Konfigurace Delta Lake pro řízení velikosti datového souboru
Poznámka:
Doporučení v tomto článku se nevztahují na spravované tabulky Katalogu Unity. Databricks doporučuje používat spravované tabulky Unity Catalog s výchozím nastavením pro všechny nové tabulky Delta.
Počínaje Databricks Runtime 13.3 Databricks doporučuje použít seskupování pro uspořádání tabulky Delta. Viz Použijte kapalný clustering pro tabulky Delta.
Databricks doporučuje používat prediktivní optimalizaci k automatickému spouštění OPTIMIZE a VACUUM pro tabulky Delta. Viz prediktivní optimalizace spravovaných tabulek v katalogu Unity.
V Databricks Runtime 10.4 LTS a novějších jsou automatické komprimace a optimalizované zápisy vždy povoleny pro MERGE, UPDATEa DELETE operace. Tuto funkci nelze zakázat.
Delta Lake poskytuje možnosti pro ruční nebo automatickou konfiguraci cílové velikosti souboru pro zápisy a operace OPTIMIZE . Azure Databricks automaticky naladí mnoho z těchto nastavení a umožňuje funkce, které automaticky zlepšují výkon tabulky hledáním souborů správné velikosti.
Pokud používáte SQL Warehouse nebo Databricks Runtime 11.3 LTS nebo novější, databricks pro spravované tabulky Unity většinu těchto konfigurací automaticky naladí.
Pokud upgradujete úlohu z Databricks Runtime 10.4 LTS nebo níže, přečtěte si téma Upgrade na automatické komprimace na pozadí.
Kdy spustit OPTIMIZE
Automatické komprimace a optimalizované zápisy zmenšují malé problémy se soubory, ale nejsou úplnou náhradou za OPTIMIZE. Databricks doporučuje zejména pro tabulky větší než 1 TB spouštět OPTIMIZE podle plánu pro další konsolidaci souborů. Azure Databricks automaticky nespouští ZORDER u tabulek, proto je nutné spustit OPTIMIZE s ZORDER, aby bylo možné rozšířené přeskočení dat. Viz Vynechání dat pro Delta Lake.
Co je automatická optimalizace v Azure Databricks?
Termín automatická optimalizace se někdy používá k popisu funkčnosti řízené nastaveními delta.autoOptimize.autoCompact a delta.autoOptimize.optimizeWrite. Tento termín byl vyřazen ve prospěch popisu každého nastavení jednotlivě. Viz Automatické komprimace pro Delta Lake v Azure Databricks a optimalizované zápisy pro Delta Lake v Azure Databricks.
Automatické komprimace pro Delta Lake v Azure Databricks
Automatické komprimace kombinuje malé soubory v rámci oddílů tabulky Delta, aby se automaticky snížily malé problémy se soubory. Automatické komprimace nastane po úspěšném zápisu do tabulky a synchronně se spustí v clusteru, který provedl zápis. Automatické komprimace zkomprimuje pouze soubory, které nebyly dříve komprimovány.
Velikost výstupního souboru můžete řídit nastavením konfigurace. Databricks doporučuje používat automatické ladění na základě úloh nebo velikosti tabulky. Viz Automatické ladění velikosti souboru na základě úloh a Automatické ladění velikosti souboru na základě velikosti tabulky.
Automatické komprimace se aktivuje jenom pro oddíly nebo tabulky, které mají alespoň určitý počet malých souborů. Volitelně můžete změnit minimální počet souborů potřebných k aktivaci automatické komprimace nastavením spark.databricks.delta.autoCompact.minNumFiles.
