části Konfigurace systému klepněte na tlačítko Systém.
- V části Globální vlastnosti zaškrtněte políčko s dlaždicemi proměnných prostředí.
- Klikněte na Přidat a zadejte název a hodnotu proměnné prostředí. Tento postup opakujte pro každou další proměnnou prostředí.
- Po dokončení přidávání proměnných prostředí se kliknutím na uložit vraťte na řídicí panel Jenkinse.
Návrh kanálu Jenkinse
Jenkins nabízí několik různých typů projektů pro vytváření kanálů CI/CD. Tento příklad implementuje kanál Jenkinse. Jenkins Pipelines poskytuje rozhraní pro definování fází v kanálu Jenkinse pomocí kódu Groovy pro volání a konfiguraci modulů plug-in Jenkins.
Definici kanálu Jenkinse zapíšete do textového souboru s názvem Jenkinsfile, který je zase vrácen do úložiště správy zdrojového kódu projektu. Další informace najdete v tématu Jenkins Pipeline. Tady je kanál Jenkinse pro příklad tohoto článku. V tomto příkladu Jenkinsfilenahraďte následující zástupné symboly:
- Nahraďte
<user-name>uživatelské<repo-name>jméno a název úložiště hostovaného vaším poskytovatelem Gitu třetí části. Tento článek používá jako příklad adresu URL GitHubu. - Nahraďte
<release-branch-name>názvem větve vydané verze ve vašem úložišti. Může to býtmainnapříklad . - Nahraďte
<databricks-cli-installation-path>cestu na místním vývojovém počítači, kde je nainstalované rozhraní příkazového řádku Databricks. Například v macOS to může být/usr/local/bin. - Nahraďte
<jq-installation-path>cestu na místním vývojovém počítači, na kterémjqje nainstalovaný. Například v macOS to může být/usr/local/bin. - Nahraďte
<job-prefix-name>nějakým řetězcem, který vám pomůže jednoznačně identifikovat úlohy Azure Databricks vytvořené v pracovním prostoru v tomto příkladu. Může to býtjenkins-demonapříklad . - Všimněte si, že
BUNDLETARGETje nastavena nadevhodnotu , což je název cíle sady prostředků Databricks, který je definován dále v tomto článku. V reálných implementacích byste to změnili na název vlastního cíle sady. Další podrobnosti o cílech sady najdete dále v tomto článku.
Tady je soubor Jenkinsfile, který se musí přidat do kořenového adresáře úložiště:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
Zbývající část tohoto článku popisuje jednotlivé fáze tohoto kanálu Jenkinse a jak nastavit artefakty a příkazy pro Jenkinse ke spuštění v této fázi.
Stažení nejnovějších artefaktů z úložiště třetí strany
První fáze v tomto kanálu Jenkinse, fáze Checkout , je definována takto:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Tato fáze zajišťuje, že pracovní adresář, který Jenkins používá na místním vývojovém počítači, má nejnovější artefakty z vašeho úložiště Git třetí strany. Jenkins obvykle nastaví tento pracovní adresář na <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. To vám umožní na stejném místním vývojovém počítači zachovat vlastní kopii artefaktů ve vývoji odděleně od artefaktů, které Jenkins používá z vašeho úložiště Git třetí strany.
Ověření sady prostředků Databricks
Druhá fáze v tomto kanálu Jenkinse, Validate Bundle fáze, je definována takto:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Tato fáze zajišťuje, že sada prostředků Databricks, která definuje pracovní postupy pro testování a spouštění artefaktů, je syntakticky správná. Sady prostředků Databricks, označované jednoduše jako sady prostředků, umožňují vyjádřit kompletní data, analýzy a projekty ML jako kolekci zdrojových souborů. Podívejte se, co jsou sady prostředků Databricks?
