Připojení ke cloudovému úložišti Google
Tento článek popisuje, jak nakonfigurovat připojení z Azure Databricks ke čtení a zápisu tabulek a dat uložených ve službě Google Cloud Storage (GCS).
Pokud chcete číst nebo zapisovat z kontejneru GCS, musíte vytvořit připojený účet služby a přidružit kontejner k účtu služby. K kbelíku se připojíte přímo pomocí klíče, který pro účet služby vygenerujete.
Přístup k kbelíku GCS přímo pomocí klíče účtu služby Google Cloud
Pokud chcete číst a zapisovat přímo do kontejneru, nakonfigurujte klíč definovaný v konfiguraci Sparku.
Krok 1: Nastavení účtu služby Google Cloud pomocí konzoly Google Cloud Console
Pro cluster Azure Databricks musíte vytvořit účet služby. Databricks doporučuje poskytnout tomuto účtu služby nejnižší oprávnění potřebná k provádění svých úloh.
V levém navigačním podokně klikněte na IAM a Správce .
Klikněte na Účty služeb.
Klikněte na + VYTVOŘIT ÚČET SLUŽBY.
Zadejte název a popis účtu služby.
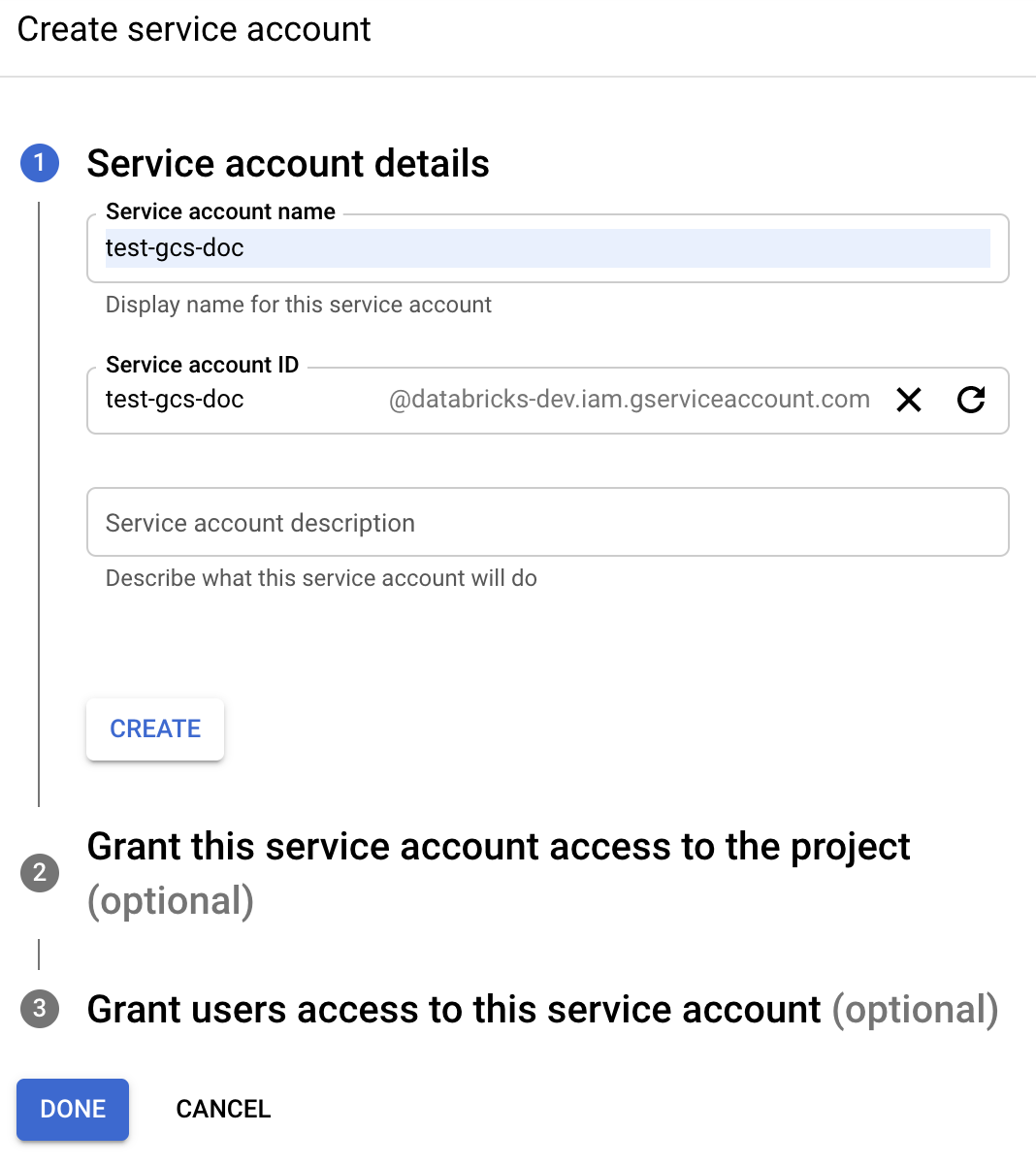
Klikněte na VYTVOŘIT.