Automatické komprimování lze povolit na úrovni tabulky nebo relace pomocí následujících nastavení:
- Vlastnost tabulky:
delta.autoOptimize.autoCompact - Nastavení SparkSession:
spark.databricks.delta.autoCompact.enabled
Tato nastavení přijímají následující možnosti:
| Možnosti | Chování |
|---|---|
auto (doporučeno) |
Cílová velikost souboru Tunes při zachování dalších funkcí automatického ladění Vyžaduje Databricks Runtime 10.4 LTS nebo vyšší. |
legacy |
Alias pro true. Vyžaduje Databricks Runtime 10.4 LTS nebo vyšší. |
true |
Jako cílovou velikost souboru použijte 128 MB. Žádná dynamická velikost. |
false |
Vypne automatické komprimace. Lze nastavit na úrovni relace, aby přebíraly automatické komprimace pro všechny tabulky Delta upravené v rámci pracovní zátěže. |
Důležité
V Databricks Runtime 9.1 LTS, když ostatní zapisovače provádějí operace, jako DELETEje , MERGEUPDATEnebo OPTIMIZE souběžně, může způsobit selhání těchto dalších úloh s konfliktem transakce. Nejedná se o problém v Databricks Runtime 10.4 LTS a novějších.
Optimalizované zápisy pro Delta Lake v Azure Databricks
Optimalizované zápisy zlepšují velikost souboru při zápisu dat a zlepšují následná čtení v tabulce.
Optimalizované zápisy jsou nejúčinnější pro dělené tabulky, protože snižují počet malých souborů zapsaných do každého oddílu. Zápis méně velkých souborů je efektivnější než zápis mnoha malých souborů, ale stále se může zobrazit zvýšení latence zápisu, protože data se před zápisem zahazují.
Následující obrázek ukazuje, jak optimalizované zápisy fungují:
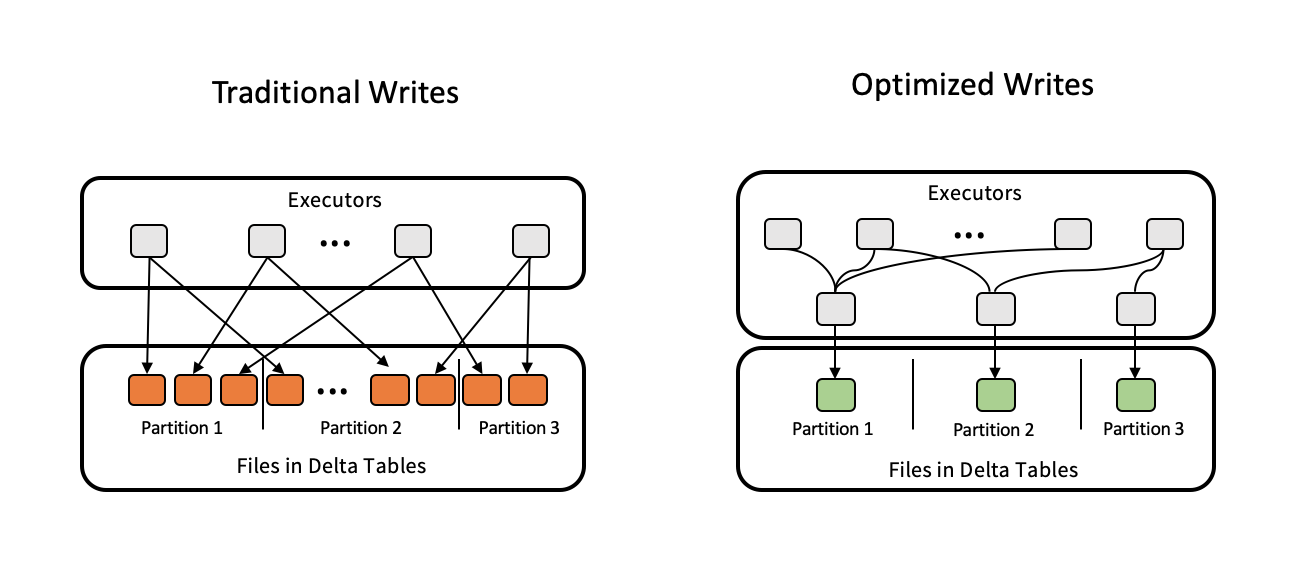
Poznámka:
Můžete mít kód, který se spustí coalesce(n) nebo repartition(n) těsně před tím, než zapíšete data, abyste mohli řídit počet zapsaných souborů. Optimalizované zápisy eliminují potřebu použití tohoto modelu.
