Konfigurace výpočetních prostředků (starší verze)
Poznámka:
Toto jsou pokyny pro starší uživatelské rozhraní clusteru pro vytvoření a jsou zahrnuty pouze pro historickou přesnost. Všichni zákazníci by měli používat aktualizované uživatelské rozhraní pro vytvoření clusteru.
Tento článek vysvětluje možnosti konfigurace, které jsou k dispozici při vytváření a úpravách clusterů Azure Databricks. Zaměřuje se na vytváření a úpravy clusterů pomocí uživatelského rozhraní. Další metody najdete v rozhraní příkazového řádku Databricks, rozhraní API clusterů a zprostředkovatele Terraformu Databricks.
Nápovědu k rozhodování o tom, jaká kombinace možností konfigurace nejlépe vyhovuje vašim potřebám, najdete v osvědčených postupech konfigurace clusteru.
Zásady clusteru
Zásady clusteru omezují možnost konfigurovat clustery na základě sady pravidel. Pravidla zásad omezují atributy nebo hodnoty atributů, které jsou k dispozici pro vytvoření clusteru. Zásady clusteru mají seznamy ACL, které omezují jejich použití na konkrétní uživatele a skupiny, a tím omezují zásady, které můžete vybrat při vytváření clusteru.
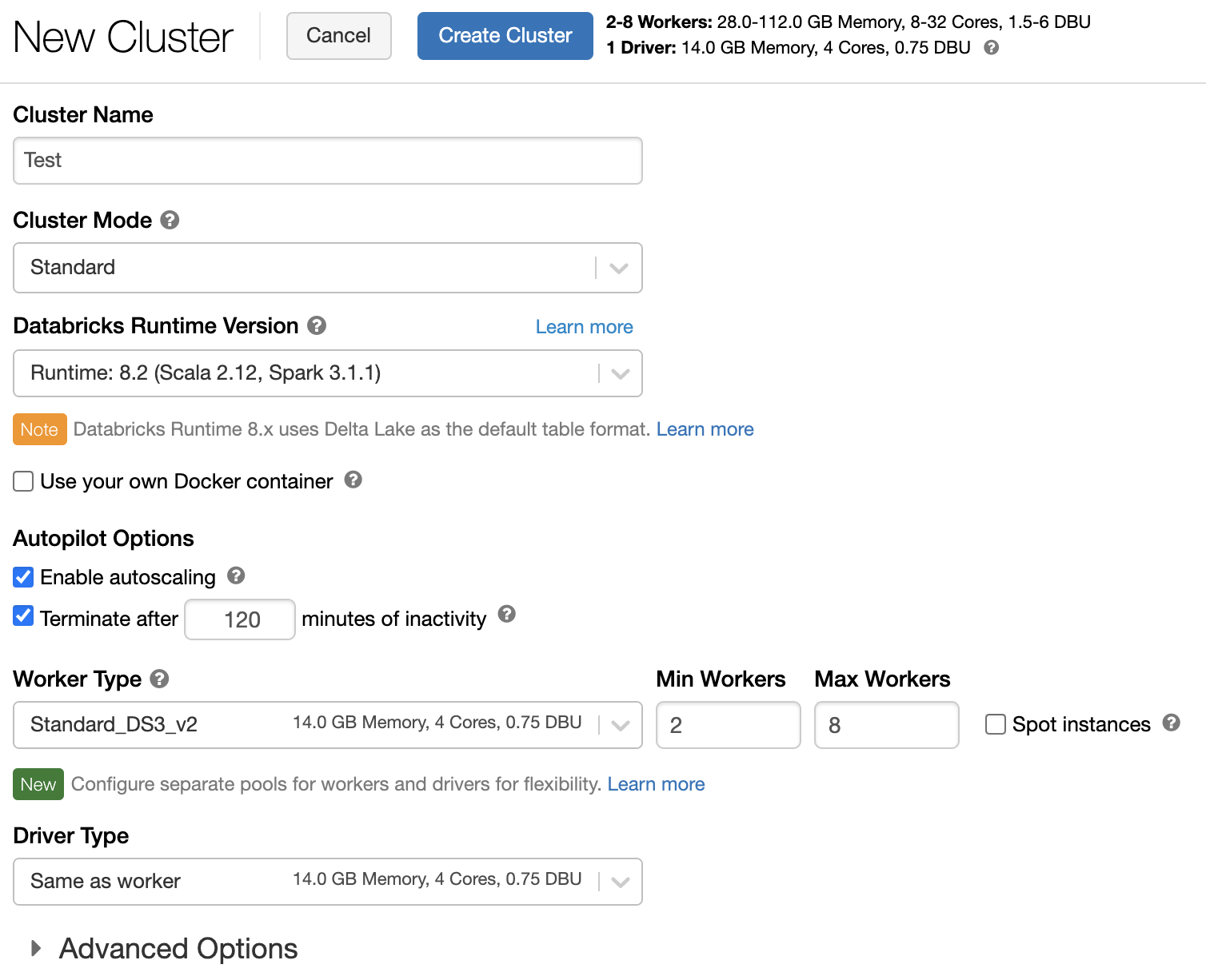
Pokud chcete nakonfigurovat zásady clusteru, vyberte v rozevíracím seznamu Zásady zásady clusteru.
