Referenční informace k systému úloh table
Poznámka:
lakeflow
schema se dříve označovala jako workflow. Obsah obou schémat je identický. Pokud chcete lakeflowschema zobrazit, musíte ho povolit samostatně.
Tento článek slouží jako průvodce používáním systému lakeflowtables pro monitorování úloh ve vašem účtu. Tyto tables zahrnují záznamy ze všech pracovních prostorů ve vašem účtu nasazené ve stejné cloudové oblasti. Pokud chcete zobrazit záznamy z jiného regionu, musíte otevřít tables z pracovního prostoru nasazeného v tomto regionu.
Požadavky
- Správce účtu musí povolit
system.lakeflowschema. Viz Povolení systémových table schémat. - Pro přístup k těmto systémovým tablesmusí uživatelé buď:
- Být správcem metastoru i správcem účtu nebo
- Mít oprávnění
USEaSELECTk systémovým schématům. Viz Grant přístup k systému tables.
Dostupné úlohy tables
Všechny úlohy související se systémem tables existují v system.lakeflowschema. V současné době schema hostuje čtyři tables:
| Table | Popis | Podporuje streamování. | Období bezplatného uchovávání | Zahrnuje globální nebo regionální data. |
|---|---|---|---|---|
| pracovní pozice (Public Preview) | Sleduje všechny úlohy vytvořené v účtu. | Ano | 365 dní | Regionální |
| job_tasks (Veřejná verze) | Sleduje všechny pracovní úkoly, které probíhají v účtu. | Ano | 365 dní | Regionální |
| job_run_timeline (Veřejná ukázka) | Sleduje spuštění úlohy a související metadata. | Ano | 365 dní | Regionální |
| job_task_run_timeline (Veřejná ukázka) | Sleduje spuštění úloh a související metadata. | Ano | 365 dní | Regionální |
Podrobné schema reference
Následující části obsahují schema odkazy na každý systém související s úlohami tables.
práce tableschema
jobs
table je pomalu se měnící dimenze table (SCD2). Když se řádek změní, vygeneruje se nový řádek a logicky nahradí předchozí řádek.
Table cesta: system.lakeflow.jobs
| Column název | Datový typ | Popis | Poznámky |
|---|---|---|---|
account_id |
string | ID účtu, do které tato úloha patří | |
workspace_id |
string | ID pracovního prostoru, do které tato úloha patří | |
job_id |
string | ID úlohy | Pouze jedinečné v rámci jednoho pracovního prostoru |
name |
string | Uživatelem zadaný název úlohy | |
description |
string | Popis úlohy zadaný uživatelem | Toto pole je prázdné, pokud máte nakonfigurované klíče spravované zákazníkem. Nenaplněno pro řádky generované před koncem srpna 2024 |
creator_id |
string | ID entity, která úlohu vytvořila | |
tags |
string | Vlastní značky přiřazené uživatelem přidružené k této úloze | |
change_time |
časové razítko | Čas poslední změny úlohy | Timezone bylo zaznamenáno jako +00:00 (UTC) |
delete_time |
časové razítko | Čas odstranění úlohy uživatelem | Timezone bylo zaznamenáno jako +00:00 (UTC) |
run_as |
string | ID uživatele nebo instančního objektu, jehož oprávnění se použijí pro spuštění úlohy |
Příklad dotazu
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
pracovní úkol tableschema
Pracovní úkoly table představují pomalu se měnící dimenzi table (SCD2). Když se řádek změní, vygeneruje se nový řádek a logicky nahradí předchozí řádek.
Table cesta: system.lakeflow.job_tasks
| Column název | Datový typ | Popis | Poznámky |
|---|---|---|---|
account_id |
string | ID účtu, do které tato úloha patří | |
workspace_id |
string | ID pracovního prostoru, do které tato úloha patří | |
job_id |
string | ID úlohy | Pouze jedinečné v rámci jednoho pracovního prostoru |
task_key |
string | Referenční klíč pro úkol v úloze | Pouze jedinečné v rámci jedné úlohy |
depends_on_keys |
pole | Klíče úkolů všech nadřazených závislostí tohoto úkolu | |
change_time |
časové razítko | Čas poslední změny úkolu | Timezone zaznamenáno jako +00:00 (UTC) |
delete_time |
časové razítko | Čas odstranění úkolu uživatelem | Timezone zaznamenáno jako +00:00 (UTC) |
Příklad dotazu
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
časová osa spuštění úlohy tableschema
Časová osa spuštění úlohy table je neměnná a dokončená v době, kdy je vytvořena.