Optimalizované zápisy jsou ve výchozím nastavení povolené pro následující operace v Databricks Runtime 9.1 LTS a vyšší:
MERGE-
UPDATEs poddotazy -
DELETEs poddotazy
Optimalizované zápisy jsou také povoleny pro CTAS příkazy a INSERT operace při použití SQL Warehouse. Ve službě Databricks Runtime 13.3 LTS a vyšší mají všechny tabulky Delta zaregistrované v katalogu Unity optimalizované zápisy pro příkazy CTAS a operace INSERT pro particionované tabulky.
Optimalizované zápisy je možné povolit na úrovni tabulky nebo relace pomocí následujících nastavení:
- Nastavení tabulky:
delta.autoOptimize.optimizeWrite - Nastavení SparkSession:
spark.databricks.delta.optimizeWrite.enabled
Tato nastavení přijímají následující možnosti:
| Možnosti | Chování |
|---|---|
true |
Jako cílovou velikost souboru použijte 128 MB. |
false |
Vypne optimalizované zápisy. Lze nastavit na úrovni relace, aby se nahradila automatická komprese pro všechny tabulky Delta upravené během vykonávání úlohy. |
Nastavení cílové velikosti souboru
Pokud chcete vyladit velikost souborů v tabulce Delta, nastavte vlastnost tabulky delta.targetFileSize na požadovanou velikost. Pokud je tato vlastnost nastavená, všechny operace optimalizace rozložení dat se pokusí vygenerovat soubory se zadanou velikostí. Mezi příklady patří optimalizace nebo Z-řád, automatická komprimacea optimalizované zápisy.
Poznámka:
Pokud používáte spravované tabulky Katalogu Unity, SQL Warehouses nebo verzi Databricks Runtime 11.3 LTS a vyšší, respektují nastavení targetFileSize pouze příkazy OPTIMIZE.
| Vlastnost tabulky |
|---|
|
delta.targetFileSize Typ: Velikost v bajtech nebo vyšších jednotkách. Cílová velikost souboru. Například 104857600 (bajty) nebo 100mb.Výchozí hodnota: None |
U existujících tabulek můžete nastavit a zrušit nastavení vlastností pomocí příkazu SQL ALTER TABLESET vlastnosti TBL. Tyto vlastnosti můžete také nastavit automaticky při vytváření nových tabulek pomocí konfigurací relace Sparku. Podrobnosti najdete v referenčních informacích o vlastnostech tabulky Delta .
Velikost souboru automatického ladění na základě úlohy
Databricks doporučuje nastavit vlastnost tabulky delta.tuneFileSizesForRewrites na hodnotu true pro všechny tabulky, na které cílí mnoho operací MERGE nebo DML, bez ohledu na Databricks Runtime, Unity Catalog nebo jiné optimalizace. Při nastavení na trueje cílová velikost souboru tabulky nastavená na mnohem nižší prahovou hodnotu, která zrychluje operace náročné na zápis.
Pokud není explicitně nastavená, Azure Databricks automaticky zjistí, jestli 9 z posledních 10 předchozích operací v tabulce Delta byly MERGE operace a nastaví tuto vlastnost tabulky na true. Tuto vlastnost musíte explicitně nastavit na false, aby se zabránilo tomuto chování.
