Transformace dat ve službě Azure Virtual Network pomocí aktivity Hivu v Azure Data Factory
PLATÍ PRO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
V tomto kurzu použijete Azure PowerShell k vytvoření kanálu datové továrny, který transformuje data pomocí aktivity Hivu v clusteru HDInsight, který je ve službě Azure Virtual Network. V tomto kurzu provedete následující kroky:
- Vytvoření datové továrny
- Vytvoření a nastavení modulu runtime integrace v místním prostředí
- Vytvoření a nasazení propojených služeb
- Vytvoření a nasazení kanálu který obsahuje aktivitu Hivu
- Zahajte spuštění kanálu.
- Monitorování spuštění kanálu
- Ověření výstupu
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
Poznámka:
Při práci s Azure doporučujeme používat modul Azure Az PowerShellu. Začněte tím, že si projdete téma Instalace Azure PowerShellu. Informace o tom, jak migrovat na modul Az PowerShell, najdete v tématu Migrace Azure PowerShellu z AzureRM na Az.
Účet služby Azure Storage. Vytvoříte skript Hivu a uložíte ho do úložiště Azure. Výstup ze skriptu Hivu je uložený v tomto účtu úložiště. V této ukázce clusteru HDInsight používá tento účet služby Azure Storage jako primární úložiště.
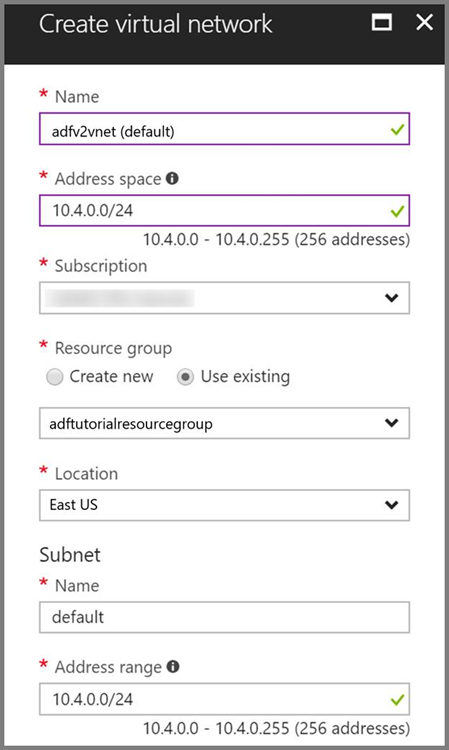
Azure Virtual Network. Pokud nemáte virtuální síť Azure, vytvořte ji pomocí těchto pokynů. V této ukázce je HDInsight ve službě Azure Virtual Network. Tady je ukázka konfigurace služby Azure Virtual Network.
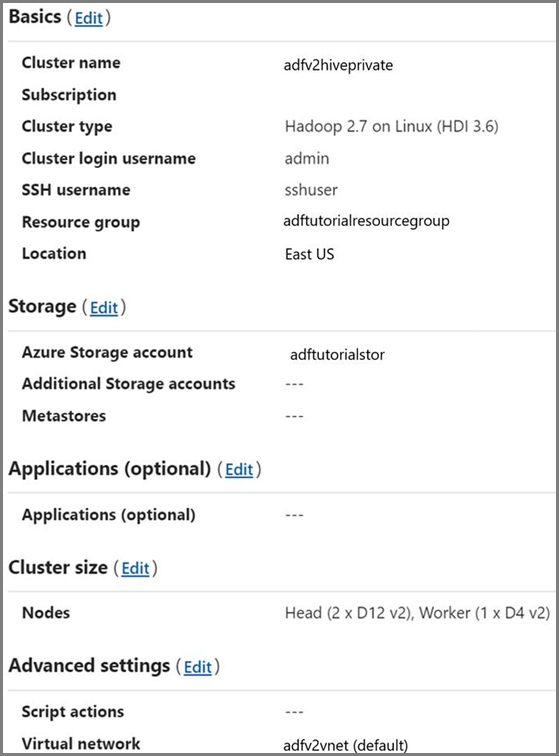
Cluster HDInsight. Vytvořte cluster HDInsight a připojte ho k virtuální síti, kterou jste vytvořili v předchozím kroku, a na základě informací v článku věnovaném rozšíření Azure HDInsightu s využitím služby Azure Virtual Network. Tady je ukázka konfigurace HDInsightu ve virtuální síti.