Table cesta: system.lakeflow.job_run_timeline
| Column název | Datový typ | Popis | Poznámky |
|---|---|---|---|
account_id |
string | ID účtu, do které tato úloha patří | |
workspace_id |
string | ID pracovního prostoru, do které tato úloha patří | |
job_id |
string | ID úlohy | Tento klíč je jedinečný pouze v rámci jednoho pracovního prostoru. |
run_id |
string | ID spuštění úlohy | |
period_start_time |
časové razítko | Počáteční čas pro běh nebo časové období |
Timezone informace je zaznamenána na konci hodnoty, přičemž +00:00 představuje UTC. |
period_end_time |
časové razítko | Koncový čas pro běh nebo pro časové období | Informace Timezone se zaznamenávají na konci hodnoty, přičemž +00:00 představuje UTC. |
trigger_type |
string | Typ spouštěče, který může spustit běh | Možnosti valuesnajdete v části typ aktivační události values |
run_type |
string | Typ spuštění úlohy | Pro prohlédnutí možného valuespřejděte na , typ spuštění values. |
run_name |
string | Název spuštění zadaný uživatelem přidružený k tomuto spuštění úlohy | |
compute_ids |
pole | Pole obsahující ID výpočtů úlohy pro provádění nadřazené úlohy | Slouží k identifikaci clusteru úloh používaného typy spuštění WORKFLOW_RUN. Další informace o výpočetních prostředcích najdete v job_task_run_timelinetable.Nenaplněno pro řádky generované před koncem srpna 2024 |
result_state |
string | Výsledek spuštění úlohy | Pro možné valuesse podívejte na výsledek stavu values |
termination_code |
string | Kód ukončení spuštění úlohy | Pro možné values, viz kód ukončení values. Nenaplněno pro řádky generované před koncem srpna 2024 |
job_parameters |
map | parameters na úrovni úlohy použité při spuštění úlohy | V tomto poli nejsou zahrnutá zastaralá nastavení notebook_params. Nenaplněno pro řádky generované před koncem srpna 2024 |
Příklad dotazu
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name={run_name}
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
časová osa spuštění úkolu tableschema
Časová osa spuštění úlohy table je neměnná a dokončená v době, kdy je vytvořena.
Table cesta: system.lakeflow.job_task_run_timeline
| Column název | Datový typ | Popis | Poznámky |
|---|---|---|---|
account_id |
string | ID účtu, do které tato úloha patří | |
workspace_id |
string | ID pracovního prostoru, do které tato úloha patří | |
job_id |
string | ID úlohy | Pouze jedinečné v rámci jednoho pracovního prostoru |
run_id |
string | ID spuštění této úlohy | |
job_run_id |
string | ID spuštění úlohy | Nenaplněno pro řádky generované před koncem srpna 2024 |
parent_run_id |
string | ID nadřazeného spuštění | Nenaplněno pro řádky generované před koncem srpna 2024 |
period_start_time |
časové razítko | Čas zahájení úkolu nebo časového období | Informace Timezone se zaznamenávají na konci hodnoty s +00:00 představujícím UTC. |
period_end_time |
časové razítko | Koncový čas úkolu nebo časového období |
Timezone informace je zaznamenána na konci hodnoty s +00:00 představujícím UTC. |
task_key |
string | Referenční klíč pro úkol v úloze | Tento klíč je jedinečný pouze v rámci jedné úlohy. |
compute_ids |
pole | Pole compute_ids obsahuje ID clusterů úloh, interaktivních clusterů a sql warehouse používaných úlohou. | |
result_state |
string | Výsledek spuštění úkolové úlohy | Viz možné valuesv části stav výsledku values |
termination_code |
string | Kód ukončení spuštění úlohy | Pro možnosti valuesviz kód ukončení values. Nenaplněno pro řádky generované před koncem srpna 2024 |
Běžné vzory join
Následující části obsahují ukázkové dotazy, které zvýrazňují běžně používané vzory join pro systém úloh tables.
