Google BigQuery
Tento článek popisuje, jak číst a zapisovat do tabulek Google BigQuery v Azure Databricks.
Důležité
Konfigurace popsané v tomto článku jsou experimentální. Experimentální funkce jsou poskytovány tak, jak jsou, a Databricks je nepodporuje prostřednictvím technické podpory zákazníků. Pokud chcete získat plnou podporu federace dotazů, měli byste místo toho použít Lakehouse Federation, která uživatelům Azure Databricks umožňuje využívat syntaxi katalogu Unity a nástroje zásad správného řízení dat.
K BigQuery se musíte připojit pomocí ověřování založeného na klíči.
Oprávnění
Vaše projekty musí mít specifická oprávnění Google ke čtení a zápisu pomocí BigQuery.
Poznámka:
Tento článek popisuje materializovaná zobrazení BigQuery. Podrobnosti najdete v článku Google Úvod do materializovaných zobrazení. Další terminologii BigQuery a model zabezpečení BigQuery najdete v dokumentaci k Google BigQuery.
Čtení a zápis dat pomocí BigQuery závisí na dvou projektech Google Cloud:
- Project (
project): ID projektu Google Cloud, ze kterého Azure Databricks čte nebo zapisuje tabulku BigQuery. - Nadřazený projekt (
parentProject): ID nadřazeného projektu, což je ID projektu Google Cloud, které se má fakturovat za čtení a zápis. Nastavte ho na projekt Google Cloud přidružený k účtu služby Google, pro který vygenerujete klíče.
Je nutné explicitně zadat project hodnoty a parentProject hodnoty v kódu, který přistupuje k BigQuery. Použijte kód podobný následujícímu:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Požadovaná oprávnění pro projekty Google Cloud závisí na tom, jestli project a parentProject jsou stejná. V následujících částech jsou uvedena požadovaná oprávnění pro jednotlivé scénáře.
Požadovaná oprávnění, pokud project a parentProject odpovídá
Pokud jsou ID vaší project a parentProject jsou stejná, použijte následující tabulku k určení minimálních oprávnění:
| Úloha Azure Databricks | Oprávnění Google vyžadovaná v projektu |
|---|---|
| Čtení tabulky BigQuery bez materializovaného zobrazení | project V projektu:– Uživatel relace čtení BigQuery – Prohlížeč dat BigQuery (Volitelně ho udělte na úrovni datové sady nebo tabulky místo na úrovni projektu). |
| Čtení tabulky BigQuery s materializovaným zobrazením | project V projektu:– Uživatel úlohy BigQuery – Uživatel relace čtení BigQuery – Prohlížeč dat BigQuery (Volitelně ho udělte na úrovni datové sady nebo tabulky místo na úrovni projektu). V projektu materializace: – Editor dat BigQuery |
| Zápis tabulky BigQuery | project V projektu:– Uživatel úlohy BigQuery – Editor dat BigQuery |
Požadovaná oprávnění, pokud project se parentProject liší
Pokud se ID vašeho project a parentProject liší se, použijte následující tabulku k určení minimálních oprávnění:
| Úloha Azure Databricks | Požadovaná oprávnění Google |
|---|---|
| Čtení tabulky BigQuery bez materializovaného zobrazení | parentProject V projektu:– Uživatel relace čtení BigQuery project V projektu:– Prohlížeč dat BigQuery (Volitelně ho udělte na úrovni datové sady nebo tabulky místo na úrovni projektu). |
| Čtení tabulky BigQuery s materializovaným zobrazením | parentProject V projektu:– Uživatel relace čtení BigQuery – Uživatel úlohy BigQuery project V projektu:– Prohlížeč dat BigQuery (Volitelně ho udělte na úrovni datové sady nebo tabulky místo na úrovni projektu). V projektu materializace: – Editor dat BigQuery |
| Zápis tabulky BigQuery | parentProject V projektu:– Uživatel úlohy BigQuery project V projektu:– Editor dat BigQuery |
Krok 1: Nastavení Služby Google Cloud
Povolení rozhraní API služby BigQuery Storage
Rozhraní API služby BigQuery Storage je ve výchozím nastavení povolené v nových projektech Google Cloud, ve kterých je povolený BigQuery. Pokud ale máte existující projekt a rozhraní API služby BigQuery Storage není povolené, povolte ho podle kroků v této části.