Azure PowerShell: Postupujte podle pokynů v tématu Jak nainstalovat a nakonfigurovat Azure PowerShell.
Uložení skriptu Hivu do vašeho účtu služby Blob Storage
Vytvořte soubor SQL Hivu s názvem hivescript.hql a s následujícím obsahem:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableVe službě Azure Blob Storage, vytvořte kontejner nazvaný adftutorial, pokud ještě neexistuje.
Vytvořte složku s názvem hivescripts.
Uložte soubor hivescript.hql do podsložky hivescripts.
Vytvoření datové továrny
Nastavte název skupiny prostředků. Skupinu prostředků vytvoříte v rámci tohoto kurzu. Pokud ale chcete, můžete použít existující skupinu prostředků.
$resourceGroupName = "ADFTutorialResourceGroup"Zadejte název datové továrny. Musí být globálně jedinečný.
$dataFactoryName = "MyDataFactory09142017"Zadejte název pro kanál.
$pipelineName = "MyHivePipeline" #Zadejte název pro místní prostředí Integration Runtime. Místní prostředí Integration Runtime potřebujete, pokud služba Data Factory vyžaduje přístup k prostředkům uvnitř virtuální sítě (jako je Azure SQL Database).
$selfHostedIntegrationRuntimeName = "MySelfHostedIR09142017"Spusťte PowerShell. Nechte prostředí Azure PowerShell otevřené až do konce tohoto kurzu Rychlý start. Pokud ho zavřete a znovu otevřete, bude potřeba tyto příkazy spustit znovu. Pokud chcete zobrazit seznam oblastí Azure, ve kterých je služba Data Factory aktuálně dostupná, na následující stránce vyberte oblasti, které vás zajímají, pak rozbalte Analýza a vyhledejte Data Factory:Dostupné produkty v jednotlivých oblastech. Úložiště dat (Azure Storage, Azure SQL Database atd.) a výpočetní prostředí (HDInsight atd.) používané datovou továrnou mohou být v jiných oblastech.
Spusťte následující příkaz a zadejte uživatelské jméno a heslo, které používáte k přihlášení na web Azure Portal:
Connect-AzAccountSpuštěním následujícího příkazu zobrazíte všechna předplatná pro tento účet:
Get-AzSubscriptionSpuštěním následujícího příkazu vyberte předplatné, se kterým chcete pracovat. Místo SubscriptionId použijte ID vašeho předplatného Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"Vytvořte skupinu prostředků ADFTutorialResourceGroup, pokud ještě ve vašem předplatném neexistuje.
New-AzResourceGroup -Name $resourceGroupName -Location "East Us"Vytvořte datovou továrnu.
$df = Set-AzDataFactoryV2 -Location EastUS -Name $dataFactoryName -ResourceGroupName $resourceGroupNameSpusťte následující příkaz pro zobrazení výstupu:
$df
Vytvoření IR v místním prostředí
V této části vytvoříte modul runtime integrace v místním prostředí a přidružíte ho k virtuálnímu počítači Azure ve stejné službě Azure Virtual Network, ve které je váš cluster HDInsight.
Vytvořte modul runtime integrace v místním prostředí. Pokud už existuje jiné prostředí Integration Runtime se stejným názvem, použijte jedinečný název.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName -Type SelfHostedTento příkaz vytvoří logickou registraci modulu runtime integrace v místním prostředí.
Pomocí PowerShellu načtěte ověřovací klíče pro registraci modulu runtime integrace v místním prostředí. Jeden z těchto klíčů zkopírujte pro registraci modulu runtime integrace v místním prostředí.