Klikněte na POKRAČOVAT.
Klikněte na HOTOVO.
Krok 2: Vytvoření klíče pro přímý přístup k kbelíku GCS
Upozorňující
Klíč JSON, který pro účet služby vygenerujete, je privátní klíč, který by se měl sdílet jenom s autorizovanými uživateli, protože řídí přístup k datovým sadám a prostředkům ve vašem účtu Google Cloud.
- V konzole Google Cloud klikněte v seznamu účtů služeb na nově vytvořený účet.
- V části Klíče klikněte na PŘIDAT KLÍČ > Vytvořit nový klíč.
- Přijměte typ klíče JSON.
- Klikněte na VYTVOŘIT. Soubor klíče se stáhne do počítače.
Krok 3: Konfigurace kontejneru GCS
Vytvoření kontejneru
Pokud kontejner ještě nemáte, vytvořte ho:
V levém navigačním podokně klikněte na Úložiště .
Klikněte na VYTVOŘIT KBELÍK.
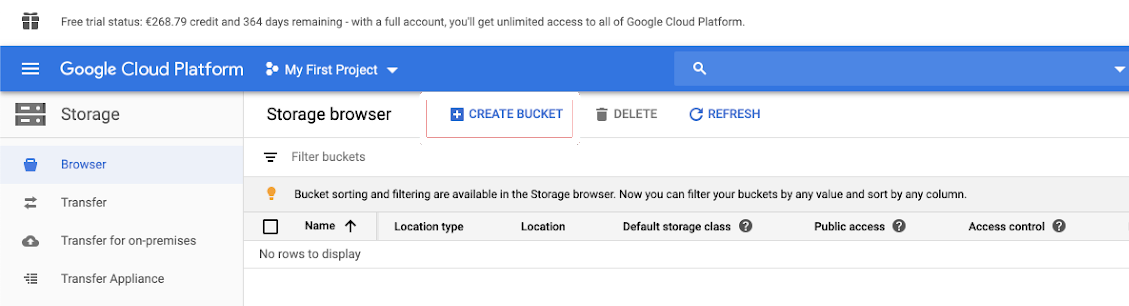
Klikněte na VYTVOŘIT.
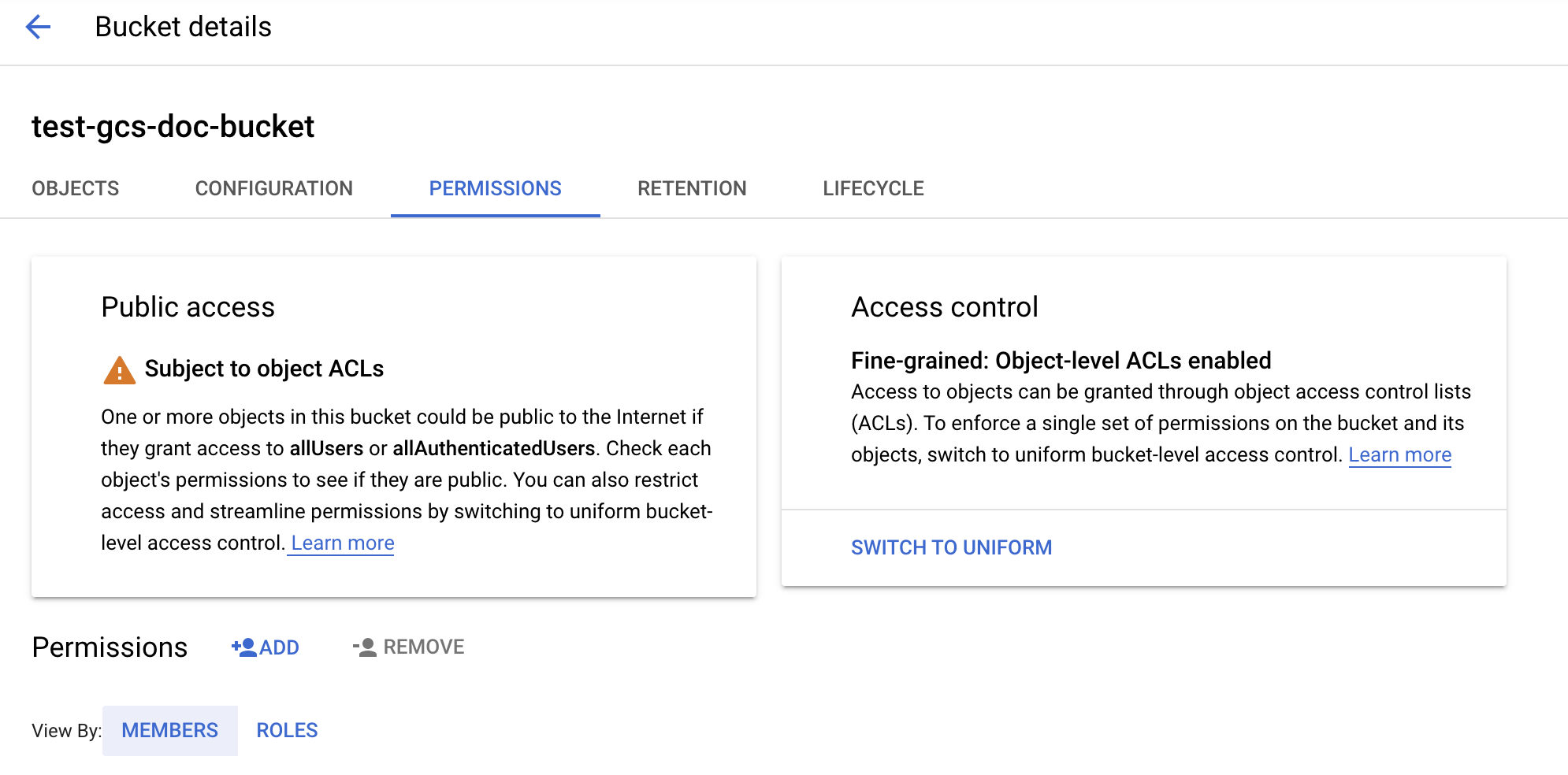
Konfigurace kontejneru
Nakonfigurujte podrobnosti o kontejneru.
Klikněte na kartu Oprávnění .
Vedle popisku Oprávnění klikněte na PŘIDAT.
Zadejte oprávnění správce úložiště k účtu služby v kontejneru z rolí cloudového úložiště.
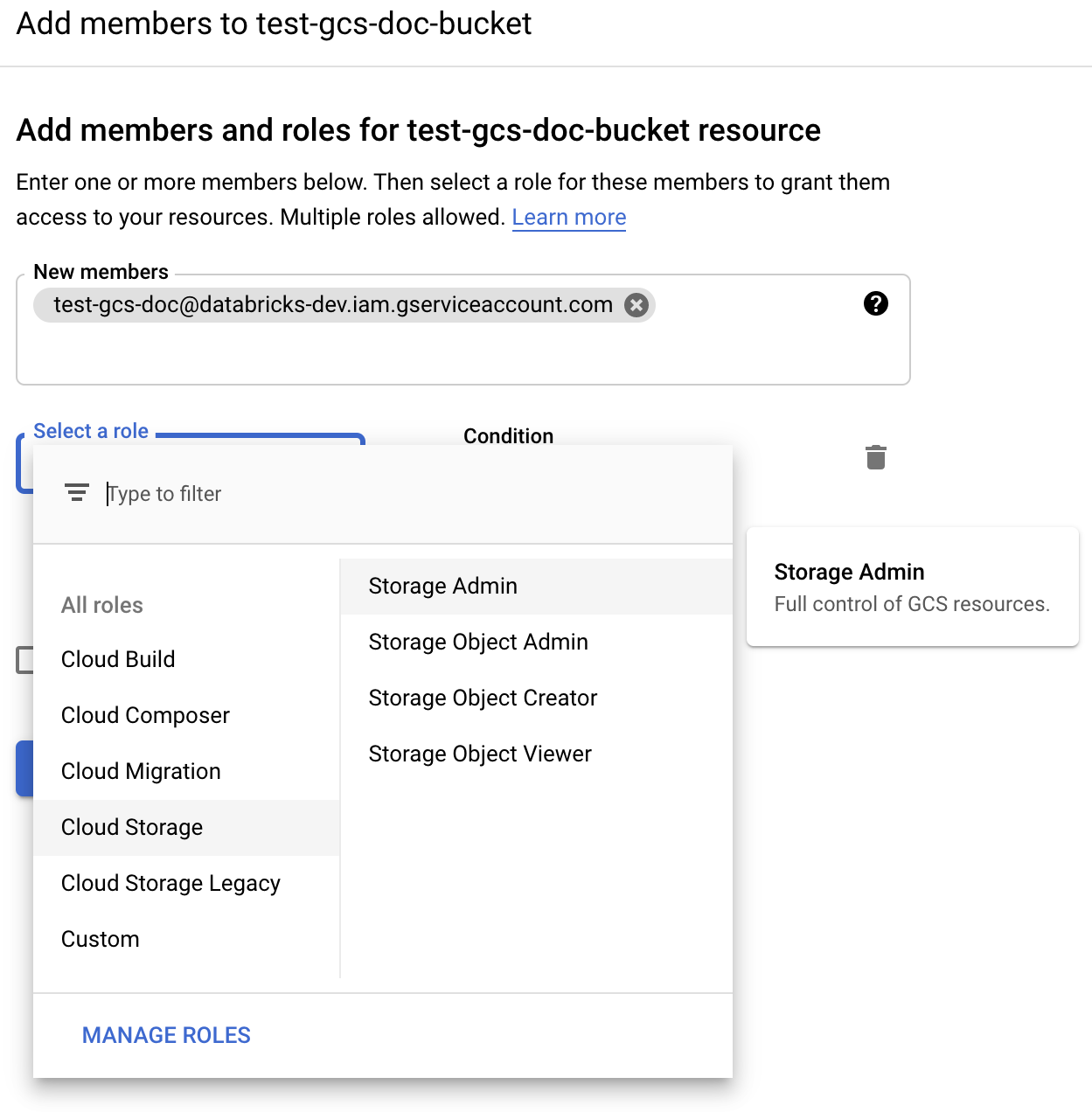
Klikněte na ULOŽIT.
Krok 4: Vložení klíče účtu služby do tajných kódů Databricks
Databricks doporučuje používat omezení tajných klíčů pro ukládání všech přihlašovacích údajů. Privátní klíč a ID privátního klíče ze souboru JSON klíče můžete vložit do oborů tajných kódů Databricks. Uživatelům, instančním objektům a skupinám v pracovním prostoru můžete udělit přístup ke čtení oborů tajných kódů. Tím se chrání klíč účtu služby a zároveň umožňuje uživatelům přístup ke službě GCS. Pokud chcete vytvořit obor tajných kódů, přečtěte si téma Správa tajných kódů.
Krok 5: Konfigurace clusteru Azure Databricks
Na kartě Konfigurace Sparku nakonfigurujte globální konfiguraci nebo konfiguraci pro jednotlivé kontejnery. Následující příklady nastavují klíče pomocí hodnot uložených jako tajné kódy Databricks.
Poznámka:
Pomocí řízení přístupu ke clusteru a řízení přístupu k poznámkovému bloku můžete chránit přístup k účtu služby a datům v kontejneru GCS. Podívejte se na výpočetní oprávnění a spolupráci pomocí poznámkových bloků Databricks.
Globální konfigurace
Tuto konfiguraci použijte, pokud by se zadané přihlašovací údaje měly použít pro přístup ke všem kontejnerům.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
<client-email> Nahraďte <project-id>hodnoty těchto přesných názvů polí ze souboru JSON klíče.
Konfigurace podle kbelíku
Tuto konfiguraci použijte, pokud je nutné nakonfigurovat přihlašovací údaje pro konkrétní kontejnery. Syntaxe konfigurace pro jednotlivé kontejnery připojí název kontejneru na konec každé konfigurace, jak je znázorněno v následujícím příkladu.
Důležité
Kromě globálních konfigurací je možné použít také konfigurace pro jednotlivé kontejnery. Při zadání se konfigurace pro jednotlivé kontejnery supercede globální konfigurace.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
<client-email> Nahraďte <project-id>hodnoty těchto přesných názvů polí ze souboru JSON klíče.
Krok 6: Čtení ze služby GCS
Pokud chcete číst z kontejneru GCS, použijte příkaz Pro čtení Sparku v libovolném podporovaném formátu, například:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Pokud chcete zapisovat do kontejneru GCS, použijte příkaz pro zápis Sparku v libovolném podporovaném formátu, například:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Nahraďte <bucket-name> názvem kontejneru, který jste vytvořili v kroku 3: Konfigurace kontejneru GCS.