Pokud chcete definovat sadu pro tento článek, vytvořte soubor s názvem databricks.yml v kořenovém adresáři klonovaného úložiště na místním počítači. V tomto ukázkovém databricks.yml souboru nahraďte následující zástupné symboly:
- Nahraďte
<bundle-name>jedinečným programovým názvem sady. Může to býtjenkins-demonapříklad . - Nahraďte
<job-prefix-name>nějakým řetězcem, který vám pomůže jednoznačně identifikovat úlohy Azure Databricks vytvořené v pracovním prostoru v tomto příkladu. Může to býtjenkins-demonapříklad . Měla by odpovídat hodnotěJOBPREFIXv souboru Jenkinsfile. - Nahraďte
<spark-version-id>ID verze databricks Runtime pro clustery úloh, například13.3.x-scala2.12. - Nahraďte
<cluster-node-type-id>ID typu uzlu pro clustery úloh, napříkladStandard_DS3_v2. - Všimněte si, že
devvtargetsmapování je stejné jakoBUNDLETARGETv souboru Jenkinsfile. Cíl sady určuje hostitele a související chování nasazení.
Tady je databricks.yml soubor, který se musí přidat do kořenového adresáře úložiště, aby tento příklad fungoval správně:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Další informace o souboru naleznete v databricks.yml tématu Konfigurace sady prostředků Databricks.
Nasazení sady do pracovního prostoru
Třetí fáze kanálu Jenkinse s názvem je definována Deploy Bundletakto:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Tato fáze dělá dvě věci:
- Vzhledem k tomu, že
artifactmapování vdatabricks.ymlsouboru je nastavenéwhl, dává rozhraní příkazového řádku Databricks pokyn k sestavení souboru kola Pythonu pomocísetup.pysouboru v zadaném umístění. - Po vytvoření souboru kola Pythonu na místním vývojovém počítači nasadí rozhraní příkazového řádku Databricks vytvořený soubor kola Pythonu spolu se zadanými soubory a poznámkovými bloky Pythonu do pracovního prostoru Azure Databricks. Ve výchozím nastavení sada prostředků Databricks nasadí soubor kola Pythonu a další soubory do
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Pokud chcete povolit, aby se soubor kola Pythonu vytvořil tak, jak je uvedeno v databricks.yml souboru, vytvořte následující složky a soubory v kořenovém adresáři naklonovaného úložiště na místním počítači.
Pokud chcete definovat logiku a testy jednotek pro soubor kola Pythonu, na kterém se poznámkový blok spustí, vytvořte dva pojmenované addcol.py soubory a test_addcol.pypřidejte je do struktury složek pojmenované python/dabdemo/dabdemo ve složce úložiště Libraries vizualizované následujícím způsobem (tři tečky označují vynechané složky v úložišti pro stručnost):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Soubor addcol.py obsahuje funkci knihovny, která je později integrovaná do souboru kola Pythonu a pak je nainstalovaná v clusteru Azure Databricks. Jedná se o jednoduchou funkci, která do datového rámce Apache Sparku přidá nový sloupec naplněný literálem:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Soubor test_addcol.py obsahuje testy, které předávají napodobení objektu DataFrame funkci with_status definované v addcol.py. Výsledek se pak porovná s objektem DataFrame obsahujícím očekávané hodnoty. Pokud se hodnoty shodují, což v tomto případě proběhne, test projde:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Pokud chcete rozhraní příkazového řádku Databricks povolit správné zabalení kódu knihovny do souboru kola Pythonu, vytvořte dva pojmenované __init__.py soubory a __main__.py ve stejné složce jako předchozí dva soubory. Vytvořte také soubor s názvem setup.py ve python/dabdemo složce vizualizovaný následujícím způsobem (tři tečky označují vynechané složky pro stručnost):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Soubor __init__.py obsahuje číslo verze a autora knihovny. Nahraďte <my-author-name> svým jménem:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Soubor __main__.py obsahuje vstupní bod knihovny:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Soubor setup.py obsahuje další nastavení pro sestavení knihovny do souboru kola Pythonu. Nahraďte <my-url>, <my-author-name>@<my-organization>a <my-package-description> smysluplnými hodnotami:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Testování logiky komponent kolečka Pythonu
Fáze Run Unit Tests , čtvrtá fáze tohoto kanálu Jenkinse, používá pytest k otestování logiky knihovny, aby se ujistila, že funguje jako sestavená. Tato fáze je definována takto:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Tato fáze používá rozhraní příkazového řádku Databricks ke spuštění úlohy poznámkového bloku. Tato úloha spustí poznámkový blok Pythonu s názvem souboru run-unit-test.py. Tento poznámkový blok běží pytest proti logice knihovny.