Rozhraní API služby BigQuery Storage můžete povolit pomocí rozhraní příkazového řádku Google Cloud nebo konzoly Google Cloud Console.
Povolení rozhraní API služby BigQuery Storage pomocí Rozhraní příkazového řádku Google Cloud
gcloud services enable bigquerystorage.googleapis.com
Povolení rozhraní API služby BigQuery Storage pomocí konzoly Google Cloud Console
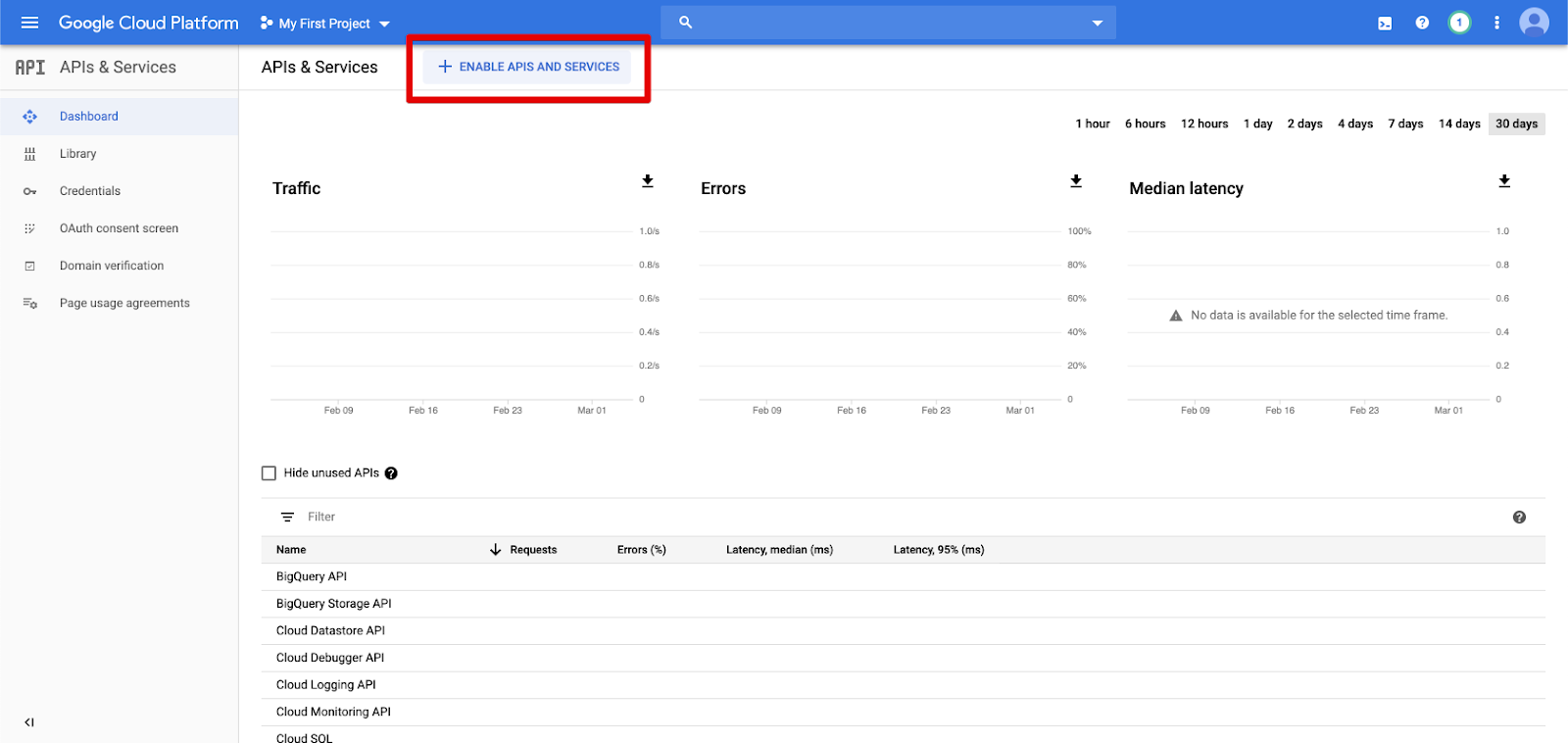
V levém navigačním podokně klikněte na rozhraní API a služby .