Get-AzDataFactoryV2IntegrationRuntimeKey -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName | ConvertTo-JsonTady je ukázkový výstup:
{ "AuthKey1": "IR@0000000000000000000000000000000000000=", "AuthKey2": "IR@0000000000000000000000000000000000000=" }Poznamenejte si hodnotu AuthKey1 bez uvozovek.
Vytvořte virtuální počítač Azure a připojte ho do stejné virtuální sítě, která obsahuje příslušný cluster HDInsight. Podrobnosti najdete v tématu věnovaném postupu při vytváření virtuálních počítačů. Připojte ho k virtuální síti Azure.
Ve virtuálním počítači Azure stáhněte modul runtime integrace v místním prostředí. Použijte ověřovací klíč získaný v předchozím kroku a tento modul runtime integrace v místním prostředí ručně zaregistrujte.
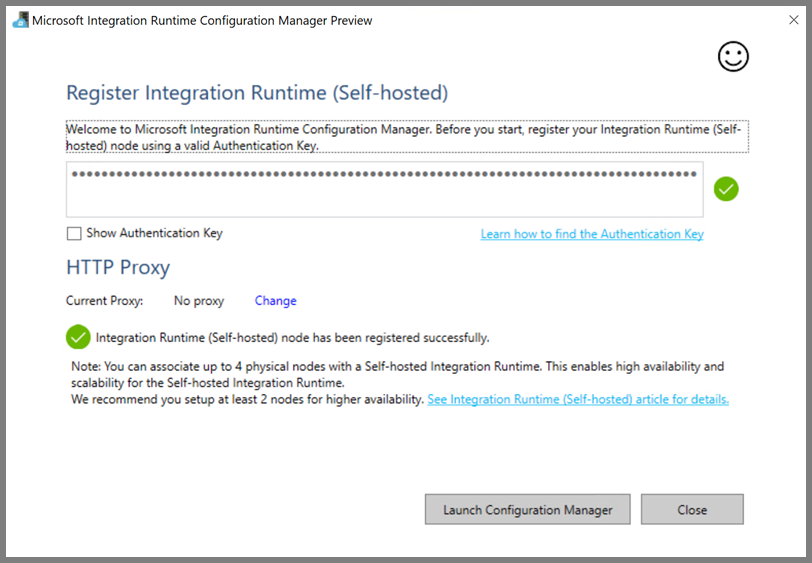
Po úspěšné registraci místního prostředí Integration Runtime se zobrazí následující zpráva:
Po připojení uzlu ke cloudové službě se zobrazí následující stránka:
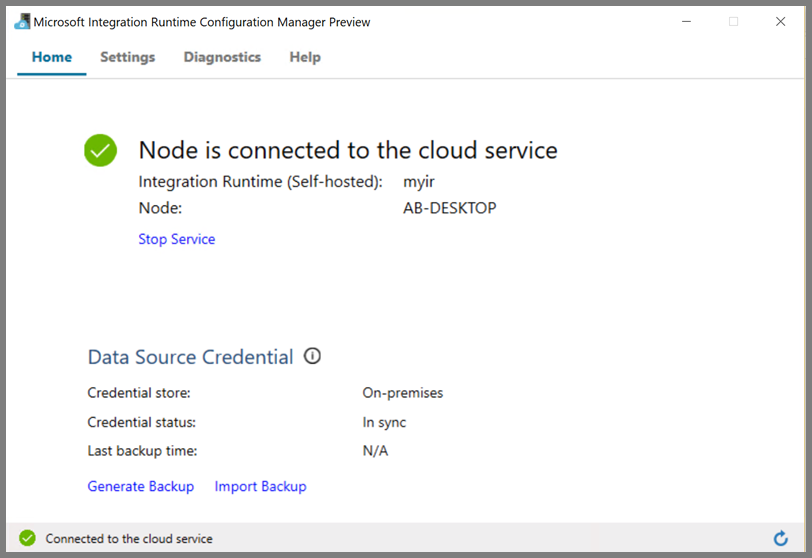
Vytvoření propojených služeb
V této části vytvoříte a nasadíte dvě propojené služby:
- Propojená služba Azure Storage, která propojí váš účet služby Azure Storage s datovou továrnou. Toto úložiště používá cluster HDInsight jako primární. V tomto případě používáme tento účet Azure Storage také k uložení skriptu Hivu a výstup tohoto skriptu.
