Instalace závislostí poznámkového bloku
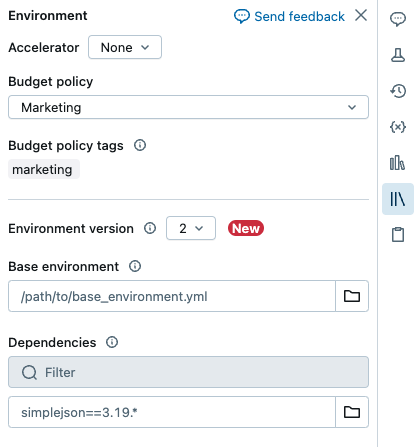
Závislosti Pythonu pro bezserverové poznámkové bloky můžete nainstalovat pomocí bočního panelu Prostředí . Tento panel poskytuje jedno místo pro úpravy, zobrazení a export požadavků na knihovnu poznámkového bloku. Tyto závislosti je možné přidat pomocí základního prostředí nebo jednotlivě.
Informace o úkolech, které nejsou poznámkovými bloky, najdete v tématu Konfigurace prostředí a závislostí pro úlohy, které nejsou poznámkovými bloky.
Důležité
Neinstalujte PySpark ani žádnou knihovnu, která nainstaluje PySpark jako závislost na bezserverových poznámkových blocích. Tím zastavíte relaci a výsledkem bude chyba. Pokud k tomu dojde, odeberte knihovnu a resetujte prostředí.
Konfigurace základního prostředí
Základní prostředí je soubor YAML uložený jako soubor pracovního prostoru nebo na svazku katalogu Unity, který určuje další závislosti prostředí. Základní prostředí je možné sdílet mezi poznámkovými bloky. Konfigurace základního prostředí:
Vytvořte soubor YAML, který definuje nastavení pro virtuální prostředí Pythonu. Následující příklad YAML, který je založen na specifikaci prostředí projektů MLflow, definuje základní prostředí s několika závislostmi knihovny:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - my-library==6.1 - "/Workspace/Shared/Path/To/simplejson-3.19.3-py3-none-any.whl" - git+https://github.com/databricks/databricks-cliNahrajte soubor YAML jako soubor pracovního prostoru nebo do svazku katalogu Unity. Viz Importovat soubor nebo Nahrát soubory do svazku katalogu Unity.
Napravo od poznámkového bloku klikněte na tlačítko
 a rozbalte boční panel Prostředí. Toto tlačítko se zobrazí jenom v případě, že je poznámkový blok připojený k bezserverovému výpočetnímu prostředí.
a rozbalte boční panel Prostředí. Toto tlačítko se zobrazí jenom v případě, že je poznámkový blok připojený k bezserverovému výpočetnímu prostředí.Do pole Základní prostředí zadejte cestu k nahranému souboru YAML nebo k němu přejděte a vyberte jej.
Klikněte na tlačítko Použit. Tím se nainstalují závislosti ve virtuálním prostředí poznámkového bloku a restartuje proces Pythonu.
Uživatelé mohou přepsat závislosti zadané v základním prostředí instalací závislostí jednotlivě.
Konfigurace prostředí poznámkového bloku
Závislosti můžete také nainstalovat do poznámkového bloku připojeného k bezserverovému výpočetnímu prostředí pomocí prostředí bočním panelu:
- Napravo od poznámkového bloku klikněte na tlačítko a rozbalte tak boční panel prostředí . Toto tlačítko se zobrazí jenom v případě, že je poznámkový blok připojený k bezserverovému výpočetnímu prostředí.
- V rozevíracím seznamu Verze prostředí vyberte verzi prostředí. Viz verze bezserverového prostředí . Databricks doporučuje vybrat nejnovější verzi, abyste získali nejaktuálnější funkce poznámkového bloku up-to.
- V části Závislosti klepněte na tlačítko Přidat závislost a zadejte cestu závislosti knihovny do pole. Závislost můžete zadat v libovolném formátu, který je platný v souboru requirements.txt .
- Klikněte na tlačítko Použit. Tím se nainstalují závislosti ve virtuálním prostředí poznámkového bloku a restartuje proces Pythonu.
Poznámka:
Úloha využívající bezserverové výpočetní prostředky před spuštěním kódu poznámkového bloku nainstaluje specifikaci prostředí poznámkového bloku. To znamená, že při plánování poznámkových bloků jako úloh není potřeba přidávat závislosti. Viz Konfigurace prostředí a závislostí.