Klikněte na tlačítko POVOLIT APIS A SLUŽBY .
Zadejte
bigquery storage apido panelu hledání a vyberte první výsledek.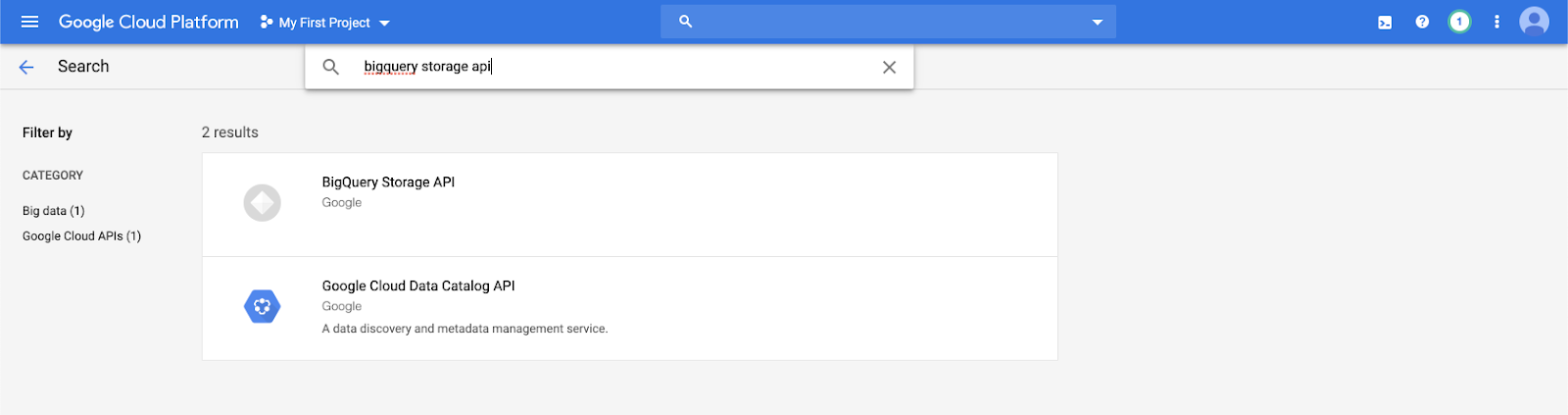
Ujistěte se, že je povolené rozhraní API služby BigQuery Storage.
Vytvoření účtu služby Google pro Azure Databricks
Vytvořte účet služby pro cluster Azure Databricks. Databricks doporučuje poskytnout tomuto účtu služby nejnižší oprávnění potřebná k provádění svých úloh. Viz role a oprávnění BigQuery.
Účet služby můžete vytvořit pomocí rozhraní příkazového řádku Google Cloud nebo konzoly Google Cloud Console.
Vytvoření účtu služby Google pomocí Rozhraní příkazového řádku Google Cloud
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Vytvořte klíče pro účet služby:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Vytvoření účtu služby Google pomocí konzoly Google Cloud Console
Vytvoření účtu:
V levém navigačním podokně klikněte na IAM a Správce .
Klikněte na Účty služeb.
Klikněte na + VYTVOŘIT ÚČET SLUŽBY.
Zadejte název a popis účtu služby.
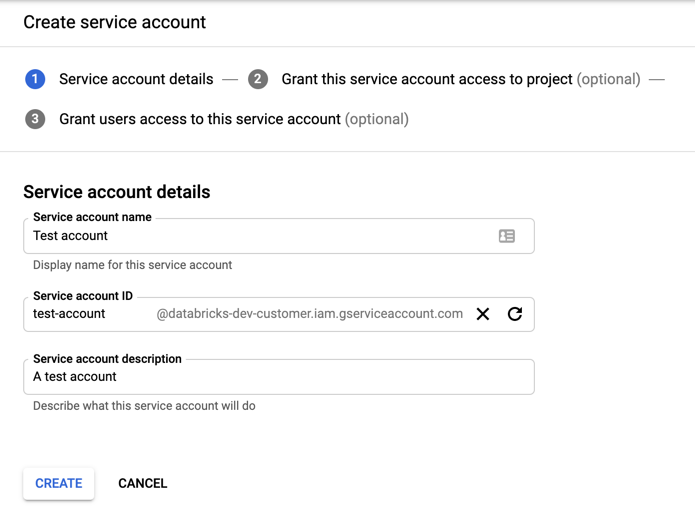
Klikněte na VYTVOŘIT.