Poznámka:
Pokud v pracovním prostoru nebyly vytvořeny žádné zásady, rozevírací seznam Zásady se nezobrazí.
Pokud máte:
- oprávnění k vytvoření clusteru, můžete vybrat politiku Neomezené a vytvořit plně konfigurovatelné clustery. Zásady Neomezené neomezují žádné atributy clusteru ani hodnoty atributů.
- Můžete vybrat oprávnění pro vytváření clusterů i přístup k zásadám clusteru, včetně neomezené zásady a dalších zásad, ke kterým máte přístup.
- Přístup jenom k zásadám clusteru, můžete vybrat zásady, ke kterým máte přístup.
Režim clusteru
Poznámka:
Tento článek popisuje starší uživatelské rozhraní clusterů. Informace o novém uživatelském rozhraní clusterů (ve verzi Preview) najdete v referenčních informacích ke konfiguraci výpočetních prostředků. To zahrnuje některé změny terminologie pro typy a režimy přístupu ke clusteru. Porovnání nových a starších typů clusterů najdete v tématu Změny uživatelského rozhraní clusterů a režimy přístupu ke clusteru. V uživatelském rozhraní preview:
- Clustery standardního režimu se teď označují jako clustery bez sdíleného přístupu izolace.
- Vysoká souběžnost s ACL tabulek je nyní nazývána jako clustery v režimu sdíleného přístupu .
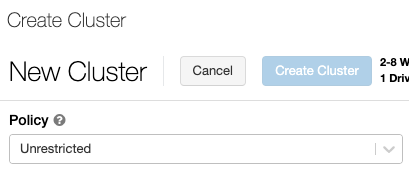
Azure Databricks podporuje tři režimy clusteru: Standard, High Concurrency a Single Node. Výchozí režim clusteru je Standard.
Důležité
- Pokud je váš pracovní prostor přiřazen k katalogu Unity metastore, clustery s vysokou úrovní souběžnosti nejsou k dispozici. Místo toho použijete režim přístupu k zajištění integrity řízení přístupu a vynucování záruk silné izolace. Viz také režimy Accessu.
- Po vytvoření clusteru nelze změnit režim clusteru. Pokud chcete jiný režim clusteru, musíte vytvořit nový cluster.
Konfigurace clusteru zahrnuje nastavení automatického ukončení , jehož výchozí hodnota závisí na režimu clusteru:
- Clustery Standard a Single Node se ve výchozím nastavení automaticky ukončí po 120 minutách.
- Clustery s vysokou souběžností se ve výchozím nastavení automaticky neukončují .
Standardní clustery
Upozorňující
Clustery standardního režimu (někdy označované jako Sdílené clustery bez izolace) můžou sdílet více uživatelů bez izolace mezi uživateli. Pokud používáte režim clusteru s vysokou souběžností bez dalších nastavení zabezpečení, jako jsou seznamy ACL pro tabulky nebopředávání přihlašovacích údajů, používají se stejná nastavení jako clustery v režimu Standard. Správci účtů můžou zabránit automatickému vygenerování interních přihlašovacích údajů pro správce pracovního prostoru Databricks v těchto typech clusteru. Pro bezpečnější možnosti Databricks doporučuje alternativy, jako jsou clustery s vysokou souběžností a seznamy řízení přístupu k tabulkám (ACL).