Join úlohy a časová osa jejich spuštění tables
Obohatit spuštění úlohy názvem úlohy
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Obohacení využití názvem úlohy
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
usage.*,
coalesce(usage_metadata.job_name, jobs.name) as job_name
FROM system.billing.usage
LEFT JOIN jobs ON usage.workspace_id=jobs.workspace_id AND usage.usage_metadata.job_id=jobs.job_id
WHERE
billing_origin_product="JOBS"
Join časová osa spuštění úlohy a využití tables
Obohacení každého fakturačního protokolu o metadata spuštění úlohy
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Výpočet nákladů na spuštění úlohy
Tento dotaz se spojí se systémem billing.usagetable, aby vypočítal náklady na běh úlohy.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Get záznamy o využití pro úlohy SUBMIT_RUN
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name={run_name}
AND workspace_id={workspace_id}
)
Join časová osa spuštění úloh a klastrů tables
úloha obohacení úlohy se spouští s metadaty clusterů
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Vyhledání úloh běžících na univerzálních výpočetních jednotkách
Tento dotaz se spojí se systémem compute.clusterstable, aby se vrátily poslední úlohy spuštěné na výpočetních prostředcích pro všechny účely místo výpočetních úloh.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
řídicí panel monitorování úloh
Následující řídicí panel používá systém tables, který vám pomůže s tím, abyste get začali monitorovat své úlohy a provozní zdraví. Zahrnuje běžné případy použití, jako je sledování výkonu úloh, monitorování selhání a využití prostředků.
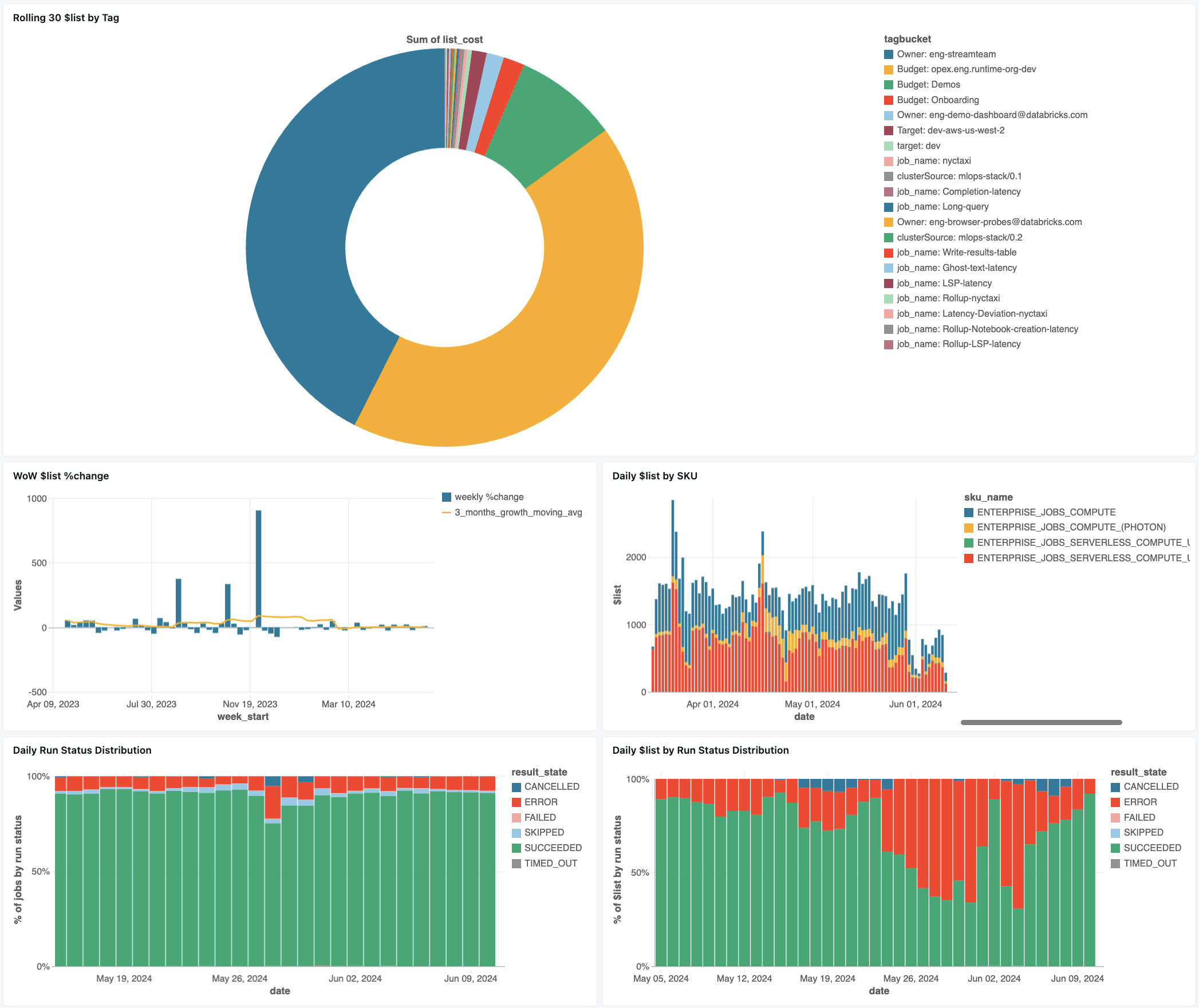
Informace o stažení řídicího panelu naleznete v sekci Monitoring nákladů na úlohy, & výkonnostní sledování pomocí systémů tables.