Pokud chcete spustit testy jednotek pro tento příklad, přidejte do kořenového adresáře naklonovaného úložiště na místním počítači soubor run_unit_tests.py poznámkového bloku Pythonu s následujícím obsahem:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Použití sestaveného kola Pythonu
Pátá fáze tohoto kanálu Jenkinse s názvem Run Notebook, spustí poznámkový blok Pythonu, který volá logiku v integrovaném souboru kola Pythonu následujícím způsobem:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Tato fáze spustí rozhraní příkazového řádku Databricks, které zase dává vašemu pracovnímu prostoru pokyn ke spuštění úlohy poznámkového bloku. Tento poznámkový blok vytvoří objekt datového rámce, předá ho with_status funkci knihovny, vytiskne výsledek a nahlásí výsledky spuštění úlohy. Vytvořte poznámkový blok přidáním souboru poznámkového bloku Pythonu s následujícím dabdaddemo_notebook.py obsahem v kořenovém adresáři naklonovaného úložiště na místním vývojovém počítači:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Vyhodnocení výsledků spuštění úlohy poznámkového bloku
Fáze Evaluate Notebook Runs , šestá fáze tohoto kanálu Jenkinse, vyhodnocuje výsledky předchozího spuštění úlohy poznámkového bloku. Tato fáze je definována takto:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Tato fáze spustí rozhraní příkazového řádku Databricks, které pak dává vašemu pracovnímu prostoru pokyn ke spuštění úlohy souboru Pythonu. Tento soubor Pythonu určuje kritéria selhání a úspěchu pro spuštění úlohy poznámkového bloku a hlásí tento výsledek selhání nebo úspěchu. V kořenovém adresáři naklonovaného úložiště v místním vývojovém počítači vytvořte soubor evaluate_notebook_runs.py s následujícím obsahem:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Import a hlášení výsledků testů