Pro jednotlivé uživatele se doporučuje jenom cluster Úrovně Standard. Standardní clustery můžou spouštět úlohy vyvinuté v Pythonu, SQL, R a Scala.
Clustery s vysokou souběžností
Cluster s vysokou souběžností je spravovaný cloudový prostředek. Klíčové výhody clusterů s vysokou souběžností jsou, že poskytují jemně odstupňované sdílení pro maximální využití prostředků a minimální latenci dotazů.
Clustery s vysokou souběžností můžou spouštět úlohy vyvinuté v SQL, Pythonu a R. Výkon a zabezpečení clusterů s vysokou souběžností poskytuje spouštění uživatelského kódu v samostatných procesech, což není možné v jazyce Scala.
Kromě toho řízení přístupu k tabulce podporují pouze clustery s vysokou paralelní kapacitou.
Pokud chcete vytvořit cluster s vysokou souběžností, nastavte režim clusteru na Vysoká souběžnost.
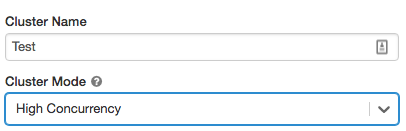
Clustery s jedním uzlem
Cluster s jedním uzlem nemá žádné pracovní procesy a spouští úlohy Sparku na uzlu ovladače.
Naproti tomu cluster úrovně Standard vyžaduje kromě uzlu ovladače k provádění úloh Sparku alespoň jeden pracovní uzel Sparku.
Pokud chcete vytvořit cluster s jedním uzlem, nastavte režim Clusteru na Single Node.
Další informace o práci s clustery s jedním uzlem najdete v tématu Výpočetní prostředky s jedním uzlem nebo více uzly.
Bazény
Pokud chcete zkrátit dobu spuštění clusteru, můžete cluster připojit k předdefinovanému fondu nečinných instancí pro ovladače a pracovní uzly. Cluster se vytvoří pomocí instancí ve fondech. Pokud fond nemá dostatek nečinných prostředků k vytvoření požadovaného ovladače nebo pracovních uzlů, fond se rozšíří přidělením nových instancí od poskytovatele instance. Po ukončení připojeného clusteru se instance, které používá, vrátí do fondů a dají se znovu použít jiným clusterem.
Pokud pro pracovní uzly zvolíte fond, ale ne pro ovladač, uzel ovladače převezme fond z konfigurace pracovního uzlu.
Důležité
Pokud se pokusíte vybrat fond pro uzel ovladače, ale ne pro pracovní uzly, dojde k chybě a cluster se nevytvoří. Tento požadavek brání situaci, kdy musí uzel ovladače čekat na vytvoření pracovních uzlů, nebo kdy naopak pracovní uzly musí čekat na vytvoření uzlu ovladače.
Další informace o práci s fondy v Azure Databricks najdete v referenčních informacích ke konfiguraci fondu.
Databricks Runtime
Runtimy Databricks jsou soubor základních komponent, které běží na clusterech . Všechny moduly runtime Databricks zahrnují Apache Spark a přidávají komponenty a aktualizace, které zlepšují použitelnost, výkon a zabezpečení. Podrobnosti najdete v poznámkách k verzi modulu Databricks Runtime a jejich kompatibilitě.
Azure Databricks nabízí několik typů modulů runtime a několik verzí těchto typů modulu runtime v rozevíracím seznamu Verze modulu runtime Databricks při vytváření nebo úpravách clusteru.
Akcelerace foton
Photon je k dispozici pro clustery s Modulem Databricks Runtime 9.1 LTS a novějším.
Pokud chcete povolit akceleraci Photon, zaškrtněte políčko Použít akceleraci photon.
V případě potřeby můžete zadat typ instance v rozevíracím seznamu Typ pracovního procesu a Typ ovladače.