- Propojená služba HDInsight. Azure Data Factory odešle skript Hive do tohoto clusteru HDInsight ke spuštění.
Propojená služba Azure Storage
Pomocí preferovaného editoru vytvořte soubor JSON, zkopírujte do něj následující definici JSON propojené služby Azure Storage a potom tento soubor uložte jako MyStorageLinkedService.json.
{
"name": "MyStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;AccountKey=<storageAccountKey>"
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Položky <accountname> a <accountkey> nahraďte názvem svého účtu Azure Storage a jeho klíčem.
Propojená služba HDInsight
Pomocí preferovaného editoru vytvořte soubor JSON, zkopírujte následující definici JSON propojené služby Azure HDInsight a potom tento soubor uložte jako MyHDInsightLinkedService.json.
{
"name": "MyHDInsightLinkedService",
"properties": {
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<clustername>.azurehdinsight.net",
"userName": "<username>",
"password": {
"value": "<password>",
"type": "SecureString"
},
"linkedServiceName": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
V definici propojené služby aktualizujte hodnoty následujících vlastností:
userName. Uživatelské jméno pro přihlášení clusteru, které jste zadali při vytváření clusteru.
password. Heslo pro tohoto uživatele.
clusterUri. Zadejte adresu URL clusteru HDInsight v následujícím formátu:
https://<clustername>.azurehdinsight.netV tomto článku se předpokládá, že máte ke clusteru přístup přes internet. To znamená, že se ke clusteru můžete připojit třeba nahttps://clustername.azurehdinsight.net. Tato adresa se používá veřejnou brány, která není dostupná, pokud jste k omezení přístupu z internetu použili skupiny zabezpečení sítě (NSG) nebo uživatelem definované trasy (UDR). Aby služba Data Factory mohla odesílat úlohy do clusterů HDInsight ve službě Azure Virtual Network, musíte ji nakonfigurovat tak, aby tuto adresu URL bylo možné přeložit na privátní IP adresu brány, kterou používá HDInsight.Na webu Azure Portal otevřete službu Virtual Network, ve které je HDInsight. Otevřete síťové rozhraní s názvem začínajícím textem
nic-gateway-0. Poznamenejte si jeho privátní IP adresu. Příklad: 10.6.0.15.Pokud Azure Virtual Network má server DNS, aktualizujte záznam DNS tak, aby se adresa URL clusteru HDInsight
https://<clustername>.azurehdinsight.netdala přeložit na10.6.0.15. Toto je doporučený postup. Pokud ve službě Azure Virtual Network nemáte server DNS, můžete to dočasně obejít tak, že upravíte soubor hosts (C:\Windows\System32\drivers\etc) všech virtuálních počítačů, které se registrovaly jako uzly místního prostředí Integration Runtime, a to přidáním položky jako je tato:10.6.0.15 myHDIClusterName.azurehdinsight.net
Vytvoření propojených služeb
V PowerShellu přejděte do složky, ve které jste vytvořili soubory JSON, a spusťte následující příkaz pro nasazení propojených služeb:
V PowerShellu přejděte do složky, ve které jste vytvořili soubory JSON.
Spuštěním následujícího příkazu vytvořte propojenou službu Azure Storage.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyStorageLinkedService" -File "MyStorageLinkedService.json"Spuštěním následujícího příkazu vytvořte propojenou službu Azure HDInsight.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyHDInsightLinkedService" -File "MyHDInsightLinkedService.json"
Vytvoření kanálu
V tomto kroku pomocí aktivity Hivu vytvoříte nový kanál. Tato aktivity spustí skript Hivu, který vrátí data z ukázkové tabulky a uloží je do cesty, které jste definovali. Pomocí preferovaného editoru vytvořte soubor JSON, zkopírujte následující definici JSON kanálu a potom tento soubor uložte jako MyHivePipeline.json.