| Vlastnost tabulky |
|---|
|
delta.tuneFileSizesForRewrites Typ: BooleanUrčuje, jestli chcete optimalizovat velikosti souborů pro optimalizaci rozložení dat. Výchozí hodnota: None |
U existujících tabulek můžete nastavit a zrušit nastavení vlastností pomocí příkazu SQL ALTER TABLESET vlastnosti TBL. Tyto vlastnosti můžete také nastavit automaticky při vytváření nových tabulek pomocí konfigurací relace Sparku. Podrobnosti najdete v referenčních informacích o vlastnostech tabulky Delta .
velikost souboru automatického ladění na základě velikosti tabulky
Aby se minimalizovala potřeba ručního ladění, Azure Databricks automaticky naladí velikost souboru tabulek Delta na základě velikosti tabulky. Azure Databricks použije menší velikosti souborů pro menší tabulky a větší velikosti souborů pro větší tabulky, aby se počet souborů v tabulce nezvětšil příliš velký. Azure Databricks automaticky nenaladí tabulky, které jste naladili s konkrétní cílovou velikostí nebo na základě zátěže s častým přepisem.
Cílová velikost souboru je založená na aktuální velikosti tabulky Delta. U tabulek menších než 2,56 TB je velikost automaticky vyladěného cílového souboru 256 MB. U tabulek s velikostí mezi 2,56 TB a 10 TB se cílová velikost bude lineárně zvětšovat z 256 MB na 1 GB. U tabulek větších než 10 TB je cílová velikost souboru 1 GB.
Poznámka:
Když se cílová velikost souboru pro tabulku zvětší, existující soubory se neoptimalizuje do větších souborů příkazem OPTIMIZE. Velká tabulka proto může mít vždy některé soubory, které jsou menší než cílová velikost. Pokud je potřeba optimalizovat i menší soubory do větších souborů, můžete pro tabulku nakonfigurovat pevnou cílovou velikost pomocí vlastnosti tabulky delta.targetFileSize.
Při přírůstkovém zápisu tabulky se cílové velikosti souborů a počty souborů v závislosti na velikosti tabulky blíží následujícím číslům. Počty souborů v této tabulce jsou pouze příkladem. Skutečné výsledky se budou lišit v závislosti na mnoha faktorech.
| Velikost tabulky | Cílová velikost souboru | Přibližný počet souborů v tabulce |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2,56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Omezení řádků zapsaných v datovém souboru
V některých případech můžou tabulky s úzkými daty narazit na chybu, kdy počet řádků v daném datovém souboru překračuje limity podpory formátu Parquet. Chcete-li se této chybě vyhnout, můžete pomocí konfigurace relace SQL spark.sql.files.maxRecordsPerFile určit maximální počet záznamů pro zápis do jednoho souboru pro tabulku Delta Lake. Určení hodnoty nuly nebo záporné hodnoty představuje žádný limit.
V Databricks Runtime 11.3 LTS a vyšší můžete také použít možnost DataFrameWriter maxRecordsPerFile při použití rozhraní API datového rámce k zápisu do tabulky Delta Lake. Po maxRecordsPerFile zadání se hodnota konfigurace spark.sql.files.maxRecordsPerFile relace SQL ignoruje.
Poznámka:
Databricks nedoporučuje tuto možnost používat, pokud není nutné se vyhnout výše uvedené chybě. Toto nastavení může být stále nezbytné pro některé spravované tabulky Katalogu Unity s velmi úzkými daty.
Upgrade na automatické komprimace na pozadí
Automatické komprimace na pozadí je k dispozici pro spravované tabulky Katalogu Unity ve službě Databricks Runtime 11.3 LTS a vyšší. Při migraci starší verze úlohy nebo tabulky postupujte takto:
- Odeberte konfiguraci Sparku
spark.databricks.delta.autoCompact.enabledz nastavení konfigurace clusteru nebo konfigurace poznámkového bloku. - Pro každou tabulku spusťte
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact), abyste odebrali všechna starší nastavení automatické komprimace.
Po odebrání těchto starších konfigurací byste měli vidět automatické komprimace na pozadí aktivované automaticky pro všechny spravované tabulky Katalogu Unity.