Databricks doporučuje následující typy instancí pro optimální cenu a výkon:
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
Aktivitu Photon můžete zobrazit v uživatelském rozhraní Sparku. Následující snímek obrazovky ukazuje dag podrobností dotazu. Existují dvě indikace Photon v DAG. Nejprve operátory Photon začínají na "Photon", PhotonGroupingAggnapříklad . Za druhé, v DAG jsou operátory Photon a fáze barevné broskve, zatímco jiné než Foton jsou modré.
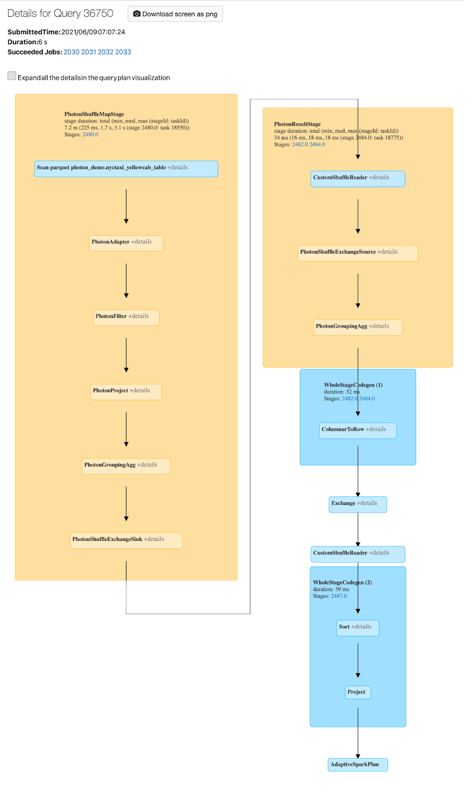
Image Dockeru
U některých verzí Modulu runtime Databricks můžete při vytváření clusteru zadat image Dockeru. Mezi příklady případů použití patří přizpůsobení knihovny, zlaté prostředí kontejneru, které se nemění, a integrace CI/CD Dockeru.
Image Dockeru můžete také použít k vytváření vlastních prostředí hlubokého učení v clusterech se zařízeními GPU.
Pokyny najdete v tématu Přizpůsobení kontejnerů pomocí služby Databricks Container Service a Databricks Container Services na výpočetních prostředcích GPU.
Typ uzlu clusteru
Cluster se skládá z jednoho uzlu ovladače a nuly nebo více pracovních uzlů.
Pro ovladače a pracovní uzly můžete vybrat samostatné typy instancí poskytovatele cloudu, ale ve výchozím nastavení používá uzel ovladače stejný typ instance jako pracovní uzel. Různé rodiny typů instancí odpovídají různým případům použití, jako jsou úlohy náročné na paměť nebo úlohy náročné na výpočetní výkon.
Poznámka:
Pokud vaše požadavky na zabezpečení zahrnují izolaci výpočetních prostředků, vyberte jako typ pracovního procesu Standard_F72s_V2 instanci. Tyto typy instancí představují izolované virtuální počítače, které spotřebovávají celého fyzického hostitele a poskytují potřebnou úroveň izolace potřebné pro podporu, například úlohy ministerstva obrany USA (IL5).
Uzel ovladače
Uzel ovladače udržuje informace o stavu všech poznámkových bloků připojených ke clusteru. Uzel ovladače udržuje také kontext Sparku (SparkContext), interpretuje všechny příkazy spuštěné z poznámkového bloku nebo knihovny v clusteru a spouští hlavní uzel Apache Sparku, který se koordinuje s exekutory Sparku.
Výchozí hodnota typu uzlu ovladače je stejná jako hodnota typu pracovního uzlu. Pokud plánujete velké collect() množství dat z pracovních procesů Sparku, můžete zvolit větší typ uzlu ovladače s větší pamětí a analyzovat je v poznámkovém bloku.
Tip
Vzhledem k tomu, že uzel ovladače udržuje všechny informace o stavu připojených poznámkových bloků, nezapomeňte odpojit nepoužívané poznámkové bloky z uzlu ovladače.
Pracovní uzel
Na pracovních uzlech Azure Databricks běží exekutory Sparku a další služby potřebné ke správnému fungování clusterů. V případě distribuce zatížení pomocí Sparku se veškeré distribuované zpracování odehrává na pracovních uzlech. Azure Databricks spouští jeden exekutor na pracovní uzel; proto se termíny exekutor a pracovní proces používají zaměnitelně v kontextu architektury Azure Databricks.
Tip
Ke spuštění úlohy Sparku potřebujete aspoň jeden pracovní uzel. Pokud cluster nemá žádné pracovní procesy, můžete na uzlu ovladače spustit jiné příkazy než příkazy Sparku, ale příkazy Sparku selžou.
Typy instancí GPU
Pro výpočetně náročné úlohy, které vyžadují vysoký výkon, jako jsou úlohy spojené s hloubkovým učením, podporuje Azure Databricks clustery akcelerované pomocí grafických procesorů (GPU). Další informace najdete v tématu Výpočetní výkon s podporou GPU.
Spotové instance
Pokud chcete ušetřit náklady, můžete použít spotové instance, označované také jako spotové virtuální počítače Azure, zaškrtnutím políčka Spotové instance.

První instance bude vždy na vyžádání (uzel ovladače je vždy na vyžádání) a následné instance budou spotové instance. Pokud se spotové instance vyřazují z důvodu nedostupnosti, nasadí se instance na vyžádání, aby se nahradily vyřazené instance.
Velikost clusteru a automatické škálování
Při vytváření clusteru Azure Databricks můžete buď poskytnout pevný počet pracovních procesů pro cluster, nebo zadat minimální a maximální počet pracovních procesů pro cluster.
Když zadáte cluster s pevnou velikostí, Azure Databricks zajistí, že váš cluster bude mít zadaný počet pracovních procesů. Když zadáte rozsah pro počet pracovních procesů, Databricks zvolí odpovídající počet pracovních procesů potřebných ke spuštění vaší úlohy. Označuje se jako automatické škálování.
Díky automatickému škálování Azure Databricks dynamicky relokuje pracovní procesy, aby zohlednily charakteristiky vaší úlohy. Některé části kanálu můžou být výpočetně náročnější než ostatní a Databricks během těchto fází vaší úlohy automaticky přidá další pracovní procesy (a odebere je, když už nejsou potřeba).
Automatické škálování usnadňuje dosažení vysokého využití clusteru, protože cluster nemusíte zřizovat tak, aby odpovídal úloze. To platí zejména pro úlohy, jejichž požadavky se v průběhu času mění (například zkoumání datové sady v průběhu dne), ale může se také vztahovat na jednorázovou kratší úlohu, jejíž požadavky na zřizování jsou neznámé. Automatické škálování tak nabízí dvě výhody:
- Úlohy můžou běžet rychleji v porovnání s nedostatečně zřízeným clusterem s konstantní velikostí.
- Automatické škálování clusterů může snížit celkové náklady v porovnání se staticky velkým clusterem.
V závislosti na konstantní velikosti clusteru a úlohy nabízí automatické škálování jednu nebo obě tyto výhody současně. Velikost clusteru může být nižší než minimální počet pracovních procesů vybraných při ukončení instancí poskytovatelem cloudu. V tomto případě Azure Databricks neustále opakuje pokusy o opětovné zřízení instancí, aby se zachoval minimální počet pracovních procesů.
Poznámka:
Automatické škálování není dostupné pro úlohy spark-submit.
Jak se chová automatické škálování
- Vertikálně navyšuje kapacitu z min na maximum v 2 krocích.
- Můžete vertikálně snížit kapacitu i v případě, že cluster není nečinný, když se podíváte na stav shuffle souboru.
- Škáluje se dolů na základě procenta aktuálních uzlů.
- V clusterech úloh se vertikálně navyšují kapacitu, pokud je cluster nedostatečně využitý za posledních 40 sekund.
- V clusterech pro všechny účely se vertikálně navyšují kapacitu, pokud je cluster nedostatečně využitý za posledních 150 sekund.
-
spark.databricks.aggressiveWindowDownSVlastnost konfigurace Sparku určuje v sekundách, jak často cluster provádí rozhodnutí o snížení kapacity. Zvýšení hodnoty způsobí snížení kapacity clusteru pomaleji. Maximální hodnota je 600.
Povolení a konfigurace automatického škálování
Pokud chcete službě Azure Databricks povolit automatickou změnu velikosti clusteru, povolíte automatické škálování clusteru a poskytnete minimální a maximální rozsah pracovních procesů.
Povolte automatické škálování.
All-Purpose clusteru – Na stránce Vytvořit cluster zaškrtněte políčko Povolit automatické škálování v možnosti Autopilotu:

Cluster úloh – Na stránce Konfigurovat cluster zaškrtněte políčko Povolit automatické škálování v boxu Možnosti autopilotu:

Nakonfigurujte minimální a maximální počet pracovních procesů.

Po spuštění clusteru se na stránce podrobností clusteru zobrazí počet přidělených pracovních procesů. Počet přidělených pracovních procesů můžete porovnat s konfigurací pracovního procesu a podle potřeby provádět úpravy.
Důležité
Pokud používáte fond instancí:
- Ujistěte se, že požadovaná velikost clusteru je menší nebo rovna minimálnímu počtu nečinných instancí ve fondu. Pokud je větší, doba potřebná ke spuštění clusteru bude stejná jako u clusteru, který nevyužívá fond.
- Ujistěte se, že maximální velikost clusteru je menší nebo rovna maximální kapacitě fondu. Pokud je větší, vytváření clusteru selže.
Příklad automatického škálování
Pokud změníte konfiguraci statického clusteru na cluster automatického škálování, Azure Databricks okamžitě změní velikost clusteru v rámci minimální a maximální hranice a pak spustí automatické škálování. Následující tabulka například ukazuje, co se stane s clustery s určitou počáteční velikostí, pokud změníte konfiguraci clusteru na automatické škálování mezi 5 a 10 uzly.
| Počáteční velikost | Velikost po rekonfiguraci |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Automatické škálování místního úložiště
Často může být obtížné odhadnout, kolik místa na disku bude konkrétní úloha trvat. Azure Databricks automaticky umožňuje automatické škálování místního úložiště na všech clusterech Azure Databricks, abyste nemuseli odhadnout, kolik gigabajtů spravovaného disku se má připojit k vašemu clusteru.
Díky automatickému škálování místního úložiště Azure Databricks monitoruje množství volného místa na disku dostupném v pracovních prostředcích Spark vašeho clusteru. Pokud pracovní proces začne na disku běžet příliš málo, Databricks automaticky připojí nový spravovaný disk k pracovnímu procesu před vyčerpáním místa na disku. Disky jsou připojené až k limitu 5 TB celkového místa na disku na virtuální počítač (včetně počátečního místního úložiště virtuálního počítače).
Spravované disky připojené k virtuálnímu počítači se odpojily jenom v případech, kdy se virtuální počítač vrátí do Azure. To znamená, že spravované disky se nikdy neodpojily od virtuálního počítače, pokud je součástí spuštěného clusteru. Pokud chcete snížit využití spravovaných disků, Azure Databricks doporučuje použít tuto funkci v clusteru s nakonfigurovanou velikostí clusteru a automatickým škálováním nebo neočekávaným ukončením.
Šifrování místního disku
Důležité
Tato funkce je ve verzi Public Preview.
Některé typy instancí, které používáte ke spouštění clusterů, můžou mít místně připojené disky. Azure Databricks může ukládat data prohazování nebo dočasné data na těchto místně připojených discích. Pokud chcete zajistit, aby všechna neaktivní uložená data byla šifrovaná pro všechny typy úložišť, včetně dat prohazování uložených dočasně na místních discích clusteru, můžete povolit šifrování místního disku.
Důležité
Vaše úlohy můžou běžet pomaleji kvůli dopadu čtení a zápisu šifrovaných dat na a z místních svazků.
Pokud je povolené šifrování místního disku, Azure Databricks generuje místně šifrovací klíč, který je jedinečný pro každý uzel clusteru a slouží k šifrování všech dat uložených na místních discích. Rozsah klíče je místní pro každý uzel clusteru a je zničen společně se samotným uzlem clusteru. Během své životnosti se klíč nachází v paměti pro šifrování a dešifrování a je uložen zašifrovaný na disku.
Pokud chcete povolit šifrování místního disku, musíte použít rozhraní API clusterů. Během vytváření nebo úprav clusteru nastavte:
{
"enable_local_disk_encryption": true
}
Příklady volání těchto rozhraní API najdete v rozhraní API clusterů.
Tady je příklad volání vytvoření clusteru, které umožňuje šifrování místního disku:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Režim zabezpečení
Pokud je váš pracovní prostor přiřazen ke katalogu Unity metastore, použijete režim zabezpečení místo režimu clusteru s vysokou souběžností zajistit integritu řízení přístupu a vynutit záruky silné izolace. U katalogu Unity není k dispozici režim clusteru s vysokou souběžností.
V části Pokročilé možnostivyberte z následujících režimů zabezpečení clusteru.
- Žádné: Žádná izolace. Nevynucuje řízení přístupu k místní tabulce pracovního prostoru ani předávání přihlašovacích údajů. Nelze získat přístup k datům katalogu Unity.
- Jeden uživatel: Může ho používat jenom jeden uživatel (ve výchozím nastavení uživatel, který cluster vytvořil). Ostatní uživatelé se nemůžou připojit ke clusteru. Při přístupu k zobrazení z clusteru s režimem zabezpečení jednoho uživatele se zobrazení spustí s oprávněními uživatele. Clustery s jedním uživatelem podporují úlohy pomocí Pythonu, Scaly a R. Inicializační skripty, instalace knihovny a připojení DBFS se podporují v clusterech s jedním uživatelem. Automatizované úlohy by měly používat clustery s jedním uživatelem.
- Izolace uživatelů: Může být sdíleno více uživateli. Podporují se jenom úlohy SQL. Instalace knihoven, inicializační skripty a připojení DBFS jsou zakázány, aby se mezi uživateli clusteru vynucuje striktní izolace.
- ACL tabulky pouze (starší verze): Vynucuje řízení přístupu k tabulce místního pracovního prostoru, ale nemůže získat přístup k datům Unity Catalog.
- Propustnost pouze (zastaralá verze): Vynucuje předávání přihlašovacích údajů místního pracovního prostoru, ale nemá přístup k datům katalogu Unity.
Jedinými režimy zabezpečení podporovanými úlohami katalogu Unity jsou Jeden uživatel a Izolace uživatelů.
Další informace najdete v tématu Režimy accessu.
Konfigurace Sparku
Pokud chcete ladit úlohy Sparku, můžete v konfiguraci clusteru zadat vlastní vlastnosti konfigurace Sparku.
Na stránce konfigurace clusteru klikněte na přepínač Upřesnit možnosti .
Klikněte na kartu Spark .
V konfiguraci Sparku zadejte vlastnosti konfigurace jako jeden pár klíč-hodnota na řádek.
Když nakonfigurujete cluster pomocírozhraní API clusteru
Databricks nedoporučuje používat globální inicializační skripty.
Pokud chcete nastavit vlastnosti Sparku pro všechny clustery, vytvořte globální inicializační skript:
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Načtení vlastnosti konfigurace Sparku z tajného kódu
Databricks doporučuje ukládat citlivé informace, jako jsou hesla, v tajném kódu místo prostého textu. Pokud chcete odkazovat na tajný klíč v konfiguraci Sparku, použijte následující syntaxi:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Pokud například chcete nastavit vlastnost konfigurace Sparku s názvem password na hodnotu tajného kódu uloženého v secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Další informace najdete v tématu Správa tajných kódů.
Proměnné prostředí
Můžete nakonfigurovat vlastní proměnné prostředí, ke kterým máte přístup z inicializačních skriptů spuštěných v clusteru. Databricks také poskytuje předdefinované proměnné prostředí, které můžete použít v inicializačních skriptech. Tyto předdefinované proměnné prostředí nelze přepsat.
Na stránce konfigurace clusteru klikněte na přepínač Upřesnit možnosti .
Klikněte na kartu Spark .
Nastavte proměnné prostředí v poli Proměnné prostředí.
Proměnné prostředí můžete také nastavit pomocí pole spark_env_vars v Vytvořit nové rozhraní API clusteru nebo Aktualizovat rozhraní API konfigurace clusteru.
Značky clusteru
Značky clusteru umožňují snadno monitorovat náklady na cloudové prostředky používané různými skupinami ve vaší organizaci. Značky můžete zadat jako páry klíč-hodnota při vytváření clusteru a Azure Databricks tyto značky použije na cloudové prostředky, jako jsou virtuální počítače a diskové svazky, a také sestavy využití DBU.
U clusterů spuštěných z fondů se vlastní značky clusteru použijí jenom na sestavy využití DBU a nešírují se do cloudových prostředků.
Podrobné informace o tom, jak kategorie značek fondu a clusteru vzájemně působí, najdete v tématu Použití atributů pomocí značek.
Pro usnadnění používání Azure Databricks pro každý cluster používá čtyři výchozí značky: Vendor, Creator, ClusterNamea ClusterId.
Kromě toho v clusterech úloh používá Azure Databricks dvě výchozí značky: RunName a JobId.
U prostředků používaných službou Databricks SQL používá Azure Databricks také výchozí značku SqlWarehouseId.
Upozorňující
Nepřiřazujte vlastní značku s klíčem Name ke clusteru. Každý cluster má značku Name, jejíž hodnota je nastavená službou Azure Databricks. Pokud změníte hodnotu přidruženou ke klíči Name, azure Databricks už cluster nemůže sledovat. V důsledku toho se cluster nemusí po nečinnosti ukončit a bude nadále vyžadovat náklady na využití.
Vlastní značky můžete přidat při vytváření clusteru. Konfigurace značek clusteru:
Na stránce konfigurace clusteru klikněte na přepínač Upřesnit možnosti .
V dolní části stránky klikněte na kartu Značky .

Přidejte pár klíč-hodnota pro každou vlastní značku. Můžete přidat až 43 vlastních značek.
Přístup SSH ke clusterům
Z bezpečnostních důvodů se v Azure Databricks ve výchozím nastavení port SSH zavře. Pokud chcete povolit přístup SSH ke svým clusterům Spark, obraťte se na podporu Azure Databricks.
Poznámka:
SSH je možné povolit jenom v případě, že je váš pracovní prostor nasazený ve vaší vlastní virtuální síti Azure.
Doručení protokolu clusteru
Při vytváření clusteru můžete zadat umístění pro doručování protokolů uzlu ovladače Sparku, pracovních uzlů a událostí. Protokoly se do vybraného cíle doručují každých 5 minut. Po ukončení clusteru Azure Databricks zaručuje doručování všech protokolů vygenerovaných až do ukončení clusteru.
Cíl protokolů závisí na ID clusteru. Pokud je dbfs:/cluster-log-deliveryzadaný cíl , protokoly clusteru se 0630-191345-leap375 doručí do dbfs:/cluster-log-delivery/0630-191345-leap375.
Konfigurace umístění doručení protokolu:
Na stránce konfigurace clusteru klikněte na přepínač Upřesnit možnosti .
Klikněte na kartu Protokolování .
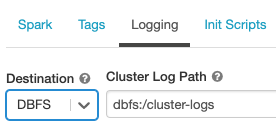
Vyberte typ cíle.
Zadejte cestu k protokolu clusteru.
Poznámka:
Tato funkce je také k dispozici v rozhraní REST API. Podívejte se na rozhraní API clusterů.
Inicializační skripty
Inicializace uzlu clusteru (neboli inicializace) je skript prostředí, který se spouští při spuštění každého uzlu clusteru před spuštěním ovladače Sparku nebo pracovního prostředí JVM. Inicializační skripty můžete použít k instalaci balíčků a knihoven, které nejsou součástí modulu runtime Databricks, úpravě cesty ke třídě systému JVM, nastavení vlastností systému a proměnných prostředí používaných prostředím JVM nebo úpravě parametrů konfigurace Sparku mimo jiné úlohy konfigurace.
Inicializační skripty můžete připojit ke clusteru rozbalením části Upřesnit možnosti a kliknutím na kartu Inicializační skripty .
Podrobné pokyny najdete v tématu Co jsou inicializační skripty?