{
"name": "MyHivePipeline",
"properties": {
"activities": [
{
"name": "MyHiveActivity",
"type": "HDInsightHive",
"linkedServiceName": {
"referenceName": "MyHDILinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptPath": "adftutorial\\hivescripts\\hivescript.hql",
"getDebugInfo": "Failure",
"defines": {
"Output": "wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/"
},
"scriptLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
]
}
}
Mějte na paměti následující body:
- Parametr scriptPath odkazuje na cestu ke skriptu Hivu v účtu Azure Storage, který jste použili pro MyStorageLinkedService. V této cestě se rozlišují velká a malá písmena.
- Output je argument použitý ve skriptu Hivu. Při zadávání odkazu na existující složku ve službě Azure Storage použijte formát
wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. V této cestě se rozlišují velká a malá písmena.
Přejděte do složky, ve které jste vytvořili soubory JSON, a spusťte následující příkaz pro nasazení kanálu:
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name $pipelineName -File "MyHivePipeline.json"
Spuštění kanálu
Zahajte spuštění kanálu. Zaznamená se také ID spuštění kanálu pro budoucí monitorování.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName $pipelineNameSpusťte následující skript, který bude nepřetržitě kontrolovat stav spuštění kanálu, dokud neskončí.
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if(!$result) { Write-Host "Waiting for pipeline to start..." -foregroundcolor "Yellow" } elseif (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" } else { Write-Host "Pipeline '"$pipelineName"' run finished. Result:" -foregroundcolor "Yellow" $result break } ($result | Format-List | Out-String) Start-Sleep -Seconds 15 } Write-Host "Activity `Output` section:" -foregroundcolor "Yellow" $result.Output -join "`r`n" Write-Host "Activity `Error` section:" -foregroundcolor "Yellow" $result.Error -join "`r`n"Zde je výstup tohoto ukázkového spuštění:
Pipeline run status: In Progress ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 000000000-0000-0000-000000000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : DurationInMs : Status : InProgress Error : Pipeline ' MyHivePipeline' run finished. Result: ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 0000000-0000-0000-0000-000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : {logLocation, clusterInUse, jobId, ExecutionProgress...} LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : 9/18/2017 6:59:16 AM DurationInMs : 63636 Status : Succeeded Error : {errorCode, message, failureType, target} Activity Output section: "logLocation": "wasbs://adfjobs@adfv2samplestor.blob.core.windows.net/HiveQueryJobs/000000000-0000-47c3-9b28-1cdc7f3f2ba2/18_09_2017_06_58_18_023/Status" "clusterInUse": "https://adfv2HivePrivate.azurehdinsight.net" "jobId": "job_1505387997356_0024" "ExecutionProgress": "Succeeded" "effectiveIntegrationRuntime": "MySelfhostedIR" Activity Error section: "errorCode": "" "message": "" "failureType": "" "target": "MyHiveActivity"Zkontrolujte složku
outputfolder. Měla by obsahovat nový soubor vytvořený jako výsledek dotazu Hivu, který vypadá podobně jako následující ukázkový výstup:8 en-US SCH-i500 California 23 en-US Incredible Pennsylvania 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 246 en-US SCH-i500 District Of Columbia 246 en-US SCH-i500 District Of Columbia
Související obsah
V tomto kurzu jste provedli následující kroky:
- Vytvoření datové továrny
- Vytvoření a nastavení modulu runtime integrace v místním prostředí
- Vytvoření a nasazení propojených služeb
- Vytvoření a nasazení kanálu který obsahuje aktivitu Hivu
- Zahajte spuštění kanálu.
- Monitorování spuštění kanálu
- Ověření výstupu
Pokud se chcete dozvědět víc o transformaci dat pomocí clusteru Spark v Azure, přejděte k následujícímu kurzu: