Zpracování datových proudů s využitím Apache Kafka a Azure Databricks
Tento článek popisuje, jak použít Apache Kafka jako zdroj nebo jímku při spouštění úloh strukturovaného streamování v Azure Databricks.
Další informace o Systému Kafka najdete v dokumentaci k Systému Kafka.
Čtení dat ze systému Kafka
Následuje příklad streamovaného čtení ze systému Kafka:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks také podporuje sémantiku dávkového čtení pro zdroje dat Kafka, jak je znázorněno v následujícím příkladu:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Pro přírůstkové dávkové načítání doporučuje Databricks používat Kafka s Trigger.AvailableNow. Viz Konfigurace přírůstkového dávkového zpracování.
V Databricks Runtime 13.3 LTS a novějších poskytuje Azure Databricks funkci SQL pro čtení dat Kafka. Streamování s SQL je podporováno pouze v Delta Live Tables nebo se streamovanými tabulkami v Databricks SQL. Podívejte se na tabulkovou funkci read_kafka .
Konfigurace čtečky strukturovaného streamování Kafka
Azure Databricks poskytuje klíčové slovo kafka jako datový formát pro konfiguraci připojení k Platformě Kafka 0.10 nebo novější.
Nejběžnější konfigurace pro Kafka jsou následující:
Existuje několik způsobů, jak určit, která témata se mají přihlásit k odběru. Měli byste zadat pouze jeden z těchto parametrů:
| Možnost | Hodnota | Popis |
|---|---|---|
| přihlásit k odběru | Seznam témat oddělených čárkami. | Seznam témat pro přihlášení k odběru. |
| subscribePattern | Řetězec regulárního výrazu Java. | Vzor použitý k přihlášení k odběru témat. |
| přiřadit | Řetězec {"topicA":[0,1],"topic":[2,4]}JSON . |
Specific topicPartitions to consume. |
Další velmi vhodné konfigurace:
| Možnost | Hodnota | Výchozí hodnota | Popis |
|---|---|---|---|
| kafka.bootstrap.servers | Seznam ve formátu host:port, oddělený čárkami. | empty | [Povinné] Konfigurace Kafka bootstrap.servers . Pokud zjistíte, že v systému Kafka nejsou žádná data, nejprve zkontrolujte seznam adres zprostředkovatele. Pokud je seznam adres zprostředkovatele nesprávný, nemusí se zde vyskytovat žádné chyby. Důvodem je to, že klient Kafka předpokládá, že zprostředkovatelé budou nakonec k dispozici a v případě chyb sítě se budou opakovat navždy. |
| failOnDataLoss |
true nebo false. |
true |
[Volitelné] Jestli dotaz selže, když je možné, že došlo ke ztrátě dat. Dotazy můžou trvale selhat při čtení dat ze systému Kafka kvůli mnoha scénářům, jako jsou odstraněná témata, zkrácení tématu před zpracováním atd. Snažíme se odhadnout konzervativně, jestli se data pravděpodobně ztratila nebo ne. Někdy to může způsobit falešné poplachy. Tuto možnost nastavte na false, pokud nefunguje podle očekávání, nebo chcete, aby dotaz pokračoval ve zpracování i přes ztrátu dat. |
| minPartitions | Celé číslo >= 0, 0 = zakázáno. | 0 (zakázáno) | [Volitelné] Minimální počet oddílů, které se mají číst ze systému Kafka Spark můžete nakonfigurovat tak, aby pomocí této minPartitions možnosti používal libovolný minimální počet oddílů ke čtení ze systému Kafka. Spark má za normálních okolností mapování témat Kafka 1–1 na oddíly Sparku, které využívají kafka. Pokud nastavíte možnost minPartitions na hodnotu větší, než jsou vaše oddíly Kafka topicPartitions, Spark rozdělí velké oddíly Kafka na menší části. Tuto možnost je možné nastavit v době maximálního zatížení, nerovnoměrné distribuce dat a s tím, jak váš datový proud klesá, aby se zvýšila rychlost zpracování. Při inicializaci příjemců Kafka při každém triggeru to může mít vliv na výkon, pokud při připojování k Kafka používáte SSL. |
| kafka.group.id | ID skupiny příjemců Kafka. | nenastaveno | [Volitelné] ID skupiny, které se má použít při čtení ze systému Kafka. Tuto možnost používejte s opatrností. Ve výchozím nastavení každý dotaz vygeneruje jedinečné ID skupiny pro čtení dat. Tím zajistíte, že každý dotaz bude mít vlastní skupinu příjemců, která nedochází k rušení od žádného jiného příjemce, a proto může číst všechny oddíly svých předplacených témat. V některých scénářích (například autorizace založená na skupinách Kafka) můžete ke čtení dat použít konkrétní autorizovaná ID skupin. Volitelně můžete nastavit ID skupiny. Nicméně, to s extrémní opatrností, protože může způsobit neočekávané chování. – Souběžné spouštění dotazů (dávkové i streamování) se stejným ID skupiny pravděpodobně vzájemně kolidují, což způsobí, že každý dotaz bude číst jen část dat. – K tomu může dojít také v případě, že se dotazy spustí nebo restartují v rychlém sledu. Pokud chcete tyto problémy minimalizovat, nastavte konfiguraci příjemce Kafka tak, aby session.timeout.ms byla velmi malá. |
| startingOffsets | nejstarší , nejnovější | nejnovější | [Volitelné] Počáteční bod při spuštění dotazu, buď "nejstarší", který je od nejstarších offsetů, nebo řetězec JSON určující počáteční offset pro každou TopicPartition. Ve formátu JSON lze -2 jako posun použít k označení nejstarších dat a -1 k označení nejnovějších. Poznámka: U dávkových dotazů není povoleno nejnovější (implicitně nebo pomocí parametru -1 ve formátu JSON). U streamovaných dotazů to platí jenom v případě, že se spustí nový dotaz, a toto obnovení vždy vyzvedne místo, kde dotaz skončil. Nově zjištěné oddíly během dotazu se spustí nejdříve. |
Další volitelné konfigurace najdete v průvodci integrací Kafka se strukturovaným streamováním.
Schéma pro záznamy Kafka
Schéma záznamů Kafka je:
| Sloupec | Typ |
|---|---|
| key | binární |
| hodnota | binární |
| topic | string |
| oddíl | int |
| ofset | long |
| časové razítko | long |
| timestampType | int |
A key jsou value vždy deserializovány jako bajtové pole s ByteArrayDeserializer. K explicitní deserializaci klíčů a hodnot použijte operace datového rámce (například cast("string")).
Zápis dat do Kafka
Následuje příklad streamování zápisu do Kafka:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks podporuje také sémantiku dávkového zápisu do datových jímek Kafka, jak je znázorněno v následujícím příkladu:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Konfigurace zapisovače strukturovaného streamování Kafka
Důležité
Databricks Runtime 13.3 LTS a vyšší obsahuje novější verzi kafka-clients knihovny, která ve výchozím nastavení umožňuje zápisy idempotentní. Pokud jímka Kafka používá verzi 2.8.0 nebo nižší s nakonfigurovanými seznamy ACL, ale bez IDEMPOTENT_WRITE povolení, zápis selže s chybovou zprávou org.apache.kafka.common.KafkaException:Cannot execute transactional method because we are in an error state.
Tuto chybu můžete vyřešit upgradem na Kafka verze 2.8.0 nebo vyšší nebo nastavením .option(“kafka.enable.idempotence”, “false”) při konfiguraci zapisovače strukturovaného streamování.
Schéma poskytnuté dataStreamWriter komunikuje s jímkou Kafka. Můžete použít následující pole:
| Název sloupce | Požadované nebo volitelné | Typ |
|---|---|---|
key |
optional |
STRING nebo BINARY |
value |
povinné |
STRING nebo BINARY |
headers |
optional | ARRAY |
topic |
volitelné (ignorováno, pokud je možnost topic nastavena jako writer) |
STRING |
partition |
optional | INT |
Níže jsou uvedené běžné možnosti nastavené při psaní do systému Kafka:
| Možnost | Hodnota | Výchozí hodnota | Popis |
|---|---|---|---|
kafka.boostrap.servers |
Čárkami oddělený seznam <host:port> |
Žádná | [Povinné] Konfigurace Kafka bootstrap.servers . |
topic |
STRING |
nenastaveno | [Volitelné] Nastaví téma pro zápis všech řádků. Tato možnost přepíše libovolný sloupec tématu, který v datech existuje. |
includeHeaders |
BOOLEAN |
false |
[Volitelné] Zda se mají do řádku zahrnout záhlaví Kafka. |
Další volitelné konfigurace najdete v průvodci integrací Kafka se strukturovaným streamováním.
Načtení metrik Kafka
Pomocí metrik avgOffsetsBehindLatest, maxOffsetsBehindLatesta minOffsetsBehindLatest můžete zjistit průměrný, minimální a maximální počet posunů, o které streamovací dotaz zaostává za nejnovějším dostupným posunem ve všech předplacených tématech. Podívejte se na interaktivní čtení metrik.
Poznámka:
K dispozici ve službě Databricks Runtime 9.1 a novějších.
Získejte odhadovaný celkový počet bajtů, které proces dotazu nespotřeboval z odebíraných témat prozkoumáním hodnoty estimatedTotalBytesBehindLatest. Tento odhad vychází z dávek zpracovaných za posledních 300 sekund. Časový rámec, na který je odhad založen, lze změnit nastavením možnosti bytesEstimateWindowLength na jinou hodnotu. Pokud ho chcete například nastavit na 10 minut:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Pokud stream spouštíte v poznámkovém bloku, můžete tyto metriky zobrazit na kartě Nezpracovaná data na řídicím panelu průběhu dotazu streamování:
{
"sources" : [ {
"description" : "KafkaV2[Subscribe[topic]]",
"metrics" : {
"avgOffsetsBehindLatest" : "4.0",
"maxOffsetsBehindLatest" : "4",
"minOffsetsBehindLatest" : "4",
"estimatedTotalBytesBehindLatest" : "80.0"
},
} ]
}
Připojení Azure Databricks k Kafka pomocí PROTOKOLU SSL
Pokud chcete povolit připojení SSL k systému Kafka, postupujte podle pokynů v dokumentaci ke Confluentu Šifrování a ověřování pomocí SSL. Můžete zadat konfigurace, které jsou zde popsány, s předponou kafka., jako možnosti. Zadáte například umístění úložiště důvěryhodnosti ve vlastnosti kafka.ssl.truststore.location.
Databricks doporučuje:
- Uložte certifikáty do cloudového úložiště objektů. Přístup k certifikátům můžete omezit jenom na clustery, které mají přístup ke kafka. Viz zásady správného řízení dat pomocíkatalogu Unity .
- Uložte hesla certifikátů jako tajné kódy v oboru tajných kódů.
Následující příklad používá umístění úložiště objektů a tajné kódy Databricks k povolení připojení SSL:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Připojení Kafka ve službě HDInsight k Azure Databricks
Vytvořte cluster HDInsight Kafka.
Pokyny najdete v tématu Připojení k Platformě Kafka ve službě HDInsight prostřednictvím služby Azure Virtual Network .
Nakonfigurujte zprostředkovatele Kafka tak, aby inzerovali správnou adresu.
Postupujte podle pokynů v části Konfigurace kafka pro inzerci IP adres. Pokud spravujete Kafka sami na virtuálních počítačích Azure, ujistěte se, že konfigurace
advertised.listenersbrokerů je nastavena na interní IP adresu hostitelů.Vytvořte cluster Azure Databricks.
Vytvoření partnerského vztahu clusteru Kafka ke clusteru Azure Databricks
Postupujte podle pokynů v partnerských virtuálních sítích.
Ověřování instančního objektu s VYUŽITÍM ID Microsoft Entra a Azure Event Hubs
Azure Databricks podporuje ověřování úloh Sparku pomocí služeb Event Hubs. Toto ověřování se provádí prostřednictvím OAuth s ID Microsoft Entra.
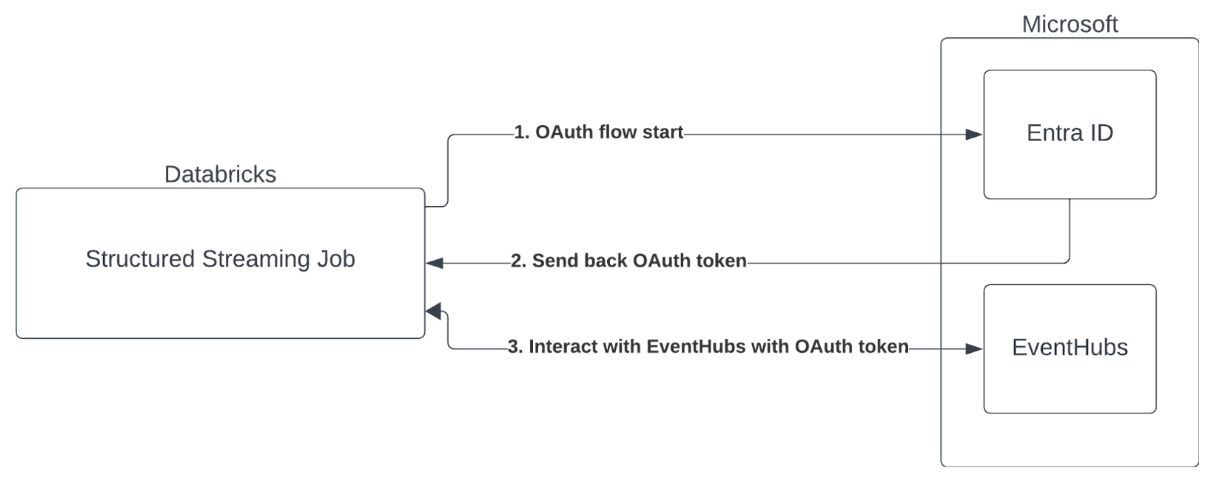
Azure Databricks podporuje ověřování Microsoft Entra ID s ID klienta a tajným kódem v následujících výpočetních prostředích:
- Databricks Runtime 12.2 LTS a vyšší na výpočetních prostředcích nakonfigurovaných v režimu přístupu jednoho uživatele
- Databricks Runtime 14.3 LTS a vyšší na výpočetních prostředcích nakonfigurovaných v režimu sdíleného přístupu
- Kanály Delta Live Tables konfigurované bez Unity Catalogu.
Azure Databricks nepodporuje ověřování MICROSOFT Entra ID pomocí certifikátu v žádném výpočetním prostředí ani v kanálech Delta Live Tables nakonfigurovaných pomocí katalogu Unity.
Toto ověřování nefunguje ve sdílených clusterech ani v dynamických tabulkách Unity Catalog Delta.
Konfigurace konektoru Kafka pro strukturované streamování
Pokud chcete provést ověřování pomocí ID Microsoft Entra, budete potřebovat následující hodnoty:
ID tenanta. Najdete ho na kartě služby Microsoft Entra ID .
ID klienta (označované také jako ID aplikace).
Tajný klíč klienta. Jakmile to budete mít, měli byste ho přidat jako tajný kód do pracovního prostoru Databricks. Pokud chcete přidat tento tajný klíč, přečtěte si téma Správa tajných kódů.
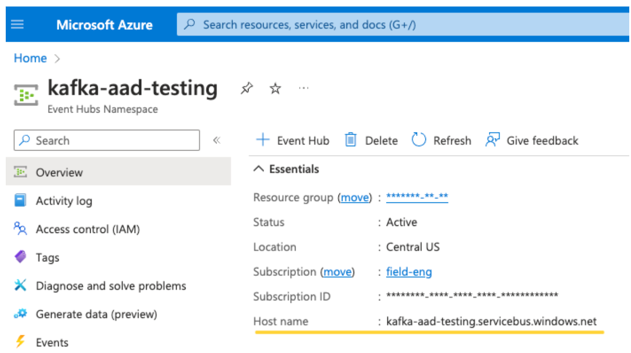
Téma EventHubs Seznam témat najdete v části
Event Hubs v části Entity konkrétníoboru názvů služby Event Hubs. Pokud chcete pracovat s několika tématy, můžete nastavit roli IAM na úrovni služby Event Hubs. Server EventHubs. Najdete ho na stránce přehledu vašeho konkrétního oboru názvů služby Event Hubs:
Kromě toho, abychom mohli použít Id Entra, musíme kafka říct, aby používal mechanismus SASL OAuth (SASL je obecný protokol a OAuth je typ SASL "mechanismus"):
-
kafka.security.protocolby měla býtSASL_SSL -
kafka.sasl.mechanismby měla býtOAUTHBEARER -
kafka.sasl.login.callback.handler.classby měl být plně kvalifikovaný název třídy Java s hodnotoukafkashadedobslužné rutiny zpětného volání pro přihlášení naší stínované třídy Kafka. Přesné třídy najdete v následujícím příkladu.
Příklad
Teď se podíváme na spuštěný příklad:
Python
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Zpracování potenciálních chyb
Možnosti streamování se nepodporují.
Pokud se pokusíte použít tento mechanismus ověřování v kanálu Delta Live Tables nakonfigurovaný pomocí katalogu Unity, může se zobrazit následující chyba:
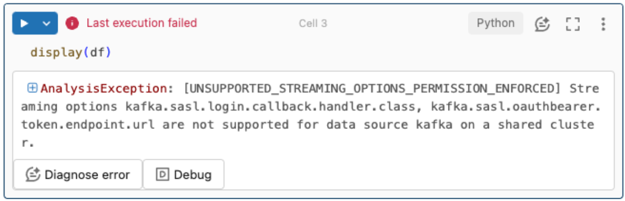
Pokud chcete tuto chybu vyřešit, použijte podporovanou konfiguraci výpočetních prostředků. Viz Ověřování instančního objektu s ID Microsoft Entra a Azure Event Hubs.
Vytvoření nového
KafkaAdminClientsouboru se nezdařilo.Jedná se o vnitřní chybu, kterou kafka vyvolá v případě, že některá z následujících možností ověřování není správná:
- ID klienta (označované také jako ID aplikace)
- ID tenanta
- Server EventHubs
Pokud chcete chybu vyřešit, ověřte správnost hodnot pro tyto možnosti.
Kromě toho se tato chyba může zobrazit, pokud upravíte možnosti konfigurace, které jsou ve výchozím nastavení k dispozici v příkladu (že jste byli požádáni o změnu), například
kafka.security.protocol.Nevrácené žádné záznamy
Pokud se pokoušíte datový rámec zobrazit nebo zpracovat, ale nezobrazují se vám výsledky, zobrazí se v uživatelském rozhraní následující kód.
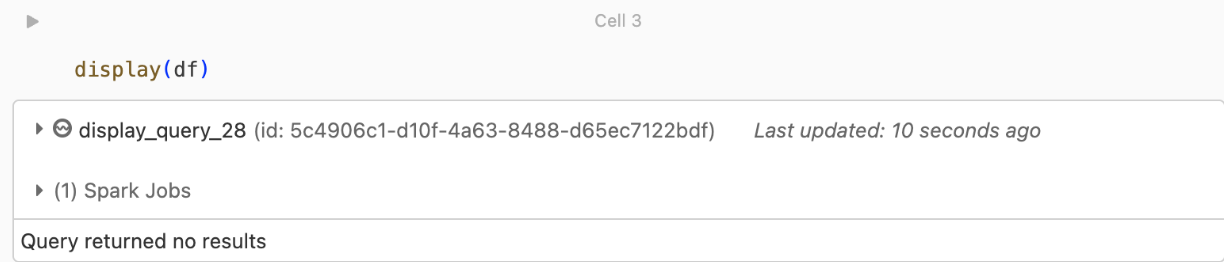
Tato zpráva znamená, že ověřování proběhlo úspěšně, ale Služba EventHubs nevrátila žádná data. Některé možné (i když bez vyčerpávajícího) důvodu jsou:
- Zadali jste nesprávné téma EventHubs .
- Výchozí možnost
startingOffsetskonfigurace Kafka jelatesta v současné době nedostáváte žádná data prostřednictvím tématu. Můžete nastavitstartingOffsetstoearliestpro čtení dat od nejstarších offsetů Kafka.