Sedmá fáze tohoto kanálu Jenkinse s názvem Import Test Results, používá rozhraní příkazového řádku Databricks k odeslání výsledků testu z vašeho pracovního prostoru do místního vývojového počítače. Osmá a poslední fáze s názvem , publikuje Publish Test Resultsvýsledky testu jenkins pomocí modulu plug-in junit Jenkins. Díky tomu můžete vizualizovat sestavy a řídicí panely související se stavem výsledků testu. Tyto fáze jsou definovány takto:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
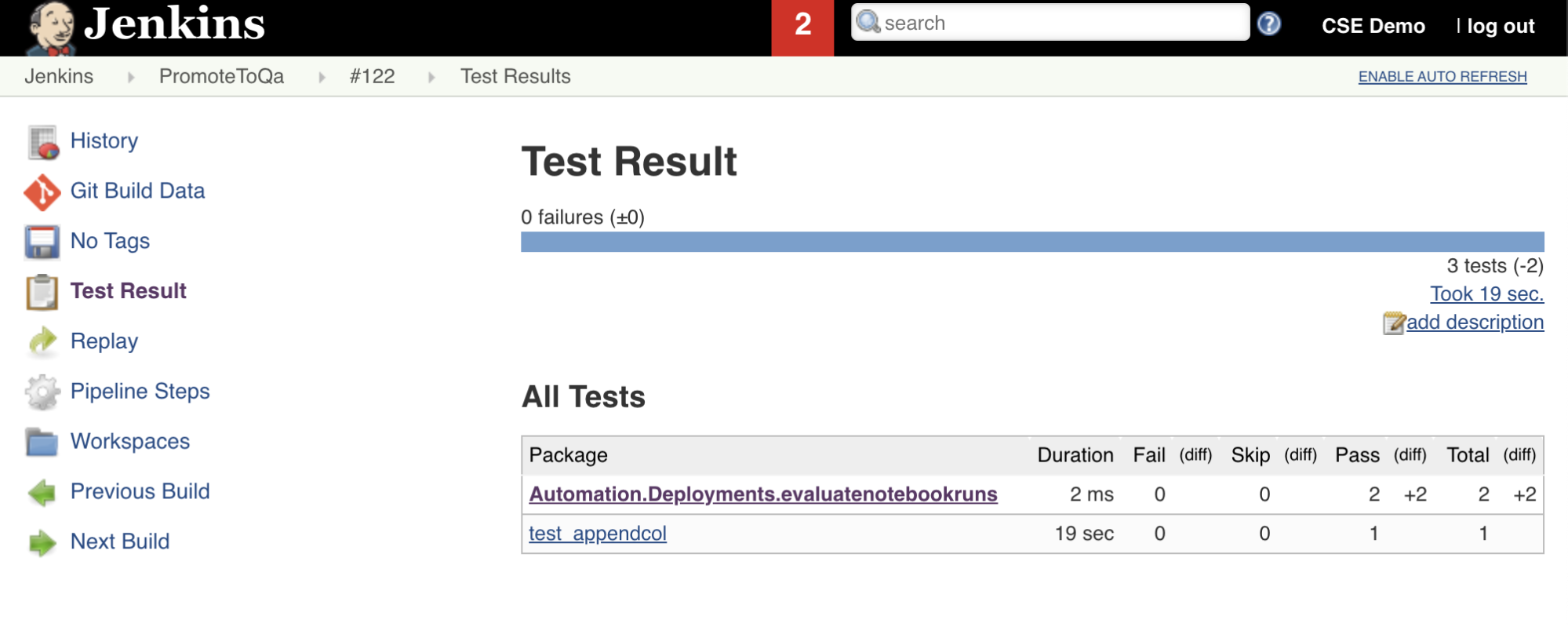
Nasdílení všech změn kódu do úložiště třetí strany
Obsah naklonovaného úložiště byste teď měli odeslat do místního vývojového počítače do úložiště třetí strany. Než nasdílíte změny, měli byste nejprve do .gitignore souboru v naklonovaném úložišti přidat následující položky, protože byste pravděpodobně neměli do úložiště třetích stran odesílat pracovní soubory Sady prostředků Databricks, ověřovací sestavy, soubory sestavení Pythonu a mezipaměti Pythonu. Obvykle budete chtít znovu vygenerovat nové sestavy ověření a nejnovější buildy kol Pythonu v pracovním prostoru Azure Databricks, místo abyste mohli používat potenciálně zastaralé ověřovací sestavy a buildy kol Pythonu:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Spuštění kanálu Jenkinse
Teď jste připraveni spustit kanál Jenkinse ručně. Uděláte to tak, že na řídicím panelu Jenkinse:
- Klikněte na název kanálu Jenkinse.
- Na bočním panelu klikněte na Sestavit hned.
- Pokud chcete zobrazit výsledky, klikněte na nejnovější spuštění kanálu (například
#1) a potom klikněte na výstup konzoly.
V tuto chvíli kanál CI/CD dokončil cyklus integrace a nasazení. Automatizací tohoto procesu můžete zajistit, aby byl váš kód testován a nasazen efektivním, konzistentním a opakovatelným procesem. Pokud chcete externímu poskytovateli Gitu dát pokyn ke spuštění Jenkinse při každé konkrétní události, jako je například žádost o přijetí změn úložiště, prohlédněte si dokumentaci poskytovatele Gitu třetí strany.