Řešení problémů
úloha není přihlášena do lakeflow.jobstable
Pokud není úloha v systému viditelná, tables:
- Úloha nebyla změněna za posledních 365 dnů.
- Upravte jakékoli pole úlohy, které jsou v schema, a vytvořte nový záznam.
- Úloha byla vytvořena v jiné oblasti.
- Nedávné vytvoření pracovních míst (table lag)
v job_run_timelinetable nejde najít úlohu
Ne všechna spuštění úloh jsou viditelná všude. I když se položky JOB_RUN zobrazují ve všech položkách tablessouvisejících s úlohou, WORKFLOW_RUN (spuštění pracovního postupu poznámkového bloku) se zaznamenávají pouze v job_run_timeline a SUBMIT_RUN (jednorázová odeslaná spuštění) se zaznamenávají pouze v obou časových osách tables. Tyto běhy nejsou přeneseny do jiného systému úloh tables, jako jsou jobs nebo job_tasks.
Podívejte se na níže uvedené typy běhutable pro podrobný rozpis, jak je každý typ where viditelný a přístupný.
úloha není viditelná v billing.usagetable
V system.billing.usagese usage_metadata.job_id naplní jenom pro úlohy, které běží na výpočetních prostředcích nebo bezserverových prostředcích.
Kromě toho úlohy WORKFLOW_RUN nemají vlastní přiřazení usage_metadata.job_id ani usage_metadata.job_run_id v system.billing.usage.
Místo toho se jejich využití výpočetních prostředků přiřadí nadřazenému poznámkovému bloku, který je spustil.
To znamená, že když poznámkový blok spustí spuštění pracovního postupu, zobrazí se všechny náklady na výpočetní prostředky v rámci využití nadřazeného poznámkového bloku, ne jako samostatná úloha pracovního postupu.
Další informace najdete v tématu Analýza metadat využití.
Vypočítat náklady na úlohu běžící na univerzálním výpočetním prostředí
Přesný výpočet nákladů pro úlohy běžící na výpočetních kapacitách pro specifické účely není možný s přesností 100%. Když se úloha spustí na interaktivním výpočetním prostředí (pro celý účel), na stejném výpočetním prostředku často běží současně několik úloh, jako jsou poznámkové bloky, dotazy SQL nebo jiné úlohy. Vzhledem k tomu, že jsou prostředky clusteru sdílené, neexistuje žádné přímé mapování 1:1 mezi výpočetními náklady a spuštěním jednotlivých úloh.
Pro přesné sledování nákladů na úlohy doporučuje Databricks spouštět úlohy na vyhrazených výpočetních prostředcích pro úlohy nebo na bezserverových výpočetních prostředcích. where, usage_metadata.job_id a usage_metadata.job_run_id umožňují přesné určení nákladů.
Pokud potřebujete použít výpočetní prostředky pro všechny účely, můžete:
- Monitorujte celkové náklady a využití clusteru v
system.billing.usagena základěusage_metadata.cluster_id. - Sledujte metriky doby běhu úloh samostatně.
- Vezměte v úvahu, že jakýkoli odhad nákladů bude přibližný kvůli sdíleným prostředkům.
Další informace o přisuzování nákladů najdete v tématu Analýza metadat využití.
Referenční values
Následující část obsahuje odkazy na selectcolumns v pracovních záležitostech tables.
typ triggeru values
Možné values pro trigger_typecolumn jsou:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
typ spuštění values
Možné values pro run_typecolumn jsou:
| Typ | Popis | Umístění uživatelského rozhraní | Koncový bod rozhraní API | Systém Tables |
|---|---|---|---|---|
JOB_RUN |
Standardní provádění úloh | Uživatelské rozhraní úloh & spuštění úloh | /jobs a /jobs/běhy konečných bodů | pracovních příležitostí, pracovní úkoly, časový harmonogram spuštění úlohy, časový harmonogram spuštění úkolů úlohy |
SUBMIT_RUN |
Jednorázové spuštění přes POST /jobs/runs/submit | Pouze uživatelské rozhraní pro spuštění úloh | /jobs/runs koncové body pouze | časová osa spuštění úlohy, časová osa spuštění úkolu úlohy |
WORKFLOW_RUN |
Iniciováno spuštění z pracovního postupu poznámkového bloku | Nezobrazuje se | Nedostupné | časová osa spuštění úlohy |
stav výsledku values
Možné values pro result_statecolumn jsou:
| Stát | Popis |
|---|---|
SUCCEEDED |
Běh byl úspěšně dokončen. |
FAILED |
Běh se dokončil s chybou |
SKIPPED |
Spuštění nebylo nikdy provedeno, protože nebyla splněna podmínka. |
CANCELLED |
Běh byl zrušen na žádost uživatele. |
TIMED_OUT |
Běh byl zastaven po dosažení časového limitu. |
ERROR |
Běh se dokončil s chybou |
BLOCKED |
Spuštění bylo zablokováno kvůli vstupní závislosti. |
kód ukončení values
Možné values pro termination_codecolumn jsou:
| Kód ukončení | Popis |
|---|---|
SUCCESS |
Operace byla úspěšně dokončena. |
CANCELLED |
Spuštění bylo během provádění zrušeno platformou Databricks; Například pokud byla překročena maximální doba běhu. |
SKIPPED |
Spuštění neproběhlo, například pokud selhalo spuštění nadřazené úlohy, nebyla splněna podmínka typu závislosti nebo neexistovaly žádné věcné úlohy k provedení. |
DRIVER_ERROR |
Při komunikaci se Spark Driverem došlo k chybě. |
CLUSTER_ERROR |
Spuštění selhalo kvůli chybě clusteru. |
REPOSITORY_CHECKOUT_FAILED |
Dokončení rezervace se nezdařilo kvůli chybě při komunikaci se službou třetí strany |
INVALID_CLUSTER_REQUEST |
Spuštění selhalo, protože vydalo neplatný požadavek na spuštění clusteru. |
WORKSPACE_RUN_LIMIT_EXCEEDED |
Pracovní prostor dosáhl limitu maximálního počtu současně aktivních běhů. Zvažte plánování běhů v delším časovém rámci. |
FEATURE_DISABLED |
Spuštění se nezdařilo, protože se pokusilo o přístup k funkci, která pro pracovní prostor není dostupná. |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
Počet žádostí o vytvoření, spuštění a přenesení clusteru překročil přidělenou rychlost limit. Zvažte rozložení spuštění v delším časovém rámci. |
STORAGE_ACCESS_ERROR |
Spuštění selhalo kvůli chybě při přístupu k úložišti blobů zákazníka |
RUN_EXECUTION_ERROR |
Běh byl dokončen se selháním úloh. |
UNAUTHORIZED_ERROR |
Spuštění selhalo kvůli problému s oprávněním při přístupu k prostředku |
LIBRARY_INSTALLATION_ERROR |
Spuštění se nezdařilo při instalaci knihovny požadované uživatelem. Příčiny mohou zahrnovat, ale nejsou omezeny na: zadaná knihovna je neplatná, uživatel nemá dostatečná oprávnění k instalaci této knihovny atd. |
MAX_CONCURRENT_RUNS_EXCEEDED |
Naplánované spuštění překračuje limit maximálního počtu souběžných spuštění set pro úlohu. |
MAX_SPARK_CONTEXTS_EXCEEDED |
Spuštění je naplánované v clusteru, který už dosáhl maximálního počtu kontextů, který je nakonfigurovaný k vytvoření. |
RESOURCE_NOT_FOUND |
Prostředek nezbytný ke spuštění neexistuje. |
INVALID_RUN_CONFIGURATION |
Spuštění selhalo kvůli neplatné konfiguraci. |
CLOUD_FAILURE |
Spuštění selhalo kvůli problému s poskytovatelem cloudu |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
Spuštění se přeskočilo kvůli dosáhnutí maximální velikosti fronty pro úroveň úlohy limit |