Zobrazení nainstalovaných závislostí a protokolů pip
Pokud chcete zobrazit nainstalované závislosti, klikněte na Nainstalované v panelu Prostředí poznámkového bloku. Protokoly instalace pip pro prostředí poznámkového bloku jsou k dispozici, také kliknutím na pip protokoly ve spodní části panelu.
resetování prostředí
Pokud je poznámkový blok připojený k bezserverovému výpočetnímu prostředí, Databricks automaticky ukládá obsah virtuálního prostředí poznámkového bloku do mezipaměti. To znamená, že obvykle nemusíte přeinstalovat závislosti Pythonu zadané v postranním panelu Prostředí při otevření existujícího poznámkového bloku, i když byl odpojen kvůli nečinnosti.
Ukládání do mezipaměti virtuálního prostředí Pythonu platí také pro úlohy. Když se spustí úloha, jakýkoli úkol, který sdílí stejnou sadu závislostí jako dokončený úkol v tomto spuštění, probíhá rychleji, protože požadované závislosti jsou již k dispozici.
Poznámka:
Pokud změníte implementaci vlastního balíčku Pythonu použitého v úloze na bezserverové verzi, musíte také aktualizovat její číslo verze, aby úlohy mohly vyzvednout nejnovější implementaci.
Pokud chcete vymazat mezipaměť prostředí a provést novou instalaci závislostí zadaných v Prostředí bočním panelu poznámkového bloku připojeného k bezserverovému výpočetnímu prostředí, klikněte na šipku vedle Použít a potom klikněte na Obnovit prostředí.
Poznámka:
Pokud instalujete balíčky, které přeruší nebo změní základní poznámkový blok nebo prostředí Apache Spark, resetujte virtuální prostředí. Odpojení poznámkového bloku od bezserverového výpočetního prostředí a jeho opětovné připojení nemusí nutně vymazat celou mezipaměť prostředí. Resetováním prostředí se přeinstalují všechny závislosti zadané na bočním panelu Environment, proto se ujistěte, že problémové balíčky jsou odstraněny před resetováním.
Konfigurace prostředí a závislostí pro úlohy, které nejsou poznámkovými bloky
Pro jiné podporované typy úloh, jako je skript Pythonu, kolo Pythonu nebo úlohy dbt, obsahuje výchozí prostředí nainstalované knihovny Pythonu. Seznam nainstalovaných knihoven najdete v části Nainstalované knihovny Pythonu části verze klienta, kterou používáte. Viz verze bezserverového prostředí . Pokud úloha vyžaduje knihovnu Pythonu, která není nainstalovaná, můžete knihovnu nainstalovat z souborů pracovního prostoru, objemů Unity Catalogu , nebo z veřejných úložišť balíčků. Přidání knihovny při vytváření nebo úpravě úkolu:
V rozevírací nabídce Prostředí a knihovny klikněte vedle
 výchozího prostředí nebo klikněte na + Přidat nové prostředí.
výchozího prostředí nebo klikněte na + Přidat nové prostředí.
V rozevíracím seznamu Verze prostředí vyberte verzi prostředí. Viz verze bezserverového prostředí . Databricks doporučuje vybrat nejnovější verzi, abyste získali nejvíce up-tofunkcí data.
V dialogovém okně Konfigurovat prostředí klikněte na + Přidat knihovnu.
Vyberte typ závislosti z rozevírací nabídky pod Knihovny.
Do textového pole Cesta k souboru zadejte cestu ke knihovně.
Pro kolo Pythonu v souboru pracovního prostoru by měla být cesta absolutní a začínat na
/Workspace/.Pro Python Wheel ve svazku Unity Catalog by měla být cesta
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.U souboru
requirements.txtvyberte PyPi a zadejte-r /path/to/requirements.txt.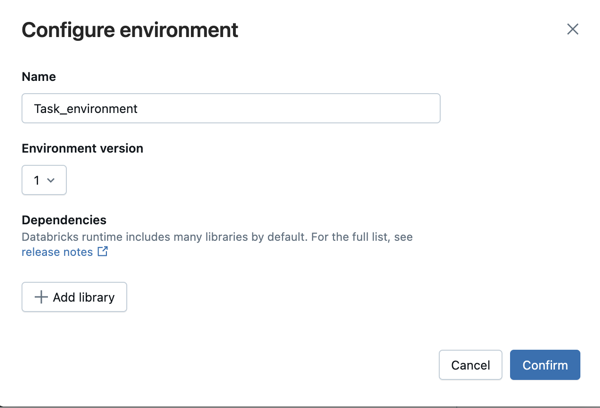
- Chcete-li přidat další knihovnu, klikněte na tlačítko Potvrdit nebo přidat knihovnu.
- Pokud přidáváte úkol, klikněte na Vytvořit úkol. Pokud upravujete úkol, klikněte na Uložit úkol.
Konfigurace výchozích úložišť balíčků Pythonu
Správci můžou nakonfigurovat privátní nebo ověřené úložiště balíčků v rámci pracovních prostorů jako výchozí konfiguraci pip pro bezserverové poznámkové bloky i bezserverové úlohy. To umožňuje uživatelům instalovat balíčky z interních úložišť Pythonu bez explicitního definování index-url nebo extra-index-url. Pokud jsou ale tyto hodnoty zadané v kódu nebo v poznámkovém bloku, mají přednost před výchozími hodnotami pracovního prostoru.
Tato konfigurace využívá tajných kódů Databricks k bezpečnému ukládání a správě adres URL a přihlašovacích údajů úložiště. Správci mohou nakonfigurovat nastavení pomocí stránky nastavení pracovního prostoru nebo pomocí předdefinovaného oboru tajných kódů a rozhraní příkazového řádku Databricks příkazy tajných kódů nebo rozhraní REST API.
Nastavení pomocí stránky nastavení pracovního prostoru
Správci pracovního prostoru můžou pomocí stránky nastavení pracovního prostoru přidat nebo odebrat výchozí úložiště balíčků Pythonu.
- Jako správce pracovního prostoru se přihlaste k pracovnímu prostoru Databricks.
- Klikněte na své uživatelské jméno v horním panelu pracovního prostoru Databricks a vyberte Nastavení.
- Klikněte na kartu Compute.
- Vedle výchozích úložišť balíčkůklikněte na Spravovat.
- (Volitelné) Přidejte nebo odeberte adresu URL indexu, extra indexové adresy URL nebo vlastní certifikát SSL.
- Kliknutím na Uložit uložte změny.
Poznámka:
Změny nebo odstranění tajných kódů se použijí po opětovném připojení bezserverového výpočetního prostředí k poznámkovému bloku nebo opětovnému spuštění úloh bez serveru.
Nastavení pomocí rozhraní příkazového řádku tajných kódů nebo rozhraní REST API
Pokud chcete nakonfigurovat výchozí úložiště balíčků Pythonu pomocí rozhraní příkazového řádku nebo rozhraní REST API, vytvořte předdefinovaný obor tajných kódů a nakonfigurujte přístupová oprávnění a přidejte tajné kódy úložiště balíčků.
Předdefinovaný název tajné oblasti
Správci pracovního prostoru můžou nastavit výchozí adresy URL indexu pip nebo adresy URL extra indexu spolu s ověřovacími tokeny a tajnými kódy v určeném oboru tajných kódů v rámci předdefinovaných klíčů:
- Název oboru tajného kódu:
databricks-package-management - Tajný klíč pro adresu URL indexu:
pip-index-url - Tajný klíč pro extra-index-urls:
pip-extra-index-urls - Tajný klíč pro obsah certifikace SSL:
pip-cert
Vytvoření prostoru tajných údajů
Obor tajných kódů je možné vytvořit pomocí rozhraní příkazového řádku Databricks databricks-package-management.
databricks secrets create-scope databricks-package-management
databricks secrets put-acl databricks-package-management admins MANAGE
databricks secrets put-acl databricks-package-management users READ
Přidejte tajemství úložiště Python balíčků
Přidejte podrobnosti o úložišti balíčků Pythonu pomocí předdefinovaných názvů tajných klíčů, přičemž všechna tři pole jsou volitelná.
# Add index URL.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-index-url", "string_value":"<index-url-value>"}'
# Add extra index URLs. If you have multiple extra index URLs, separate them using white space.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-extra-index-urls", "string_value":"<extra-index-url-1 extra-index-url-2>"}'
# Add cert content. If you want to pip configure a custom SSL certificate, put the cert file content here.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-cert", "string_value":"<cert-content>"}'
Úprava nebo odstranění tajných kódů privátního úložiště PyPI
K úpravě tajných kódů úložiště PyPI použijte příkaz put-secret. Pokud chcete odstranit tajné kódy úložiště PyPI, použijte delete-secret, jak je znázorněno níže:
# delete secret
databricks secrets delete-secret databricks-package-management pip-index-url
databricks secrets delete-secret databricks-package-management pip-extra-index-urls
databricks secrets delete-secret databricks-package-management pip-cert
# delete scope
databricks secrets delete-scope databricks-package-management