Zadejte role pro váš účet služby. V rozevíracím seznamu Vybrat roli zadejte
BigQuerya přidejte následující role: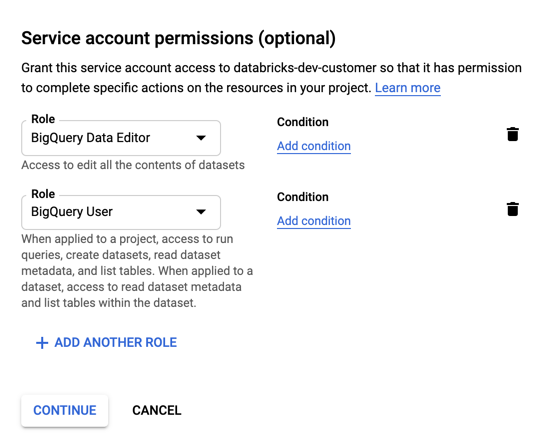
Klikněte na POKRAČOVAT.
Klikněte na HOTOVO.
Vytvoření klíčů pro účet služby:
V seznamu účtů služeb klikněte na nově vytvořený účet.
V části Klíče vyberte tlačítko PŘIDAT KLÍČ > Vytvořit nový klíč .
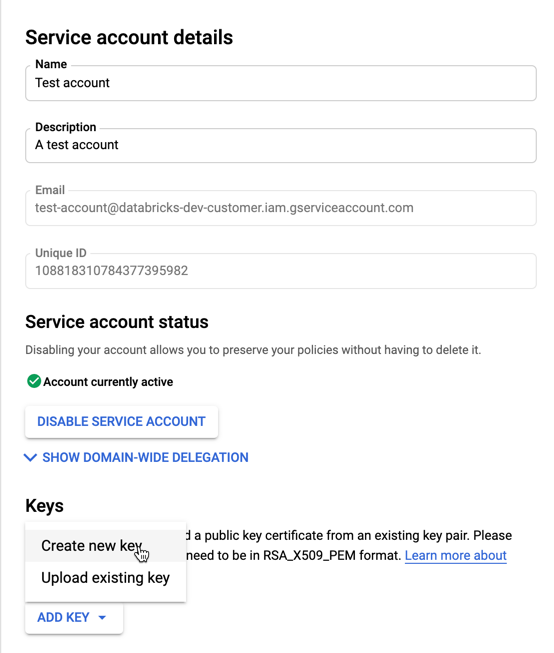
Přijměte typ klíče JSON.
Klikněte na VYTVOŘIT. Soubor klíče JSON se stáhne do počítače.
Důležité
Soubor klíče JSON, který pro účet služby vygenerujete, je privátní klíč, který by se měl sdílet jenom s autorizovanými uživateli, protože řídí přístup k datovým sadám a prostředkům ve vašem účtu Google Cloud.
Vytvoření kontejneru GCS (Google Cloud Storage) pro dočasné úložiště
Pro zápis dat do BigQuery potřebuje zdroj dat přístup k kbelíku GCS.
V levém navigačním podokně klikněte na Úložiště .
Klikněte na VYTVOŘIT KBELÍK.
Nakonfigurujte podrobnosti o kontejneru.
Klikněte na VYTVOŘIT.
Klikněte na kartu Oprávnění a přidejte členy.
Zadejte následující oprávnění k účtu služby v kontejneru.
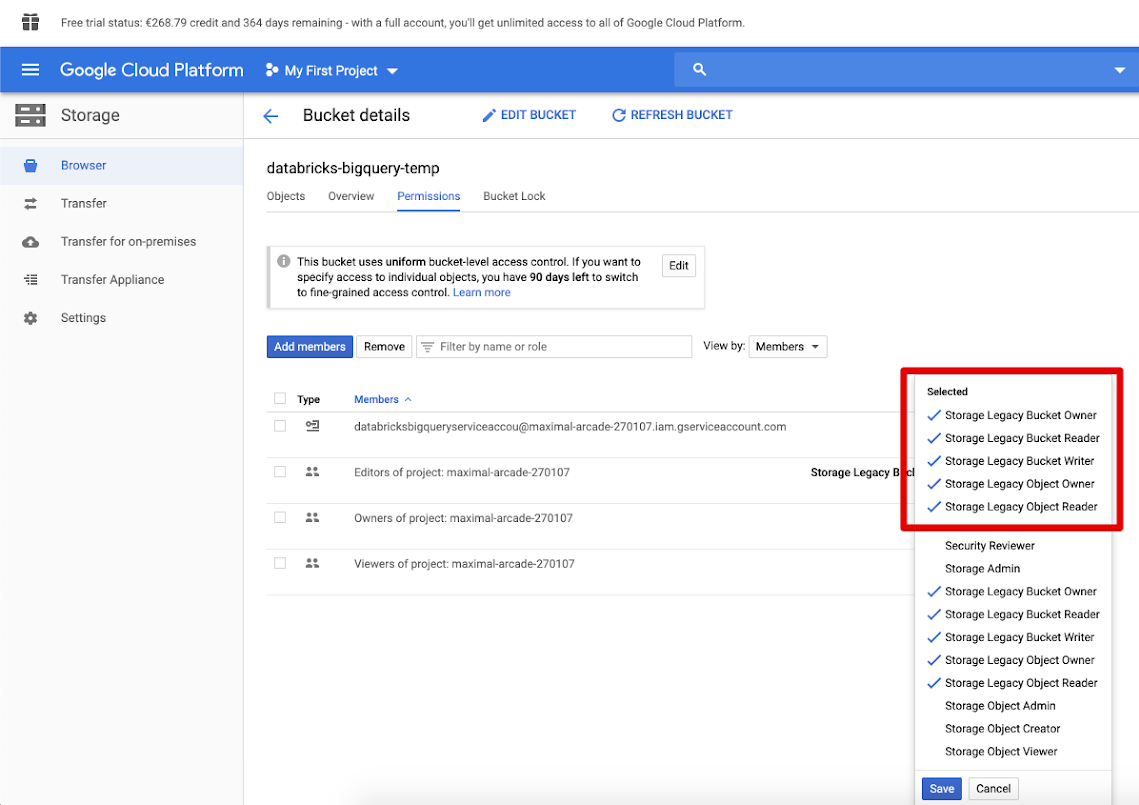
Klikněte na ULOŽIT.
Krok 2: Nastavení Azure Databricks
Pokud chcete nakonfigurovat cluster pro přístup k tabulkám BigQuery, musíte jako konfiguraci Sparku zadat soubor klíče JSON. K kódování souboru klíče JSON použijte místní nástroj. Pro účely zabezpečení nepoužívejte webový ani vzdálený nástroj, který by mohl přistupovat k vašim klíčům.
Na kartě Konfigurace Sparku přidejte následující konfiguraci Sparku. Nahraďte <base64-keys> řetězcem souboru klíče JSON s kódováním Base64. Ostatní položky v hranatých závorkách (například <client-email>) nahraďte hodnotami těchto polí ze souboru klíče JSON.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Čtení a zápis do tabulky BigQuery
Pokud chcete přečíst tabulku BigQuery, zadejte
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Pokud chcete zapisovat do tabulky BigQuery, zadejte
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
kde <bucket-name> je název kontejneru, který jste vytvořili v kontejneru Pro dočasné úložiště Google Cloud Storage (GCS). Informace o požadavcích <project-id> a <parent-id> hodnotách najdete v tématu Oprávnění.
Vytvoření externí tabulky z BigQuery
Důležité
Tato funkce není podporována katalogem Unity.
V Databricks můžete deklarovat nespravovanou tabulku, která bude číst data přímo z BigQuery:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Příklad poznámkového bloku Pythonu: Načtení tabulky Google BigQuery do datového rámce
Následující poznámkový blok Pythonu načte tabulku Google BigQuery do datového rámce Azure Databricks.
Ukázkový poznámkový blok Pythonu Pro Google BigQuery
Příklad poznámkového bloku Scala: Načtení tabulky Google BigQuery do datového rámce
Následující poznámkový blok Scala načte tabulku Google BigQuery do datového rámce Azure Databricks.